
이 글은 주로 Java에서 Cassandra 고급 작업을 구현하는 페이징 예제를 소개합니다(특정 프로젝트 요구 사항 포함). 관심 있는 친구들은 이를 참조할 수 있습니다.
카산드라 페이징에 대해 지난 블로그에서 이야기한 바 있습니다. 모두가 이에 주의할 것입니다. 다음 쿼리는 이전 쿼리에 따라 달라집니다(이전 쿼리에서 마지막 레코드의 모든 기본 키). mysql만큼 유연하지 않아 이전 페이지, 다음 페이지 등의 기능만 구현할 수 있고, 페이지 번호 등의 기능은 구현할 수 없습니다(억지로 하면 성능이 너무 저하됩니다). 구현).
먼저 드라이버
의 공식 페이징 방식을 살펴보자. 쿼리로 얻은 레코드의 개수가 너무 많아 한번에 반환되는 경우 효율성이 떨어진다. 매우 낮고 매우 메모리 오버플로를 유발하고 전체 애플리케이션이 중단될 수 있습니다. 따라서 드라이버는 결과 집합의 페이지를 매기고 적절한 데이터 페이지를 반환합니다.
1. 가져오기 크기 설정
가져오기 크기는 Cassandra에서 한 번에 가져온 레코드 수를 의미합니다. 각 페이지의 레코드 수입니다. 클러스터 인스턴스를 생성할 때 가져오기 크기에 대한 기본값을 지정할 수 있습니다. 지정하지 않으면 기본값은 5000
// At initialization:
Cluster cluster = Cluster.builder()
.addContactPoint("127.0.0.1")
.withQueryOptions(new QueryOptions().setFetchSize(2000))
.build();
// Or at runtime:
cluster.getConfiguration().getQueryOptions().setFetchSize(2000);입니다. 또한 다음 명령문을 설정할 수도 있습니다. 가져오기 크기
Statement statement = new SimpleStatement("your query");
statement.setFetchSize(2000);문에 가져오기 크기가 설정된 경우 문의 가져오기 크기가 적용되고, 그렇지 않으면 클러스터의 가져오기 크기가 적용됩니다.
참고: 가져오기 크기를 설정한다고 해서 Cassandra가 항상 정확한 결과 집합(가져오기 크기와 동일)을 반환한다는 의미는 아니며 가져오기 크기보다 약간 크거나 작은 결과 집합을 반환할 수 있습니다.
2. 결과 세트 반복
가져오기 크기는 각 페이지에 대해 반환되는 결과 세트 수를 제한합니다. 드라이버는 백그라운드에서 레코드의 다음 페이지를 자동으로 캡처합니다. 다음 예와 같이 fetch size = 20:
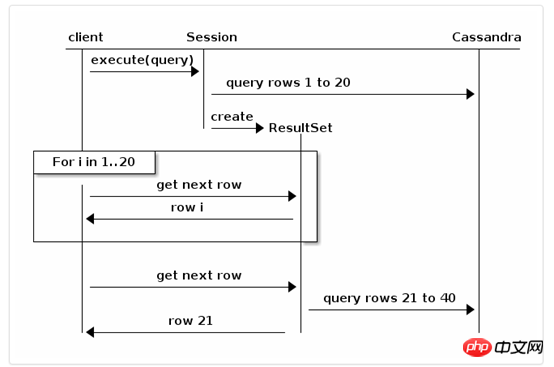
기본적으로 백그라운드 자동 가져오기는 마지막 순간, 즉 특정 페이지의 레코드가 반복. 더 나은 제어가 필요한 경우 ResultSet인터페이스는 다음 메소드를 제공합니다.
getAvailableWithoutFetching() and isFullyFetched() to check the current state; fetchMoreResults() to force a page fetch;
다음은 이러한 메소드를 사용하여 다음 페이지를 미리 가져오는 방법입니다. 특정 페이지가 반복됩니다. 다음 페이지를 잡아서 발생하는 성능 저하:
ResultSet rs = session.execute("your query");
for (Row row : rs) {
if (rs.getAvailableWithoutFetching() == 100 && !rs.isFullyFetched())
rs.fetchMoreResults(); // this is asynchronous
// Process the row ...
System.out.println(row);
}객체를 노출합니다.
ResultSet resultSet = session.execute("your query");
// iterate the result set...
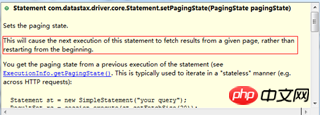
PagingState pagingState = resultSet.getExecutionInfo().getPagingState();
// PagingState对象可以被序列化成字符串或字节数组
String string = pagingState.toString();
byte[] bytes = pagingState.toBytes();PagingState.fromBytes(byte[] bytes); PagingState.fromString(String str);
각er 테이블의 모든 레코드 순회를 구현하기 위한 요청입니다.
인터페이스:
import java.util.Map;
import com.datastax.driver.core.PagingState;
public interface ICassandraPage
{
Map<String, Object> page(PagingState pagingState);
}import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import com.datastax.driver.core.PagingState;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Row;
import com.datastax.driver.core.Session;
import com.datastax.driver.core.SimpleStatement;
import com.datastax.driver.core.Statement;
import com.huawei.cassandra.dao.ICassandraPage;
import com.huawei.cassandra.factory.SessionRepository;
import com.huawei.cassandra.model.Teacher;
public class CassandraPageDao implements ICassandraPage
{
private static final Session session = SessionRepository.getSession();
private static final String CQL_TEACHER_PAGE = "select * from mycas.teacher;";
@Override
public Map<String, Object> page(PagingState pagingState)
{
final int RESULTS_PER_PAGE = 2;
Map<String, Object> result = new HashMap<String, Object>(2);
List<Teacher> teachers = new ArrayList<Teacher>(RESULTS_PER_PAGE);
Statement st = new SimpleStatement(CQL_TEACHER_PAGE);
st.setFetchSize(RESULTS_PER_PAGE);
// 第一页没有分页状态
if (pagingState != null)
{
st.setPagingState(pagingState);
}
ResultSet rs = session.execute(st);
result.put("pagingState", rs.getExecutionInfo().getPagingState());
//请注意,我们不依赖RESULTS_PER_PAGE,因为fetch size并不意味着cassandra总是返回准确的结果集
//它可能返回比fetch size稍微多一点或者少一点,另外,我们可能在结果集的结尾
int remaining = rs.getAvailableWithoutFetching();
for (Row row : rs)
{
Teacher teacher = this.obtainTeacherFromRow(row);
teachers.add(teacher);
if (--remaining == 0)
{
break;
}
}
result.put("teachers", teachers);
return result;
}
private Teacher obtainTeacherFromRow(Row row)
{
Teacher teacher = new Teacher();
teacher.setAddress(row.getString("address"));
teacher.setAge(row.getInt("age"));
teacher.setHeight(row.getInt("height"));
teacher.setId(row.getInt("id"));
teacher.setName(row.getString("name"));
return teacher;
}
}import java.util.Map;
import com.datastax.driver.core.PagingState;
import com.huawei.cassandra.dao.ICassandraPage;
import com.huawei.cassandra.dao.impl.CassandraPageDao;
public class PagingTest
{
public static void main(String[] args)
{
ICassandraPage cassPage = new CassandraPageDao();
Map<String, Object> result = cassPage.page(null);
PagingState pagingState = (PagingState) result.get("pagingState");
System.out.println(result.get("teachers"));
while (pagingState != null)
{
// PagingState对象可以被序列化成字符串或字节数组
System.out.println("==============================================");
result = cassPage.page(pagingState);
pagingState = (PagingState) result.get("pagingState");
System.out.println(result.get("teachers"));
}
}
}
4. 오프셋 쿼리
페이징 상태를 저장하면 한 페이지에서 다음 페이지로의 이동이 잘 이루어지도록 할 수 있지만(이전 페이지도 구현 가능) 10페이지로 직접 점프하는 등의 무작위 점프는 만족하지 않습니다. 10페이지 이전 페이지의 페이징 상태를 알 수 없습니다. 오프셋 쿼리가 필요한 이와 같은 기능은 기본적으로 Cassandra에서 지원되지 않습니다. 그 이유는 오프셋 쿼리가 비효율적이기 때문입니다(성능은 건너뛴 행 수에 선형적으로 반비례함). 따라서 Cassandra는 공식적으로 오프셋 사용을 권장하지 않습니다. 오프셋 쿼리를 구현해야 하는 경우 클라이언트 측에서 이를 시뮬레이션할 수 있습니다. 그러나 성능은 여전히 선형적으로 반비례합니다. 즉, 오프셋이 클수록 성능이 허용 범위 내에 있으면 여전히 달성할 수 있습니다. 예를 들어, 각 페이지는 10줄을 표시하며 최대 20페이지를 표시할 수 있습니다. 즉, 20번째 페이지를 표시할 때 최대 190줄을 추가로 가져와야 하지만 이로 인해 성능이 크게 저하되지는 않습니다. , 데이터 양이 크지 않은 경우에도 오프셋 쿼리를 시뮬레이션하는 것이 가능합니다.
예를 들어 각 페이지에 10개의 레코드가 표시되고 가져오기 크기가 50이라고 가정하면 12페이지(즉, 110~119행)를 요청합니다.
1 먼저 쿼리를 한 번 실행합니다. , 결과 집합에는 0~49행이 포함됩니다. 이를 사용할 필요는 없으며 페이징 상태만 필요합니다.
2. 두 번째 쿼리를 실행하려면 첫 번째 쿼리에서 얻은 페이징 상태를 사용하세요. 🎜 >
3. 두 번째 쿼리에서 얻은 페이징 상태를 사용하여 세 번째 쿼리를 실행합니다. 결과 집합에는 100~149개의 행이 포함됩니다. 4. 세 번째 쿼리에서 얻은 결과 집합을 사용하여 먼저 처음 10개 레코드를 필터링한 다음 10개 레코드를 읽고 마지막으로 나머지 레코드를 삭제하고 10개를 읽습니다. 레코드는 12페이지에 표시되어야 하는 레코드입니다. 가장 좋은 가져오기 크기를 찾으려고 노력해야 합니다. 너무 작으면 백그라운드에 더 많은 쿼리가 반환되고, 너무 크면 더 많은 양의 정보가 반환되고 불필요한 OK가 더 많이 반환됩니다. 또한 Cassandra 자체는 오프셋 쿼리를 지원하지 않습니다. 성능 만족을 전제로 클라이언트 측 시뮬레이션 오프셋 구현은 절충안일 뿐입니다. 공식 권장 사항은 다음과 같습니다. 1. 예상되는 쿼리 패턴을 사용하여 코드를 테스트하여 가정이 올바른지 확인합니다. 2. 악의적인 사용자가 대규모 건너뛰기 행 쿼리 실행5. 요약
Cassandra는 페이징 지원이 제한되어 있으며 이전 페이지와 다음 페이지가 구현하기 더 쉽습니다. . 오프셋 쿼리는 지원되지 않습니다. 구현을 고집하는 경우 클라이언트 시뮬레이션을 사용할 수 있습니다. 그러나 Cassandra는 일반적으로 빅 데이터 문제를 해결하는 데 사용되므로 이 시나리오는 사용하지 않는 것이 가장 좋습니다. 쿼리가 너무 크면 성능을 칭찬할 수 없습니다. 내 프로젝트에서index 복구는 cassandra의 페이징을 사용합니다. 시나리오는 다음과 같습니다. cassandra 테이블에는 보조 인덱스가 없으며 elasticsearch는 cassandra의 보조 인덱스를 구현하는 데 사용됩니다. 그런 다음 인덱스 일관성 복구 문제가 발생합니다. 여기에서는 Cassandra 페이징을 사용하여 Cassandra 테이블의 전체 테이블을 탐색하고 Elasticsearch의 데이터와 하나씩 일치시킵니다. 을 추가하세요. 존재하지만 일관성이 없으면 Elasticsearch에서 수정하세요. Elasticsearch가 Cassandra의 인덱싱 기능을 구현하는 방법은 다음 블로그에서 구체적으로 설명할 것이므로 여기에서는 자세히 다루지 않겠습니다. 카산드라 테이블 전체를 순회할 때 테이블에 포함된 데이터의 양이 너무 많고, 수억 개의 데이터를 한번에 메모리에 로드하는 것이 불가능하기 때문에 페이징이 필요하다.
위 내용은 Java는 Cassandra 고급 작업의 페이징 예를 구현합니다(그림).의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



