

SQL 문 최적화 경험 공유

제가 사용하는 데이터베이스는 mysql5.6입니다. 아래에 시나리오를 간략하게 소개합니다
강의일정
create table Course( c_id int PRIMARY KEY, name varchar(10) )
100개 데이터 항목
학생 테이블:
create table Student( id int PRIMARY KEY, name varchar(10) )
data 항목 70,000개
학생 점수표 SC
CREATE table SC( sc_id int PRIMARY KEY, s_id int, c_id int, score int )
700,000개 항목
쿼리 목적:
중국어 시험에서 100점을 획득한 후보자 찾기
쿼리 문:
select s.* from Student s where s.s_id in (select s_id from SC sc where sc.c_id = 0 and sc.score = 100 )
실행 시간: 30248.271s
Halo, 왜 이렇게 느린가요? 먼저 쿼리 계획을 확인해 볼까요:
EXPLAIN select s.* from Student s where s.s_id in (select s_id from SC sc where sc.c_id = 0 and sc.score = 100 )

인덱스를 사용하지 않고 타입이 모두 ALL인 것으로 확인되어 가장 먼저 인덱스를 생성할 필드는 당연히 where 조건의 필드이다.
먼저 sc 테이블의 c_id와 점수에 대한 인덱스를 생성합니다
CREATE index sc_c_id_index on SC(c_id); CREATE index sc_score_index on SC(score);
위 쿼리 문을 다시 실행합니다. 시간은 1.054초입니다
30,000배 이상 빠릅니다. , 쿼리 시간이 크게 단축되었습니다. 인덱스를 사용하면 쿼리 효율성이 크게 향상될 수 있는 것 같습니다. 인덱스를 작성하는 것을 잊어버릴 때가 많습니다.
索引了,数据量小的的时候压根没感觉,这优化的感觉挺爽。
但是1s的时间还是太长了,还能进行优化吗,仔细看执行计划:

查看优化后的sql:
SELECT `YSB`.`s`.`s_id` AS `s_id`, `YSB`.`s`.`name` AS `name` FROM `YSB`.`Student` `s` WHERE < in_optimizer > ( `YSB`.`s`.`s_id` ,< EXISTS > ( SELECT 1 FROM `YSB`.`SC` `sc` WHERE ( (`YSB`.`sc`.`c_id` = 0) AND (`YSB`.`sc`.`score` = 100) AND ( < CACHE > (`YSB`.`s`.`s_id`) = `YSB`.`sc`.`s_id` ) ) ) )
补充:这里有网友问怎么查看优化后的语句
方法如下:
在命令窗口执行

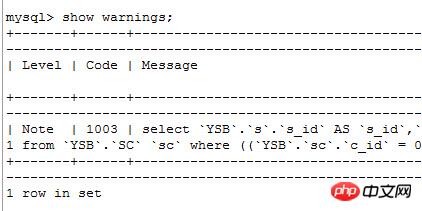
有type=all
按照我之前的想法,该sql的执行的顺序应该是先执行子查询
select s_id from SC sc where sc.c_id = 0 and sc.score = 100
耗时:0.001s
得到如下结果:
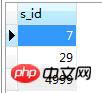
然后再执行
select s.* from Student s where s.s_id in(7,29,5000)
耗时:0.001s
这样就是相当快了啊,Mysql竟然不是先执行里层的查询,而是将sql优化成了exists子句,并出现了EPENDENT SUBQUERY,
mysql是先执行外层查询,再执行里层的查询,这样就要循环70007*11=770077次。
那么改用连接查询呢?
SELECT s.* from Student s INNER JOIN SC sc on sc.s_id = s.s_id where sc.c_id=0 and sc.score=100
这里为了重新分析连接查询的情况,先暂时删除索引sc_c_id_index,sc_score_index
执行时间是:0.057s
效率有所提高,看看执行计划:

这里有连表的情况出现,我猜想是不是要给sc表的s_id建立个索引
CREATE index sc_s_id_index on SC(s_id); show index from SC
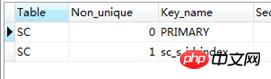
在执行连接查询
时间: 1.076s,竟然时间还变长了,什么原因?查看执行计划:

优化后的查询语句为:
SELECT `YSB`.`s`.`s_id` AS `s_id`, `YSB`.`s`.`name` AS `name` FROM `YSB`.`Student` `s` JOIN `YSB`.`SC` `sc` WHERE ( ( `YSB`.`sc`.`s_id` = `YSB`.`s`.`s_id` ) AND (`YSB`.`sc`.`score` = 100) AND (`YSB`.`sc`.`c_id` = 0) )
貌似是先做的连接查询,再进行的where条件过滤
回到前面的执行计划:

这里是先做的where条件过滤,再做连表,执行计划还不是固定的,那么我们先看下标准的sql执行顺序:

正常情况下是先join再where过滤,但是我们这里的情况,如果先join,将会有70w条数据发送join做操,因此先执行where
过滤是明智方案,现在为了排除mysql的查询优化,我自己写一条优化后的sql
SELECT s.* FROM ( SELECT * FROM SC sc WHERE sc.c_id = 0 AND sc.score = 100 ) t INNER JOIN Student s ON t.s_id = s.s_id
即先执行sc表的过滤,再进行表连接,执行时间为:0.054s
和之前没有建s_id索引的时间差不多
查看执行计划:

先提取sc再连表,这样效率就高多了,现在的问题是提取sc的时候出现了扫描表,那么现在可以明确需要建立相关索引
CREATE index sc_c_id_index on SC(c_id); CREATE index sc_score_index on SC(score);
再执行查询:
SELECT s.* FROM ( SELECT * FROM SC sc WHERE sc.c_id = 0 AND sc.score = 100 ) t INNER JOIN Student s ON t.s_id = s.s_id
执行时间为:0.001s,这个时间相当靠谱,快了50倍
执行计划:

我们会看到,先提取sc,再连表,都用到了索引。
那么再来执行下sql
SELECT s.* from Student s INNER JOIN SC sc on sc.s_id = s.s_id where sc.c_id=0 and sc.score=100
执行时间0.001s
执行计划:

这里是mysql进行了查询语句优化,先执行了where过滤,再执行连接操作,且都用到了索引。
总结:
1.mysql嵌套子查询效率确实比较低
2.可以将其优化成连接查询
3.连接表时,可以先用where条件对表进行过滤,然后做表连接
(虽然mysql会对连表语句做优化)
4.建立合适的索引
5.学会分析sql执行计划,mysql会对sql进行优化,所以分析执行计划很重要
索引优化
上面讲到子查询的优化,以及如何建立索引,而且在多个字段索引时,分别对字段建立了单个索引
后面发现其实建立联合索引效率会更高,尤其是在数据量较大,单个列区分度不高的情况下。
单列索引
查询语句如下:
select * from user_test_copy where sex = 2 and type = 2 and age = 10
索引:
CREATE index user_test_index_sex on user_test_copy(sex); CREATE index user_test_index_type on user_test_copy(type); CREATE index user_test_index_age on user_test_copy(age);
分别对sex,type,age字段做了索引,数据量为300w,查询时间:0.415s
执行计划:

发现type=index_merge
这是mysql对多个单列索引的优化,对结果集采用intersect并集操作
多列索引
我们可以在这3个列上建立多列索引,将表copy一份以便做测试
create index user_test_index_sex_type_age on user_test(sex,type,age);
查询语句:
select * from user_test where sex = 2 and type = 2 and age = 10
执行时间:0.032s,快了10多倍,且多列索引的区分度越高,提高的速度也越多
执行计划:

最左前缀
多列索引还有最左前缀的特性:
执行一下语句:
select * from user_test where sex = 2 select * from user_test where sex = 2 and type = 2 select * from user_test where sex = 2 and age = 10
都会使用到索引,即索引的第一个字段sex要出现在where条件中
索引覆盖
就是查询的列都建立了索引,这样在获取结果集的时候不用再去磁盘获取其它列的数据,直接返回索引数据即可
如:
select sex,type,age from user_test where sex = 2 and type = 2 and age = 10
执行时间:0.003s
要比取所有字段快的多
排序
select * from user_test where sex = 2 and type = 2 ORDER BY user_name
时间:0.139s
在排序字段上建立索引会提高排序的效率
create index user_name_index on user_test(user_name)
最后附上一些sql调优的总结,以后有时间再深入研究
1. 列类型尽量定义成数值类型,且长度尽可能短,如主键和外键,类型字段等等
2. 建立单列索引
3. 根据需要建立多列联合索引
当单个列过滤之后还有很多数据,那么索引的效率将会比较低,即列的区分度较低,
那么如果在多个列上建立索引,那么多个列的区分度就大多了,将会有显著的效率提高。
4. 비즈니스 시나리오에 따라 커버링 인덱스를 생성합니다
비즈니스에 필요한 필드만 쿼리하면 쿼리 효율성이 크게 향상됩니다
5. 필드에 다중 테이블 연결 인덱스를 설정해야 합니다
이렇게 하면 테이블 연결의 효율성이 크게 향상됩니다
6. Where 조건 필드에 인덱스가 설정되어야 합니다
7. 정렬 필드에 인덱스를 설정해야 합니다
8. 그룹 필드에 인덱스를 생성해야 합니다
9. 인덱스를 피하는 조건에는 산술 함수를 사용하지 마세요. 실패
위 내용은 SQL 문 최적화 경험 공유의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7467
7467
 15
1376
52
77
11
46
19
18
20
15
1376
52
77
11
46
19
18
20

 MySQL : 초보자를위한 데이터 관리의 용이성
Apr 09, 2025 am 12:07 AM
MySQL : 초보자를위한 데이터 관리의 용이성
Apr 09, 2025 am 12:07 AM
MySQL은 설치가 간단하고 강력하며 데이터를 쉽게 관리하기 쉽기 때문에 초보자에게 적합합니다. 1. 다양한 운영 체제에 적합한 간단한 설치 및 구성. 2. 데이터베이스 및 테이블 작성, 삽입, 쿼리, 업데이트 및 삭제와 같은 기본 작업을 지원합니다. 3. 조인 작업 및 하위 쿼리와 같은 고급 기능을 제공합니다. 4. 인덱싱, 쿼리 최적화 및 테이블 파티셔닝을 통해 성능을 향상시킬 수 있습니다. 5. 데이터 보안 및 일관성을 보장하기위한 지원 백업, 복구 및 보안 조치.
 Navicat Premium을 만드는 방법
Apr 09, 2025 am 07:09 AM
Navicat Premium을 만드는 방법
Apr 09, 2025 am 07:09 AM
Navicat Premium을 사용하여 데이터베이스 생성 : 데이터베이스 서버에 연결하고 연결 매개 변수를 입력하십시오. 서버를 마우스 오른쪽 버튼으로 클릭하고 데이터베이스 생성을 선택하십시오. 새 데이터베이스의 이름과 지정된 문자 세트 및 Collation의 이름을 입력하십시오. 새 데이터베이스에 연결하고 객체 브라우저에서 테이블을 만듭니다. 테이블을 마우스 오른쪽 버튼으로 클릭하고 데이터 삽입을 선택하여 데이터를 삽입하십시오.
 SQL 문을 사용하여 SQL Server로 테이블을 만드는 방법
Apr 09, 2025 pm 03:48 PM
SQL 문을 사용하여 SQL Server로 테이블을 만드는 방법
Apr 09, 2025 pm 03:48 PM
SQL Server에서 SQL 문을 사용하여 테이블을 만드는 방법 : SQL Server Management Studio를 열고 데이터베이스 서버에 연결하십시오. 테이블을 만들려면 데이터베이스를 선택하십시오. 테이블 이름, 열 이름, 데이터 유형 및 제약 조건을 지정하려면 테이블 작성 문을 입력하십시오. 실행 버튼을 클릭하여 테이블을 만듭니다.
 Navicat에서 MySQL에 새로운 연결을 만드는 방법
Apr 09, 2025 am 07:21 AM
Navicat에서 MySQL에 새로운 연결을 만드는 방법
Apr 09, 2025 am 07:21 AM
응용 프로그램을 열고 새로운 연결 (Ctrl n)을 선택하여 Navicat에서 새로운 MySQL 연결을 만들 수 있습니다. "MySQL"을 연결 유형으로 선택하십시오. 호스트 이름/IP 주소, 포트, 사용자 이름 및 비밀번호를 입력하십시오. (선택 사항) 고급 옵션을 구성합니다. 연결을 저장하고 연결 이름을 입력하십시오.
 SQL 문에서 3 개의 테이블을 연결하는 방법에 대한 자습서를 작성하는 방법
Apr 09, 2025 pm 02:03 PM
SQL 문에서 3 개의 테이블을 연결하는 방법에 대한 자습서를 작성하는 방법
Apr 09, 2025 pm 02:03 PM
이 기사에서는 SQL 문을 사용하여 3 개의 테이블에 가입하는 것에 대한 자세한 자습서를 소개합니다. 독자는 다른 테이블의 데이터를 효과적으로 상관시키는 방법을 배우도록 독자를 안내합니다. 예제 및 세부 구문 설명을 통해이 기사를 사용하면 SQL에서 테이블의 결합 기술을 마스터하여 데이터베이스에서 관련 정보를 효율적으로 검색 할 수 있습니다.
 SQL 문 삽입을 사용하는 방법
Apr 09, 2025 pm 06:15 PM
SQL 문 삽입을 사용하는 방법
Apr 09, 2025 pm 06:15 PM
SQL 삽입 문은 데이터를 테이블에 삽입하는 데 사용됩니다. 단계에는 다음이 포함됩니다. 삽입 할 열을 나열하려면 대상 테이블을 지정하십시오. 삽입 할 값을 지정합니다 (값 순서는 열 이름에 해당해야합니다).
 Navicat의 Local MySQL에 연결하는 방법
Apr 09, 2025 am 07:45 AM
Navicat의 Local MySQL에 연결하는 방법
Apr 09, 2025 am 07:45 AM
Navicat을 사용하여 로컬 MySQL 데이터베이스에 연결하려면 : 연결을 만들고 연결 이름, 호스트, 포트, 사용자 이름 및 비밀번호를 설정하십시오. 연결을 테스트하여 매개 변수가 올바른지 확인하십시오. 연결을 저장하십시오. 연결 목록에서 새 연결을 선택하십시오. 연결하려는 데이터베이스를 두 번 클릭하십시오.
 Navicat에서 SQL을 실행하는 방법
Apr 08, 2025 pm 11:42 PM
Navicat에서 SQL을 실행하는 방법
Apr 08, 2025 pm 11:42 PM
Navicat에서 SQL을 수행하는 단계 : 데이터베이스에 연결하십시오. SQL 편집기 창을 만듭니다. SQL 쿼리 또는 스크립트를 작성하십시오. 실행 버튼을 클릭하여 쿼리 또는 스크립트를 실행하십시오. 결과를 봅니다 (쿼리가 실행 된 경우).
