

XML 구문 분석 기본 사항

Java Web Development Practical Classic
프로젝트 개발에서 HTML의 주요 기능은 데이터 표시이며, 데이터 저장 구조를 표준화하려면 XML을 사용해야 합니다. . XML에는 고유한 구문이 있으며 모든 마크업 요소는 사용자가 임의로 정의할 수 있습니다.
1. XML 이해
XML(eXtended Markup Language, 확장 가능한 마크업 언어)은 크로스 플랫폼, 크로스 네트워크를 제공합니다. , 교차 프로그램 언어 데이터 설명 방법은 XML을 사용하여 데이터 교환, 시스템 구성 및 컨텐츠 관리와 같은 공통 기능을 쉽게 실현할 수 있습니다.
XML은 HTML과 유사하며 둘 다 마크업 언어입니다. 가장 큰 차이점은 HTML의 요소는 고정되어 있으며 주로 표시에 중점을 두는 반면, XML 언어의 태그는 사용자가 맞춤화하고 주로 데이터 저장에 중점을 둔다는 것입니다.
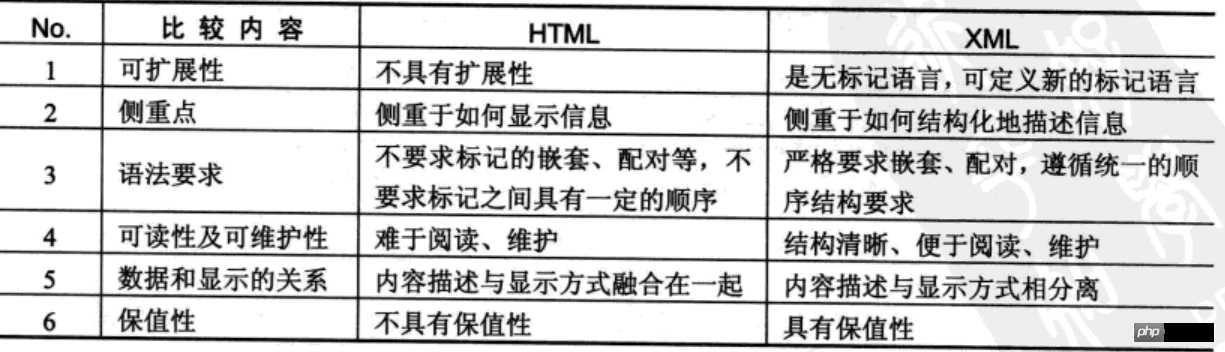
XML과 HTML의 비교
실제로 모든 XML 파일은 선행 영역과 데이터 영역의 두 부분으로 그룹화됩니다 성공했습니다.
리더 영역: XML 페이지의 일부 속성을 지정합니다. 다음 3가지 속성이 있습니다.
version: 사용된 XML 버전을 나타냅니다. 지금은 1.0입니다.
인코딩: 페이지에 사용된 텍스트 인코딩입니다. 중국어가 있는 경우 인코딩을 지정해야 합니다.
독립형: 이 XML 파일이 독립적으로 실행되는지 여부입니다. 표시해야 하는 경우 CSS 또는 XSL을 사용하여 제어할 수 있습니다.
속성이 나타나는 순서는 고정, 버전, 인코딩, 독립형입니다. 순서가 잘못되면 XML에서 오류가 발생합니다.
<?xml version="1.0" encoding="GB2312" standalone="no"?>로그인 후 복사데이터 영역: 모든 데이터 영역에는 루트 요소가 있어야 합니다. 하나의 루트 요소 아래에 여러 하위 요소를 저장할 수 있지만 각 요소는 대소문자를 구분해야 합니다.
CDATA 태그는 파일 데이터를 식별하기 위해 XML 언어로 제공됩니다. XML 파서는 CDATA 태그를 처리할 때 데이터의 기호나 태그를 구문 분석하지 않습니다. 원본 데이터는 그대로 애플리케이션에 전달됩니다.
CDATA 구문 형식:
<![CDATA[] 不解析内容 ]>
2. XML 구문 분석
XML 파일에서는 내용의 대부분이 설명 정보이므로 XML 문서를 얻은 후 이 애플리케이션을 사용하십시오. 요소의 해당 내용을 추출하는 데 사용됩니다. 이 작업을 XML 구문 분석이라고 합니다.
XML 구문 분석에서 W3C는 SAX와 DOM이라는 두 가지 구문 분석 방법을 정의합니다. 이 두 가지 구문 분석 방법의 프로그램 작동은 다음과 같습니다.
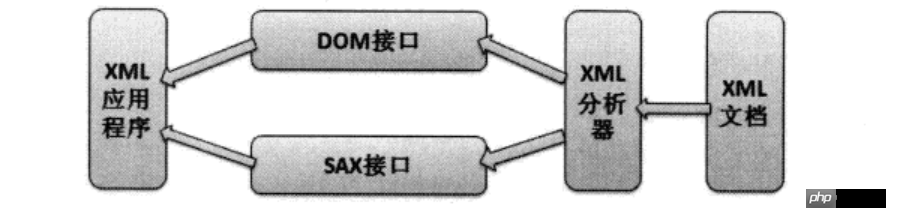
XML 파싱 작업
애플리케이션이 XML 문서에 직접적으로 동작하지 않고, 대신 XML 파서가 XML 문서를 먼저 분석한 후, 애플리케이션이 제공하는 DOM을 전달하는 것을 볼 수 있습니다. XML 파서 인터페이스 또는 SAX 인터페이스는 분석 구조에서 작동하므로 XML 문서에 간접적으로 액세스할 수 있습니다.
2.1. DOM 파싱 작업
애플리케이션에서는 DOM(Document Object Model, Document객체모델) XML 파서는 XML 문서를 객체 모델 모음(종종 DOM 트리라고 함)으로 변환합니다. Cheng Xun 애플리케이션은 이 객체 모델의 작업을 통해 작업을 실현합니다. XML 문서 데이터에 대해. DOM 인터페이스를 통해 애플리케이션은 언제든지 XML 문서에 있는 데이터의 모든 부분에 액세스할 수 있습니다. 따라서 DOM 인터페이스를 활용하는 이 메커니즘을 무작위 액세스 메커니즘이라고도 합니다. DOM 파서는 XML 문서 전체를 DOM 트리로 변환하여 메모리에 저장하기 때문에 문서가 크거나 구조가 복잡할 경우 메모리 요구량이 상대적으로 높고 구조가 복잡한 트리의 순회도 시간이 많이 걸리는 작업입니다.
DOM 작업은 모든 XML 파일을 메모리의 DOM 트리로 변환합니다.
- 문서: 이 인터페이스는 전체 XML 문서를 나타내고 전체 DOM 트리의 루트를 나타내며 Document 노드를 통해 XML 파일의 모든 요소 내용에 접근하고 조작할 수 있는 입구를 제공합니다.

Node:DOM操作的核心接口中有很大一部分是从Node接口继承过来的。例如Document、Element、Attri等接口。在DOM树中,每一个Node接口代表了DOM树中的一个节点。
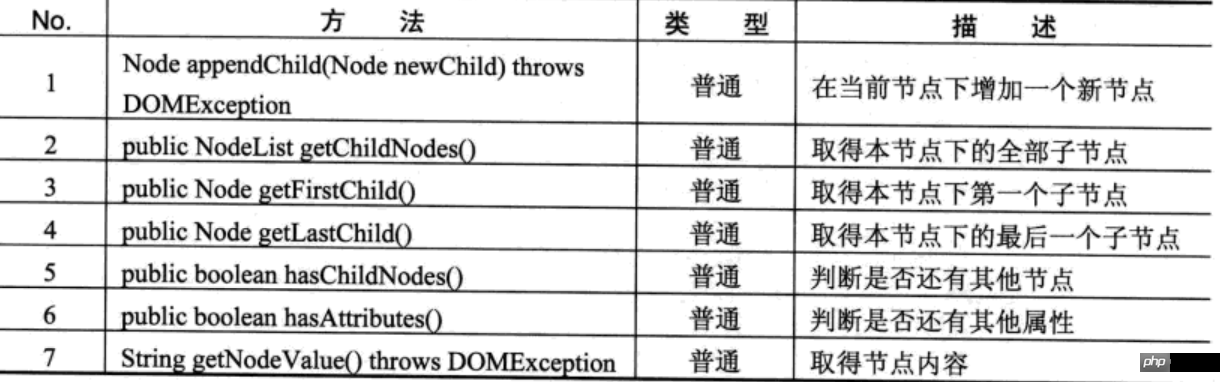
Node接口的常用方法
NodeList:此接口表示一个节点的集合,一般用于表示有顺序关系的一组节点。例如,一个节点的子节点,当文档改变时会直接 影响到NodeList集合。

NodeList接口的常用方法
NameNodeMap:此接口表示一组节点和其唯一名称对应的一一对应关系,主要用于属性节点的表示。
出以上4个核心接口外,如果一个程序需要进行DOM解析读操作,则需要按如下步骤进行:
(1)建立DocumentBuilderFactory:DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
(2)建立DocumentBuilder:DocumentBuilder builder = factory.newDocumentBuilder();
(3)建立Document:Document doc= builder.parse("要读取的文件路径");
(4)建立NodeList:NodeList nl = doc.getElementsByTagName("读取节点");
(5)进行XML信息读取。
// xml_demo.xml <?xml version="1.0" encoding="GBK"?> <addresslist> <linkman> <name>小明</name> <email>asaasa@163.com</email> </linkman> <linkman> <name>小张</name> <email>xiaoli@163.com</email> </linkman> </addresslist>
DOM完成XML的读取。
package com.demo;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class XmlDomDemo {
public static void main(String[] args) {
// (1)建立DocumentBuilderFactory,以用于取得DocumentBuilder
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// (2)通过DocumentBuilderFactory,取得DocumentBuilder
DocumentBuilder builder = null;
try {
builder = factory.newDocumentBuilder();
} catch (ParserConfigurationException e) {
e.printStackTrace();
}
// (3)定义Document接口对象,通过DocumentBuilder类进行DOM树是转换操作
Document doc = null;
try {
// 读取指定路径的XML文件,读取到内存中
doc = builder.parse("xml_demo.xml");
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
// (4)查找linkman节点
NodeList nl = doc.getElementsByTagName("linkman");
// (5)输出NodeList中第一个子节点中文本节点的内容
for (int i = 0; i < nl.getLength(); i++) {
// 取出每一个元素
Element element = (Element) nl.item(i);
System.out.println("姓名:" + element.getElementsByTagName("name").item(0).getFirstChild().getNodeValue());
System.out.println("邮箱:" + element.getElementsByTagName("email").item(0).getFirstChild().getNodeValue());
}
}
}DOM完成XML的文件输出。
此时就需要使用DOM操作中提供的各个接口(如Element接口)并手工设置各个节点的关系,同时在创建Document对象时就必须使用newDocument()方法建立一个新的DOM树。
如果现在需要将XML文件保存在硬盘上,则需要使用TransformerFactory、Transformer、DOMSource、StreamResult 4个类完成。
TransformerFactory类:取得一个Transformer类的实例对象。
DOMSource类:接收Document对象。
StreamResult 类:指定要使用的输出流对象(可以向文件输出,也可以向指定的输出流输出)。
Transformer类:通过该类完成内容的输出。

StreamResult类的构造方法
package com.demo;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
public class XmlDemoWrite {
public static void main(String[] args) {
// (1)建立DocumentBuilderFactory,以用于取得DocumentBuilder
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// (2)通过DocumentBuilderFactory,取得DocumentBuilder
DocumentBuilder builder = null;
try {
builder = factory.newDocumentBuilder();
} catch (ParserConfigurationException e) {
e.printStackTrace();
}
// (3)定义Document接口对象,通过DocumentBuilder类进行DOM树是转换操作
Document doc = null;
// 创建一个新的文档
doc = builder.newDocument();
// (4)建立各个操作节点
Element addresslist = doc.createElement("addresslist");
Element linkman = doc.createElement("linkman");
Element name = doc.createElement("name");
Element email = doc.createElement("email");
// (5)设置节点的文本内容,即为每一个节点添加文本节点
name.appendChild(doc.createTextNode("小明"));
email.appendChild(doc.createTextNode("xiaoming@163.com"));
// (6)设置节点关系
linkman.appendChild(name);
linkman.appendChild(email);
addresslist.appendChild(linkman);
doc.appendChild(addresslist);
// (7)输出文档到文件中
TransformerFactory tf = TransformerFactory.newInstance();
Transformer t = null;
try {
t = tf.newTransformer();
} catch (TransformerConfigurationException e) {
e.printStackTrace();
}
// 设置编码
t.setOutputProperty(OutputKeys.ENCODING, "GBK");
// 输出文档
DOMSource source = new DOMSource(doc);
// 指定输出位置
StreamResult result = new StreamResult(new File("xml_wirte.xml"));
try {
// 输出
t.transform(source, result);
System.out.println("yes");
} catch (TransformerException e) {
e.printStackTrace();
}
}
}生成文档:
//xml_write.xml <?xml version="1.0" encoding="GBK" standalone="no"?> <addresslist> <linkman> <name>小明</name> <email>xiaoming@163.com</email> </linkman> </addresslist>
2.2、SAX解析操作
SAX(Simple APIs for XML,操作XML的简单接口)与DOM操作不同的是,SAX采用的是一种顺序的模式进行访问,是一种快速读取XML数据的方式。
当使用SAX 解析器进行操作时会触发一系列的事件。
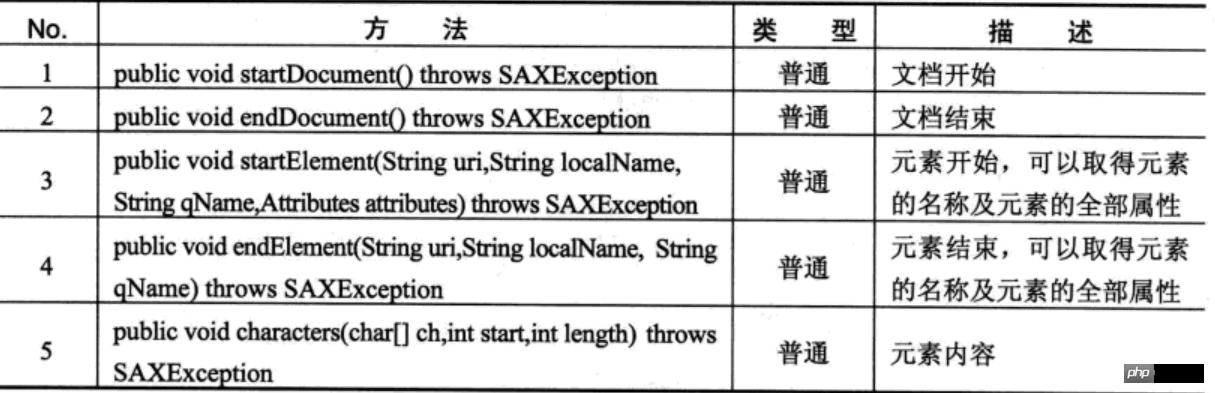
SAX主要事件
当扫描到文档(Document)开始与结束、元素(Element)开始与结束时都会调用相关的处理方法,并由这些操作方法做出相应的操作,直到整个文档扫描结束。
如果在开发中想要使用SAX解析,则首先应该编写一个SAX解析器,再直接定义一个类,并使该类继承自DefaultHandler类,同时覆写上述的表中的方法即可。
package com.sax.demo;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class XmlSax extends DefaultHandler {
@Override
public void startDocument() throws SAXException {
System.out.println("<?xml version=\"1.0\" encoding=\"GBK\"?>");
}
@Override
public void endDocument() throws SAXException {
System.out.println("\n 文档读取结束。。。");
}
@Override
public void startElement(String url, String localName, String name,
Attributes attributes) throws SAXException {
System.out.print("<");
System.out.print(name);
if (attributes != null) {
for (int x = 0; x < attributes.getLength(); x++) {
System.out.print("" + attributes.getQName(x) + "=\"" + attributes.getValue(x) + "\"");
}
}
System.out.print(">");
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
System.out.print(new String(ch, start, length));
}
@Override
public void endElement(String url, String localName, String name)
throws SAXException {
System.out.print("</");
System.out.print(name);
System.out.print(">");
}
}建荔湾SAX解析器后,还需要建立SAXParserFactory和SAXParser对象,之后通过SAXPaeser的parse()方法指定要解析的XML文件和指定的SAX解析器。
建立要读取的文件:sax_demo.xml
<?xml version="1.0" encoding="GBK"?> <addresslist> <linkman id="xm"> <name>小明</name> <email>xiaoming@163.com</email> </linkman> <linkman id="xl"> <name>小李</name> <email>xiaoli@163.com</email> </linkman> </addresslist>
使用SAX解析器
package com.sax.demo;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
public class SaxTest {
public static void main(String[] args) throws Exception {
//(1)建立SAX解析工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
//(2)构造解析器
SAXParser parser = factory.newSAXParser();
//(3)解析XML使用handler
parser.parse("sax_demo.xml", new XmlSax());
}
}通过上面的程序可以发现,使用SAX解析比使用DOM解析更加容易。
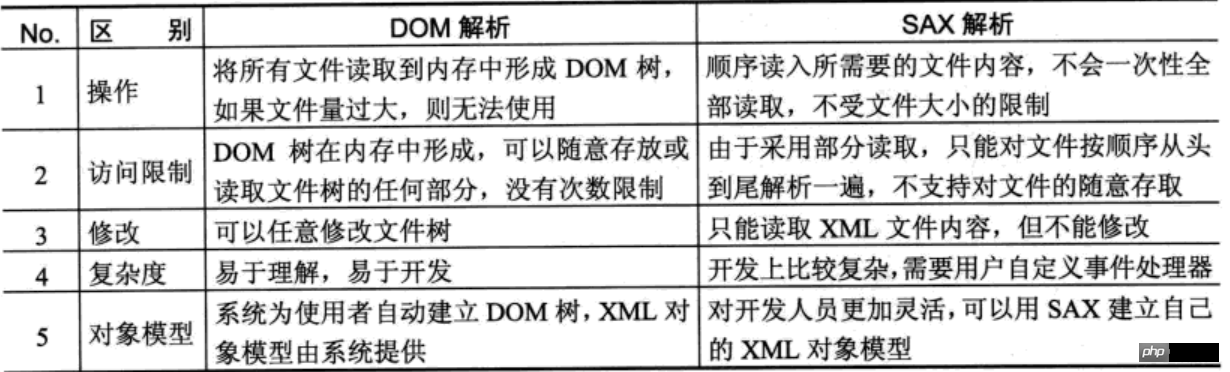
DOM解析与SAX解析的区别
有两者的特点可以发现两者的区别:
DOM解析适合于对文件进行修改和随机存取的操作,但是不适合于大型文件的操作。
SAX采用部分读取的方式,所以可以处理大型文件,而且只需要从文件中读取特定内容。SAX解析可以由用户自己建立自己的对象模型。
2.3、XML解析的好帮手:jdom
jdom是使用Java编写的,用于读、写、操作XML的一套组件。
jdom = dom 修改文件的有点 + SAX读取快速的优点

jdom的主要操作类
使用jdom生成XML文件
package com.jdom.demo;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import org.jdom.Attribute;
import org.jdom.Document;
import org.jdom.Element;
import org.jdom.output.XMLOutputter;
public class WriteXml {
public static void main(String[] args) {
// 定义节点
Element addresslist = new Element("addresslist");
Element linkman = new Element("linkman");
Element name = new Element("name");
Element email = new Element("email");
// 定义属性
Attribute id = new Attribute("id", "xm");
// 声明一个Document对象
Document doc = new Document(addresslist);
// 设置元素的内容
name.setText("小明");
email.setText("xiaoming@163.com");
name.setAttribute(id);
// 设置子节点
linkman.addContent(name);
linkman.addContent(email);
// 将linkman加入根子节点
addresslist.addContent(linkman);
// 用来输出XML文件
XMLOutputter out = new XMLOutputter();
// 设置输出编码
out.setFormat(out.getFormat().setEncoding("GBK"));
// 输出XML文件
try {
out.output(doc, new FileOutputStream("jdom_write.xml"));
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}// jdom_write.xml <?xml version="1.0" encoding="GBK"?> <addresslist> <linkman> <name id="xm">小明</name> <email>xiaoming@163.com</email> </linkman> </addresslist>
使用jdom读取XML文件
package com.jdom.demo;
import java.io.IOException;
import java.util.List;
import org.jdom.Document;
import org.jdom.Element;
import org.jdom.JDOMException;
import org.jdom.input.SAXBuilder;
public class ReadXml {
public static void main(String[] args) throws JDOMException, IOException {
//建立SAX解析
SAXBuilder builder = new SAXBuilder();
//找到Document
Document readDoc = builder.build("jdom_write.xml");
//读取根元素
Element stu = readDoc.getRootElement();
//得到全部linkman子元素
List list = stu.getChildren("linkman");
for (int i = 0; i < list.size(); i++) {
Element e = (Element) list.get(i);
String name = e.getChildText("name");
String id = e.getChild("name").getAttribute("id").getValue();
String email = e.getChildText("email");
System.out.println("----联系人----");
System.out.println("姓名:" + name + "编号:" + id);
System.out.println("Email:" + email);
}
}
}jdom是一种常见的操作组件
在实际的开发中使用非常广泛。
2.4、解析工具:dom4j
dom4j也是一组XML操作组件包,主要用来读写XML文件,由于dom4j性能优异、功能强大,且具有易用性,所以现在已经被广泛地应用开来。如,Hibernate、Spring框架中都使用了dom4j进行XML的解析操作。
开发时需要引入的jar包:dom4j-1.6.1.jar、lib/jaxen-1.1-beta-6.jar
dom4j中的所用操作接口都在org.dom4j包中定义。其他包根据需要把选择使用。
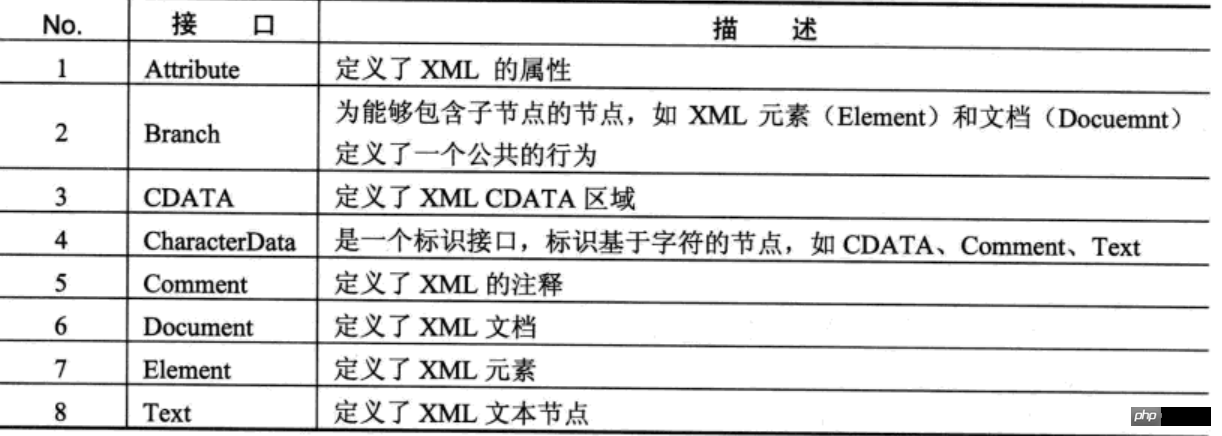
dom4j的主要接口
用dom4j生成XML文件:
package com.dom4j.demo;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.XMLWriter;
public class Dom4jWrite {
public static void main(String[] args) {
// 创建文档
Document doc = DocumentHelper.createDocument();
// 定义个节点
Element addresslist = doc.addElement("addresslist");
Element linkman = addresslist.addElement("linkman");
Element name = linkman.addElement("name");
Element email = linkman.addElement("email");
// 设置节点内容
name.setText("小明");
email.setText("xiaoming@163.com");
// 设置输出格式
OutputFormat format = OutputFormat.createPrettyPrint();
// 指定输出编码
format.setEncoding("GBK");
try {
XMLWriter writer = new XMLWriter(new FileOutputStream(new File(
"dom4j_demo.xml")), format);
writer.write(doc);
writer.close();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}// dom4j_demo.xml <?xml version="1.0" encoding="GBK"?> <addresslist> <linkman> <name>小明</name> <email>xiaoming@163.com</email> </linkman> </addresslist>
用dom4j读取XML文件:
package com.dom4j.demo;
import java.io.File;
import java.util.Iterator;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class Dom4jRead {
public static void main(String[] args) {
//读取文件
File file = new File("dom4j_demo.xml");
//建立SAX解析读取
SAXReader reader = new SAXReader();
Document doc = null;
try {
//读取文档
doc = reader.read(file);
} catch (DocumentException e) {
e.printStackTrace();
}
//取得根元素
Element root = doc.getRootElement();
//取得全部的子节点
Iterator iter = root.elementIterator();
while (iter.hasNext()) {
//取得每一个linkman
Element linkman = (Element) iter.next();
System.out.println("姓名:"+linkman.elementText("name"));
System.out.println("邮件地址:"+linkman.elementText("email"));
}
}
}小结
XML主要用于数据交换,而HTML则用于显示。
-
Java直接提供的XML解析方式分为两种,即DOM和SAX。这两种解析的区别如下:
DOM解析是将所有内容读取到内存中,并形成内存树,如果文件量较大则无法使用,但是DOM解析可以进行文件的修改
SAX解析是采用顺序的方式读取XML文件中,不受文件大小限制,但是不允许修改。
XML解析可以使用jdom和dom4j第三方工具包,以提升开发效率。
위 내용은 XML 구문 분석 기본 사항의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7629
7629
 15
1389
52
89
11
70
19
31
141
15
1389
52
89
11
70
19
31
141

 PowerPoint를 사용하여 XML 파일을 열 수 있나요?
Feb 19, 2024 pm 09:06 PM
PowerPoint를 사용하여 XML 파일을 열 수 있나요?
Feb 19, 2024 pm 09:06 PM
XML 파일을 PPT로 열 수 있나요? XML, Extensible Markup Language(Extensible Markup Language)는 데이터 교환 및 데이터 저장에 널리 사용되는 범용 마크업 언어입니다. HTML에 비해 XML은 더 유연하고 자체 태그와 데이터 구조를 정의할 수 있으므로 데이터 저장과 교환이 더 편리하고 통합됩니다. PPT 또는 PowerPoint는 프레젠테이션 작성을 위해 Microsoft에서 개발한 소프트웨어입니다. 이는 포괄적인 방법을 제공합니다.
 Oracle 오류 3114에 대한 자세한 설명: 신속하게 해결하는 방법
Mar 08, 2024 pm 02:42 PM
Oracle 오류 3114에 대한 자세한 설명: 신속하게 해결하는 방법
Mar 08, 2024 pm 02:42 PM
Oracle 오류 3114에 대한 자세한 설명: 이를 신속하게 해결하는 방법, 구체적인 코드 예제가 필요합니다. Oracle 데이터베이스를 개발 및 관리하는 동안 다양한 오류가 발생하는 경우가 많으며 그중 오류 3114는 비교적 일반적인 문제입니다. 오류 3114는 일반적으로 네트워크 오류, 데이터베이스 서비스 중지 또는 잘못된 연결 문자열 설정으로 인해 발생할 수 있는 데이터베이스 연결 문제를 나타냅니다. 이 문서에서는 오류 3114의 원인과 이 문제를 신속하게 해결하는 방법을 자세히 설명하고 특정 코드를 첨부합니다.
 웜홀 NTT 구문 분석: 모든 토큰을 위한 개방형 프레임워크
Mar 05, 2024 pm 12:46 PM
웜홀 NTT 구문 분석: 모든 토큰을 위한 개방형 프레임워크
Mar 05, 2024 pm 12:46 PM
Wormhole은 블록체인 상호 운용성의 선두주자로서 소유권, 통제 및 무허가형 혁신을 우선시하는 탄력적이고 미래 지향적인 분산 시스템을 만드는 데 중점을 두고 있습니다. 이 비전의 기초는 단순성, 명확성 및 광범위한 다중 체인 솔루션 제품군으로 상호 운용성 환경을 재정의하기 위한 기술 전문 지식, 윤리적 원칙 및 커뮤니티 조정에 대한 헌신입니다. 영지식 증명, 확장 솔루션 및 풍부한 기능의 토큰 표준이 등장하면서 블록체인은 더욱 강력해지고 상호 운용성은 점점 더 중요해지고 있습니다. 이 혁신적인 애플리케이션 환경에서 새로운 거버넌스 시스템과 실용적인 기능은 네트워크 전반의 자산에 전례 없는 기회를 제공합니다. 프로토콜 빌더는 이제 이 새로운 멀티체인에서 어떻게 기능할지 고민하고 있습니다.
 PHP에서 중간점의 의미와 사용법 분석
Mar 27, 2024 pm 08:57 PM
PHP에서 중간점의 의미와 사용법 분석
Mar 27, 2024 pm 08:57 PM
[PHP 중간점의 의미와 사용법 분석] PHP에서 중간점(.)은 두 개의 문자열이나 객체의 속성이나 메소드를 연결하는 데 사용되는 일반적으로 사용되는 연산자입니다. 이 기사에서는 구체적인 코드 예제를 통해 PHP에서 중간점의 의미와 사용법을 자세히 살펴보겠습니다. 1. 문자열 중간점 연산자 연결 PHP에서 가장 일반적인 사용법은 두 문자열을 연결하는 것입니다. 두 문자열 사이에 .을 배치하면 두 문자열을 이어붙여 새 문자열을 만들 수 있습니다. $string1=&qu
 Win11의 새로운 기능 분석: Microsoft 계정 로그인을 건너뛰는 방법
Mar 27, 2024 pm 05:24 PM
Win11의 새로운 기능 분석: Microsoft 계정 로그인을 건너뛰는 방법
Mar 27, 2024 pm 05:24 PM
Win11의 새로운 기능 분석: Microsoft 계정 로그인을 건너뛰는 방법 Windows 11이 출시되면서 많은 사용자는 Windows 11이 더 편리하고 새로운 기능을 제공한다는 사실을 알게 되었습니다. 그러나 일부 사용자는 시스템을 Microsoft 계정에 연결하는 것을 좋아하지 않아 이 단계를 건너뛰기를 원할 수도 있습니다. 이 문서에서는 사용자가 Windows 11에서 Microsoft 계정 로그인을 건너뛰고 보다 개인적이고 자율적인 환경을 달성하는 데 도움이 되는 몇 가지 방법을 소개합니다. 먼저 일부 사용자가 Microsoft 계정에 로그인하기를 꺼리는 이유를 이해해 보겠습니다. 한편으로는 일부 사용자들은 다음과 같은 걱정을 합니다.
 PHP 함수를 사용하여 XML 데이터를 처리하는 방법은 무엇입니까?
May 05, 2024 am 09:15 AM
PHP 함수를 사용하여 XML 데이터를 처리하는 방법은 무엇입니까?
May 05, 2024 am 09:15 AM
PHPXML 함수를 사용하여 XML 데이터 처리: XML 데이터 구문 분석: simplexml_load_file() 및 simplexml_load_string()은 XML 파일 또는 문자열을 로드합니다. XML 데이터에 액세스: SimpleXML 개체의 속성과 메서드를 사용하여 요소 이름, 속성 값 및 하위 요소를 가져옵니다. XML 데이터 수정: addChild() 및 addAttribute() 메서드를 사용하여 새 요소와 속성을 추가합니다. 직렬화된 XML 데이터: asXML() 메서드는 SimpleXML 객체를 XML 문자열로 변환합니다. 실제 예: 제품 피드 XML을 구문 분석하고, 제품 정보를 추출하고, 변환하여 데이터베이스에 저장합니다.
 Apache2는 PHP 파일을 올바르게 구문 분석할 수 없습니다.
Mar 08, 2024 am 11:09 AM
Apache2는 PHP 파일을 올바르게 구문 분석할 수 없습니다.
Mar 08, 2024 am 11:09 AM
공간 제한으로 인해 다음은 간략한 기사입니다. Apache2는 일반적으로 사용되는 웹 서버 소프트웨어이고 PHP는 널리 사용되는 서버측 스크립팅 언어입니다. 웹 사이트를 구축하는 과정에서 Apache2가 PHP 파일을 올바르게 구문 분석할 수 없어 PHP 코드가 실행되지 않는 문제가 발생하는 경우가 있습니다. 이 문제는 일반적으로 Apache2가 PHP 모듈을 올바르게 구성하지 않거나 PHP 모듈이 Apache2 버전과 호환되지 않기 때문에 발생합니다. 이 문제를 해결하는 방법은 일반적으로 두 가지가 있는데, 그 중 하나는
 PHP에서 HTML/XML을 어떻게 구문 분석하고 처리합니까?
Feb 07, 2025 am 11:57 AM
PHP에서 HTML/XML을 어떻게 구문 분석하고 처리합니까?
Feb 07, 2025 am 11:57 AM
이 튜토리얼은 PHP를 사용하여 XML 문서를 효율적으로 처리하는 방법을 보여줍니다. XML (Extensible Markup Language)은 인간의 가독성과 기계 구문 분석을 위해 설계된 다목적 텍스트 기반 마크 업 언어입니다. 일반적으로 데이터 저장 AN에 사용됩니다
