
목차이전 기사 노드 진입 시나리오 - 크롤러에서는 가장 간단한 노드 크롤러 구현을 소개했습니다. 이 기사에서는 원래 기반으로 더 나아가 로그인을 우회하고 로그인 영역에서 데이터를 크롤링하는 방법에 대해 설명합니다. 🎜>
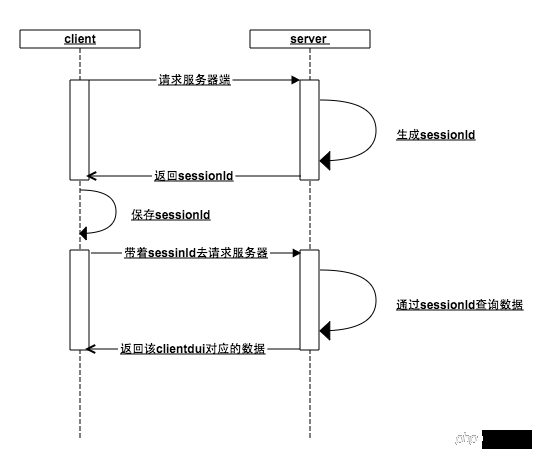 클라이언트는 서버에서 sessionId를 가져와 로컬에 저장하고 다음 요청 시 이 sessionId를 가져옵니다. , 서버는 메모리를 확인합니다. 이 sessionId가 존재합니까? (
클라이언트는 서버에서 sessionId를 가져와 로컬에 저장하고 다음 요청 시 이 sessionId를 가져옵니다. , 서버는 메모리를 확인합니다. 이 sessionId가 존재합니까? (
이전 단계에서 사용자가 로그인 인터페이스에 액세스한 경우 현재 seesionId가
로 메모리에 저장되어 있습니다. 사용자 데이터는 값으로 메모리에 저장되었으며, 서버는 sessionId
의 고유 식별자를 기반으로 클라이언트에 해당하는 데이터를 반환할 수 있습니다. 서버가 sessionId를 잃으면 이전 단계가 반복됩니다. 더 이상 아는 사람이 없습니다.브라우저에서는 어떻게 수행하나요? 실제로 브라우저는 위의 내용을 따르나요? 메커니즘 디자인은 어떻습니까? 사실이에요!
2. 브라우저는 서버 응답 헤더의브라우저가 수행하는 작업:
1. , 요청 주소의 도메인 이름에 해당하는 쿠키가 http 요청 헤더에 추가됩니다(사용자가 쿠키를 비활성화하지 않은 경우). 위 그림에서 서버에 대한 첫 번째 요청에도 요청에 쿠키가 포함되어 있습니다. 헤더가 있지만 쿠키에는 아직 sessionId가 없습니다
브라우저가 Set-Cookie 명령을 받으면 요청 주소의 도메인 이름을 키로 사용하여 로컬 쿠키를 설정합니다. 일반적으로 서버가 Set-를 반환합니다. 쿠키의 경우 sessionId의 만료 시간은 기본적으로 브라우저가 닫히도록 설정되어 있습니다. 브라우저가 열릴 때 만료됩니다. 따라서 브라우저는 열릴 때부터 닫힐 때까지 세션입니다(일부 웹사이트에서는 로그인 상태를 유지하도록 설정할 수도 있음). 오랫동안 만료되지 않는 쿠키 설정)
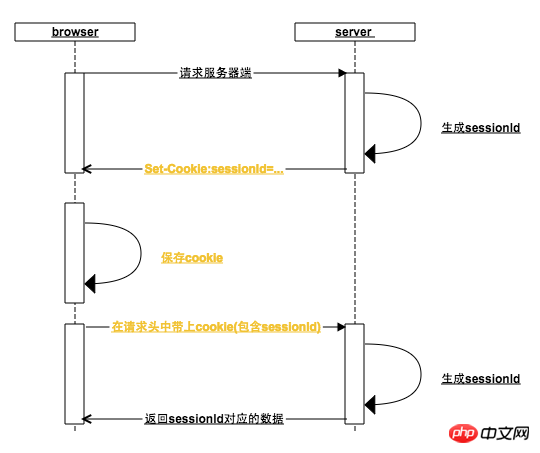 3. 브라우저가 다시 열릴 때 요청이 백그라운드에서 시작되면 요청 헤더의 쿠키에 이미 sessionId가 포함되어 있습니다. 이전에 로그인 인터페이스를 방문한 경우 세션 ID를 기반으로 사용자 데이터를
3. 브라우저가 다시 열릴 때 요청이 백그라운드에서 시작되면 요청 헤더의 쿠키에 이미 sessionId가 포함되어 있습니다. 이전에 로그인 인터페이스를 방문한 경우 세션 ID를 기반으로 사용자 데이터를
쿼리
1) 먼저 로그인을 사용하세요.
chr
ome에 의해 열린 페이지에서 http://www.jianshu.com에 있는 모든 파일을 응용 프로그램 쿠키에서 찾으려면 네트워크 항목을 입력하고 로그 보존을 확인하세요(그렇지 않으면 해당 파일을 볼 수 없습니다). 페이지가 리디렉션된 후 이전 로그)
로그인
2) 그런 다음 페이지를 새로 고치고 로그인 인터페이스를 찾으세요. 응답 헤더에 많은 Set-Cookies가 있습니다. 로그인 3) 쿠키를 다시 확인하시면 세션ID가 저장되어 있으니 다음에 요청하시면 됩니다기타 인터페이스 사용 시(예: 인증 코드 받기, 로그인) 로그인 후 사용자 정보도 세션 ID와 연결됩니다 로그인 브라우저의 작동 모드를 시뮬레이션하고 로그인에서 데이터를 크롤링해야 합니다. 해당 웹사이트 영역 요청 헤더 정보를 얻으려면 Chrome에서 요청을 캡처해야 합니다. 서버는 이러한 요청 헤더 정보를 확인할 수 있습니다. 예를 들어, 제가 실험한 웹사이트에서는 처음에 User-Agent를 전달하지 않았습니다. 서버에서 요청이 서버에서 온 것이 아니라는 것을 발견하고 오류 메시지 문자열을 반환했기 때문에 나중에 User-Agent를 설정하고 크롬 브라우저인 척 했어요~~ superagent는 클라이언트측 HTTP 요청 라이브러리로 쉽게 요청을 보내고 쿠키를 처리할 수 있습니다. (http.request를 직접 호출하여 조작해야 합니다. 헤더 필드 데이터는 그다지 편리하지 않습니다. set-cookie를 얻은 후 이를 적절한 형식의 쿠키로 조립해야 합니다.) Redirects(0)는 주로 리디렉션을 설정하지 않습니다 이전 단계에서 set-cookie를 가져온 후 getData 메소드, 슈퍼에이전트를 통해 요청에 설정한 후(set-cookie는 쿠키로 형식화됨) 일반적으로 로그인 데이터를 가져올 수 있습니다 실제 시나리오에서는 그다지 원활하지 않을 수 있습니다 웹사이트마다 보안 조치가 다릅니다. 예를 들어 일부 웹사이트는 먼저 토큰을 요청해야 하고, 일부 웹사이트는 매개변수를 암호화해야 하며, 일부 웹사이트는 더 높은 보안 및 재생 방지 메커니즘을 갖추고 있습니다. 방향성 크롤러에서는 웹사이트의 처리 메커니즘에 대한 상세한 분석이 필요합니다. 피할 수 없다면 충분합니다~~ 위의 방법을 통해 요청한 것은 html문자열의 일부일 뿐입니다. 여기서는 이전 방법을 사용하여 문자열을 로드하면 jquery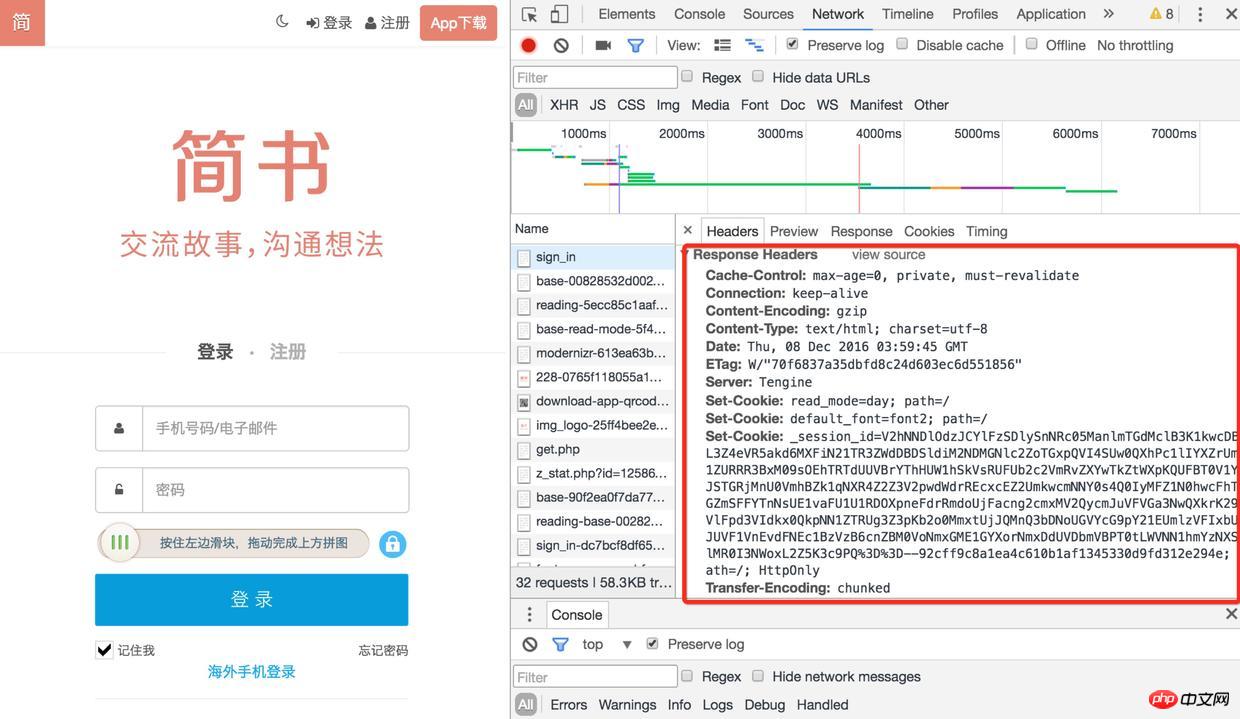
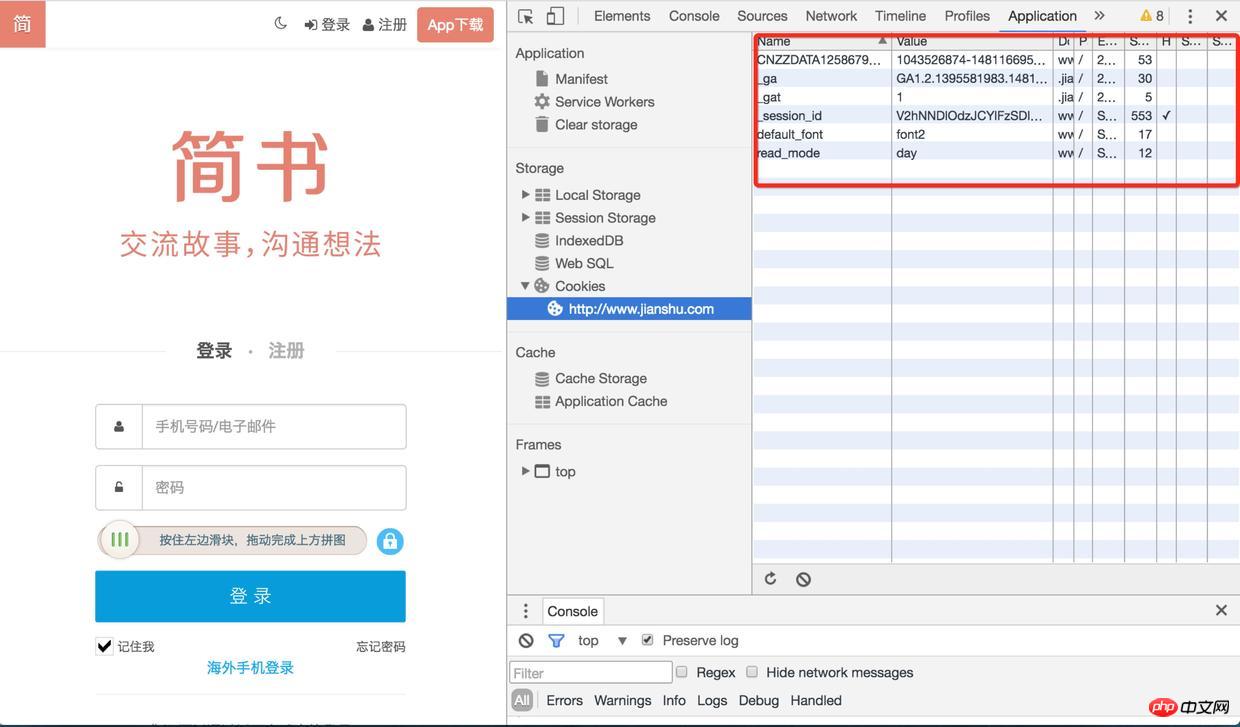
2. 노드 구현
인증 없이 발견했습니다. 인증 코드가 있는 경우 인증 코드 식별이 포함됩니다. (로그인은 고려되지 않으며 인증 코드의 복잡성이 인상적입니다.) . 다음 섹션에서는 쿠키를 얻기 위해 로그인 인터페이스에 액세스
// 浏览器请求报文头部部分信息
var browserMsg={
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36",
'Content-Type':'application/x-www-form-urlencoded'
};
//访问登录接口获取cookie
function getLoginCookie(userid, pwd) {
userid = userid.toUpperCase();
return new Promise(function(resolve, reject) {
superagent.post(url.login_url).set(browserMsg).send({
userid: userid,
pwd: pwd,
timezoneOffset: '0'
}).redirects(0).end(function (err, response) {
//获取cookie
var cookie = response.headers["set-cookie"];
resolve(cookie);
});
});
}
로그인 영역에서 인터페이스를 요청합니다
function getData(cookie) {
return new Promise(function(resolve, reject) {
//传入cookie
superagent.get(url.target_url).set("Cookie",cookie).set(browserMsg).end(function(err,res) {
var $ = cheerio.load(res.text);
resolve({
cookie: cookie,
doc: $
});
});
});
}
하지만 일반 콘텐츠 및 정보 웹사이트를 처리하는 데는 여전히 충분합니다
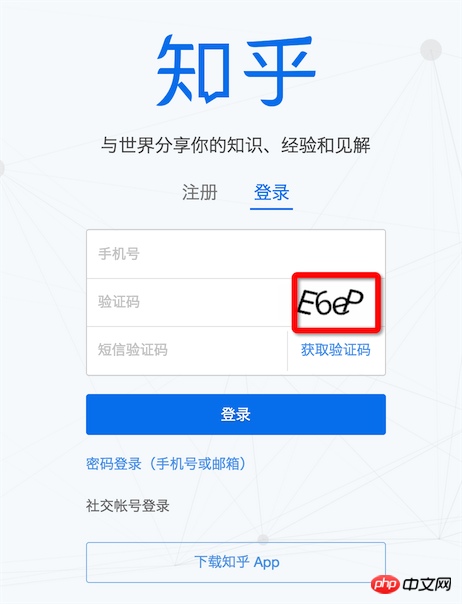
간단한 인증코드 인식을 구현합니다그러나 Graphicsmagick을 사용하여
사진을 전처리하더라도 높은 인식률을 보장할 수는 없습니다. tesseract를 훈련시키려면 다음을 참조하십시오: jTessBoxEditor 도구를 사용하여 Tesseract3.02.02 샘플을 훈련하여 인증 코드 인식률을 향상시키세요 높은 인식률을 달성할 수 있는지 여부는 캐릭터에 따라 다릅니다~~~
4. 확장
기반의 오픈 소스 서버 js입니다. 브라우저로 간주되지만 js 스크립트를 통해 제어할 수 있습니다. 브라우저의
동작을 완전히 시뮬레이션하므로 set-cookie 및 쿠키에 전혀 신경 쓸 필요가 없습니다. 사용자의 클릭 동작만 시뮬레이션하면 됩니다(물론, 인증 코드가 있으므로 식별해야 합니다.) 이 방법에는 단점이 있습니다. 즉, 요청을 놓치지 않고 정적 자료의 경우 대상 페이지에 도달하려면 여러 페이지를 클릭해야 하는데 이는 대상 URL에 직접 액세스하는 것보다 효율성이 떨어집니다관심 있는 경우 검색
5. 요약노드 크롤러의 로그인에 대해 이야기하고 있지만, 그 목적은 이전에 많은 원칙에 대해 이야기했습니다. 다시 말씀드리지만, 같은 문장 : 원리를 이해하는 것이 중요합니다 도움이 되셨다면 댓글 남겨주세요. 좋아요~~
위 내용은 노드 크롤러 고급 - 로그인의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



