
본 글은 Java의 HashMap 구현 원리를 심도 있게 이해하기 위한 관련 정보를 주로 소개하고 있습니다. 필요한 친구들은
1. HashMap
의 데이터 구조에는 데이터를 저장하는 배열과 연결 목록이 포함되어 있지만 이 두 가지는 기본적으로 두 가지 극단입니다.어레이
어레이 저장 간격이 연속적이고 많은 메모리를 차지하므로 공간이 매우 복잡합니다. 그러나 배열의이진 검색은 시간 복잡도가 낮습니다. O(1) 배열의 특징은 다음과 같습니다. 주소 지정이 쉽고 삽입 및 삭제가 어렵습니다.
연결된 목록
연결된 목록의 저장 간격이 이산적이고 점유 메모리가 비교적 느슨하므로 공간 복잡도는 매우 작지만 시간 복잡도는 매우 커서 O에 도달합니다. (N).연결리스트의 특징은 주소 지정이 어렵고 삽입 및 삭제가 쉽다는 것입니다.
해시 테이블
그럼 둘의 특성을 결합하여 주소 지정이 쉽고 삽입 및 삭제가 쉬운 데이터 구조를 만들 수 있을까요? 대답은 '예'입니다. 이것이 우리가 언급할 해시 테이블입니다. 해시 테이블(Hash table)은 데이터 검색의 편의성을 충족할 뿐만 아니라, 콘텐츠 공간을 많이 차지하지 않아 사용이 매우 편리합니다. 해시 테이블의 구현 방법은 다양합니다. 설명은 가장 일반적으로 사용되는 방법 중 하나인 지퍼 방법으로, 그림과 같이 "연결 목록 배열"으로 이해할 수 있습니다.
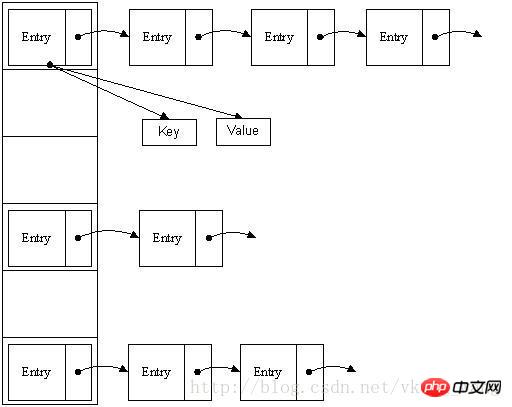
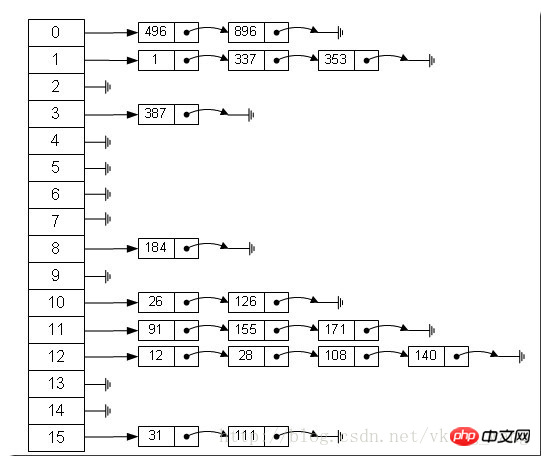
배열 + 연결 리스트로 구성된 길이의 배열을 확인할 수 있습니다. 16, 각 요소는 연결된 목록의 헤드 노드를 저장합니다. 그러면 이러한 요소는 어떤 규칙에 따라 배열에 저장됩니까? 일반적으로 hash(key)%len에 의해 얻어집니다. 즉, 요소 키의 해시 값은 다음과 같습니다. 예를 들어 위의 해시 테이블에서는 12%16=12, 28%16=12, 108%16=12, 140%16=12이므로 12, 28, 108, 140이 모두 저장됩니다. 🎜>HashMap은 실제로 선형 배열로 구현되므로 데이터를 저장하는 컨테이너가 선형 배열인 것으로 이해될 수 있습니다. 선형 배열이 어떻게 키-값으로 데이터에 액세스할 수 있는지 혼란스러울 수 있습니다. 먼저 HashMap은 정적
내부 클래스 항목을 구현합니다.속성에는
key, value, next가 포함됩니다. Entry는 HashMap 키-값 쌍 구현을 위한 기본 Bean인 속성 키와 값에서 볼 수 있듯이 위에서 언급한 것처럼 HashMap의 기본은 선형 배열이며 Map의 내용은 다음과 같습니다. Entry[]에 저장됩니다. 2. HashMap 접근 구현 HashMap은 선형 배열인데 왜 작은 랜덤 접근 방식을 사용할 수 있나요? 대략적으로 다음과 같이 구현됩니다:
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry[] table;1) put
질문: hash%Entry[].length를 통해 두 키로 얻은 인덱스가 동일하다면, 잘못될 위험이 있나요? HashMap에서는 체인형 데이터 구조의 개념이 사용됩니다. 위에서 Entry 클래스에 다음 항목을 가리키는 다음 속성이 있다고 언급했습니다. 예를 들어 첫 번째 키-값 쌍 A가 들어오고 해당 키의 해시를 계산하여 얻은 index=0은 Entry[0] = A로 기록됩니다. 잠시 후 또 다른 키-값 쌍 B가 들어오고, 계산을 통해 그 인덱스도 0이 됩니다. 이제 어떻게 해야 할까요? HashMap은 다음을 수행합니다:B.next = A,Entry[0] = B. C가 다시 들어오면 인덱스도 0이 되고 C.next = B
,Entry[0 ] = C; 이런 식으로 index=0인 곳이 실제로 3개의 키-값 쌍인 A, B, C에 접근하고, 다음 속성을 통해 서로 연결되어 있음을 알 수 있습니다. 궁금한 점이 있으면 걱정하지 마세요.즉, 마지막으로 삽입된 요소가 배열에 저장됩니다.
이제 우리는 HashMap의 일반적인 구현을 명확하게 이해해야 합니다.// 存储时: int hash = key.hashCode(); // 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值 int index = hash % Entry[].length; Entry[index] = value; // 取值时: int hash = key.hashCode(); int index = hash % Entry[].length; return Entry[index];
public V put(K key, V value) {
if (key == null)
return putForNullKey(value); //null总是放在数组的第一个链表中
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//遍历链表
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果key在链表中已存在,则替换为新value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}3) Null 키 액세스
null 키는 항상 Entry[]에 저장됩니다. 배열의 요소입니다.
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);//参数e, 是Entry.next
//如果size超过threshold,则扩充table大小。再散列
if (size++ >= threshold)
resize(2 * table.length);
}4) 배열 인덱스 결정: hashcode % table.length 모듈로
HashMap에 액세스할 때 Entry[] 배열의 어떤 요소가 현재인지 계산해야 합니다. 키는 에 해당해야 합니다. 즉, 배열 첨자를 계산하는 알고리즘은 다음과 같습니다.public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
//先定位到数组元素,再遍历该元素处的链表
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}배열 첨자가 동일하다는 뜻이지만, 해시코드가 동일하다는 의미는 아닙니다.
5)table初始大小
public HashMap(int initialCapacity, float loadFactor) {
.....
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}注意table初始大小并不是构造函数中的initialCapacity!!
而是 >= initialCapacity的2的n次幂!!!!
————为什么这么设计呢?——
3. 解决hash冲突的办法开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列) 再哈希法 链地址法 建立一个公共溢出区
Java中hashmap的解决办法就是采用的链地址法。
4. 再散列rehash过程
当哈希表的容量超过默认容量时,必须调整table的大小。当容量已经达到最大可能值时,那么该方法就将容量调整到Integer.MAX_VALUE返回,这时,需要创建一张新表,将原表的映射到新表中。
/**
* Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
*
* If current capacity is MAXIMUM_CAPACITY, this method does not
* resize the map, but sets threshold to Integer.MAX_VALUE.
* This has the effect of preventing future calls.
*
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
//重新计算index
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}위 내용은 Java의 HashMap 구현 원리에 대한 심층적 이해(그림)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



