
HashSet과 HashMap, 그리고 TreeSet과 TreeMap에 대한 이전 글을 읽어보셨다면 설명을 하자면, 이 글에서 설명하는 LinkedHashSet과 LinkedHashMap은 사실 같은 것이라고 생각하시면 됩니다. LinkedHashSet 및 LinkedHashMap도 Java에서 동일한 구현을 갖습니다. 전자는 후자를 래핑합니다. 즉, LinkedHashSet 내부에 이 있습니다. LinkedHashMap(어댑터 패턴) . 따라서 이번 글에서는 LinkedHashMap을 분석하는 데 중점을 두겠습니다.
LinkedHashMap은 Map 인터페이스를 구현하여 key이 있는 요소를 null로 삽입하고 value이 있는 요소를 null으로 삽입할 수 있습니다. 삽입됩니다. 이름에서 알 수 있듯이 컨테이너는 linked list와 HashMap이 혼합되어 있어 HashMap을 모두 만족한다는 의미입니다. 그리고 연결리스트의 일부 기능. LinkedHashMap을 연결 목록으로 강화된 HashMap이라고 생각해 보세요.
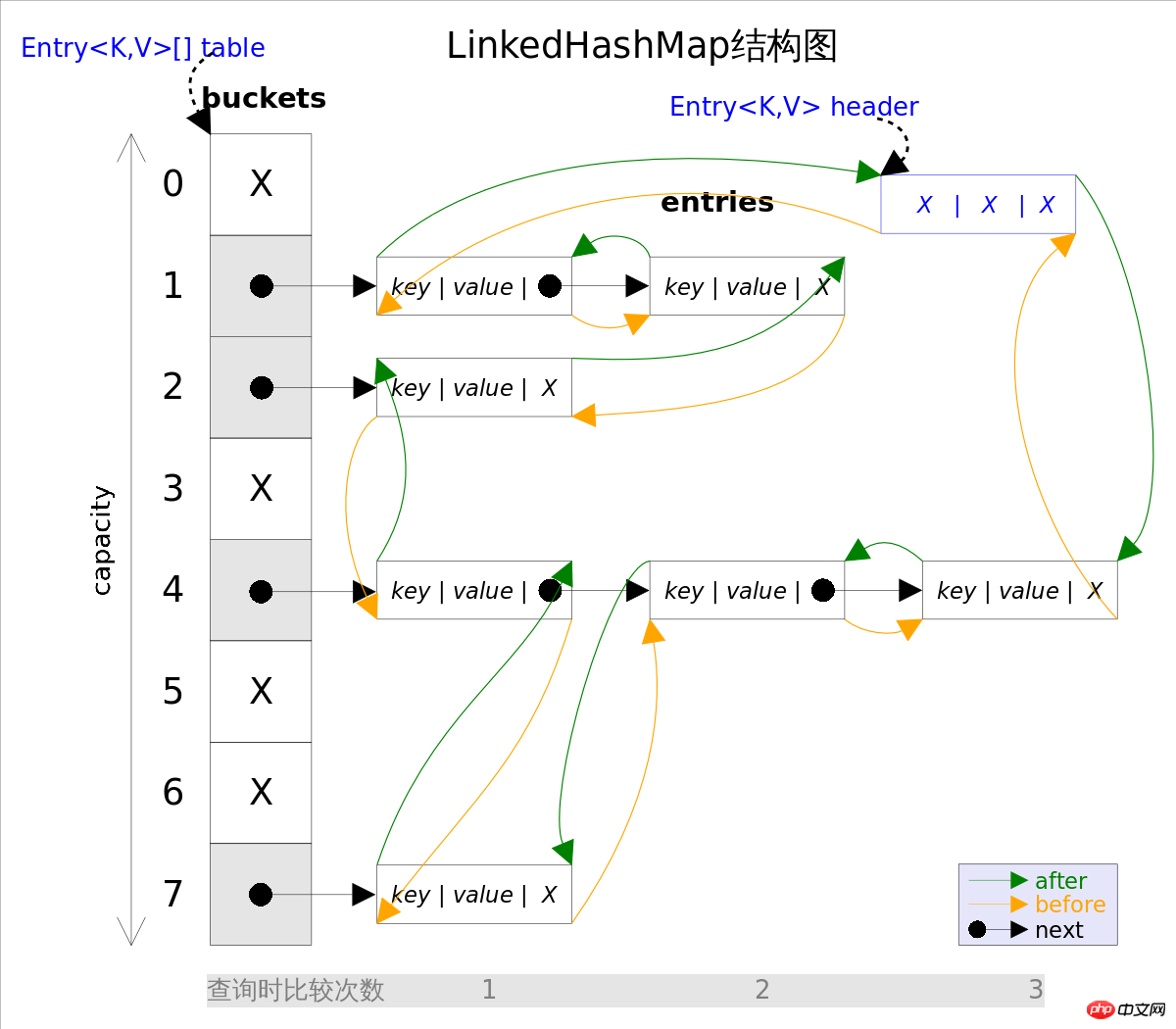
사실 LinkedHashMap은 HashMap의 직접적인 하위 클래스입니다. 두 클래스의 유일한 차이점은 isLinkedHashMap은 HashMap을 기반으로 하며 이중 연결 목록을 사용하여 모든 entry을 연결합니다. 이는 요소의 반복 순서가 삽입 순서와 동일하도록 하기 위한 것입니다. . 위 그림은 LinkedHashMap의 구조 다이어그램을 보여줍니다. 주요 부분은 HashMap과 완전히 동일하며, 이중 연결 목록의 선두를 가리키는 header이 추가됩니다. 는 더미 요소), 이중 연결 리스트의 반복 순서는 entry의 삽입 순서 입니다.
이 구조에는 반복 순서를 유지하는 것 외에도 또 다른 이점이 있습니다. LinkedHashMap의 반복에서는 HashMap처럼 전체 table을 탐색할 필요가 없습니다. 그리고 header 이 가리키는 이중 연결 리스트만 직접 순회하면 됩니다. 즉, LinkedHashMap의 반복 시간은 entry의 개수에만 관련되고 아무것도 없다는 의미입니다. table 의 크기와 관련이 있습니다.
LinkedHashMap의 성능에 영향을 미칠 수 있는 두 가지 매개변수는 초기 용량과 부하율입니다. 초기 용량은 table의 초기 크기를 지정하고 부하율은 자동 확장에 대한 임계 값을 지정하는 데 사용됩니다. entry 개수가 capacity*load_factor개를 초과하면 컨테이너가 자동으로 확장되고 다시 해시됩니다. 많은 수의 요소가 삽입되는 시나리오의 경우 초기 용량을 더 크게 설정하면 재해시 횟수를 줄일 수 있습니다.
이 객체 를 LinkedHashMap 또는 LinkedHashSet에 넣을 때 특별한 주의가 필요한 두 가지 방법이 있습니다: hashCode() 및 equals() . hashCode() 메서드는 개체가 어느 bucket에 배치될지 결정합니다. 여러 개체의 해시 값이 충돌하는 경우 equals() 메서드는 이러한 개체가 "동일 개체"인지 여부를 확인합니다. 따라서 LinkedHashMap 또는 LinkedHashSet에 사용자 정의 개체를 넣으려면 *@Override*hashCode() 및 equals() 메서드가 필요합니다.
다음과 같이 소스 Map과 동일한 반복 순서를 사용하여 LinkedHashMap을 얻을 수 있습니다. 성능을 위해
void foo(Map m) {
Map copy = new LinkedHashMap(m);
}이유는 LinkedHashMap이 비동기식(동기화되지 않음)이기 때문에 다중 스레드 환경에서 사용해야 하는 경우 프로그래머가 수동으로 동기화하거나 LinkedHashMap을 패키지해야 합니다. 다음과 같은 방식으로 (래핑) 동기식:
Map m = Collections.synchronizedMap(new LinkedHashMap(...));
get(<code>get(<a href="http://www.php.cn/wiki/60.html" target="_blank">Object</a> key)Object key 키) 메소드는 지정된 value 값을 기반으로 해당 HashMap.get()을 반환합니다. 이 방법의 프로세스는
put(K key, V value)key, value 메소드는 지정된 map 쌍을 map에 추가합니다. 이 메소드는 먼저 get()를 검색하여 튜플이 포함되어 있으면 직접 반환합니다. 검색 프로세스는 addEntry(int hash, K key, V value, int bucketIndex) 메소드와 유사합니다. 🎜> 메소드를 통해 삽입됩니다. entry
삽입에는 두 가지 의미가 있습니다. :
의 관점에서 보면 새로운
table해시 충돌이 있는 경우 충돌 연결 리스트의 헤드에 새로운entry을 삽입하는 방식을 사용합니다.bucket从
header的角度看,新的entry需要插入到双向链表的尾部。
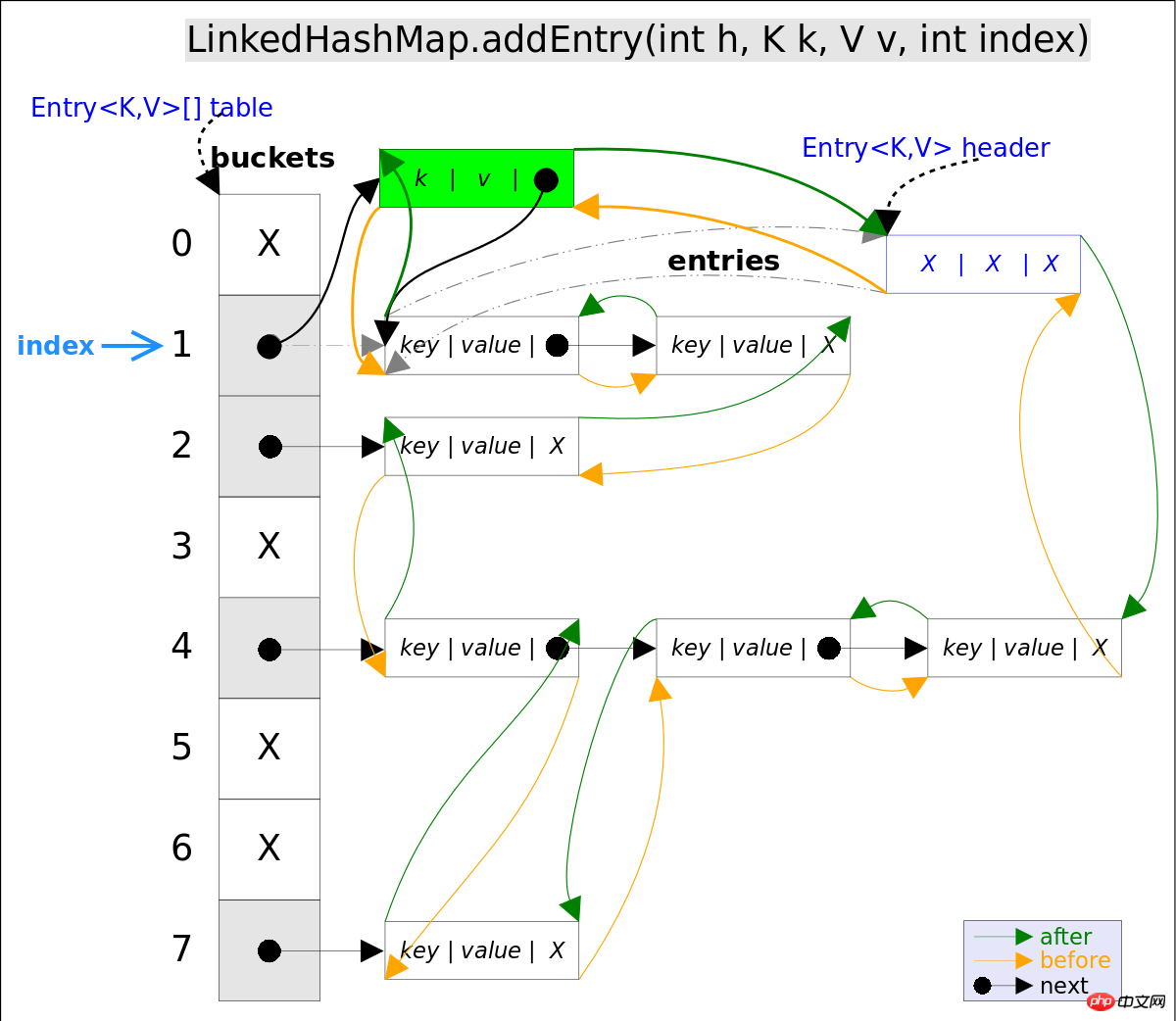
addEntry()代码如下:
// LinkedHashMap.addEntry()
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);// 自动扩容,并重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);// hash%table.length
}
// 1.在冲突链表头部插入新的entry
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
// 2.在双向链表的尾部插入新的entry
e.addBefore(header);
size++;
}上述代码中用到了addBefore()方法将新entry e插入到双向链表头引用header的前面,这样e就成为双向链表中的最后一个元素。addBefore()的代码如下:
// LinkedHashMap.Entry.addBefor(),将this插入到existingEntry的前面
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}上述代码只是简单修改相关entry的引用而已。
remove(Object key)的作用是删除key值对应的entry,该方法的具体逻辑是在removeEntryForKey(Object key)里实现的。removeEntryForKey()方法会首先找到key值对应的entry,然后删除该entry(修改链表的相应引用)。查找过程跟get()方法类似。
注意,这里的删除也有两重含义:
从
table的角度看,需要将该entry从对应的bucket里删除,如果对应的冲突链表不空,需要修改冲突链表的相应引用。从
header的角度来看,需要将该entry从双向链表中删除,同时修改链表中前面以及后面元素的相应引用。

removeEntryForKey()对应的代码如下:
// LinkedHashMap.removeEntryForKey(),删除key值对应的entry
final Entry<K,V> removeEntryForKey(Object key) {
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);// hash&(table.length-1)
Entry<K,V> prev = table[i];// 得到冲突链表
Entry<K,V> e = prev;
while (e != null) {// 遍历冲突链表
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {// 找到要删除的entry
modCount++; size--;
// 1. 将e从对应bucket的冲突链表中删除
if (prev == e) table[i] = next;
else prev.next = next;
// 2. 将e从双向链表中删除
e.before.after = e.after;
e.after.before = e.before;
return e;
}
prev = e; e = next;
}
return e;
}前面已经说过LinkedHashSet是对LinkedHashMap的简单包装,对LinkedHashSet的函数调用都会转换成合适的LinkedHashMap方法,因此LinkedHashSet的实现非常简单,这里不再赘述。
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
// LinkedHashSet里面有一个LinkedHashMap
public LinkedHashSet(int initialCapacity, float loadFactor) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
public boolean add(E e) {//简单的方法转换
return map.put(e, PRESENT)==null;
}
}위 내용은 Java 수집 프레임워크 LinkedHashSet 및 LinkedHashMap 소스 코드 분석에 대한 자세한 설명(그림)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



