

Java 동시 프로그래밍의 요약 및 사고에 대한 자세한 소개

좋은 동시 코드를 작성하는 것은 매우 어렵습니다. Java 언어에는 첫 번째 버전부터 멀티스레딩 지원 기능이 내장되어 있었는데, 이는 당시로서는 매우 놀라운 일이었습니다. 그러나 동시성 프로그래밍에 대한 더 깊은 이해와 실습을 통해 깨닫게 된 것은 동시성 프로그래밍입니다. 더 많은 솔루션과 더 나은 선택이 있습니다. 이 기사는 동시 프로그래밍에 대한 요약이자 반영이며 Java 5 이상 버전에서 동시 코드를 작성하는 방법에 대한 경험도 공유합니다.
동시성이 필요한 이유
동시성은 실제로 무엇을 할지(목표)와 언제 할지(타이밍)를 구분하는 데 도움이 되는 디커플링 전략입니다. 이렇게 하면 애플리케이션의 처리량(CPU 예약 시간 증가)과 구조(프로그램의 여러 부분이 함께 작동함)가 크게 향상될 수 있습니다. Java 웹 개발을 해본 사람이라면 Java 웹의 Servlet 프로그램이 Servlet 컨테이너 지원을 통해 단일 인스턴스 다중 스레드 작업 모드를 채택한다는 것을 알고 있습니다.
오해와 답변
동시 프로그래밍에 대한 가장 일반적인 오해는 다음과 같습니다.
-동시성은 항상 성능을 향상시킵니다. CPU)는 프로그램의 성능을 크게 향상시킬 수 있지만 스레드 수가 많은 경우 스레드 간 스케줄링을 자주 전환하면 시스템 성능이 저하됩니다.)
- 동시 프로그램 작성에는 원래 설계를 수정할 필요가 없습니다. (목적은 디커플링 타이밍이 시스템 구조에 큰 영향을 미치는 경우가 많기 때문입니다)
-웹이나 EJB 컨테이너를 사용할 때 동시성 문제에 대해 걱정하지 마십시오. (컨테이너가 무엇을 하는지 이해해야만 가능합니다) 컨테이너를 더 잘 사용하는 것이 좋습니다)
다음 설명은 동시성에 대한 객관적인 이해입니다.
-동시 프로그램을 작성하면 코드에 추가 오버헤드가 추가됩니다
-올바른 동시성 매우 간단한 문제라도 매우 복잡합니다
-동시성의 결함은 재현하기가 쉽지 않기 때문에 찾기가 쉽지 않습니다
-동시성은 종종 디자인에 근본적인 수정이 필요합니다 전략
병행성 프로그래밍의 원리와 기법
단일 책임 원칙
동시성 관련 코드와 기타 코드 분리(동시성 관련 코드는 자체 개발, 수정 및 튜닝 수명주기).
데이터 범위 제한
공유 객체의 동일한 필드를 수정할 때 두 스레드가 서로 간섭하여 예측할 수 없는 동작이 발생할 수 있습니다. 하지만 중요한 영역의 수는 제한되어야 합니다.
데이터 복사본 사용
데이터 복사본은 데이터 공유를 방지하는 좋은 방법입니다. 복사된 개체는 읽기 전용으로만 처리됩니다. CopyOnWriteArrayList라는 클래스가 Java 5의 java.util.concurrent 패키지에 추가되었습니다. 이는 List 인터페이스의 하위 유형이므로 ArrayList의 스레드 안전 버전으로 생각할 수 있습니다. 쓰기 시 복사를 사용합니다. 데이터 복사본을 생성하여 공유 데이터에 대한 동시 액세스로 인해 발생하는 문제를 방지합니다.
스레드는 최대한 독립적이어야 합니다.
스레드가 자신만의 세계에 존재하도록 하고 다른 스레드와 데이터를 공유하지 마세요. Java 웹 개발 경험이 있는 사람이라면 누구나 Servlet이 단일 인스턴스 및 다중 스레드 방식으로 작동한다는 것을 알고 있습니다. 각 요청과 관련된 데이터는 Servlet 하위 클래스의 서비스 메소드(또는 doGet 또는 doPost 메소드)의 매개변수를 통해 전달됩니다. 의. 서블릿의 코드가 지역 변수만 사용하는 한 서블릿은 동기화 문제를 일으키지 않습니다. springMVC 컨트롤러는 동일한 작업을 수행합니다. 요청에서 얻은 개체는 클래스의 멤버가 아닌 메서드 매개 변수로 전달됩니다. 분명히 Struts 2는 정반대이므로 Struts 2의 컨트롤러인 Action 클래스는 각 요청에 해당합니다. 인스턴스에.
Java 5 이전의 동시 프로그래밍
Java의 스레드 모델은 선점형 스레드 스케줄링을 기반으로 합니다. 즉,
모든 스레드는 동일한 프로세스에서 객체를 쉽게 공유할 수 있습니다.
이러한 개체에 대한 참조가 있는 모든 스레드는 이러한 개체를 수정할 수 있습니다.
데이터를 보호하기 위해 개체를 잠글 수 있습니다.
스레드와 잠금을 기반으로 하는 Java의 동시성은 수준이 너무 낮으며 잠금을 사용하는 것은 모든 동시성을 대기열로 전환하는 것과 같기 때문에 종종 매우 좋지 않습니다.
Java 5 이전에는 동기화 키워드를 사용하여 잠금 기능을 구현할 수 있었습니다. 이는 코드 블록 및 메서드에서 사용할 수 있었으며, 이는 전체 코드 블록이나 메서드를 실행하기 전에 스레드가 적절한 잠금을 획득해야 함을 나타냅니다. 클래스의 비정적 메서드(멤버 메서드)의 경우 이는 개체 인스턴스의 잠금을 획득하는 것을 의미하고, 클래스의 정적 메서드(클래스 메서드)의 경우 이는 클래스의 Class 개체의 잠금을 획득하는 것을 의미합니다. 블록의 경우 프로그래머는 어떤 객체 잠금을 획득할지 지정할 수 있습니다.
동기화 코드 블록이든 동기화 방법이든, 한 번에 하나의 스레드만 들어갈 수 있습니다. 다른 스레드가 (동일한 동기화 블록이든 다른 동기화 블록이든) 입력을 시도하면 JVM은 이를 일시 중지합니다. (풀의 대기 잠금 장치에 넣습니다). 이 구조를 동시성 이론에서는 임계 섹션이라고 합니다. 여기서는 동기화를 사용하여 Java에서 동기화 및 잠금을 구현하는 기능을 요약할 수 있습니다.
기본 데이터 유형이 아닌 객체만 잠글 수 있습니다
-
잠긴 개체 배열의 단일 개체는 잠기지 않습니다
동기화 메서드는 전체 개체를 포함하는 동기화된(this) { … } 코드 블록으로 볼 수 있습니다. 메소드
정적 동기화 메소드는 클래스 객체를 잠급니다
내부 클래스의 동기화는 외부 클래스와 독립적입니다
동기화 수정자는 메서드 시그니처의 일부가 아니므로 인터페이스의 메서드 선언에 나타날 수 없습니다.
비동기 메서드는 잠금에 신경 쓰지 않습니다. status; 동기화된 메소드는 실행 중에도 계속 실행될 수 있습니다.
동기화에 의해 구현된 잠금은 재진입 잠금입니다.
JVM 내부에서는 효율성을 높이기 위해 동시에 실행되는 각 스레드가 처리 중인 데이터의 캐시된 복사본을 갖게 됩니다. 실제로 동기화됨 다른 스레드에서 잠긴 개체를 나타내는 메모리 블록입니다(복사 데이터는 주 메모리와 동기화된 상태로 유지됩니다. 이제 동기화라는 단어가 사용되는 이유를 알 수 있습니다). 간단히 말해서 동기화 블록 또는 동기화 방법이 실행된 후입니다. , 잠긴 개체에 대한 모든 수정 사항은 잠금이 해제되기 전에 주 메모리에 다시 기록되어야 합니다. 잠금을 얻기 위해 동기화 블록에 들어간 후 잠긴 개체의 데이터가 주 메모리에서 읽혀지고 데이터가 복사됩니다. 잠금을 보유한 스레드의 메인 메모리에 있는 데이터 보기와 동기화되어야 합니다.
Java 원본에는 Volatile이라는 키워드가 있었는데, 이는 휘발성에 의해 수정되는 변수는 다음과 같은 규칙을 따르기 때문에 간단한 동기화 처리 메커니즘이다.
변수의 값은 사용하기 전에 항상 메인 메모리에서 읽어옵니다.
변수 값에 대한 수정은 항상 완료 후 메인 메모리에 다시 기록됩니다.
휘발성 키워드를 사용하면 멀티 스레드 환경에서 컴파일러가 잘못된 최적화 가정을 방지할 수 있습니다(컴파일러는 스레드에서 값이 변경되지 않는 변수를 상수로 최적화할 수 있습니다). 그러나 수정 시 현재 상태(읽을 때의 값)에 의존하지 않는 변수만 휘발성으로 선언해야 합니다.
불변 모드는 동시 프로그래밍 시 고려할 수 있는 디자인이기도 합니다. 객체의 상태를 변경하지 않고 그대로 유지하려면 객체의 복사본을 생성하고 원본 객체를 변경하지 않고 복사본에 변경 사항을 기록합니다. 일관되지 않은 상태가 아니므로 불변 객체는 스레드로부터 안전합니다. 우리가 Java에서 자주 사용하는 String 클래스는 이러한 디자인을 채택하고 있습니다. 불변 패턴에 익숙하지 않다면 Yan Hong 박사의 저서 "Java and Patterns" 34장을 읽어보세요. 이렇게 말씀드리면 최종 키워드의 중요성도 실감하실 수 있을 것입니다.
Java 5의 동시 프로그래밍
Java가 앞으로 어떤 방향으로 발전하든지, Java 5는 Java 개발 역사상 매우 중요한 버전임에 틀림없습니다. 여기에서는 기능에 대해 논의하지 않을 것입니다(관심이 있는 경우 내 다른 기사 "Java 20주년: Java 버전의 진화에서 프로그래밍 기술 개발 살펴보기"를 읽어보세요). 하지만 기능을 제공한 Doug Lea에게 감사해야 합니다. Java 5의 랜드마크 걸작인 java.util.concurrent 패키지의 등장으로 Java 동시 프로그래밍에 더 많은 선택권과 더 나은 작업 방식이 제공됩니다. Doug Lea의 걸작에는 주로 다음 콘텐츠가 포함됩니다.
더 나은 스레드 안전 컨테이너
-
스레드 풀 및 관련 도구 클래스
선택적 비차단 솔루션
명시적 잠금 및 세마포어 메커니즘
아래에 이러한 사항을 하나씩 설명합니다.
Atomic 클래스
Java 5의 java.util.concurrent 패키지 아래에는 AtomicInteger 및 AtomicLong과 같이 Atomic으로 시작하는 여러 클래스가 있는 원자 하위 패키지가 있습니다. 최신 프로세서의 특성을 활용하고 비차단 방식으로 원자 작업을 완료할 수 있습니다. 코드는 다음과 같습니다.
/**
ID序列生成器
*/
public class IdGenerator {
private final AtomicLong sequenceNumber = new AtomicLong(0);
public long next() {
return sequenceNumber.getAndIncrement();
}
}디스플레이 잠금
동기화 키워드를 기반으로 한 잠금 메커니즘입니다.
한 가지 유형의 잠금만 있으며 모든 동기화 작업에 동일한 효과가 있습니다.
잠금은 코드 블록이나 메소드의 시작 부분에 배치되어야 합니다. 해당 위치에서 획득하고 끝에서 해제
스레드가 잠금을 얻거나 차단됩니다. 다른 가능성은 없습니다
Java 5 잠금 메커니즘 리팩터링하여 다음 측면에서 잠금 메커니즘을 개선할 수 있는 디스플레이 잠금을 제공합니다.
可以添加不同类型的锁,例如读取锁和写入锁
可以在一个方法中加锁,在另一个方法中解锁
可以使用tryLock方式尝试获得锁,如果得不到锁可以等待、回退或者干点别的事情,当然也可以在超时之后放弃操作
显示的锁都实现了java.util.concurrent.Lock接口,主要有两个实现类:
ReentrantLock – 比synchronized稍微灵活一些的重入锁
ReentrantReadWriteLock – 在读操作很多写操作很少时性能更好的一种重入锁
对于如何使用显示锁,可以参考我的Java面试系列文章《Java面试题集51-70》中第60题的代码。只有一点需要提醒,解锁的方法unlock的调用最好能够在finally块中,因为这里是释放外部资源最好的地方,当然也是释放锁的最佳位置,因为不管正常异常可能都要释放掉锁来给其他线程以运行的机会。
CountDownLatch
CountDownLatch是一种简单的同步模式,它让一个线程可以等待一个或多个线程完成它们的工作从而避免对临界资源并发访问所引发的各种问题。下面借用别人的一段代码(我对它做了一些重构)来演示CountDownLatch是如何工作的。
import java.util.concurrent.CountDownLatch;
/**
* 工人类
* @author 骆昊
*
*/
class Worker {
private String name; // 名字
private long workDuration; // 工作持续时间
/**
* 构造器
*/
public Worker(String name, long workDuration) {
this.name = name;
this.workDuration = workDuration;
}
/**
* 完成工作
*/
public void doWork() {
System.out.println(name + " begins to work...");
try {
Thread.sleep(workDuration); // 用休眠模拟工作执行的时间
} catch(InterruptedException ex) {
ex.printStackTrace();
}
System.out.println(name + " has finished the job...");
}
}
/**
* 测试线程
* @author 骆昊
*
*/
class WorkerTestThread implements Runnable {
private Worker worker;
private CountDownLatch cdLatch;
public WorkerTestThread(Worker worker, CountDownLatch cdLatch) {
this.worker = worker;
this.cdLatch = cdLatch;
}
@Override
public void run() {
worker.doWork(); // 让工人开始工作
cdLatch.countDown(); // 工作完成后倒计时次数减1
}
}
class CountDownLatchTest {
private static final int MAX_WORK_DURATION = 5000; // 最大工作时间
private static final int MIN_WORK_DURATION = 1000; // 最小工作时间
// 产生随机的工作时间
private static long getRandomWorkDuration(long min, long max) {
return (long) (Math.random() * (max - min) + min);
}
public static void main(String[] args) {
CountDownLatch latch = new CountDownLatch(2); // 创建倒计时闩并指定倒计时次数为2
Worker w1 = new Worker("骆昊", getRandomWorkDuration(MIN_WORK_DURATION, MAX_WORK_DURATION));
Worker w2 = new Worker("王大锤", getRandomWorkDuration(MIN_WORK_DURATION, MAX_WORK_DURATION));
new Thread(new WorkerTestThread(w1, latch)).start();
new Thread(new WorkerTestThread(w2, latch)).start();
try {
latch.await(); // 等待倒计时闩减到0
System.out.println("All jobs have been finished!");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}ConcurrentHashMap
ConcurrentHashMap是HashMap在并发环境下的版本,大家可能要问,既然已经可以通过Collections.synchronizedMap获得线程安全的映射型容器,为什么还需要ConcurrentHashMap呢?因为通过Collections工具类获得的线程安全的HashMap会在读写数据时对整个容器对象上锁,这样其他使用该容器的线程无论如何也无法再获得该对象的锁,也就意味着要一直等待前一个获得锁的线程离开同步代码块之后才有机会执行。实际上,HashMap是通过哈希函数来确定存放键值对的桶(桶是为了解决哈希冲突而引入的),修改HashMap时并不需要将整个容器锁住,只需要锁住即将修改的“桶”就可以了。HashMap的数据结构如下图所示。
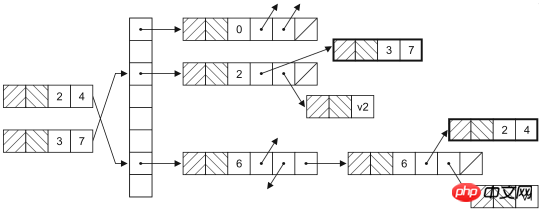
此外,ConcurrentHashMap还提供了原子操作的方法,如下所示:
putIfAbsent:如果还没有对应的键值对映射,就将其添加到HashMap中。
remove:如果键存在而且值与当前状态相等(equals比较结果为true),则用原子方式移除该键值对映射
replace:替换掉映射中元素的原子操作
CopyOnWriteArrayList
CopyOnWriteArrayList是ArrayList在并发环境下的替代品。CopyOnWriteArrayList通过增加写时复制语义来避免并发访问引起的问题,也就是说任何修改操作都会在底层创建一个列表的副本,也就意味着之前已有的迭代器不会碰到意料之外的修改。这种方式对于不要严格读写同步的场景非常有用,因为它提供了更好的性能。记住,要尽量减少锁的使用,因为那势必带来性能的下降(对数据库中数据的并发访问不也是如此吗?如果可以的话就应该放弃悲观锁而使用乐观锁),CopyOnWriteArrayList很明显也是通过牺牲空间获得了时间(在计算机的世界里,时间和空间通常是不可调和的矛盾,可以牺牲空间来提升效率获得时间,当然也可以通过牺牲时间来减少对空间的使用)。
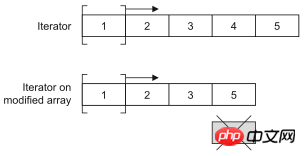
可以通过下面两段代码的运行状况来验证一下CopyOnWriteArrayList是不是线程安全的容器。
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
class AddThread implements Runnable {
private List<Double> list;
public AddThread(List<Double> list) {
this.list = list;
}
@Override
public void run() {
for(int i = 0; i < 10000; ++i) {
list.add(Math.random());
}
}
}
public class Test05 {
private static final int THREAD_POOL_SIZE = 2;
public static void main(String[] args) {
List<Double> list = new ArrayList<>();
ExecutorService es = Executors.newFixedThreadPool(THREAD_POOL_SIZE);
es.execute(new AddThread(list));
es.execute(new AddThread(list));
es.shutdown();
}
}上面的代码会在运行时产生ArrayIndexOutOfBoundsException,试一试将上面代码25行的ArrayList换成CopyOnWriteArrayList再重新运行。
List<Double> list = new CopyOnWriteArrayList<>();
Queue
队列是一个无处不在的美妙概念,它提供了一种简单又可靠的方式将资源分发给处理单元(也可以说是将工作单元分配给待处理的资源,这取决于你看待问题的方式)。实现中的并发编程模型很多都依赖队列来实现,因为它可以在线程之间传递工作单元。
Java 5中的BlockingQueue就是一个在并发环境下非常好用的工具,在调用put方法向队列中插入元素时,如果队列已满,它会让插入元素的线程等待队列腾出空间;在调用take方法从队列中取元素时,如果队列为空,取出元素的线程就会阻塞。
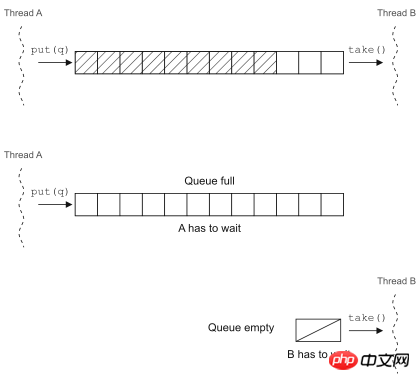
可以用BlockingQueue来实现生产者-消费者并发模型(下一节中有介绍),当然在Java 5以前也可以通过wait和notify来实现线程调度,比较一下两种代码就知道基于已有的并发工具类来重构并发代码到底好在哪里了。
基于wait和notify的实现
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 公共常量
* @author 骆昊
*
*/
class Constants {
public static final int MAX_BUFFER_SIZE = 10;
public static final int NUM_OF_PRODUCER = 2;
public static final int NUM_OF_CONSUMER = 3;
}
/**
* 工作任务
* @author 骆昊
*
*/
class Task {
private String id; // 任务的编号
public Task() {
id = UUID.randomUUID().toString();
}
@Override
public String toString() {
return "Task[" + id + "]";
}
}
/**
* 消费者
* @author 骆昊
*
*/
class Consumer implements Runnable {
private List<Task> buffer;
public Consumer(List<Task> buffer) {
this.buffer = buffer;
}
@Override
public void run() {
while(true) {
synchronized(buffer) {
while(buffer.isEmpty()) {
try {
buffer.wait();
} catch(InterruptedException e) {
e.printStackTrace();
}
}
Task task = buffer.remove(0);
buffer.notifyAll();
System.out.println("Consumer[" + Thread.currentThread().getName() + "] got " + task);
}
}
}
}
/**
* 生产者
* @author 骆昊
*
*/
class Producer implements Runnable {
private List<Task> buffer;
public Producer(List<Task> buffer) {
this.buffer = buffer;
}
@Override
public void run() {
while(true) {
synchronized (buffer) {
while(buffer.size() >= Constants.MAX_BUFFER_SIZE) {
try {
buffer.wait();
} catch(InterruptedException e) {
e.printStackTrace();
}
}
Task task = new Task();
buffer.add(task);
buffer.notifyAll();
System.out.println("Producer[" + Thread.currentThread().getName() + "] put " + task);
}
}
}
}
public class Test06 {
public static void main(String[] args) {
List<Task> buffer = new ArrayList<>(Constants.MAX_BUFFER_SIZE);
ExecutorService es = Executors.newFixedThreadPool(Constants.NUM_OF_CONSUMER + Constants.NUM_OF_PRODUCER);
for(int i = 1; i <= Constants.NUM_OF_PRODUCER; ++i) {
es.execute(new Producer(buffer));
}
for(int i = 1; i <= Constants.NUM_OF_CONSUMER; ++i) {
es.execute(new Consumer(buffer));
}
}
}基于BlockingQueue的实现
import java.util.UUID;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
/**
* 公共常量
* @author 骆昊
*
*/
class Constants {
public static final int MAX_BUFFER_SIZE = 10;
public static final int NUM_OF_PRODUCER = 2;
public static final int NUM_OF_CONSUMER = 3;
}
/**
* 工作任务
* @author 骆昊
*
*/
class Task {
private String id; // 任务的编号
public Task() {
id = UUID.randomUUID().toString();
}
@Override
public String toString() {
return "Task[" + id + "]";
}
}
/**
* 消费者
* @author 骆昊
*
*/
class Consumer implements Runnable {
private BlockingQueue<Task> buffer;
public Consumer(BlockingQueue<Task> buffer) {
this.buffer = buffer;
}
@Override
public void run() {
while(true) {
try {
Task task = buffer.take();
System.out.println("Consumer[" + Thread.currentThread().getName() + "] got " + task);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
/**
* 生产者
* @author 骆昊
*
*/
class Producer implements Runnable {
private BlockingQueue<Task> buffer;
public Producer(BlockingQueue<Task> buffer) {
this.buffer = buffer;
}
@Override
public void run() {
while(true) {
try {
Task task = new Task();
buffer.put(task);
System.out.println("Producer[" + Thread.currentThread().getName() + "] put " + task);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Test07 {
public static void main(String[] args) {
BlockingQueue<Task> buffer = new LinkedBlockingQueue<>(Constants.MAX_BUFFER_SIZE);
ExecutorService es = Executors.newFixedThreadPool(Constants.NUM_OF_CONSUMER + Constants.NUM_OF_PRODUCER);
for(int i = 1; i <= Constants.NUM_OF_PRODUCER; ++i) {
es.execute(new Producer(buffer));
}
for(int i = 1; i <= Constants.NUM_OF_CONSUMER; ++i) {
es.execute(new Consumer(buffer));
}
}
}使用BlockingQueue后代码优雅了很多。
并发模型
在继续下面的探讨之前,我们还是重温一下几个概念:
| 概念 | 解释 |
|---|---|
| 临界资源 | 并发环境中有着固定数量的资源 |
| 互斥 | 对资源的访问是排他式的 |
| 饥饿 | 一个或一组线程长时间或永远无法取得进展 |
| 死锁 | 两个或多个线程相互等待对方结束 |
| 活锁 | 想要执行的线程总是发现其他的线程正在执行以至于长时间或永远无法执行 |
重温了这几个概念后,我们可以探讨一下下面的几种并发模型。
生产者-消费者
一个或多个生产者创建某些工作并将其置于缓冲区或队列中,一个或多个消费者会从队列中获得这些工作并完成之。这里的缓冲区或队列是临界资源。当缓冲区或队列放满的时候,生产这会被阻塞;而缓冲区或队列为空的时候,消费者会被阻塞。生产者和消费者的调度是通过二者相互交换信号完成的。
读者-写者
当存在一个主要为读者提供信息的共享资源,它偶尔会被写者更新,但是需要考虑系统的吞吐量,又要防止饥饿和陈旧资源得不到更新的问题。在这种并发模型中,如何平衡读者和写者是最困难的,当然这个问题至今还是一个被热议的问题,恐怕必须根据具体的场景来提供合适的解决方案而没有那种放之四海而皆准的方法(不像我在国内的科研文献中看到的那样)。
哲学家进餐
1965年,荷兰计算机科学家图灵奖得主Edsger Wybe Dijkstra提出并解决了一个他称之为哲学家进餐的同步问题。这个问题可以简单地描述如下:五个哲学家围坐在一张圆桌周围,每个哲学家面前都有一盘通心粉。由于通心粉很滑,所以需要两把叉子才能夹住。相邻两个盘子之间放有一把叉子如下图所示。哲学家的生活中有两种交替活动时段:即吃饭和思考。当一个哲学家觉得饿了时,他就试图分两次去取其左边和右边的叉子,每次拿一把,但不分次序。如果成功地得到了两把叉子,就开始吃饭,吃完后放下叉子继续思考。
把上面问题中的哲学家换成线程,把叉子换成竞争的临界资源,上面的问题就是线程竞争资源的问题。如果没有经过精心的设计,系统就会出现死锁、活锁、吞吐量下降等问题。
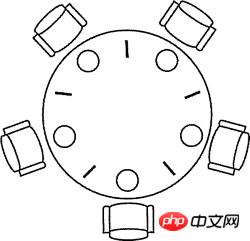
下面是用信号量原语来解决哲学家进餐问题的代码,使用了Java 5并发工具包中的Semaphore类(代码不够漂亮但是已经足以说明问题了)。
//import java.util.concurrent.ExecutorService;
//import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
/**
* 存放线程共享信号量的上下问
* @author 骆昊
*
*/
class AppContext {
public static final int NUM_OF_FORKS = 5; // 叉子数量(资源)
public static final int NUM_OF_PHILO = 5; // 哲学家数量(线程)
public static Semaphore[] forks; // 叉子的信号量
public static Semaphore counter; // 哲学家的信号量
static {
forks = new Semaphore[NUM_OF_FORKS];
for (int i = 0, len = forks.length; i < len; ++i) {
forks[i] = new Semaphore(1); // 每个叉子的信号量为1
}
counter = new Semaphore(NUM_OF_PHILO - 1); // 如果有N个哲学家,最多只允许N-1人同时取叉子
}
/**
* 取得叉子
* @param index 第几个哲学家
* @param leftFirst 是否先取得左边的叉子
* @throws InterruptedException
*/
public static void putOnFork(int index, boolean leftFirst) throws InterruptedException {
if(leftFirst) {
forks[index].acquire();
forks[(index + 1) % NUM_OF_PHILO].acquire();
}
else {
forks[(index + 1) % NUM_OF_PHILO].acquire();
forks[index].acquire();
}
}
/**
* 放回叉子
* @param index 第几个哲学家
* @param leftFirst 是否先放回左边的叉子
* @throws InterruptedException
*/
public static void putDownFork(int index, boolean leftFirst) throws InterruptedException {
if(leftFirst) {
forks[index].release();
forks[(index + 1) % NUM_OF_PHILO].release();
}
else {
forks[(index + 1) % NUM_OF_PHILO].release();
forks[index].release();
}
}
}
/**
* 哲学家
* @author 骆昊
*
*/
class Philosopher implements Runnable {
private int index; // 编号
private String name; // 名字
public Philosopher(int index, String name) {
this.index = index;
this.name = name;
}
@Override
public void run() {
while(true) {
try {
AppContext.counter.acquire();
boolean leftFirst = index % 2 == 0;
AppContext.putOnFork(index, leftFirst);
System.out.println(name + "正在吃意大利面(通心粉)..."); // 取到两个叉子就可以进食
AppContext.putDownFork(index, leftFirst);
AppContext.counter.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Test04 {
public static void main(String[] args) {
String[] names = { "骆昊", "王大锤", "张三丰", "杨过", "李莫愁" }; // 5位哲学家的名字
// ExecutorService es = Executors.newFixedThreadPool(AppContext.NUM_OF_PHILO); // 创建固定大小的线程池
// for(int i = 0, len = names.length; i < len; ++i) {
// es.execute(new Philosopher(i, names[i])); // 启动线程
// }
// es.shutdown();
for(int i = 0, len = names.length; i < len; ++i) {
new Thread(new Philosopher(i, names[i])).start();
}
}
}现实中的并发问题基本上都是这三种模型或者是这三种模型的变体。
测试并发代码
对并发代码的测试也是非常棘手的事情,棘手到无需说明大家也很清楚的程度,所以这里我们只是探讨一下如何解决这个棘手的问题。我们建议大家编写一些能够发现问题的测试并经常性的在不同的配置和不同的负载下运行这些测试。不要忽略掉任何一次失败的测试,线程代码中的缺陷可能在上万次测试中仅仅出现一次。具体来说有这么几个注意事项:
不要将系统的失效归结于偶发事件,就像拉不出屎的时候不能怪地球没有引力。
先让非并发代码工作起来,不要试图同时找到并发和非并发代码中的缺陷。
编写可以在不同配置环境下运行的线程代码。
编写容易调整的线程代码,这样可以调整线程使性能达到最优。
让线程的数量多于CPU或CPU核心的数量,这样CPU调度切换过程中潜在的问题才会暴露出来。
让并发代码在不同的平台上运行。
通过自动化或者硬编码的方式向并发代码中加入一些辅助测试的代码。
Java 7的并发编程
Java 7中引入了TransferQueue,它比BlockingQueue多了一个叫transfer的方法,如果接收线程处于等待状态,该操作可以马上将任务交给它,否则就会阻塞直至取走该任务的线程出现。可以用TransferQueue代替BlockingQueue,因为它可以获得更好的性能。
刚才忘记了一件事情,Java 5中还引入了Callable接口、Future接口和FutureTask接口,通过他们也可以构建并发应用程序,代码如下所示。
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class Test07 {
private static final int POOL_SIZE = 10;
static class CalcThread implements Callable<Double> {
private List<Double> dataList = new ArrayList<>();
public CalcThread() {
for(int i = 0; i < 10000; ++i) {
dataList.add(Math.random());
}
}
@Override
public Double call() throws Exception {
double total = 0;
for(Double d : dataList) {
total += d;
}
return total / dataList.size();
}
}
public static void main(String[] args) {
List<Future<Double>> fList = new ArrayList<>();
ExecutorService es = Executors.newFixedThreadPool(POOL_SIZE);
for(int i = 0; i < POOL_SIZE; ++i) {
fList.add(es.submit(new CalcThread()));
}
for(Future<Double> f : fList) {
try {
System.out.println(f.get());
} catch (Exception e) {
e.printStackTrace();
}
}
es.shutdown();
}
}Callable接口也是一个单方法接口,显然这是一个回调方法,类似于函数式编程中的回调函数,在Java 8 以前,Java中还不能使用Lambda表达式来简化这种函数式编程。和Runnable接口不同的是Callable接口的回调方法call方法会返回一个对象,这个对象可以用将来时的方式在线程执行结束的时候获得信息。上面代码中的call方法就是将计算出的10000个0到1之间的随机小数的平均值返回,我们通过一个Future接口的对象得到了这个返回值。目前最新的Java版本中,Callable接口和Runnable接口都被打上了@FunctionalInterface的注解,也就是说它可以用函数式编程的方式(Lambda表达式)创建接口对象。
下面是Future接口的主要方法:
get():获取结果。如果结果还没有准备好,get方法会阻塞直到取得结果;当然也可以通过参数设置阻塞超时时间。
cancel():在运算结束前取消。
isDone():可以用来判断运算是否结束。
Java 7中还提供了分支/合并(fork/join)框架,它可以实现线程池中任务的自动调度,并且这种调度对用户来说是透明的。为了达到这种效果,必须按照用户指定的方式对任务进行分解,然后再将分解出的小型任务的执行结果合并成原来任务的执行结果。这显然是运用了分治法(pide-and-conquer)的思想。下面的代码使用了分支/合并框架来计算1到10000的和,当然对于如此简单的任务根本不需要分支/合并框架,因为分支和合并本身也会带来一定的开销,但是这里我们只是探索一下在代码中如何使用分支/合并框架,让我们的代码能够充分利用现代多核CPU的强大运算能力。
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
class Calculator extends RecursiveTask<Integer> {
private static final long serialVersionUID = 7333472779649130114L;
private static final int THRESHOLD = 10;
private int start;
private int end;
public Calculator(int start, int end) {
this.start = start;
this.end = end;
}
@Override
public Integer compute() {
int sum = 0;
if ((end - start) < THRESHOLD) { // 当问题分解到可求解程度时直接计算结果
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
int middle = (start + end) >>> 1;
// 将任务一分为二
Calculator left = new Calculator(start, middle);
Calculator right = new Calculator(middle + 1, end);
left.fork();
right.fork();
// 注意:由于此处是递归式的任务分解,也就意味着接下来会二分为四,四分为八...
sum = left.join() + right.join(); // 合并两个子任务的结果
}
return sum;
}
}
public class Test08 {
public static void main(String[] args) throws Exception {
ForkJoinPool forkJoinPool = new ForkJoinPool();
Future<Integer> result = forkJoinPool.submit(new Calculator(1, 10000));
System.out.println(result.get());
}
}伴随着Java 7的到来,Java中默认的数组排序算法已经不再是经典的快速排序(双枢轴快速排序)了,新的排序算法叫TimSort,它是归并排序和插入排序的混合体,TimSort可以通过分支合并框架充分利用现代处理器的多核特性,从而获得更好的性能(更短的排序时间)。
위 내용은 Java 동시 프로그래밍의 요약 및 사고에 대한 자세한 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7549
7549
 15
1382
52
83
11
58
19
22
90
15
1382
52
83
11
58
19
22
90


 자바의 웨카
Aug 30, 2024 pm 04:28 PM
자바의 웨카
Aug 30, 2024 pm 04:28 PM
Java의 Weka 가이드. 여기에서는 소개, weka java 사용 방법, 플랫폼 유형 및 장점을 예제와 함께 설명합니다.
 Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 Smith Number 가이드. 여기서는 정의, Java에서 스미스 번호를 확인하는 방법에 대해 논의합니다. 코드 구현의 예.
 Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
이 기사에서는 가장 많이 묻는 Java Spring 면접 질문과 자세한 답변을 보관했습니다. 그래야 면접에 합격할 수 있습니다.
 Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8은 스트림 API를 소개하여 데이터 컬렉션을 처리하는 강력하고 표현적인 방법을 제공합니다. 그러나 스트림을 사용할 때 일반적인 질문은 다음과 같은 것입니다. 기존 루프는 조기 중단 또는 반환을 허용하지만 스트림의 Foreach 메소드는이 방법을 직접 지원하지 않습니다. 이 기사는 이유를 설명하고 스트림 처리 시스템에서 조기 종료를 구현하기위한 대체 방법을 탐색합니다. 추가 읽기 : Java Stream API 개선 스트림 foreach를 이해하십시오 Foreach 메소드는 스트림의 각 요소에서 하나의 작업을 수행하는 터미널 작동입니다. 디자인 의도입니다
 Java의 날짜까지의 타임스탬프
Aug 30, 2024 pm 04:28 PM
Java의 날짜까지의 타임스탬프
Aug 30, 2024 pm 04:28 PM
Java의 TimeStamp to Date 안내. 여기서는 소개와 예제와 함께 Java에서 타임스탬프를 날짜로 변환하는 방법에 대해서도 설명합니다.
 캡슐의 양을 찾기위한 Java 프로그램
Feb 07, 2025 am 11:37 AM
캡슐의 양을 찾기위한 Java 프로그램
Feb 07, 2025 am 11:37 AM
캡슐은 3 차원 기하학적 그림이며, 양쪽 끝에 실린더와 반구로 구성됩니다. 캡슐의 부피는 실린더의 부피와 양쪽 끝에 반구의 부피를 첨가하여 계산할 수 있습니다. 이 튜토리얼은 다른 방법을 사용하여 Java에서 주어진 캡슐의 부피를 계산하는 방법에 대해 논의합니다. 캡슐 볼륨 공식 캡슐 볼륨에 대한 공식은 다음과 같습니다. 캡슐 부피 = 원통형 볼륨 2 반구 볼륨 안에, R : 반구의 반경. H : 실린더의 높이 (반구 제외). 예 1 입력하다 반경 = 5 단위 높이 = 10 단위 산출 볼륨 = 1570.8 입방 단위 설명하다 공식을 사용하여 볼륨 계산 : 부피 = π × r2 × h (4
 Spring Tool Suite에서 첫 번째 Spring Boot 응용 프로그램을 실행하는 방법은 무엇입니까?
Feb 07, 2025 pm 12:11 PM
Spring Tool Suite에서 첫 번째 Spring Boot 응용 프로그램을 실행하는 방법은 무엇입니까?
Feb 07, 2025 pm 12:11 PM
Spring Boot는 강력하고 확장 가능하며 생산 가능한 Java 응용 프로그램의 생성을 단순화하여 Java 개발에 혁명을 일으킨다. Spring Ecosystem에 내재 된 "구성에 대한 협약"접근 방식은 수동 설정, Allo를 최소화합니다.
