

CBO의 SQL 최적화 문제 해결 (자세한 설명은 그림과 텍스트로 설명)

이 공유 개요:
CBO 옵티마이저의 함정은 무엇입니까
CBO 옵티마이저 함정에 대한 솔루션
SQL 감사를 강화하여 초기 단계의 성능 문제를 방지
현장 FAQ 공유
CBO(Cost Based Optimizer) 옵티마이저는 현재 Oracle에서 널리 사용됩니다. 통계 정보, 쿼리 변환 등을 사용하여 가능한 다양한 액세스 경로의 비용을 계산하고 다양한 대체 실행 계획을 생성합니다. 최적의 실행 계획으로 가장 낮은 비용의 실행 계획을 선택합니다. "고대" 시대의 RBO(Rule Based Optimizer)와 비교할 때 데이터베이스의 실제 상황에 더 부합하며 더 많은 애플리케이션 시나리오에 적응할 수 있습니다. 그러나 그 복잡성으로 인해 CBO가 해결하지 못한 실제적인 문제와 버그가 많이 있습니다. 이때 일일 최적화 과정에서는 어떠한 통계 정보를 수집하더라도 올바른 실행 계획을 따르지 못하는 상황이 발생할 수 있습니다. , 당신은 CBO를 속였을 수도 있습니다.
이 공유에서는 CBO의 함정에 대한 솔루션을 탐색하기 위한 소개로 주로 일상적인 옵티마이저 문제를 사용합니다.
1. CBO 옵티마이저의 함정은 무엇인가요?
먼저 CBO 옵티마이저의 구성요소를 살펴보겠습니다.
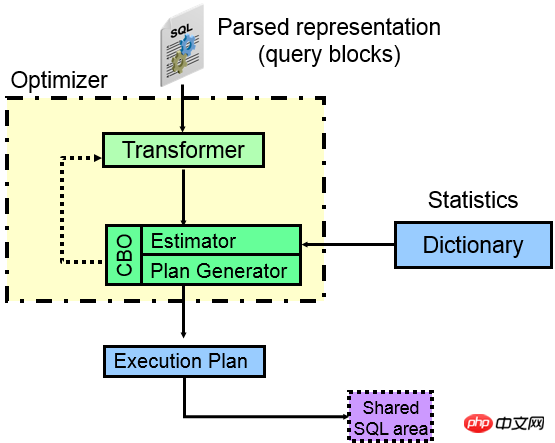
위 그림을 보면 SQL 문이 ORACLE에 들어오면 실제로는 여러 부분이 파싱을 거쳐 분리되고, 분리된 각 부분이 독립적으로 쿼리 블록(쿼리 블록)이 되는 것을 알 수 있습니다. 쿼리 블록이 되고 외부 쿼리가 쿼리 블록이 되면 ORACLE 최적화 프로그램이 해야 할 일은 각 쿼리 블록 내에서 어떤 종류의 액세스 경로가 더 나은지입니다( 인덱스 , 전체 테이블 가져오기). partition?), 두 번째는 각 쿼리 블록 사이에서 어떤 JOIN 방법과 JOIN 순서를 사용하여 최종적으로 어떤 실행 계획이 더 나은지 계산하는 것입니다.
옵티마이저의 핵심은 쿼리 변환기, 비용 추정기, 실행 계획생성기입니다.
Transformer(쿼리 변환기):
그림에서 알 수 있듯이 옵티마이저의 첫 번째 핵심 장치는 쿼리 변환기의 주요 기능은 다양한 쿼리를 연구하는 것입니다. 블록 SQL과 SQL 간의 관계는 구문론적으로, 심지어 의미론적으로 동일합니다. 다시 작성된 SQL은 코어 장치 비용 추정기 및 실행 계획 생성기에 의해 더 쉽게 처리되므로 통계 정보를 사용하여 최적의 실행 계획을 생성합니다.
쿼리 변환기에는 최적화 프로그램에서 경험적 쿼리 변환(규칙 기반)과 COST 기반 쿼리 변환이라는 두 가지 방법이 있습니다. 경험적 질의 변환은 일반적으로 상대적으로 간단한 명령문이고 비용 기반 질의 변환은 일반적으로 더 복잡합니다. 즉, 규칙 기반 질의를 준수하는 ORACLE은 어떤 상황에서도 질의 변환을 수행하지만 요구 사항을 충족하지 않는 ORACLE은 고려할 수 있습니다. 비용 기반 쿼리 변환. 경험적 쿼리 변환은 오랜 역사를 가지고 있으며 문제가 적습니다. 일반적으로 쿼리 변환을 수행하지 않는 경우보다 쿼리 변환의 효율성이 더 높습니다. 이는 CBO 옵티마이저와 밀접하게 관련되어 있으며 10G에서 도입되었으며 매우 유용합니다. 따라서 내부적으로는 많은 버그가 존재하며, 쿼리 변환 실패 시 여러 가지 어려운 SQL이 자주 나타나는데, 이는 쿼리 변환이 실패하면 Oracle이 더 나은 구조의 SQL로 변환할 수 없기 때문입니다. (프로세서 처리) 선택할 수 있는 실행 경로가 훨씬 적습니다. 예를 들어 하위 쿼리가 UNNEST가 될 수 없으면 이는 종종 재난의 시작입니다. 실제로 오라클이 쿼리 변환에 있어서 가장 많이 하는 일은 다양한 쿼리를 JOIN 방식으로 변환하여 HASH JOIN과 같이 효율적인 다양한 JOIN 방식을 사용할 수 있도록 하는 것입니다.
쿼리 변환 방법은 30가지가 넘습니다. 일반적인 경험적 방법과 COST 기반 쿼리 변환 방법은 다음과 같습니다.
휴리스틱 쿼리 변환(일련의 RULE):
RBO 사례에는 이미 많은 휴리스틱 쿼리 변환이 존재합니다. 일반적인 것들은 다음과 같습니다:
Simple View merge(단순 뷰 병합), SU(Subquery unnest subquery 확장), OJPPD(이전 스타일 Join predicate push-down 이전 Join predicate push 방법), FPD(Filter push) -down 필터 조건자 푸시), OR 확장(OR 확장), OBYE(Order by Elimination), JE(Join Elimination 연결 제거 또는 연결에서 테이블 제거), Transitive Predicate(조건자 전송) 및 기타 기술입니다.
COST 기반 쿼리 변환(COST로 계산):
복잡한 명령문에 대한 COST 기반 쿼리 변환, 일반적인 변환은 다음과 같습니다.
CVM(Complex view Merging) 뷰 병합 ), JPPD(Join predicate push-down), DP(고유 배치), GBP(배치별 그룹화) 및 기타 기술입니다.
일련의 쿼리 변환 기술을 통해 원본 SQL을 옵티마이저가 이해하고 분석하기 쉬운 SQL로 변환하여 더 많은 술어, 연결 조건 등을 활용하여 목적을 달성할 수 있도록 합니다. 최선의 계획을 얻는 것. 변환 과정을 조회하려면 10053을 통해 자세한 정보를 얻을 수 있습니다. 쿼리 변환이 성공할 수 있는지 여부는 버전, 최적화 제한 사항, 암시적 매개 변수, 패치 등과 관련됩니다.
MOS에서 쿼리 변환을 검색하면 많은 버그가 나타납니다.
이런 종류의 BUG가 발생하는 것은 성능 문제가 아니라 심각한 데이터 정확성 문제입니다. 이런 버그는 많지만 실제 애플리케이션에서는 덜 발생할 수 있다고 생각합니다. 언젠가 SQL 쿼리의 결과가 잘못되었다는 것을 알게 되면 과감히 질문해야 합니다. 일반적으로 문제가 발생했을 때 질문하는 것은 매우 올바른 사고 방식입니다. 이러한 잘못된 결과 문제는 데이터베이스 메이저 버전 업그레이드 과정에서 볼 수 있습니다.
-
원래 결과는 맞았는데 지금은 결과가 틀려요. --새 버전 BUG 발생
이제 결과는 정확하지만 원래 결과가 잘못되었습니다. --새 버전에서는 이전 버전의 BUG가 수정되었습니다
첫 번째 상황은 정상이지만, 두 번째 상황도 있을 수 있습니다. 고객이 업그레이드 후 결과가 잘못되었다고 문의하는 것을 보았습니다. , 그리고 검증 결과 이전 버전의 실행 계획이 잘못된 것으로 밝혀졌고, 새 버전의 실행 계획은 정확했습니다. 즉, 업그레이드 후 수년 동안 발견되지 않고 잘못되었습니다. 옳다고 생각했지만 그들은 그것이 틀렸다고 생각했습니다.
잘못된 결과가 나오면 핵심 기능이 아닌 경우에는 정말 몇 년 동안 깊이 묻혀 있을 수도 있습니다.
Estimator( Estimator):
분명히 Estimator는 통계 정보(테이블, 인덱스, 컬럼, 파티션 등)를 사용하여 해당 실행 계획 작업을 추정합니다. Selectivity를 통해 해당 Operation의 Cardinality를 계산하고, 해당 Operation의 COST를 생성하며, 최종적으로 전체 Plan의 COST를 계산합니다. 추정자에게 있어서 가장 중요한 것은 추정모델의 정확성과 통계정보 저장의 정확성입니다. 추정된 모델이 과학적일수록 더 많은 통계정보가 실제 데이터 분포를 반영하고 더 많은 것을 포괄할 수 있습니다. 특수 데이터를 사용하면 생성된 COST가 더 정확해집니다.
그러나 이는 불가능합니다. 예를 들어 문자열에 대한 선택도를 계산할 때 ORACLE은 내부적으로 문자열을 RAW 유형으로 변환합니다. , RAW 유형 을 숫자로 변환한 후 왼쪽에서 15자리를 ROUND하면 문자열이 매우 다를 수 있습니다. 변환 후 숫자가 15자리를 초과하므로 내부 변환 후에도 결과는 유사할 수 있습니다. 이로 인해 궁극적으로 선택성이 부정확하게 계산됩니다.
Plan Generator(Plan Generator):
Plan Generator는 다양한 액세스 경로, JOIN 방법, JOIN 시퀀스를 분석하여 다양한 실행 계획을 생성합니다. 그래서 이 부분에 문제가 있을 경우 해당 부분의 알고리즘이 부족하거나 한계가 있을 수 있습니다. 예를 들어, JOIN 테이블이 많으면 다양한 액세스 순서의 선택이 기하급수적으로 증가합니다. ORACLE에는 제한이 있으므로 모두 계산할 수 없습니다.
예를 들어 HASH JOIN 알고리즘은 일반적으로 빅 데이터 처리에 선호되는 알고리즘입니다. 그러나 HASH JOIN에는 본질적으로 HASH 충돌이 발생하면 효율성이 크게 저하됩니다.
CBO 옵티마이저에는 많은 제한 사항이 있습니다. 자세한 내용은 MOS: Oracle Cost Based Optimizer의 제한 사항(문서 ID 212809.1)을 참조하세요.
2. CBO 옵티마이저 함정에 대한 해결 방법
이 섹션에서는 현재 CBO 옵티마이저가 널리 사용되고 있으므로 일부 문제는 CBO 옵티마이저에만 국한되지 않습니다. , 항상 CBO 문제를 포함합니다.
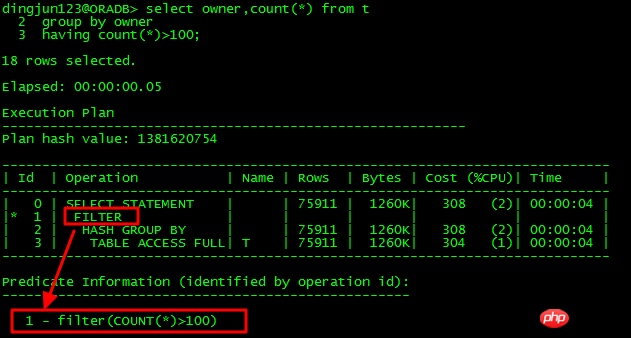
1 FILTER 성능 저하 문제
FILTER 작업은 실행 계획에서 일반적인 작업입니다. 이 작업에는 두 가지 상황이 있습니다.
한 가지만 있습니다. 하위 노드인 경우 이는 간단한 필터링 작업입니다.
를 반복하여 검색하되 기존 결과를 사용하여 효율성을 높이세요. 그러나 반복되는 일치 항목이 줄어들고 루프가 많아지면 FILTER 작업이 성능에 심각한 영향을 미치고 며칠 동안 SQL을 실행하지 못할 수도 있습니다. - 단일 하위 노드:
 여러 하위 노드:
여러 하위 노드:
FILTER 여러 하위 노드는 종종 성능 저하를 초래합니다. 이는 주로 하위 쿼리를 UNNEST 쿼리로 변환할 수 없는 상황(NOT IN 하위 쿼리 및 OR 연속 사용)에서 발생합니다. , 복잡한 하위 쿼리 등
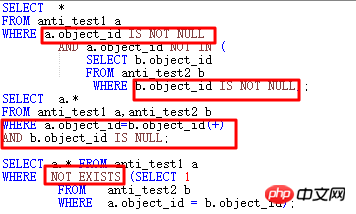
(1) NOT IN 하위 쿼리의 FILTER
먼저 NOT IN 상황을 살펴보겠습니다.
위 NOT IN 하위 쿼리의 경우 하위 쿼리 object_id에 NULL이 있으면 11g 이전에는 기본 테이블과 하위 테이블의 object_id가 있으면 전체 쿼리에 결과가 없습니다. 동시에 NOT NULL 제약 조건이 없거나 IS NOT NULL 제한이 추가되지 않은 경우 ORACLE은 FILTER를 사용합니다. 11g에는 효율성을 향상시키기 위해 하위 쿼리를 UNNEST할 수 있는 새로운 ANTI NA(NULL AWARE) 최적화가 있습니다.
11g에는 아래와 같이 NOT IN 문제에 특별히 최적화된 NULL AWARE가 있습니다.
NULL AWARE 작업은 UNNEST할 수 없는 NOT IN 하위 쿼리를 처리하는 데 사용됩니다. JOIN 형태로 변환할 수 있어 효율성이 대폭 향상됩니다. NOT IN이 발생하고 11g 이전에 UNNEST할 수 없는 경우 어떻게 해야 합니까?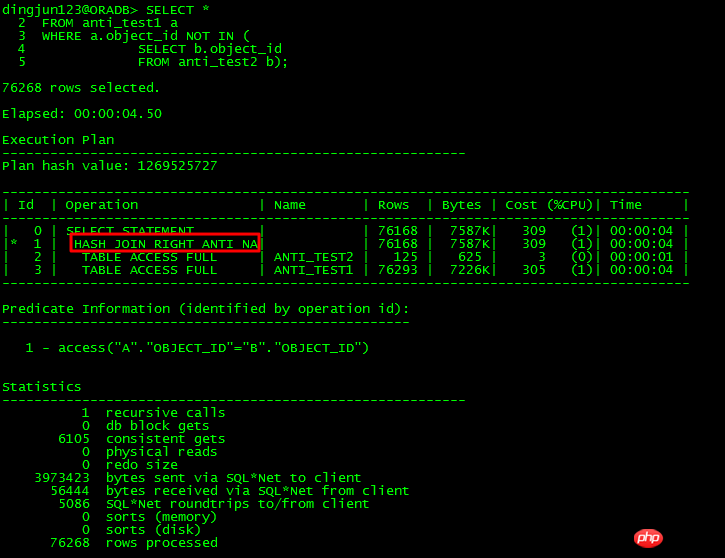
NOT IN 부분의 일치 조건을 설정합니다. 이 예에서는 ANTI_TEST1.object_id와 ANTI_TEST2.object_id가 모두 NOT NULL 제약 조건으로 설정됩니다.
NOT NULL 제약 조건을 변경하지 않는 경우 두 object_id 모두에 IS NOT NULL 조건을 추가해야 합니다.
이 NOT EXISTS로 변경되었습니다.
을 ANTI JOIN 형식으로 변경합니다.
위 네 가지 방법을 사용하면 대부분의 경우 옵티마이저가 JOIN을 사용하도록 하는 목적을 달성할 수 있습니다.
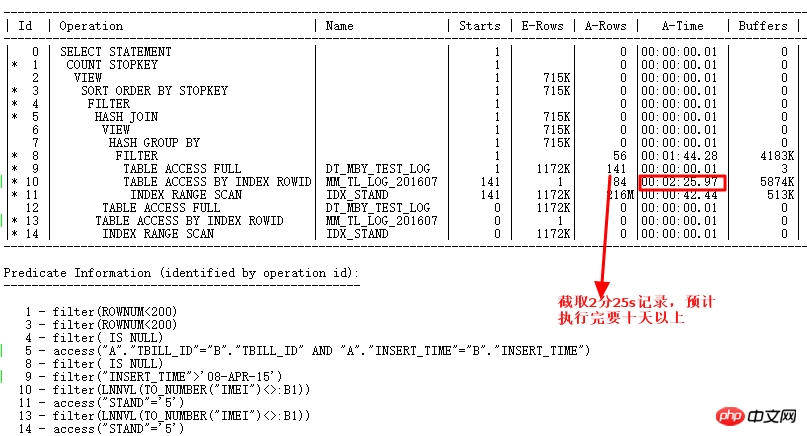
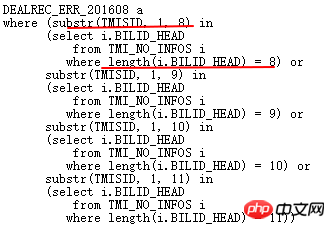
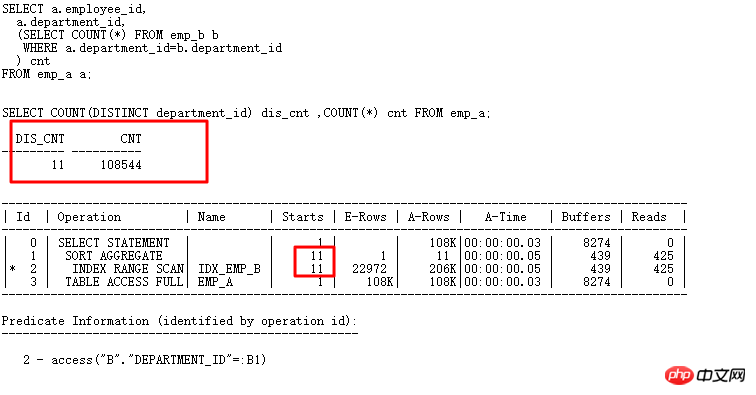
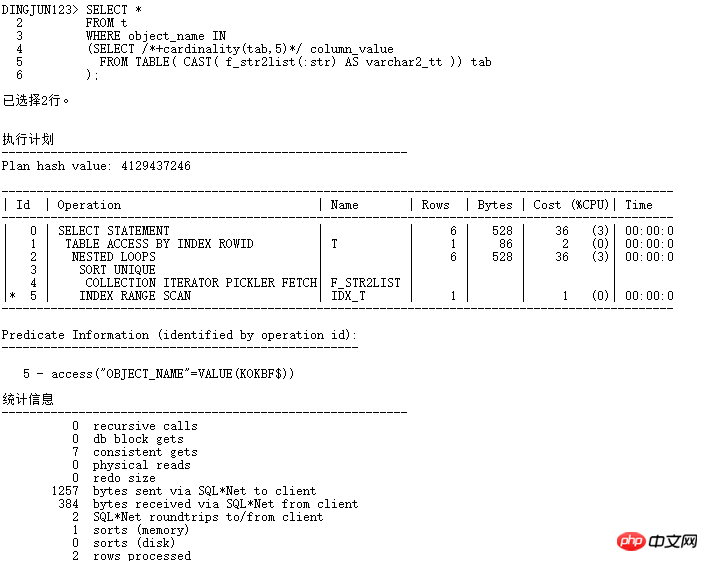
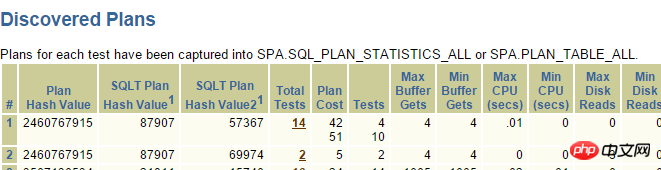
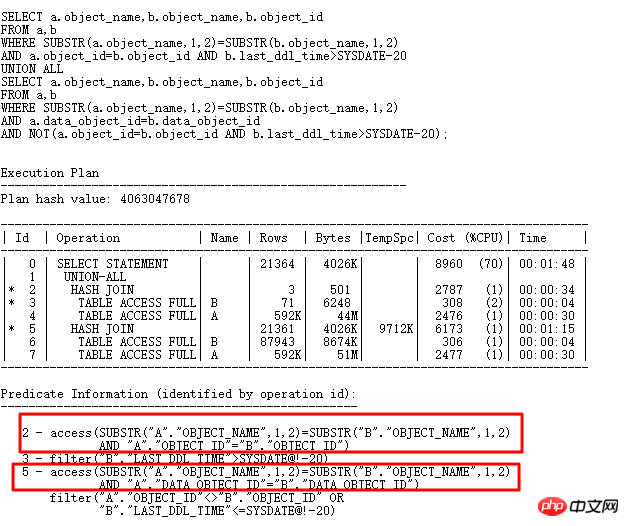
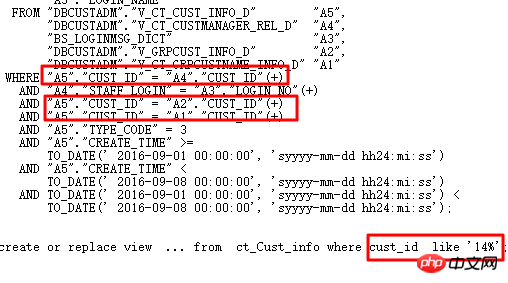
 자, 이제 데이터베이스 업그레이드 프로세스 중에 발생한 사례에 대해 이야기해 보겠습니다. 배경은 11.2.0.2에서 11.2.0.4로 업그레이드한 후 다음 SQL에 성능 문제가 있다는 것입니다. >
자, 이제 데이터베이스 업그레이드 프로세스 중에 발생한 사례에 대해 이야기해 보겠습니다. 배경은 11.2.0.2에서 11.2.0.4로 업그레이드한 후 다음 SQL에 성능 문제가 있다는 것입니다. >
실행 계획은 다음과 같습니다.
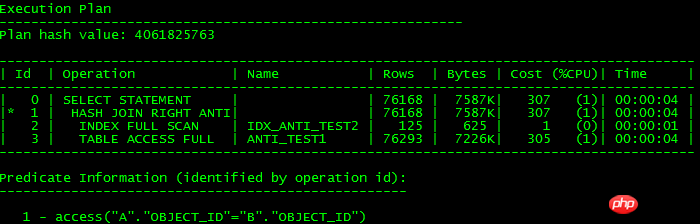
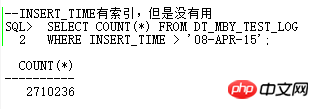
여기서 ID=4 및 ID=8인 두 FILTER에는 모두 2개의 하위 노드가 있습니다. NOT IN 하위 쿼리는 UNNEST할 수 없습니다. 위에서 언급했듯이 11g ORACLE CBO에서는 NOT IN이 NULL AWARE ANTI JOIN으로 변환이 가능하며, 11.2.0.2에서는 변환이 가능하지만 11.2.0.4에서는 변환이 불가능합니다. 두 FILTER 작업이 얼마나 유해한지 실제 실행 계획을 쿼리해 보면 알 수 있습니다.
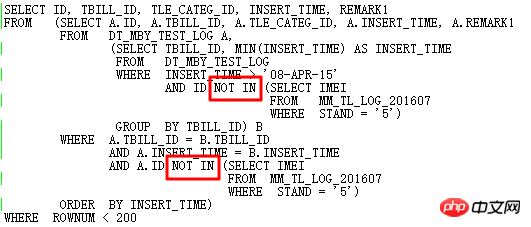 ALTER SESSION SET STATISTICS_LEVEL=ALL을 사용하여 2분 25초의 기록을 차단합니다. 실제 상황에서 ID=9 단계의 CARD=141 행은 2분 25초가 걸립니다. 실제 단계는 27w 행
ALTER SESSION SET STATISTICS_LEVEL=ALL을 사용하여 2분 25초의 기록을 차단합니다. 실제 상황에서 ID=9 단계의 CARD=141 행은 2분 25초가 걸립니다. 실제 단계는 27w 행
 입니다. 이는 이 SQL을 의미합니다. 10일 이상 실행해야 합니다. 네, 너무 무섭습니다.
입니다. 이는 이 SQL을 의미합니다. 10일 이상 실행해야 합니다. 네, 너무 무섭습니다.
이 문제에 대한 분석은 다음과 같습니다.
 수집된 통계정보가 유효한가요?
수집된 통계정보가 유효한가요?
새 버전 BUG인지, 업그레이드 중 매개변수 수정인지? 첫 번째 상황:
- 매개변수가 TRUE이므로 당연히 문제가 없습니다.
- 두 번째 상황: 통계정보 수집이 무효인 것으로 확인되었습니다.
- 현재로서는 세 번째 상황에만 희망을 걸 수 있습니다. 업그레이드 프로세스 중에 수정된 버그나 기타 매개변수가 NULL AWARE ANTI JOIN을 사용할 수 없는 데 영향을 미칠 수 있습니다. ORACLE 버그와 매개변수가 너무 많은데 어떤 BUG나 매개변수가 문제의 근본 원인을 일으키는지 어떻게 빨리 찾을 수 있을까요? 여기에서는 전체 이름이 (SQLTXPLAIN)인 SQLT라는 아티팩트를 공유하고 싶습니다. 이는 ORACLE 내부 성능 부서에서 개발한 도구로 MOS에서 다운로드할 수 있으며 매우 강력한 기능을 가지고 있습니다.
본론으로 돌아가서, 이제 문제가 새 버전의 BUG로 인해 발생한 것인지 아니면 수정된 매개변수로 인해 발생한 것인지 알아내야 합니다. 그런 다음 SQLT의 고급 방법인 XPLORE를 사용해야 합니다. XPLORE는 ORACLE에서 다양한 매개변수를 지속적으로 열고 닫아 실행 계획을 출력합니다. 마지막으로 생성된 보고서를 통해 일치하는 실행 계획을 찾아 버그 문제인지 매개변수 설정 문제인지 판단할 수 있습니다.

readme.txt를 참고하여 테스트해야 할 SQL에 대해 별도의 파일을 편집하는 것이 일반적으로 XPLAIN 방식을 사용합니다. 테스트를 위해 EXPLAIN PLAN FOR를 호출하세요. 테스트 효율성을 보장하세요.
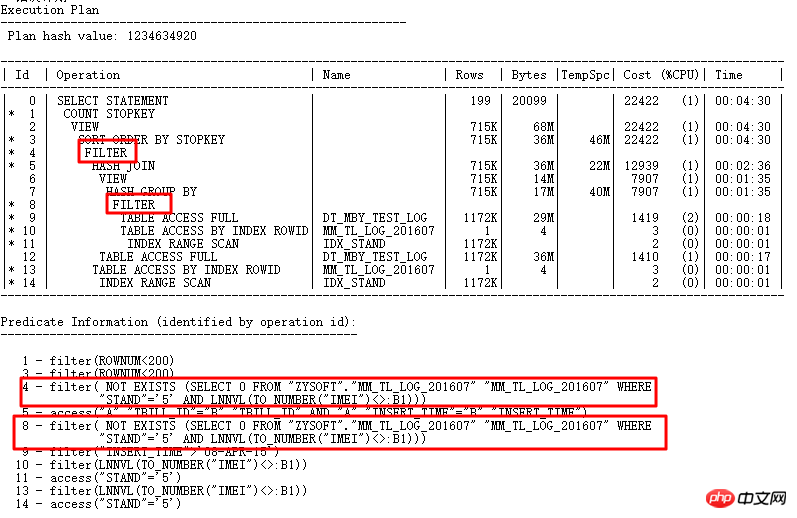
SQLT 문제의 근본 원인 찾기:

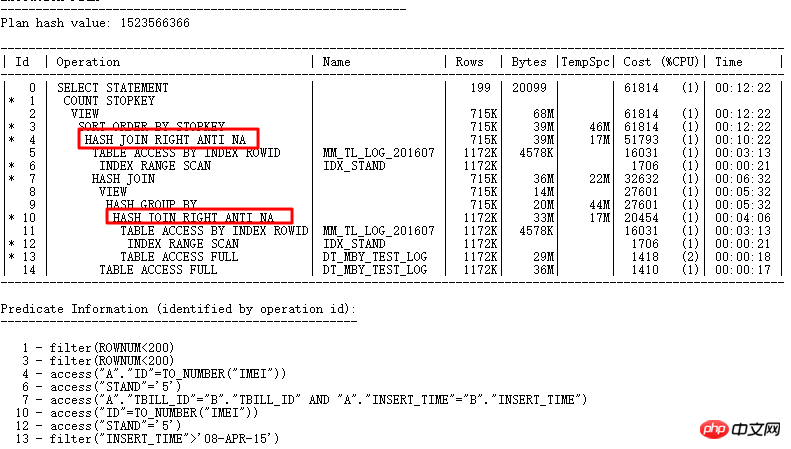
마지막으로 SQLT XPLORE를 통한 문제의 근본 원인 새 버전에서는 _optimier_squ_bottomup 매개변수(하위 쿼리 관련)가 꺼졌습니다. 또한 이 시점에서 많은 쿼리 변환이 성공할 수 있으며 하나의 매개변수가 작동할 뿐만 아니라 여러 매개변수가 함께 작동할 수도 있음을 알 수 있습니다. 따라서 기본 매개변수를 끄고, 특별한 이유가 없는 한 기본값을 쉽게 변경하지 마세요. 이 시점에서 이 문제는 SQLT의 도움으로 신속하게 해결되었습니다. SQLT를 사용하지 않았다면 문제를 해결하는 과정은 분명히 더 어려울 것입니다. 일반적인 상황에서는 개발자가 먼저 SQL을 수정해야 할 것으로 추정됩니다.
생각해 보세요. 원본 SQL을 더 최적화할 수 있을까요?
원래 SQL은 셀프 조인과 두 개의 하위 쿼리를 사용하므로 중복되고 복잡합니다. 당연히 자체 조인을 방지하여 효율성을 높이기 위해 분석 기능으로 다시 작성하는 것이 좋습니다. 다시 작성된 SQL은 다음과 같습니다. 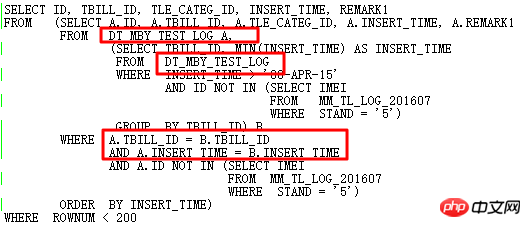
실행 계획:
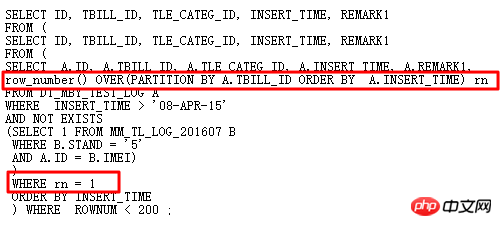
이 시점에서 이 SQL에는 FILTER가 필요합니다. 원본 문제의 근본 원인을 찾고 NULL AWARE ANTI JOIN을 사용하는 데 7초 이상이 걸렸습니다. 마침내 완전히 다시 작성하는 데 3.8초가 걸렸습니다.
(2) OR 하위 쿼리의 FILTER 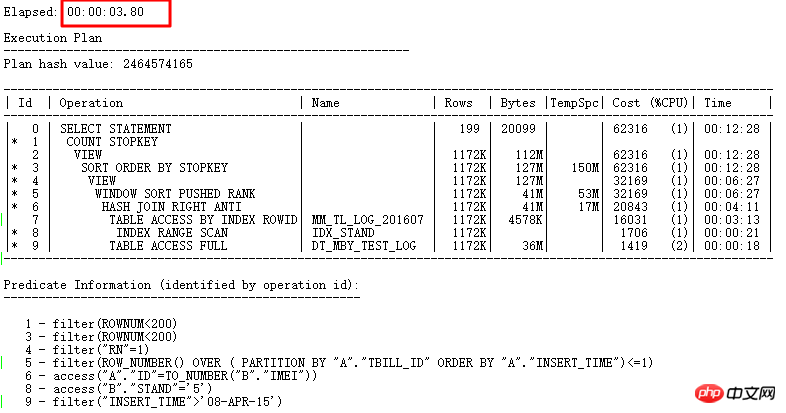
- in (조건1 또는 조건 2인 탭에서 선택)
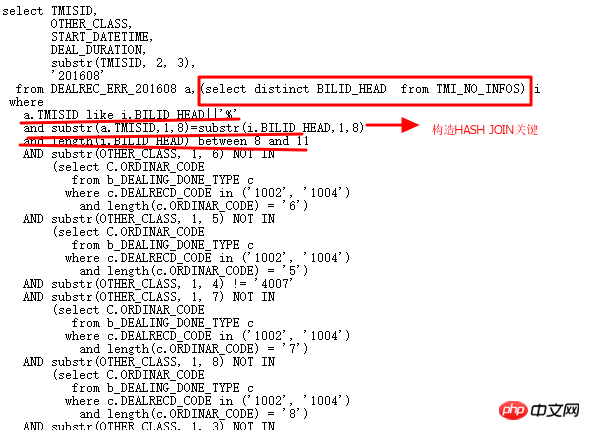
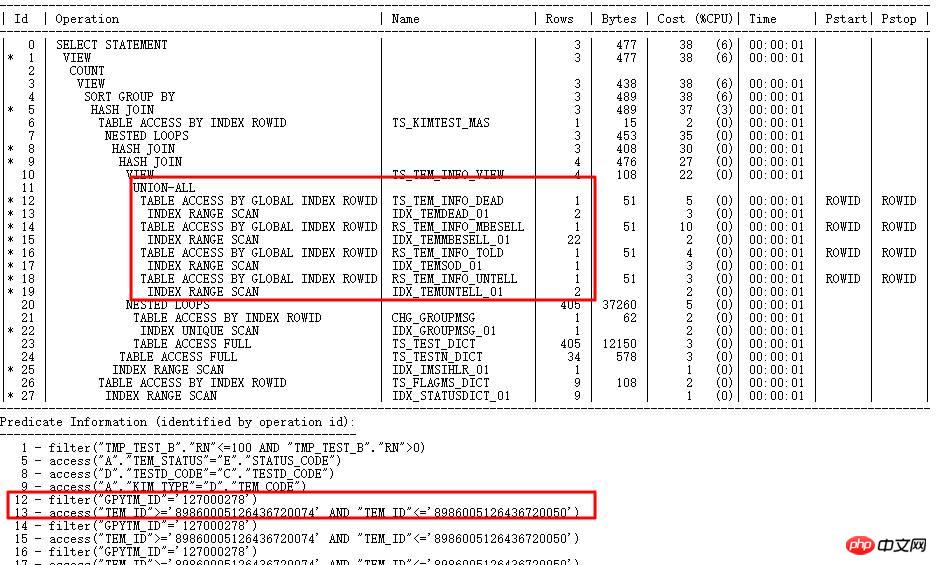
- 특정 사례를 통해 OR 하위 쿼리 최적화 처리 방법을 공유하겠습니다. 11g R2 특정 라이브러리에서 다음과 같은 SQL을 만났습니다. , 몇 시간 동안 실행되지 않은 경우:
먼저 실행 계획을 살펴보겠습니다.

이 실행 계획을 보면 성능 저하의 원인을 한눈에 찾을 수 있는 방법은 무엇일까요? 포지셔닝은 주로 다음과 같은 점을 통해 분석됩니다.
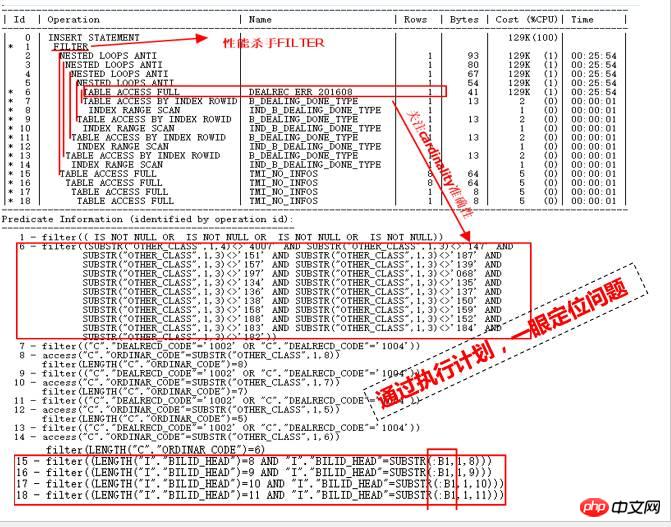
- ID=15~18 부분을 살펴보세요. 이는 ID=1 FILTER 작업의 두 번째 하위 노드입니다. ID=2 실제로 추정된 카디널리티 오류가 크다면 ID=15~18인 4개의 테이블에 대한 전체 스캔 횟수가 많아져 재앙이 발생할 수 있다.
- 분명히 ID=2 부분에 있는 NESTED LOOPS도 매우 의심스럽습니다. 전체 테이블에서 ID=2 작업의 입구가 발견됩니다. DEALREC_ERR_201608에 대해 스캔되었으며 1이 반환된 것으로 추정됩니다. 당연히 이것이 NESTED LOOPS 작업의 근본 원인이므로 정확성을 확인해야 합니다.
-
메인 테이블 DEALREC_ERR_201608은 ID=6 쿼리 조건에서 2천만 개의 행을 반환합니다. 계획에는 1개의 행만 있는 것으로 추정됩니다. 따라서 NESTED LOOPS 수는 실제로 수천만 번 실행될 것입니다. 효율성이 낮으면 HASH JOIN을 사용해야 합니다.
또한 ID=1은 FILTER이고 그 하위 노드는 ID=2이고 ID=15, 16, 17, 18입니다. 동일한 ID 15~18도 수천만 번 구동되었습니다. .
문제의 원인을 찾은 후 단계별로 해결해 보세요. 먼저 ID=6 부분의 DEALREC_ERR_201608 테이블에 대한 쿼리 조건 substr(other_class, 1, 3) NOT IN ('147', '151', …)으로 얻은 카디널리티의 정확성을 풀어야 합니다. , 통계 정보를 수집합니다.
그러나 size auto와 sizepeat를 사용해도 other_class에 대한 히스토그램 수집에는 아무런 영향을 미치지 않는 것으로 나타났습니다. 실행 계획에서 other_class에 대한 쿼리 조건 반환 추정은 여전히 1(실제 2천만 행)이었습니다.

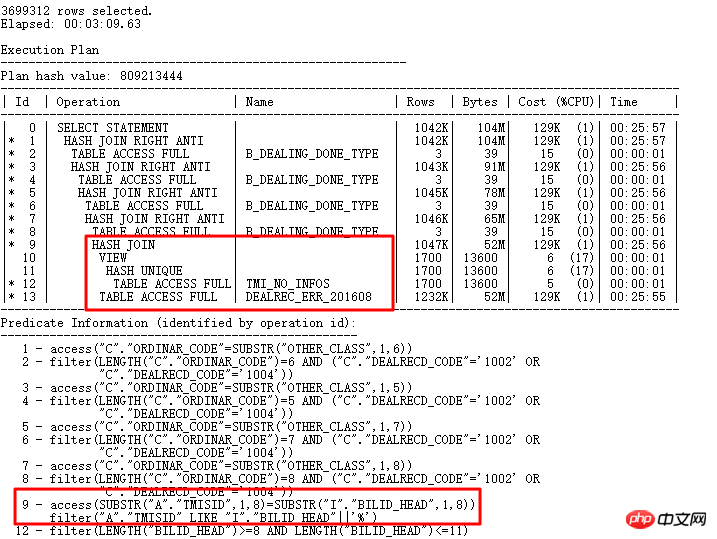
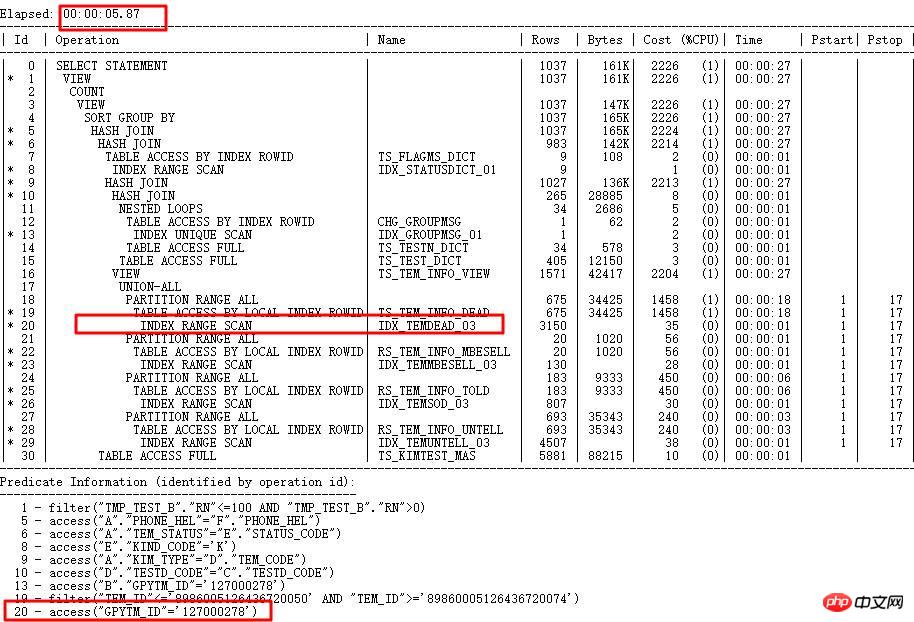
다시 실행 후 실행 계획은 다음과 같습니다.
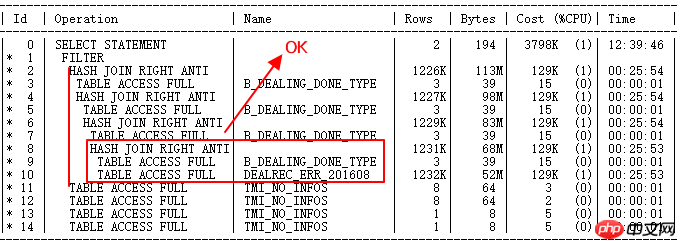
DEALREC_ERR_201608 및 B_DEALING_DONE_TYPE 원래 NL로 이동 이제 HASH JOIN이 올바르게 작동합니다. 빌드 테이블은 작은 결과 세트이고, 프로브 테이블은 ERR 테이블의 큰 결과 세트입니다.
그러나 ID=2 및 ID=11 ~ 14, 즉 TMI_NO_INFOS 또는 FILTER를 사용한 OR 하위 쿼리는 수천만 개의 하위 노드 쿼리를 구동합니다. 이것이 다음 최적화입니다. 질문을 해결해야합니다.
공연은 12시간부터 2시간까지.
지금 해결해야 할 것은 FILTER 문제입니다. 간단한 조건을 쿼리하고 변환할 수 있는 경우 일반적으로 공용체로 변환됩니다. after all view 그런 다음 세미 조인과 안티 조인을 수행합니다(Union All 뷰로 변환, 조건자 유형이 다른 경우 SQL에서 오류를 보고할 수 있음). 이러한 복잡성으로 인해 최적화 프로그램은 변환을 쿼리할 수 없으므로 다시 작성하는 것이 유일한 실행 가능한 방법입니다. SQL을 분석해 보니 쿼리는 동일한 테이블이고, 조건은 비슷하지만 길이가 달라서 다루기 편해요!
OR을 사용한 하위 쿼리 실행 계획을 FILTER에서 JOIN으로 변경하는 방법입니다. 두 가지 방법:
1) UNION ALL/UNION으로 변경
2) Semantic rewriting은 이전에 사용되었으며, 계속해서 UNION과 같은 작업으로 변환되었습니다. 테이블 액세스를 줄이면 UNION 연산으로의 변환을 피하기 위해 OR 조건을 완전히 다시 작성할 수만 있습니다.
원래 OR 조건을 분석해 보겠습니다.
위의 의미는 ERR의 TMISID 중 처음 8, 9, 10, 11자리가 테이블 일치 TMI_NO_INFOS.BILLID_HEAD , 해당 일치 BILLID_HEAD 길이는 정확히 8,9,10,11입니다. 분명히 의미는 다음과 같이 다시 작성될 수 있습니다.
ERR 테이블은 TMI_NO_INFOS 테이블과 연관되어 있습니다. ERR.TMISID의 처음 8자리는 ITMI_NO_INFOS.BILLID_HEAD의 처음 8자리와 정확히 일치하며 길이는 8- 11. 이 전제 하에서 TMISID는 'BILLID_HEAD %'와 같습니다.
이제 여러 OR 하위 쿼리를 완전히 변경하여 SQL을 더욱 간소화하고 효율적으로 만드세요.
실행 계획은 다음과 같습니다.
1) 현재 실행 계획이 드디어 더 짧고 더 쉽게 읽은 후 HASH JOIN을 논리를 통해 다시 작성했습니다. 300만 행 이상의 데이터를 반환한 최종 SQL은 원래 실행하는 데 12시간이 걸렸지만 이제는 3분 만에 실행됩니다.
2) 생각하기: 좋은 구조와 명확한 의미를 가지고 SQL을 작성하면 옵티마이저가 보다 합리적인 실행 계획을 선택하는 데 도움이 됩니다. 따라서 SQL을 잘 작성하는 것도 기술적인 일입니다.
이 사례를 통해 쿼리 변환기 역할을 하는 SQL을 작성하는 방법에 대한 영감을 얻을 수 있기를 바랍니다. 작성된 SQL은 테이블, 인덱스, 파티션 등에 대한 액세스를 줄이고, ORACLE이 효율적인 알고리즘 작업을 사용하여 SQL 실행 효율성을 향상시키는 것이 더 쉽습니다.
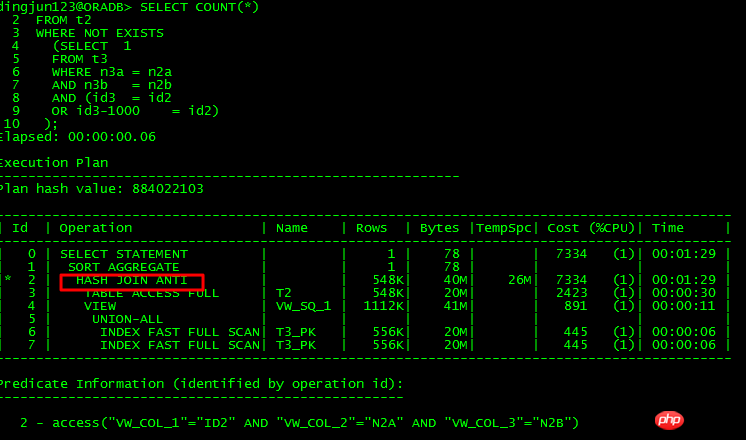
사실 OR 하위 쿼리가 반드시 중첩 해제될 수 없다는 의미는 아니며 단지 대부분의 경우 중첩 해제될 수 없다는 의미입니다.
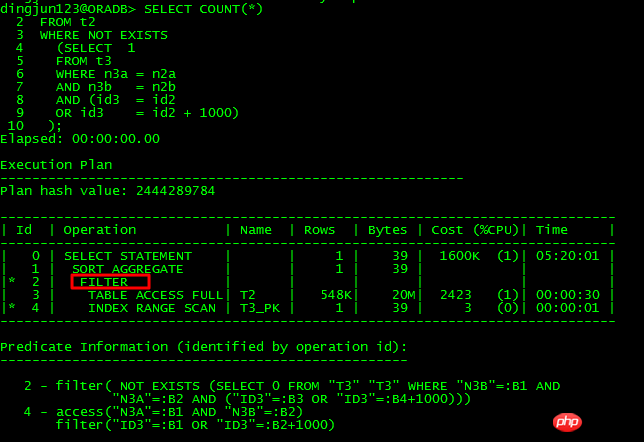
중첩 해제할 수 없는 쿼리입니다. 중첩 해제:
중첩 해제 가능 쿼리:
이 두 SQL의 차이점은 조건 또는 id3을 변환하는 것입니다. = id2-1000 into 또는 id3 -1000 = id2, 전자는 unnest가 불가능하고, 후자는 unnest가 가능함을 분석하면 다음과 같이 알 수 있습니다.
unnest 발생:
SU: 중첩 해제에 유효한 쿼리 블록 SEL$1(#1)에서 쿼리 블록을 중첩 해제합니다.
쿼리 블록 SEL$1(#1)에서 하위 쿼리 중첩 해제SU: 비용 계산이 필요하지 않은 중첩 해제를 수행합니다.
SU: 쿼리 블록 SEL$1(#1)에서 하위 쿼리 중첩 해제를 고려합니다.
SU: 중첩 해제된 하위 쿼리 SEL$2(#2)의 유효성을 확인하는 중
SU: SU 우회: 잘못된 상관 조건자.
SU: 유효성 검사에 실패했습니다.
중첩되지 않은 것으로 나타날 수 있음:
그리고 SQL을 다음과 같이 다시 작성합니다.
마지막으로 CBO는 먼저 T3 조건을 쿼리하고 UNION ALL 뷰를 만든 다음 이를 T2와 연결합니다. 이러한 관점에서 OR 하위 쿼리에 대한 중첩 해제 요구 사항은 상대적으로 엄격합니다. 이 문을 분석하면 ORACLE은 기본 테이블 열에 대한 작업 없이 중첩 해제 작업을 수행할 수 있습니다. 최적화 프로그램 자체는 +1000 조건을 왼쪽으로 이동하지 않습니다. . 엄격하기 때문에 대부분의 경우 OR 하위 쿼리는 중첩 해제될 수 없으므로 다양한 성능 문제가 발생합니다.
(3) FILTER 유사 문제
FILTER 유사 문제는 주로 UPDATE 관련 업데이트 및 스칼라 하위 쿼리에 반영됩니다. 이러한 SQL 문에는 FILTER 키워드가 명시적으로 나타나지 않지만 내부 작업은 FILTER 작업과 완전히 동일합니다.
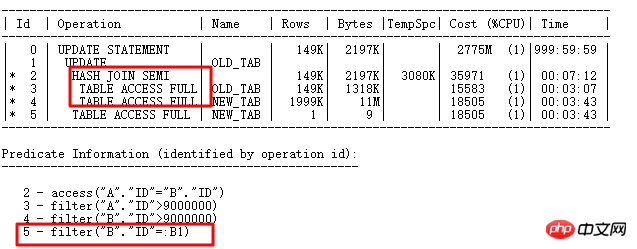
먼저 UPDATE 연관 업데이트를 살펴보세요.
여기에서 14999개의 행을 업데이트해야 합니다. 실행 계획은 다음과 같습니다.
ID=2 부분은 존재 여부 선택 부분으로, 먼저 업데이트가 필요한 조건을 쿼리한 후, UPDATE 관련 서브 쿼리 업데이트를 실행하면 바인딩 변수가 나타나는 것을 확인할 수 있습니다. ID=5 부분: B1. 분명히 UPDATE 작업은 원본 FILTER에서와 유사하며, 선택된 각 행과 하위 쿼리 테이블 NEW_TAB과 관련된 쿼리에 대해 ID 열에 반복되는 값이 적으면 하위 쿼리가 많이 실행됩니다. 이는 효율성에 영향을 미칩니다. 즉, ID=5인 작업을 많이 실행해야 합니다.
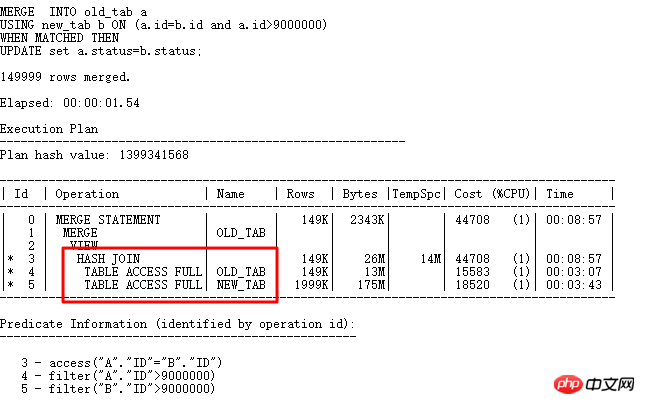
물론 여기의 필드 ID는 매우 고유합니다. UNIQUE INDEX 또는 일반 INDEX 라이트를 생성하면 5단계에서 인덱스를 사용할 수 있습니다. 다음은 이 UPDATE 최적화 방법의 예입니다. 인덱스를 작성하지 않고도 UPDATE: MERGR 및 UPDATE INLINE VIEW 방법을 구현할 수도 있습니다.
MERGE에서 직접 HASH JOIN을 사용하여 다중 액세스 작업을 방지함으로써 효율성을 크게 높일 수 있습니다. UPDATE LINE VIEW를 작성하는 방법을 살펴보겠습니다.
업데이트
(SELECT a.status astatus,
b.status bstatus
FROM old_tab a,
new_tab b
WHERE a .id= b.id
AND a.id >9000000
)
SET astatus=bstatus;
에는 b.id가 보존된 키(고유 인덱스, 고유 제약 조건, 기본 키), 11g 우회_ujvc는 MERGE 작업과 유사하게 오류를 보고합니다.
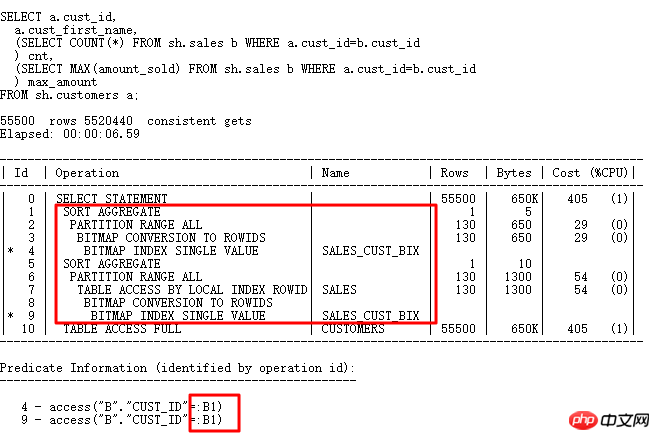
스칼라 하위 쿼리를 살펴보겠습니다. 스칼라 하위 쿼리는 종종 심각한 성능 문제를 일으키는 원인이 됩니다.
스칼라 하위 쿼리 계획 및 일반 실행 계획 순서는 다릅니다. 스칼라 하위 쿼리는 아래 CUSTOMERS 테이블의 결과에 따라 결정됩니다. 각 행은 FILTER 작업과 유사한 스칼라 하위 쿼리(CACHE 제외)를 구동합니다.
스칼라 하위 쿼리를 최적화하려면 일반적으로 SQL을 다시 작성하고 스칼라 하위 쿼리를 외부 조인 형식으로 변경해야 합니다(제약 조건과 비즈니스가 만족되면 일반 JOIN으로 다시 작성할 수도 있음) :
재작성 후 효율성이 크게 향상되며, HASH JOIN 알고리즘을 사용합니다. 스칼라 하위 쿼리에서 CACHE를 살펴보겠습니다. (FILTER 및 UPDATE 관련 업데이트는 유사합니다.) 관련 열에 반복되는 값이 많으면 하위 쿼리가 덜 자주 실행되며 이때 효율성이 더 좋아집니다. 🎜>
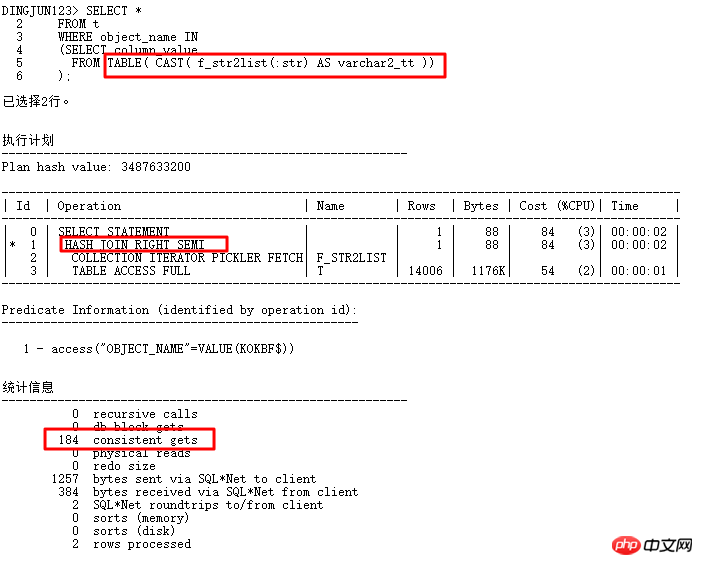
스칼라 하위 쿼리는 FILTER와 동일하며 CACHE가 있습니다. 예를 들어 위의 emp_a에는 108K 행이 있지만 반복되는 Department_id는 11뿐입니다. 이렇게 하면 쿼리는 검색만 합니다. 11번이고 서브쿼리 테이블의 스캔 횟수가 적어 효율성이 향상됩니다. FILTER 성능 저하 문제와 관련하여 저는 주로 이 3가지 사항을 공유합니다. 물론 그 외에도 주목할 만한 사항이 많이 있는데, 익숙해지려면 매일 더 많은 관심과 축적이 필요합니다. 옵티마이저의 일부 문제를 처리하는 방법에 대해 설명합니다. 2 TABLE 함수 8168 카디널리티 문제
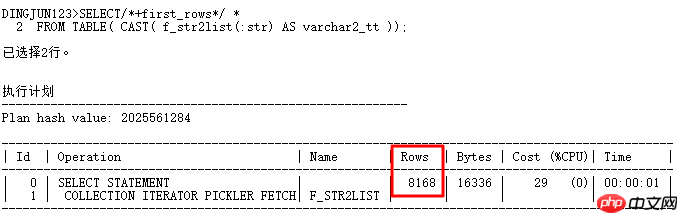
이 문제는 TABLE 함수를 사용하여 들어오는 쉼표로 구분된 값을 구성하는 목록 바인딩 문제에서 발생합니다. 서브 쿼리로서 일반적으로 프런트 엔드에서는 더 적은 값을 전달하지만 실제로는 HASH JOIN 연산 후에 T 테이블 인덱스를 사용할 수 없습니다. 일단 실행 빈도가 높으면 필연적으로 테이블에 더 큰 영향을 미치게 됩니다. ORACLE은 TABLE 함수가 매우 적은 값을 전달한다는 사실을 왜 인식하지 못합니까? 추가 분석:위 결과에서 TABLE 함수의 기본 행 수는 8168개임을 알 수 있습니다(TABLE 함수로 생성된 의사 테이블에는 통계 정보가 없음). 이 값은 작지 않으며 일반적으로 훨씬 더 많습니다. 실제 애플리케이션의 행 수보다 많아 실행 계획이 중첩 루프 대신 해시 조인을 거치는 경우가 많습니다. 물론, 힌트 프롬프트를 통해 실행 계획을 변경할 수 있습니다. 목록에서 일반적으로 사용되는 힌트는
first_rows, index, Cardinality, use_nl 등입니다.
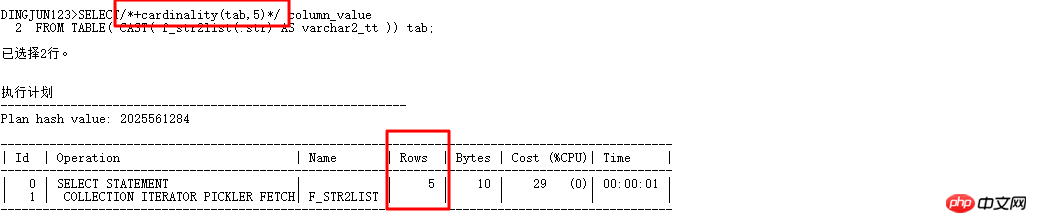
다음은 카디널리티(table|alias,n)에 대한 특별한 소개입니다. 이 힌트는 CBO 최적화 프로그램이 테이블의 행 수를 n이라고 생각하게 하여 실행 계획을 세우게 할 수 있습니다. 변경될 수 있습니다. 이제 위의 쿼리를 다시 작성합니다.
Add Cardinality(tab,5)를 사용하면 CBO 최적화 프로그램이 자동으로 테이블의 카디널리티를 5로 처리하고 이전 위치는 다음과 같습니다. 기본적으로 목록 쿼리 기반이 8168이었을 때 해시 조인이 사용되었습니다. 이제 카디널리티를 사용할 수 있으므로 빠르게 시도해 보세요.
이제 NESTED LOOPS 작업을 사용하고 하위 노드는 INDEX RANGE SCAN을 사용할 수 있으며 논리적 읽기가 184에서 7로 변경되고 효율성이 수십 배 향상됩니다. 물론 실제 응용프로그램에서는 힌트를 추가하지 않는 것이 가장 좋으며, SQL PROFILER 바인딩을 사용하면 됩니다.
3 부정확한 선택성 계산 문제
오라클의 내부 선택성 계산은 숫자 형식으로 계산되므로 문자열 유형을 만나면 해당 문자열을 RAW 유형으로 변환한 후 변환합니다. RAW 유형을 숫자로, ROUND를 왼쪽에서 15자리까지 하면 원래 문자열은 상당히 다를 수 있지만 내부적으로 변환된 숫자는 상대적으로 가까워서 선택 계산이 부정확할 수 있습니다. 예:
실행 계획은 다음과 같습니다.
SQL 실행 계획은 TEM_ID 인덱스를 사용하며 필요합니다. 계획에서 해당 단계의 카디널리티는 매우 작지만(수십 수준) 실제 카디널리티는 매우 커서(수백만 수준) 판단 통계 정보가 잘못되었습니다.
왜 잘못된 색인으로 이동하나요?
TEM_ID는 길이 20의 CHAR 문자열 유형이므로 CBO 내부 계산 선택성은 먼저 문자열을 RAW로 변환한 다음 RAW를 왼쪽에서 15자리 ROUND된 숫자로 변환합니다. 따라서 문자열 값이 매우 다를 가능성이 있으며, 숫자로 변환한 후 값이 유사하므로(15자리 이상은 0으로 채워져 있으므로) 선택적인 계산 오류가 발생할 수 있습니다. TS_TEM_INFO_DEAD의 TEM_ID 열을 예로 들어 보겠습니다.
조건에 따라 쿼리되는 실제 행 수는 29737305입니다. 따라서 인덱스가 잘못되었습니다.
해결 방법:
TEM_ID 열 히스토그램을 수집합니다. 내부 알고리즘의 특정 제한으로 인해 서로 다른 값을 갖는 문자열이 동일한 내부 계산 값을 가질 수 있으므로 히스토그램을 수집한 후, 문자열의 경우 값은 다르지만 숫자로 변환한 후에는 동일합니다. ORACLE은 확인을 위해 실제 값을 ENDPOINT_ACTUAL_VALUE에 저장하고 실행 계획의 정확성을 향상시킵니다. GPYTM_ID를 올바르게 색인화한 후 실행 시간은 1시간 이상에서 5초 미만입니다.
4 새로운 기능으로 인해 실행 오류 발생
각 버전마다 새로운 기능을 부적절하게 사용하면 다음과 같은 심각한 문제가 발생할 수 있습니다. ACS 및 카디널리티 피드백은 실행 계획의 잦은 변경으로 이어져 효율성에 영향을 미치고 하위 커서가 너무 많은 등의 문제가 발생합니다. 따라서 앞서 언급한 11g 널 인식 안티 조인을 포함하여 많은 버그가 있는 새로운 기능을 주의해서 사용해야 합니다.
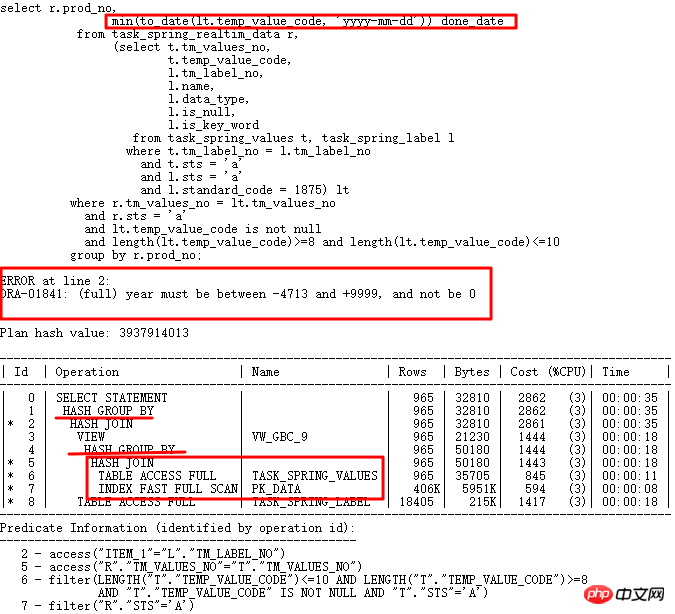
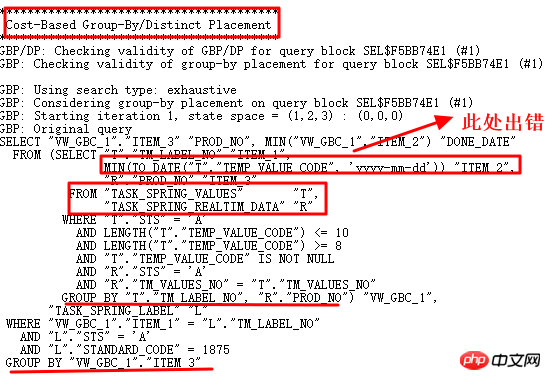
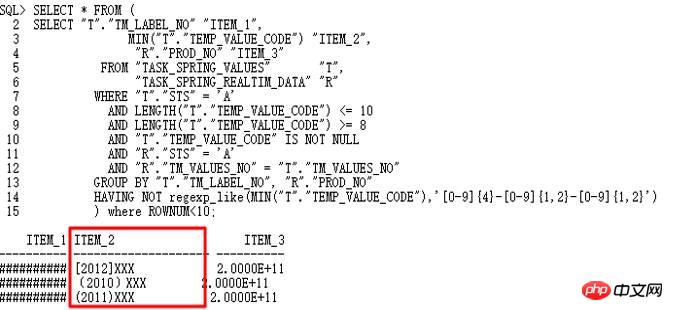
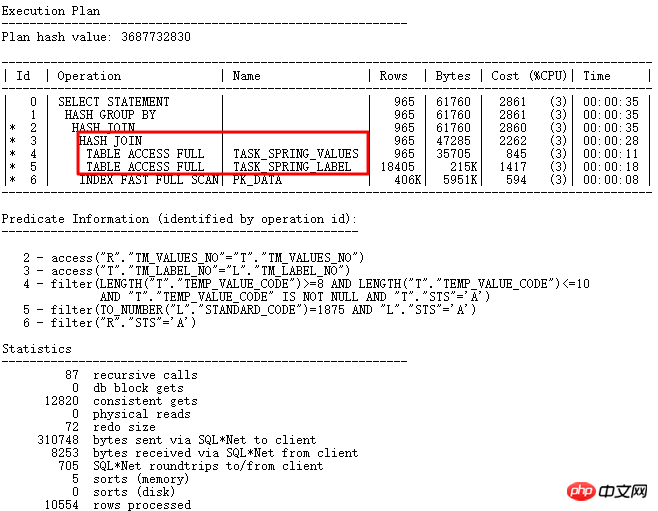
오늘 분석할 사례는 10g에서 11g으로의 메이저 버전 업그레이드 과정에서 발생한 SQL입니다. 10g에서는 정상적으로 실행되었으나, 11g에서는 잘못 실행되었습니다. SQL은 다음과 같습니다.
10g이 정상입니다. 11g r2로 업그레이드한 후 temp_value_code가 여러 형식 문자열을 저장합니다. 올바른 실행 계획: LT 관련 쿼리가 먼저 실행된 다음 테이블과 관련됩니다. 잘못된 실행 계획은 TASK_SPRING_VALUES가 먼저 테이블과 연결된 다음 VIEW로 그룹화되고 TASK_SPRING_LABEL과 연결된 다음 다시 그룹화된다는 것입니다. 여기에는 2개의 GROUP BY 작업이 있으며 이는 1개만 있는 10g 실행 계획과 다릅니다. GROUP BY 작업으로 인해 결국 오류가 발생합니다.
분명히 두 개의 GROUP BY 연산이 연구되어야 하는 이유는 10053이 첫 번째 선택입니다.
10053 연산에 따라 찾을지 여부를 분석합니다. 날짜가 아닌 형식 값:
yyyy-mm-dd가 아닌 형식의 문자열이 실제로 발견되었으므로 to_date 작업이 실패했습니다. 10053에서 볼 수 있듯이 여기서는 Group by/Distinct Placement 연산이 사용되므로 해당 제어 매개변수를 찾아 이 쿼리 변환을 꺼야 합니다.
GBP 암시적 매개변수를 끈 후 수정됨: _optimizer_group_by_placement. 올바른 실행 계획은 다음과 같습니다.
생각: 이 문제의 본질은 temp_value_code를 varchar2로 사용하여 일반 문자를 저장하는 불합리한 필드 사용 설계에 있습니다. , 숫자 및 날짜 형식 yyyy-mm -dd, 프로그램에는 to_number, to_date 및 기타 변환이 있으며 이는 실행 계획의 테이블 연결 순서 및 조건에 따라 크게 달라집니다. 따라서 좋은 디자인은 매우 중요합니다. 특히 관련 필드 유형의 일관성과 필드의 단일 역할을 보장하고 패러다임의 요구 사항을 충족하려면 더욱 그렇습니다.
5 CBO는 잘못된 작성 방법으로는 아무것도 할 수 없습니다
잘 구조화된 SQL은 CBO가 이해하기 쉽고 더 나은 쿼리 변환 작업이 가능하여 후속 세대의 기반을 마련할 수 있습니다. 최선의 실행 계획, 그리고 실제 적용 과정에서 CBO는 SQL 작성에 주의를 기울이지 않았기 때문에 아무것도 할 수 없었습니다. 다음은 페이지 매김 작성의 사례 연구입니다.
비효율적인 페이징 작성 방법:
원래 작성 방법 가장 안쪽 레이어를 use_date 및 기타 조건을 기준으로 쿼리한 후 정렬하고, rownum을 가져와서 별칭을 지정하고, 가장 바깥쪽 레이어는 rnlaw로 사용됩니다. 무엇이 문제인가요?
페이징을 직접 <,<=로 작성하는 경우 정렬(2단계 중첩) 후 바로 rownum을 가져올 수 있습니다. 간격 값을 가져와야 하는 경우 >,>=에서 가져옵니다. 가장 바깥쪽 수준(3개 수준)이 중첩됨).
이 문은 <=를 얻습니다. 세 가지 수준의 중첩을 사용하면 rownum이 조건자 푸시를 방지하여 실행 계획에 STOPKEY 작업이 발생하지 않으므로 페이징 쿼리 STOPKEY 알고리즘을 사용할 수 없습니다.
<=Paging에는 2단계 중첩만 필요하며 done_date 열에는 done_date>to_date('20150916','YYYYMMDD') 조건에 따라 인덱스가 있으며 처음 20개 행만 가져옵니다. 인덱스와 STOPKEY 알고리즘을 효율적으로 활용할 수 있으며, 재작성이 완료된 후 인덱스 내림차순 스캔을 사용하며 실행 시간은 1.72s ~ 0.01s, 논리적 IO는 42648 ~ 59 입니다.
효율적인 페이징 작성은 사양을 준수해야 하며 정렬을 없애기 위해 인덱스를 최대한 활용할 수 있습니다.
6 CBO BUG 문제
쿼리 변환 시 CBO BUG가 더 자주 나타납니다. 일단 BUG가 발생하면 찾기 어려울 수 있습니다. 이때는 빠르게 10053을 분석하거나 SQLT XPLORE를 사용해야 합니다. 문제의 원인을 찾으십시오. 예:
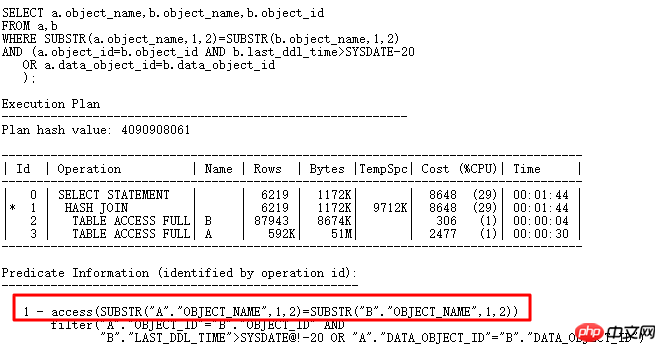
이 테이블의 oper_type에는 인덱스가 있으며 oper_type>'D' 또는 oper_type<'D' 조건이 인덱스를 사용하는 것이 더 좋지만 Oracle이 전체 테이블 스캔, SQLT를 통한 빠른 분석 >
분명히 _fix_control=8275054는 MOS를 쿼리하여 매우 의심스럽습니다.
은<> ;b. 분명히 인덱스를 사용할 수 없습니다. 이 8275054가 해결되었습니다.7 HASH 충돌 문제HASHJOIN은 빅데이터 처리에 특별히 사용되는 효율적인 알고리즘으로 테이블 빌드 테이블(해시 테이블) 및 프로브 테이블 구성에 대해 동등한 조인 조건에만 사용할 수 있습니다. 조건에 맞는 결과 집합을 찾기 위해 HASH 연산을 수행합니다.
일반적인 형식은 다음과 같습니다.
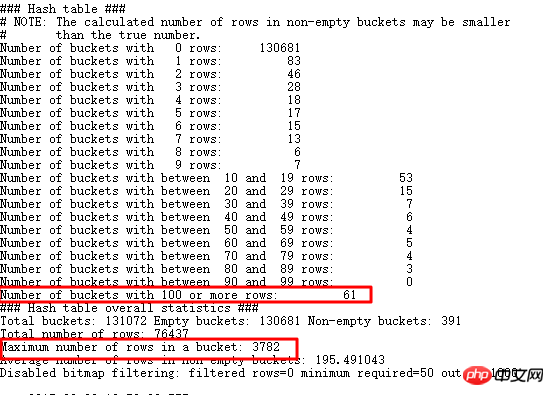
HASH JOIN빌드 테이블프로브 테이블여기의 빌드 테이블은 필터링되어야 합니다. 필터 조건에 따라 최종적으로 결과 셋은 더 작은 크기(크기는 행이 아님)의 테이블이 된 후 연결 조건에 따라 HASH 함수 연산을 수행하고 필요한 열과 HASH 함수 연산 결과가 해시에 저장됩니다. 버킷. 해시 버킷 자체는 연결된 목록 구조입니다. 마찬가지로 프로브 테이블에 대해 해시 함수 연산을 수행해야 하며, 연산 결과를 바탕으로 빌드 테이블의 해시 버킷을 쿼리하고, 결과가 발견되지 않으면 폐기됩니다. 물론 ORACLE HASH JOIN의 내부 구조는 여전히 매우 복잡합니다. 자세한 내용은 Jonathan Lewis의 CBO 원칙서를 참조하세요. HASH 검색 고유의 문제: 빌드 테이블의 조인 조건 열의 선택성이 좋지 않으면(즉, 중복 값이 너무 많을 경우) 많은 양의 데이터가 일부 해시 버킷에 저장될 수 있는데, 해시 버킷 자체가 연결 리스트 구조이기 때문에 이러한 해시 버킷을 쿼리할 때 효율성이 급격히 떨어지게 됩니다. 이 문제는 HASH 작업의 고전적인 문제인 해시 충돌(HASH Collision)입니다.해시 충돌을 분석하기 위해 작은 예를 사용해 보겠습니다.
그 중 테이블 a는 61w의 다중 레코드를 갖고, 테이블 b는 7w의 다중 레코드를 가지고 있습니다. 이 SQL 결과는 실행 계획에서 80,000개의 다중 레코드를 반환하므로 HASH를 수행하는 데 문제가 없습니다. 그러나 이 SQL의 실제 실행은 10분 이상 완료되지 않아 효율성이 매우 낮았고, CPU 사용량이 갑자기 증가하여 두 테이블에 액세스하는 시간보다 훨씬 길어졌습니다.
HASHJOIN을 알고 있다면 이때 해시 충돌이 발생했는지 고려해야 합니다. 많은 양의 데이터가 여러 버킷에 저장되어 있는 경우 이러한 해시 버킷에서 데이터를 검색하는 것은 중첩 루프와 유사합니다. . , 효율성은 필연적으로 크게 감소합니다. 추가 분석은 다음과 같습니다.
중복 데이터보다 크고 3000보다 큰 값을 찾아보세요. 물론 많습니다. 물론 더 큰 남은 데이터도 많이 있습니다. 감지 HASH JOIN을 사용하면 EVENT 10104를 사용할 수 있습니다.
100행 이상을 저장하는 버킷이 61개임을 알 수 있습니다. 가장 큰 버킷에는 3782개의 항목이 저장되어 있으며, 우리가 알아낸 내용은 일관됩니다. 원래 SQL로 돌아가 보겠습니다.
Oralce가 HASH 테이블을 구축하기 위해 왜 substr(b.object_name,1,2)를 선택했나요? OR을 확장할 수 있고 원래 SQL이 UNION ALL 형식으로 변경된다면? , HASH 테이블은 substr(b.object_name,1,2), b.object_id 및 data_object_id를 사용하여 구성할 수 있습니다. 그런 다음 고유성이 매우 좋아야 하며 이는 해시 충돌 문제를 다음과 같이 다시 작성해야 합니다.
현재 SQL 실행 시간은 원래 결과가 없는 10분에서 실행 후 4초로 늘어났습니다. 내부적으로 구성된 HASHTABLE 정보를 살펴보겠습니다.
버킷에 데이터가 6개만 저장되어 있어서 이전보다 성능이 훨씬 좋아졌을 겁니다. 해시 충돌은 매우 해롭습니다. 실제 응용 프로그램에서는 더 복잡할 수 있습니다. 해시 충돌 문제가 발생하는 경우 가장 좋은 방법은 SQL을 비즈니스 관점에서 분석하고 더 선택적인 다른 열을 추가할 수 있는지 확인하는 것입니다. .
돌아보면 UNION ALL로 다시 작성한 후 두 개의 결합된 열을 사용하여 더 나은 HASH 테이블을 구축할 것이라는 것을 알고 있는데 오라클은 왜 이렇게 하지 않는 걸까요? 매우 간단합니다. HASH 충돌 문제를 설명하기 위해 의도적으로 이 작업을 수행하는 것입니다. 이러한 종류의 간단한 SQL의 경우 더 많은 선택 열이 있고 통계 정보를 수집하면 Oracle이 SQL을 확장할 수 있습니다.
3. SQL 감사 강화 및 초기 성능 문제 해결
응용 시스템에는 항상 소방관 역할을 하여 온라인 문제를 해결하는 경우에는 당연히 그렇지 않습니다. 오늘날 IT 시스템의 급속한 발전을 충족시킬 수 있어야 합니다. 데이터베이스 기반 시스템의 요구 사항에 따르면, 주요 성능 문제는 SQL 문을 개발 및 테스트 단계에서 검토할 수 있다면 최적화되어야 합니다. 찾을 수 있으며 지능적인 프롬프트가 제공되어 신속하게 최적화를 지원하고 수많은 온라인 질문을 할 수 있습니다. 또한, 온라인 SQL문도 지속적으로 모니터링하여 성능에 문제가 있는 문장을 신속하게 발견할 수 있어 SQL의 라이프사이클전체 관리 목적을 달성할 수 있습니다.
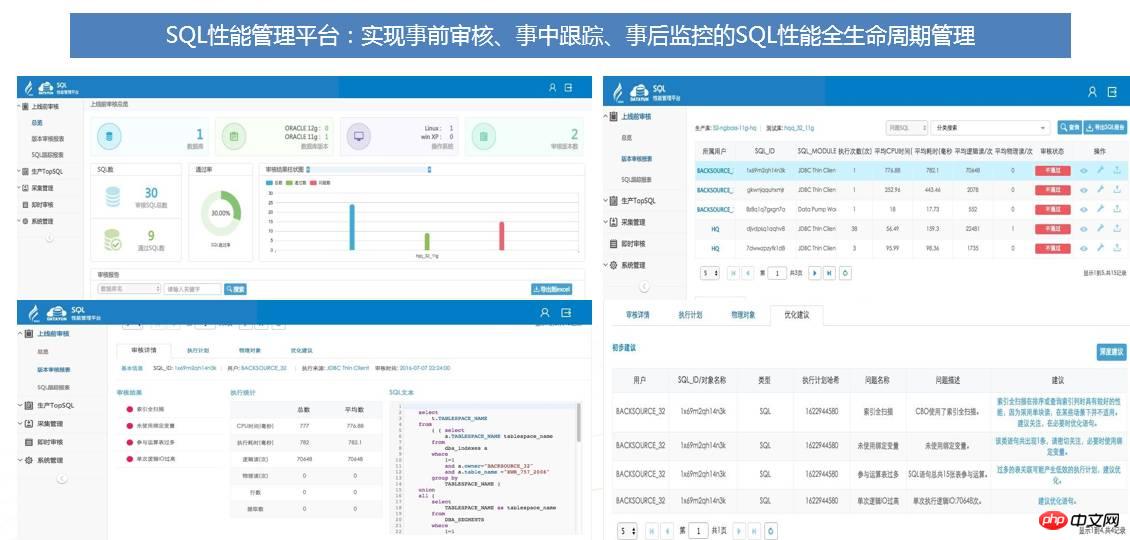
이를 위해 회사는 수년간의 운영 및 유지 관리와 최적화 경험을 결합하여 SQL 감사 도구를 독립적으로 개발했으며, 이를 통해 SQL 감사 최적화 및 성능 모니터링 처리의 효율성이 크게 향상되었습니다.
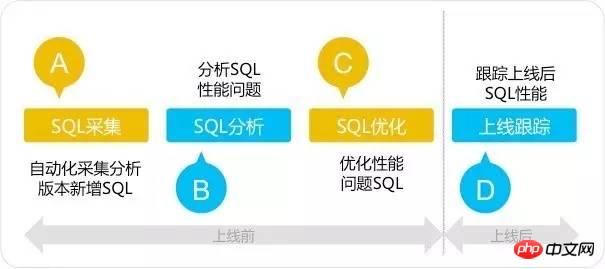
SQL 감사 도구는 SQL 수집 - SQL 분석 - SQL 최적화 - 온라인 추적의 4단계 규칙을 채택합니다. 4단계 SQL 감사 방법은 기존 SQL 최적화 방법과 다릅니다. 시스템이 온라인 상태가 되기 전 최적화. 시스템이 온라인 상태가 되기 전에 SQL 문제를 해결하고 초기 단계의 성능 문제를 해결하는 데 집중하세요. 아래 그림과 같습니다.
SQL 성능관리 플랫폼을 통해 다음과 같은 문제를 해결할 수 있습니다.
전: 온라인 전환 전 SQL 성능 감사, 초기 성능 문제 제거
중: SQL 성능 모니터링 처리, 온라인 전환 후 적시에 SQL 성능 변화 발견 , SQL 성능에서 변경 사항이 발생하고 심각한 문제가 발생하지 않으면 즉시 해결하십시오.
이후: TOPSQL 모니터링 및 적시 알람 처리.
SQL 성능 관리 플랫폼은 SQL 성능에 대한 360도 전체 수명주기 관리 및 제어를 구현하며, 다양한 지능형 프롬프트 및 처리를 통해 SQL로 인해 발생하는 대부분의 성능 문제를 해결합니다. . 문제가 발생하기 전에 해결하고 시스템 안정성을 향상시킵니다.
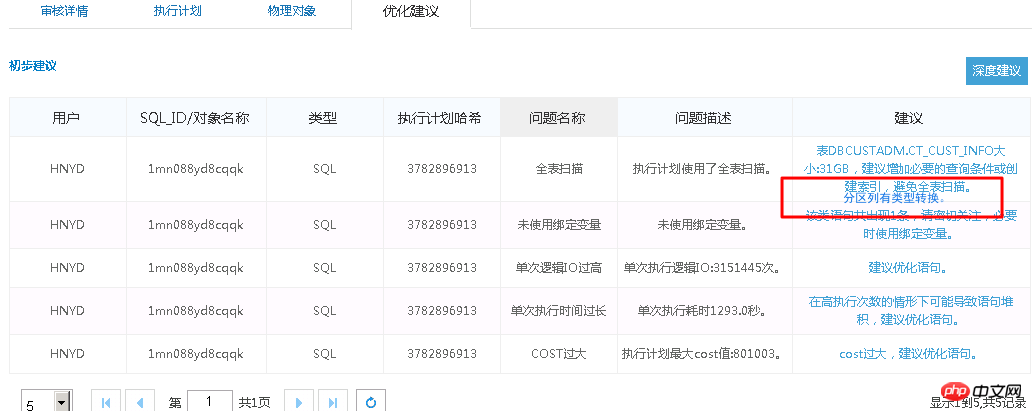
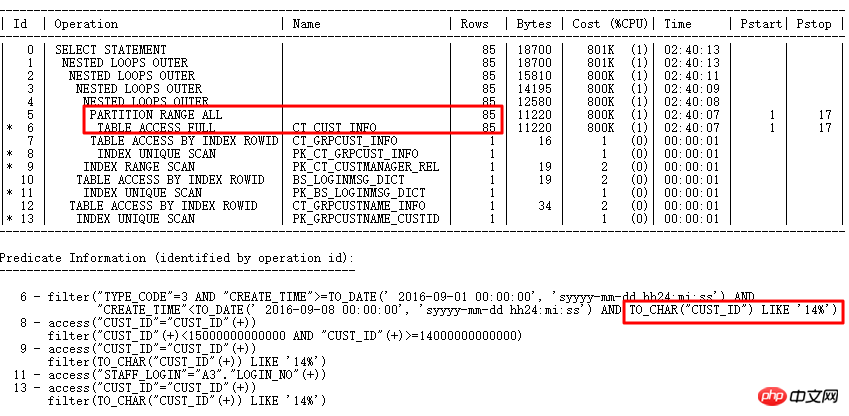
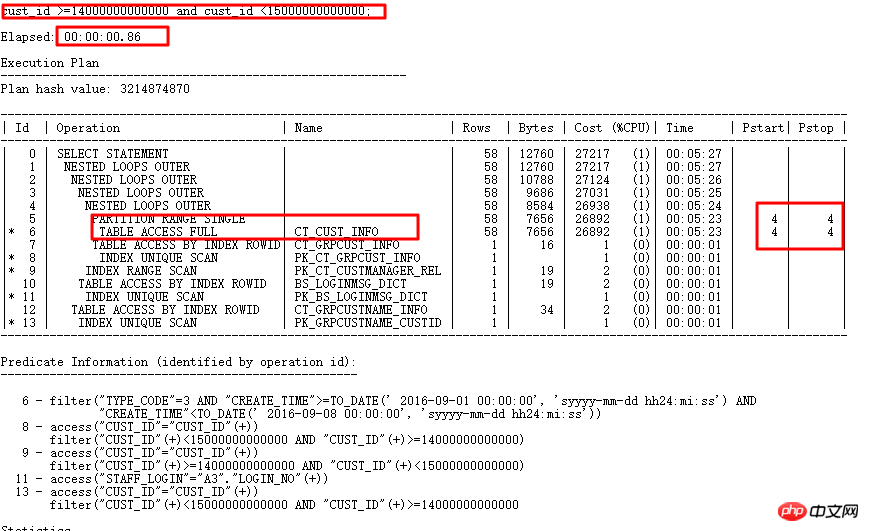
다음은 일반적인 SQL 감사 사례입니다.
실행 계획은 다음과 같습니다.
원본 SQL은 1688초 동안 실행됩니다. SQL 감사 지능형 최적화를 통해 최적화 지점을 정확하게 찾습니다. 파티션 열에는 유형 변환이 있습니다. 최적화 후 0.86초.
SQL 감사는 Xinju 데이터베이스 성능 관리 플랫폼 DPM의 모듈입니다. DPM에 대해 더 알고 싶다면 Master Zou Deyu(WeChat: carydy)에 가입하세요. 그리고 토론.
오늘은 주로 Oracle 옵티마이저에 존재하는 몇 가지 문제와 일반적인 문제에 대한 해결 방법을 공유합니다. 물론 CBO가 매우 강력하고 크게 개선된 문제는 옵티마이저 문제에만 국한되지 않습니다. 12c, 그러나 문제가 많을수록 더 많이 축적하고 관찰하며 특정 방법을 익혀야 문제에 직면한 후에 전략을 세우고 전투에서 승리할 수 있습니다.
Q&A
Q1: 해시 조인은 정렬되어 있나요? 해시 조인의 원리를 간단히 설명해 주실 수 있나요?
A1: ORACLE HASH JOIN 자체는 정렬이 필요하지 않으며 이는 SORT MERGE JOIN과 구별되는 특징 중 하나입니다. ORACLE HASH JOIN의 원리는 상대적으로 복잡합니다. Jonathan Lewis의 Cost-Based Oracle Fundamentals의 HASH JOIN 부분을 참조하세요. HASH JOIN에서 가장 중요한 것은 원리에 따라 언제 느려질지 파악하는 것입니다. , HASH_AREA_SIZE가 너무 작아서 HASH TABLE을 메모리에 완전히 배치할 수 없으면 디스크 HASH 작업이 발생하고 위에서 언급한 HASH 충돌이 발생합니다.
Q2: 언제 색인을 생성하지 말아야 합니까?
A2: 인덱싱을 사용하지 않는 경우가 많습니다. 첫 번째 이유는 통계 정보가 부정확하기 때문입니다. 두 번째 이유는 인덱싱이 전체 검색보다 효율성이 너무 낮기 때문입니다. 또한 일반적인 문제는 인덱스 열에 대해 작업이 수행되어 인덱스를 생성할 수 없다는 것입니다. 인덱스를 사용할 수 없는 이유는 그 밖에도 많습니다. 자세한 내용은 MOS 문서: 쿼리가 인덱스를 사용하지 않는 이유 진단(문서 ID 67522.1)을 참조하십시오.










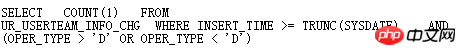
 7 HASH 충돌 문제
7 HASH 충돌 문제


위 내용은 CBO의 SQL 최적화 문제 해결 (자세한 설명은 그림과 텍스트로 설명)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7675
7675
 15
1393
52
1207
24
91
11
73
19
15
1393
52
1207
24
91
11
73
19

 MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템으로, 주로 데이터를 신속하고 안정적으로 저장하고 검색하는 데 사용됩니다. 작업 원칙에는 클라이언트 요청, 쿼리 해상도, 쿼리 실행 및 반환 결과가 포함됩니다. 사용의 예로는 테이블 작성, 데이터 삽입 및 쿼리 및 조인 작업과 같은 고급 기능이 포함됩니다. 일반적인 오류에는 SQL 구문, 데이터 유형 및 권한이 포함되며 최적화 제안에는 인덱스 사용, 최적화 된 쿼리 및 테이블 분할이 포함됩니다.
 MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
데이터베이스 및 프로그래밍에서 MySQL의 위치는 매우 중요합니다. 다양한 응용 프로그램 시나리오에서 널리 사용되는 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) MySQL은 웹, 모바일 및 엔터프라이즈 레벨 시스템을 지원하는 효율적인 데이터 저장, 조직 및 검색 기능을 제공합니다. 2) 클라이언트 서버 아키텍처를 사용하고 여러 스토리지 엔진 및 인덱스 최적화를 지원합니다. 3) 기본 사용에는 테이블 작성 및 데이터 삽입이 포함되며 고급 사용에는 다중 테이블 조인 및 복잡한 쿼리가 포함됩니다. 4) SQL 구문 오류 및 성능 문제와 같은 자주 묻는 질문은 설명 명령 및 느린 쿼리 로그를 통해 디버깅 할 수 있습니다. 5) 성능 최적화 방법에는 인덱스의 합리적인 사용, 최적화 된 쿼리 및 캐시 사용이 포함됩니다. 모범 사례에는 거래 사용 및 준비된 체계가 포함됩니다
 MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL은 성능, 신뢰성, 사용 편의성 및 커뮤니티 지원을 위해 선택됩니다. 1.MYSQL은 효율적인 데이터 저장 및 검색 기능을 제공하여 여러 데이터 유형 및 고급 쿼리 작업을 지원합니다. 2. 고객-서버 아키텍처 및 다중 스토리지 엔진을 채택하여 트랜잭션 및 쿼리 최적화를 지원합니다. 3. 사용하기 쉽고 다양한 운영 체제 및 프로그래밍 언어를 지원합니다. 4. 강력한 지역 사회 지원을 받고 풍부한 자원과 솔루션을 제공합니다.
 Apache의 데이터베이스에 연결하는 방법
Apr 13, 2025 pm 01:03 PM
Apache의 데이터베이스에 연결하는 방법
Apr 13, 2025 pm 01:03 PM
Apache는 데이터베이스에 연결하여 다음 단계가 필요합니다. 데이터베이스 드라이버 설치. 연결 풀을 만들려면 Web.xml 파일을 구성하십시오. JDBC 데이터 소스를 작성하고 연결 설정을 지정하십시오. JDBC API를 사용하여 Connections, 명세서 작성, 매개 변수 바인딩, 쿼리 또는 업데이트 실행 및 처리를 포함하여 Java 코드의 데이터베이스에 액세스하십시오.
 Docker의 MySQL을 시작하는 방법
Apr 15, 2025 pm 12:09 PM
Docker의 MySQL을 시작하는 방법
Apr 15, 2025 pm 12:09 PM
Docker에서 MySQL을 시작하는 프로세스는 다음 단계로 구성됩니다. MySQL 이미지를 가져와 컨테이너를 작성하고 시작하고 루트 사용자 암호를 설정하고 포트 확인 연결을 매핑하고 데이터베이스를 작성하고 사용자는 데이터베이스에 모든 권한을 부여합니다.
 Centos 설치 MySQL
Apr 14, 2025 pm 08:09 PM
Centos 설치 MySQL
Apr 14, 2025 pm 08:09 PM
Centos에 MySQL을 설치하려면 다음 단계가 필요합니다. 적절한 MySQL Yum 소스 추가. mysql 서버를 설치하려면 yum install mysql-server 명령을 실행하십시오. mysql_secure_installation 명령을 사용하여 루트 사용자 비밀번호 설정과 같은 보안 설정을 작성하십시오. 필요에 따라 MySQL 구성 파일을 사용자 정의하십시오. MySQL 매개 변수를 조정하고 성능을 위해 데이터베이스를 최적화하십시오.
 CentOS7에 MySQL을 설치하는 방법 7
Apr 14, 2025 pm 08:30 PM
CentOS7에 MySQL을 설치하는 방법 7
Apr 14, 2025 pm 08:30 PM
MySQL을 우아하게 설치하는 열쇠는 공식 MySQL 저장소를 추가하는 것입니다. 특정 단계는 다음과 같습니다. 피싱 공격을 방지하기 위해 MySQL 공식 GPG 키를 다운로드하십시오. MySQL 리포지토리 파일 추가 : rpm -uvh https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm yum repository cache : yum 업데이트 설치 mysql : yum 설치 mysql-server startup startup mysql 서비스 : systemctl start mysqlctl start mysqlctl.
 MySQL의 역할 : 웹 응용 프로그램의 데이터베이스
Apr 17, 2025 am 12:23 AM
MySQL의 역할 : 웹 응용 프로그램의 데이터베이스
Apr 17, 2025 am 12:23 AM
웹 응용 프로그램에서 MySQL의 주요 역할은 데이터를 저장하고 관리하는 것입니다. 1. MySQL은 사용자 정보, 제품 카탈로그, 트랜잭션 레코드 및 기타 데이터를 효율적으로 처리합니다. 2. SQL 쿼리를 통해 개발자는 데이터베이스에서 정보를 추출하여 동적 컨텐츠를 생성 할 수 있습니다. 3.mysql은 클라이언트-서버 모델을 기반으로 작동하여 허용 가능한 쿼리 속도를 보장합니다.
