

1. 소개
지난주에는 프로젝트의 전반적인 내용을 이해해야 해서 xml 파싱 부분에 대해 헷갈렸습니다. , 그래서 여기에는 XML 구문 분석에 대해 배운 지식 중 일부를 기록하겠습니다.
2. 분석
android 에는 DOM 파서, SAX 파서, 풀 파서의 세 가지 주요 유형이 있습니다.
1. DOM 파서
DOM(Document Object Model)은 XML 문서의 ObjectModel로, XML 문서 각 부분에 직접 접근할 수 있습니다. 콘텐츠를 메모리에 한 번에 로드하고 트리 구조를 생성합니다. 콜백과 복잡한 상태 관리가 필요하지 않다는 단점이 있습니다. 대용량 문서를 로드할 때는 파싱을 권장하지 않습니다.
이 구조를 구문 분석하려면 일반적으로 노드 정보를 검색하고 업데이트하기 전에 전체 문서를 로드하고 트리 구조를 구성해야 합니다. 읽기, 검색, 수정, 추가 및 삭제 DOM 작동 방식: DOM을 사용합니다. XML 파일에서 작업할 때 먼저 파일을 구문 분석하고 독립 요소로 나누어야 합니다. 🎜> 속성
및주석 등을 사용하여 XML 파일을 노드 트리 형태로 메모리에서 처리할 수 있다는 것은 노드 트리를 통해 문서의 내용에 접근할 수 있다는 의미입니다. 일반적으로 사용되는 DOM 인터페이스 및 클래스:
문서: 인터페이스는 DOM 문서를 분석하고 생성하기 위한 일련의 방법을 정의합니다. 문서 트리
의 루트이자 DOM 운영의 기초입니다.
Node 인터페이스를 상속하고 XML 요소 이름과 속성을 가져오고 수정하는 메서드를 제공합니다.
API
XML) 스트리밍 처리를 사용하여 녹음하지 않습니다. 이벤트를 드라이버로 사용하는 XML API로 구문 분석 속도가 빠르고 메모리를 덜 차지합니다. 이를 달성하려면
콜백 함수를 사용하세요. 단점은 이벤트 중심이기 때문에 롤백할 수 없다는 점입니다. 그 핵심은 주로 이벤트 소스와 이벤트 프로세서를 중심으로 작동하는 이벤트 처리 모드입니다. 이벤트 소스가 이벤트를 생성하면 해당 이벤트 프로세서의 처리 메서드를 호출하여 이벤트를 처리할 수 있습니다. 이벤트 소스가 이벤트 핸들러에서 특정 메서드를 호출할 때 해당 이벤트의 상태 정보도 이벤트 핸들러에 전달해야 이벤트 핸들러가 제공된 이벤트에 따라 자체 동작을 결정할 수 있습니다. 정보. SAX의 작동 원리: SAX는 문서를 순차적으로 스캔하고, 문서의 시작과 끝, 요소의 시작과 끝, 요소의 내용(문자)을 스캔할 때 이벤트 처리 방법을 알려줍니다. 등 해당 처리를 수행한 후 스캔을 계속하여 문서 스캔을 종료하는 방법입니다.
일반적으로 사용되는 SAX 인터페이스 및 클래스:
속성: 속성의 수, 이름 및 값을 가져오는 데 사용됩니다.
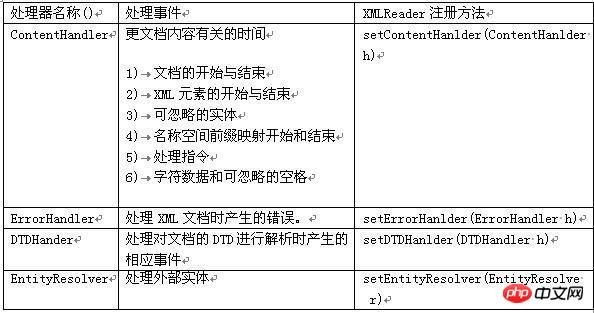
ContentHandler: 문서 자체와 관련된 이벤트(예: 열기 및 닫기 태그)를 정의합니다. 대부분의 애플리케이션은 이러한 이벤트에 등록합니다.
DTD핸들러: DTD와 관련된 이벤트를 정의합니다. DTD를 완전히 보고할 만큼 충분한 이벤트를 정의하지 않습니다. DTD 구문 분석이 필요한 경우 선택적 DeclHandler를 사용하십시오.
DeclHandler는 SAX의 확장입니다. 모든 파서가 이를 지원하는 것은 아닙니다.
EntityResolver: 엔터티 로드와 관련된 이벤트를 정의합니다. 소수의 애플리케이션만이 이러한 이벤트에 등록됩니다.
ErrorHandler: 오류 이벤트를 정의합니다. 많은 응용 프로그램은 이러한 이벤트를 등록하여 고유한 방식으로 오류를 보고합니다.
DefaultHandler: 이러한 인터페이스의 기본 구현을 제공합니다. 대부분의 경우 애플리케이션이 인터페이스를 직접 구현하는 것보다 DefaultHandler를 확장하고 관련 메서드를 재정의하는 것이 더 쉽습니다.
다음은 부분적인 설명입니다.
SAX 프로세서 설명
몇 가지 일반적인 방법에 대한 설명
따라서 우리는 일반적으로 XmlReader 및 DefaultHandler를 사용하여 xml 문서를 구문 분석합니다.
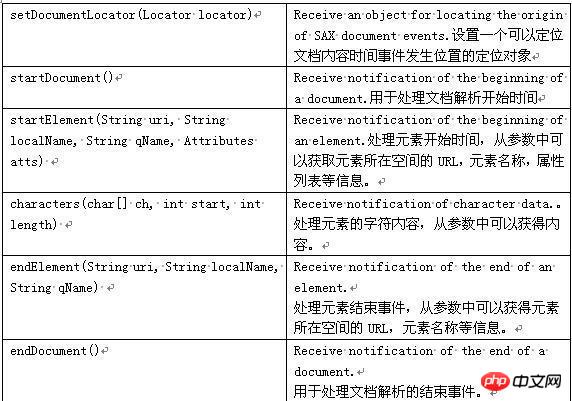
SAX 구문 분석 프로세스:
startDocument --> startElement --> 문자 --> endElement -->
Pull은 Android 시스템에 내장되어 있습니다. 이는 레이아웃 파일을 구문 분석하는 데 사용되는 공식적인 방법이기도 합니다. Pull은 SAX와 다소 유사하며 둘 다 시작 요소 및 끝 요소와 같은 유사한 이벤트를 제공합니다. 차이점은 SAX의 이벤트 드라이버는 해당 메서드를 콜백한다는 점입니다. 콜백 메서드를 제공한 다음 SAX 내부에서 해당 메서드를 자동으로 호출해야 합니다. 트리거링 방법을 제공하기 위해 Pull 파서가 필요하지 않습니다. 그가 촉발한 이벤트는 메소드가 아니라 숫자이기 때문이다. 사용하기 쉽고 효율적입니다. Android에서는 개발자에게 풀 구문 분석 기술을 사용할 것을 공식적으로 권장합니다. 풀 파싱(Pull Parsing) 기술은 타사에서 개발한 오픈소스 기술로, JavaSE 개발에도 적용할 수 있습니다.
pull에서 반환된
상수: 는 xml의 문을 읽고 START_DOCUMENT를 반환합니다.
은 xml의 끝을 읽고 END_DOCUMENT를 반환합니다. ;
xml의 시작 태그를 읽고 START_TAG를 반환합니다.
xml의 끝 태그를 읽고 END_TAG를 반환합니다.
xml의 텍스트를 읽고 TEXT를 반환합니다.
풀 작동 방식: 풀은 시작 요소와 끝 요소를 제공합니다. 요소가 시작되면 파서를 호출할 수 있습니다.
다음텍스트는 XML 문서에서 모든 문자 데이터를 추출합니다. 문서 해석이 끝나면 EndDocument 이벤트가 자동으로 생성됩니다.
일반적으로 사용되는 XML 풀 인터페이스 및 클래스:
XmlPullParser: XML 풀 파서는 XMLPULL VlAP1에서 정의 파싱 기능을 제공하는 인터페이스입니다.
XmlSerializer: XML 정보 세트의 순서를 정의하는 인터페이스입니다.
XmlPullParserFactory: 이 클래스는 XMPULL V1 API에서 XML Pull 파서를 생성하는 데 사용됩니다.
XmlPullParser
예외: 단일 XML 풀 파서 관련 오류가 발생합니다. 풀 구문 분석 프로세스:
start_document --> end_document --> start_tag -->end_tag
(사용해본 적이 없습니다) Android API에서는 Android입니다. 유틸리티 Xml 클래스는 XML 파일도 구문 분석할 수 있습니다. 사용 방법은 SAX와 유사합니다. XML 구문 분석을 처리하려면 핸들러도 작성해야 하지만 아래와 같이 SAX보다 사용이 더 간단합니다.
Android의 경우 . 유틸리티 XML은 XML 구문 분석을 구현합니다.
MyHandler myHandler=new MyHandler0;
android. 유틸리티 Xm1. parse(url.openC0nnection().getlnputStream(),
1. 먼저 참조 xml 문서를 만듭니다(asset
s 디렉터리에 배치)
<소개>
링 운하는 광시 장족 자치구 싱안 현에 위치하고 있으며 세계에서 가장 오래된 운하 중 하나이며 "세계 고대 수자원 보존 건축물의 진주"라는 명성을 가지고 있습니다. 고대에 Lingqu는 Qin Zhuoqu, Lingqu, Douhe 및 Xing'an 운하로 알려졌으며 기원전 214년에 건설되어 2217년 전에도 항해가 가능했습니다.
db7b8322e08244d3c.jpg
; 바다 삼산도(Sanshan Island)는 자오안(Jiaoan), 자오저우(Jiaozhou), 핑두(Pingdu), 가오미(Gao Mi), 창이(Changyi), 라이저우(Laizhou) 등을 거쳐 유역 면적이 5,400평방킬로미터에 달하며 산동반도를 남북으로 관통하며 황해와 발해를 연결합니다. . 자오라이 운하는 핑두 야오자 마을 동쪽 유역에서 북쪽에서 남쪽으로 갈라집니다. 남쪽 흐름은 Mawankou에서 Jiaozhou Bay로 흐르며 Nanjiolai River라고 불리며 길이는 30km입니다. 북해류는 하이창커우(Haicangkou)에서 래주만(Laizhou Bay)으로 흘러들어가며, 북가라이 강(Beijiaolai River)으로 길이가 100km가 넘습니다.
/389aa8fdb7b8322e08244d3c.jpg
>
저장하려면 River 객체를 사용해야 합니다. 노드 정보 관찰을 용이하게 하는 데이터 및 River 클래스public
classRiver {
이름을 추상화합니다. // 이름
정수길이;// 길이
문자열 소개;// 소개
문자열 이미지 URL ;//
그림
return
name;
}
public void setName(문자열 이름) {
this.name = 이름;
}
public Integer getLength() {
반환 길이;
}public void setLength(Integer length) {
this.length = length;}public String getIntroduction() {
public void setIntroduction(문자열 소개) {
public String getImageurl () {
public void setImageurl(String imageurl) {
Imageurl = imageurl;
}
@Override
public String toString() {
return "강 [이름=" + 이름 + ", 길이=" + 길이 + ", 소개="
+ 소개 + ", Imageurl=" + Imageurl + "]";
}
}
DOM 구문 분석을 사용할 때 구체적인 처리 단계는 다음과 같습니다. 1 먼저 DocumentBuilderFactory를 사용하여 DocumentBuilderFactory 인스턴스를 생성합니다. 2 그런 다음 DocumentBuilderFactory를 사용하여 DocumentBuilder를 생성합니다3 XML 문서(Document)를 로드한 다음 4 문서의 루트 노드(Element)를 가져오고 5 루트 노드를 가져옵니다. 모든 하위 노드 목록(NodeList), 6을 사용하여 하위 노드 목록에서 읽어야 하는 노드를 가져옵니다.
다음으로 xml 문서 객체를 읽고 이를 목록에 추가하기 시작합니다.
코드는 다음과 같습니다. 여기서는 river.xml을 사용합니다. 자산 파일이 있는 경우 이 xml 파일을 읽고 입력 스트림을 반환해야 합니다. 읽기 방법은 다음과 같습니다. inputStream=this.context.getResources().getAssets().open(fileName); 매개변수는 xml 파일 경로입니다. 기본값은 자산입니다. 디렉터리는 루트 디렉터리입니다.
그런 다음 DocumentBuilder 개체의 구문 분석 메서드를 사용하여 입력 스트림을 구문 분석하고 문서 개체를 반환한 다음 문서 개체의 노드 속성을 순회할 수 있습니다.
/*** DOM 파싱 xml 방식
* @param filePath
* @return
*/
private ListDOMfromXML(String filePath) {
배열Listlist = new ArrayList();
DocumentBuilderFactory 팩토리 = null;
DocumentBuilder builder = null;
문서 문서 = null ;
InputStream inputStream = null;
//파서 빌드
factory = DocumentBuilderFactory.newInstance();
시도해 보세요 {
builder = Factory.newDocumentBuilder();
//xml 파일을 찾아서 로드
inputStream = this.getResources().getAssets().open(filePath);//다음 이후의 기본값 getAssets 루트 디렉터리는 자산
document = builder.parse(inputStream);
//루트 요소 찾기
요소 root=document.getDocumentElement();
NodeList 노드=root.getElementsByTagName(RIVER);
//루트 노드의 모든 하위 노드, 강 아래의 모든 강
River river = null;
for (int i = 0; i < node.getLength(); i++) {
river = new River();
//강 가져오기 element node
element riverElement = (Element)nodes.item(i);
//river
river에 이름 및 길이 속성 값을 설정합니다. setName(riverElement.getAttribute("name") );
river.setLength(Integer.parseInt(riverElement.getAttribute("length")));
//하위 태그 가져오기
요소 소개 = (요소) riverElement.getElementsByTagName(INTRODUCTION).item(0);
요소 imageurl = (요소) riverElement.getElementsByTagName(IMAGEURL).item(0);
//소개 및 이미지 URL 속성 설정
river.setIntroduction(introduction.getFirstChild().getNodeValue());
river.setImageurl(imageurl.getFirstChild().getNodeValue( ));
list.add (river);
}
} catch (ParserConfigurationException e) {
// TODO 자동 생성된 catch 블록
e.print StackTrace();
} catch(IOException e) {
// TODO 자동 생성된 catch 블록
e.printStackTrace();
} catch (SAXException e) {
// TODO 자동 생성된 catch 블록
e.printStackTrace();
}
for ( River river : list) {
Log.w("DOM Test", river.toString());
}
return list;
}
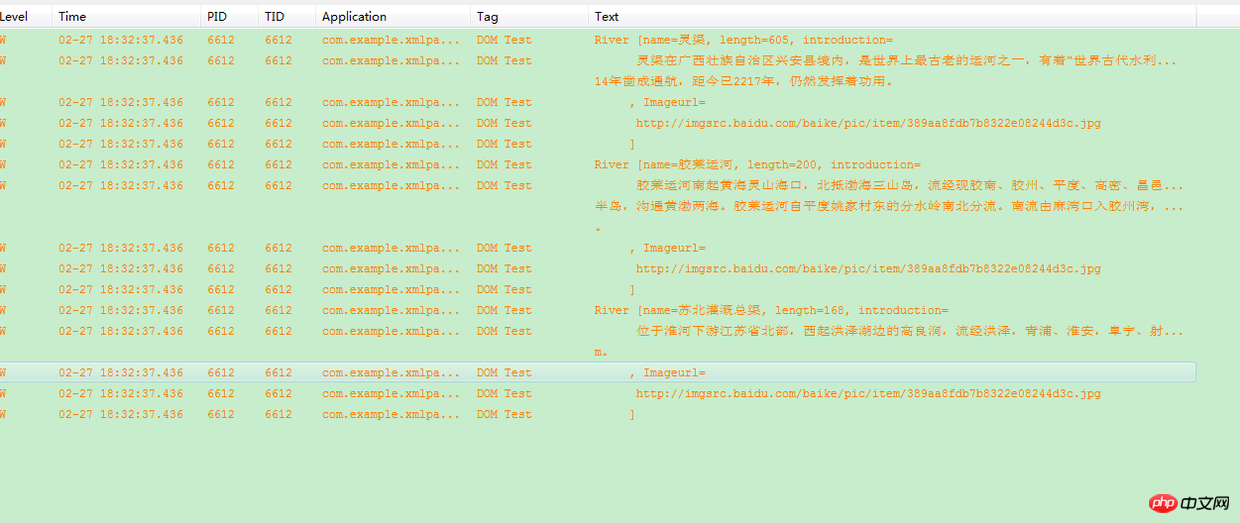
가 여기 List에 추가된 후 로그를 사용하여 인쇄합니다. 그림과 같이:
XML 구문 분석 결과
SAX 사용 구문 분석 구체적인 처리 단계는 다음과 같습니다.
1 SAXParserFactory 객체 생성
2 SAXParserFactory.newSAXParser() 메서드에 따라 SAXParser 파서를 반환합니다
3 SAXParser에 따르면 파서는 이벤트 소스 객체 XMLReader를 얻습니다
4 DefaultHandler 객체를 인스턴스화합니다
5 이벤트 소스 객체 XMLReader를 이벤트 처리 클래스 DefaultHandler
에 연결합니다. 6 호출 입력 소스
7에서 얻은 xml 데이터의 XMLReader 구문 분석 메소드는 DefaultHandler를 통해 필요한 데이터 세트 조합을 반환합니다.
코드는 다음과 같습니다:
/**
* SAX 구문 분석 xml
* @param filePath
* @return
*/
private ListSAXfromXML(String filePath) {
ArrayListlist = new ArrayList();
//파서 빌드
SAXParserFactory 팩토리 = SAXParserFactory.newInstance();
SAXParser 파서 = null;
XMLReader xReader = null;
시도 {
parser = Factory.newSAXParser();
//데이터 소스 가져오기
xReader = parser.getXMLReader();
//프로세서 설정
RiverHandler handler = new RiverHandler();
xReader.setContentHandler(handler);
//xml 파일 구문 분석
xReader.parse(new InputSource(this.getAssets().open(filePath)));
list = handler.getList();
} catch(ParserConfigurationException e) {
e.printStackTrace();
} catch(SAXException e) {
e.printStackTrace();
} catch(IOException e) {
e.printStackTrace();
}
for (River river : list) {
Log.w("DOM 테스트", river.toString() );
}
반품 목록;
}
위 내용은 Android의 XML 구문 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



