
Redis의 저자인 Salvatore Sanfilippo는 다음 두 가지 메모리 기반 데이터 스토리지 시스템을 비교한 적이 있습니다.
Redis는 서버 측 데이터 작업을 지원합니다. Redis는 Memcached에 비해 더 많은 데이터 구조를 갖고 있으며 더 풍부한 데이터 작업을 지원합니다. 일반적으로 Memcached에서는 유사한 수정을 수행하려면 데이터를 클라이언트로 가져온 다음 다시 설정해야 합니다. 이로 인해 네트워크 IO 수와 데이터 볼륨이 크게 늘어납니다. Redis에서 이러한 복잡한 작업은 일반적으로 일반 GET/SET만큼 효율적입니다. 따라서 더 복잡한 구조와 작업을 지원하기 위해 캐시가 필요한 경우 Redis가 좋은 선택이 될 것입니다.
메모리 사용 효율성 비교: 단순 키-값 저장을 사용하는 경우 Memcached의 메모리 사용률이 더 높습니다. Redis가 키-값 저장에 해시 구조를 사용하면 결합된 압축으로 인해 메모리 사용률이 Memcached보다 높아집니다.
성능 비교: Redis는 단일 코어만 사용하고 Memcached는 여러 코어를 사용할 수 있으므로 평균적으로 Redis는 각 코어에 작은 데이터를 저장할 때 Memcached보다 성능이 높습니다. 100,000개 이상의 데이터에 대해서는 Memcached의 성능이 Redis보다 높습니다. Redis는 최근 빅데이터 저장 성능에 최적화되어 있지만 여전히 Memcached에 비해 약간 열등합니다.
위의 결론이 나온 구체적인 이유는 다음과 같습니다.
단순한 키-값 구조의 데이터 레코드만 지원하는 Memcached와 달리 Redis는 훨씬 더 풍부한 데이터 유형을 지원합니다. 가장 일반적으로 사용되는 데이터 유형에는 문자열, 해시, 목록, 집합 및 정렬된 집합의 5가지가 있습니다. Redis는 내부적으로 redisObject 객체를 사용하여 모든 키와 값을 나타냅니다. redisObject의 주요 정보는 그림과 같습니다.

type은 값 객체의 특정 데이터 유형을 나타내며 인코딩은 다양한 데이터 유형이 redis 내에 저장되는 방식입니다. 예: type=string은 값이 일반 문자열로 저장됨을 나타내며 해당 인코딩은 raw 또는 int일 수 있습니다. int인 경우 실제 문자열이 redis 내부에 숫자 클래스로 저장되고 표시된다는 의미입니다. 물론 문자열 자체가 "123" "456과 같은 숫자 값으로 표시될 수 있다는 것이 전제입니다. " 그런 문자열. Redis의 가상 메모리 기능이 활성화된 경우에만 vm 필드가 실제로 메모리를 할당합니다. 이 기능은 기본적으로 비활성화되어 있습니다.
1) 문자열
일반적으로 사용되는 명령: set/get/decr/incr/mget 등
애플리케이션 시나리오: 문자열은 가장 일반적으로 사용되는 데이터 유형이며 일반 키/값 저장소는
으로 분류할 수 있습니다. 구현 방법: 문자열은 기본적으로 redisObject에 의해 참조되는 문자열로 저장됩니다. incr, decr 및 기타 작업이 발생하면 계산을 위해 숫자 값으로 변환됩니다. 정수.
2) 해시
자주 사용되는 명령: hget/hset/hgetall 등
적용 시나리오: 사용자 ID, 사용자 이름, 나이 및 생일을 포함하는 사용자 정보 개체 데이터를 저장하려고 합니다. 사용자 ID를 통해 사용자의 이름, 나이 또는 생일을 얻으려고 합니다.
3) 목록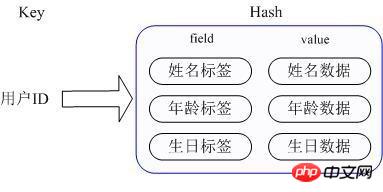
자주 사용되는 명령: sadd/spop/smembers/sunion 등
애플리케이션 시나리오: Redis 세트에서 제공하는 외부 기능은 목록 기능과 유사합니다. 특별한 점은 데이터 목록을 저장해야 하고 중복 데이터가 표시되지 않도록 할 때 세트가 매우 유용하다는 것입니다. 도구는 좋은 선택이며, 집합은 구성원이 집합 컬렉션에 있는지 여부를 결정하는 중요한 인터페이스를 제공합니다. 이 목록은 제공할 수 없습니다. 🎜> 구현 방법: set의 내부 구현은 값이 항상 null인 HashMap입니다. 실제로 해시를 계산하여 빠르게 정렬됩니다. 이것이 set이 멤버가 세트에 있는지 확인하는 방법을 제공할 수 있는 이유입니다.
5) 정렬세트
일반적으로 사용되는 명령: zadd/zrange/zrem/zcard 등
애플리케이션 시나리오: Redis 정렬 세트의 사용 시나리오는 세트와 유사합니다. 차이점은 세트가 자동으로 정렬되지 않는 반면, 정렬 세트는 사용자가 추가 우선순위(점수) 매개변수를 제공하여 멤버를 정렬할 수 있다는 것입니다. 즉, 자동 정렬입니다. 순서가 있고 중복되지 않은 세트 목록이 필요한 경우 정렬된 세트 데이터 구조를 선택할 수 있습니다. 예를 들어 Twitter의 공개 타임라인은 게시 시간을 점수로 저장하여 검색 시 자동으로 시간별로 정렬되도록 할 수 있습니다.
구현 방법: Redis 정렬 세트는 내부적으로 HashMap 및 건너뛰기 목록(SkipList)을 사용하여 데이터의 저장 및 순서를 보장합니다. HashMap은 멤버에서 점수로의 매핑을 저장하는 반면, 건너뛰기 목록은 모든 멤버를 저장합니다. , 점프 테이블 구조를 사용하면 더 높은 검색 효율성을 얻을 수 있으며 구현이 비교적 간단합니다.
2. 다양한 메모리 관리 메커니즘Redis에서는 모든 데이터가 항상 메모리에 저장되는 것은 아닙니다. 이것이 Memcached와 비교했을 때 가장 큰 차이점입니다. 물리적 메모리가 부족해지면 Redis는 오랫동안 사용되지 않은 일부 값을 디스크로 스왑할 수 있습니다. Redis는 모든 키 정보만 캐시합니다. Redis가 메모리 사용량이 특정 임계값을 초과하는 것을 발견하면 스왑 작업이 트리거됩니다. Redis는 "swappability = age*log(size_in_memory)" 스왑을 기반으로 필요한 값에 해당하는 키를 계산합니다. 디스크. 그런 다음 이러한 키에 해당하는 값은 디스크에 유지되고 메모리에서 지워집니다. 이 기능을 통해 Redis는 머신 자체의 메모리 크기를 초과하는 데이터를 유지할 수 있습니다. 물론, 기계 자체의 메모리는 모든 키를 보유할 수 있어야 하며 결국 이러한 데이터는 교환되지 않습니다. 동시에 Redis가 메모리에 있는 데이터를 디스크로 스왑할 때 서비스를 제공하는 메인 스레드와 스왑 작업을 수행하는 하위 스레드가 이 메모리 부분을 공유하게 되므로 필요한 데이터가 swapped가 업데이트되면 Redis는 스왑 작업을 완료한 후에만 하위 스레드 수정이 이루어질 수 있을 때까지 작업을 차단합니다. Redis에서 데이터를 읽을 때 읽기 키에 해당하는 값이 메모리에 없으면 Redis는 스왑 파일에서 해당 데이터를 로드한 다음 요청자에게 반환해야 합니다. 여기에 I/O 스레드 풀 문제가 있습니다. 기본적으로 Redis는 차단됩니다. 즉, 모든 스왑 파일이 로드될 때까지 응답하지 않습니다. 이 전략은 클라이언트 수가 적고 일괄 작업을 수행하는 경우에 더 적합합니다. 그러나 대규모 웹사이트 애플리케이션에 Redis를 적용한다면 분명히 대규모 동시성 상황을 충족할 수 없습니다. 따라서 Redis는 I/O 스레드 풀의 크기를 설정하고 차단 시간을 줄이기 위해 스왑 파일에서 해당 데이터를 로드해야 하는 읽기 요청에 대해 동시 작업을 수행하도록 실행합니다.
Memcached는 기본적으로 Slab 할당 메커니즘을 사용하여 메모리를 관리합니다. 주요 아이디어는 할당된 메모리를 미리 결정된 크기에 따라 특정 길이의 블록으로 나누어 해당 길이의 키-값 데이터 레코드를 저장하여 메모리 조각화 문제를 완전히 해결하는 것입니다. Slab 할당 메커니즘은 외부 데이터만 저장하도록 설계되었습니다. 즉, 모든 키-값 데이터는 Slab 할당 시스템에 저장되는 반면 Memcached에 대한 다른 메모리 요청은 일반 malloc/free를 통해 적용됩니다. 빈도는 전체 시스템의 성능에 영향을 미치지 않을 것이라고 결정합니다. 슬래브 할당의 원리는 매우 간단합니다. 그림과 같이 운영체제로부터 큰 메모리 블록을 먼저 적용하고, 이를 다양한 크기의 청크로 나누고, 같은 크기의 청크를 슬래브 클래스 그룹으로 나눕니다. 그 중 청크(Chunk)는 키-값 데이터를 저장하는 데 사용되는 가장 작은 단위이다. Memcached가 시작될 때 성장 인자를 지정하여 각 Slab 클래스의 크기를 제어할 수 있습니다. 그림에서 성장 인자 값을 1.25라고 가정합니다. 첫 번째 청크 그룹의 크기가 88바이트인 경우 두 번째 청크 그룹의 크기는 112바이트입니다.
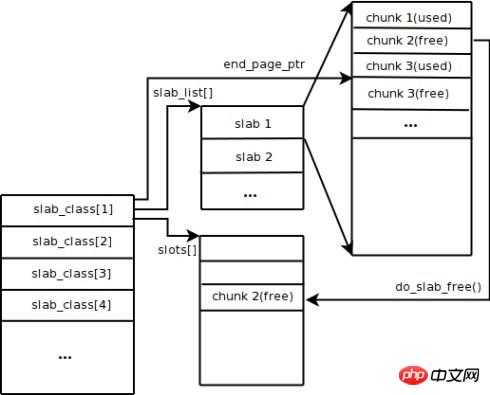
Memcached는 클라이언트가 보낸 데이터를 수신하면 먼저 수신한 데이터의 크기를 기준으로 가장 적합한 Slab 클래스를 선택한 다음 Memcached가 저장한 Slab 클래스의 사용 가능한 청크 목록을 쿼리하여 사용할 수 있는 Slab 클래스를 찾습니다. 데이터를 저장하는 데 사용됩니다. 데이터베이스 레코드가 만료되거나 폐기되면 해당 레코드가 차지한 청크를 재활용하여 사용 가능 목록에 다시 추가할 수 있습니다. 위의 과정을 통해 Memcached의 메모리 관리 시스템은 매우 효율적이고 메모리 조각화를 일으키지 않지만 가장 큰 단점은 공간 낭비를 초래한다는 점을 알 수 있습니다. 각 청크에는 특정 길이의 메모리 공간이 할당되므로 가변 길이 데이터는 이 공간을 완전히 활용할 수 없습니다. 그림과 같이 100바이트의 데이터가 128바이트의 청크에 캐시되고 나머지 28바이트는 낭비됩니다.

Redis의 메모리 관리는 주로 소스코드의 Redis와 Memcached의 차이점에 대한 자세한 설명.h, Redis와 Memcached의 차이점에 대한 자세한 설명.c 두 파일을 통해 구현됩니다. 메모리 관리를 용이하게 하기 위해 Redis는 메모리를 할당한 후 메모리 블록의 헤드에 이 메모리의 크기를 저장합니다. 그림에서 볼 수 있듯이 real_ptr은 malloc을 호출한 후 redis가 반환한 포인터입니다. Redis는 메모리 블록 크기의 크기를 헤더에 저장하며, size가 차지하는 메모리 크기는 size_t 유형의 길이이며 ret_ptr을 반환합니다. 메모리를 해제해야 할 경우 ret_ptr이 메모리 관리자에 전달됩니다. ret_ptr을 통해 프로그램은 real_ptr의 값을 쉽게 계산한 다음 real_ptr을 전달하여 메모리를 해제할 수 있습니다.

Redis는 배열을 정의하여 모든 메모리 할당을 기록합니다. 이 배열의 길이는 ZMALLOC_MAX_ALLOC_STAT입니다. 배열의 각 요소는 현재 프로그램에서 할당된 메모리 블록의 수를 나타내며, 메모리 블록의 크기는 요소의 첨자입니다. 소스 코드에서 이 배열은 Redis와 Memcached의 차이점에 대한 자세한 설명_allocations입니다. Redis와 Memcached의 차이점에 대한 자세한 설명_allocations[16]은 16바이트 길이의 할당된 메모리 블록 수를 나타냅니다. Redis와 Memcached의 차이점에 대한 자세한 설명.c에는 현재 할당된 메모리의 전체 크기를 기록하는 정적 변수 Used_memory가 있습니다. 따라서 일반적으로 Redis는 Memcached의 메모리 관리 방법보다 훨씬 간단한 packaged mallc/free를 사용합니다.
Redis는 메모리 기반 스토리지 시스템이지만 자체적으로 메모리 데이터의 지속성을 지원하고 RDB 스냅샷과 AOF 로그라는 두 가지 주요 지속성 전략을 제공합니다. Memcached는 데이터 지속성 작업을 지원하지 않습니다.
1) RDB 스냅샷
Redis는 현재 데이터의 스냅샷을 데이터 파일, 즉 RDB 스냅샷에 저장하는 지속성 메커니즘을 지원합니다. 하지만 지속적으로 작성되는 데이터베이스는 어떻게 스냅샷을 생성합니까? Redis는 fork 명령의 쓰기 시 복사 메커니즘을 사용합니다. 스냅샷을 생성할 때 현재 프로세스는 자식 프로세스로 분기된 후 모든 데이터는 자식 프로세스에서 순환되고 해당 데이터는 RDB 파일에 기록됩니다. Redis의 save 명령을 통해 RDB 스냅샷 생성 시점을 구성할 수 있습니다. 예를 들어 10분 후에 스냅샷이 생성되도록 구성할 수도 있고, 1,000회 쓰기 후에 스냅샷을 생성하도록 구성할 수도 있고, 여러 규칙을 함께 구현할 수도 있습니다. 이러한 규칙의 정의는 Redis를 다시 시작하지 않고도 Redis가 실행되는 동안 Redis CONFIG SET 명령을 통해 규칙을 설정할 수도 있습니다.
Redis의 RDB 파일은 쓰기 작업이 새 프로세스에서 수행되기 때문에 손상되지 않습니다. 새 RDB 파일이 생성되면 Redis에서 생성된 하위 프로세스는 먼저 데이터를 임시 파일에 쓴 다음 이를 원자적으로 사용합니다. 시스템 호출은 임시 파일의 이름을 RDB 파일로 변경하므로 언제든지 오류가 발생하더라도 Redis RDB 파일을 항상 사용할 수 있습니다. 동시에 Redis의 RDB 파일은 Redis 마스터-슬레이브 동기화의 내부 구현의 일부이기도 합니다. RDB에는 단점이 있습니다. 즉, 데이터베이스에 문제가 발생하면 RDB 파일에 저장된 데이터는 마지막 RDB 파일 생성부터 Redis 종료까지의 모든 데이터가 손실됩니다. 일부 기업에서는 이것이 허용될 수 있습니다.
2) AOF 로그
AOF 로그의 전체 이름은 추가 작성 로그 파일인 추가 전용 파일입니다. AOF 파일은 일반 데이터베이스의 binlog와 달리 식별 가능한 일반 텍스트이며 그 내용은 하나씩 Redis 표준 명령입니다. 데이터를 수정하는 명령만 AOF 파일에 추가됩니다. 데이터를 수정하는 각 명령은 로그를 생성하며 AOF 파일은 점점 커지므로 Redis는 AOF rewrite라는 또 다른 기능을 제공합니다. 그 기능은 AOF 파일을 재생성하는 것입니다. 동일한 값에 여러 작업을 기록할 수 있는 이전 파일과 달리 새 AOF 파일의 레코드에는 하나의 작업만 있습니다. 생성 프로세스는 RDB와 유사하며 프로세스를 분기하고 데이터를 직접 탐색하며 새 AOF 임시 파일을 작성합니다. 새 파일을 쓰는 동안 모든 쓰기 작업 로그는 원래의 이전 AOF 파일에 계속 기록되며 메모리 버퍼에도 기록됩니다. 중복 작업이 완료되면 버퍼에 있는 모든 로그가 임시 파일에 한꺼번에 기록됩니다. 그런 다음 원자 이름 바꾸기 명령을 호출하여 이전 AOF 파일을 새 AOF 파일로 바꿉니다.
AOF는 파일 쓰기 작업입니다. 그 목적은 작업 로그를 디스크에 쓰는 것이므로 위에서 언급한 쓰기 작업 프로세스도 발생합니다. Redis에서 AOF에 대한 쓰기를 호출한 후,appendfsync 옵션을 사용하여 fsync를 호출하여 디스크에 쓰는 데 걸리는 시간을 제어하면 아래의 세 가지appendfsync 설정에 대한 보안 강도가 점차 강화됩니다.
appendfsync noappendfsync가 no로 설정되면 Redis는 AOF 로그 내용을 디스크에 동기화하기 위해 fsync를 적극적으로 호출하지 않으므로 이 모든 것은 전적으로 운영 체제 디버깅에 달려 있습니다. 대부분의 Linux 운영 체제에서는 fsync가 30초마다 수행되어 버퍼의 데이터를 디스크에 씁니다.
appendfsynceverysecappendfsync가 Everysec로 설정되면 Redis는 기본적으로 버퍼의 데이터를 디스크에 쓰기 위해 매초마다 fsync 호출을 수행합니다. 하지만 이 fsync 호출이 1초 이상 지속되는 경우. Redis는 fsync를 지연하고 1초 더 기다리는 전략을 채택합니다. 즉, fsync는 2초 후에 수행됩니다. 이번에는 실행 시간이 얼마나 걸리더라도 fsync가 수행됩니다. 이때 fsync 중에는 파일 디스크립터가 차단되므로 현재 쓰기 작업이 차단됩니다. 따라서 결론은 대부분의 경우 Redis가 매초마다 fsync를 수행한다는 것입니다. 최악의 경우 fsync 작업이 2초마다 발생합니다. 이 작업을 대부분의 데이터베이스 시스템에서는 그룹 커밋이라고 하며 여러 쓰기 작업의 데이터를 결합하고 로그를 한 번에 디스크에 씁니다.
appednfsync Alwaysappendfsync를 Always로 설정하면 쓰기 작업마다 fsync가 한 번 호출됩니다. 물론 fsync가 매번 실행되므로 성능에도 영향을 미칩니다.
일반적인 비즈니스 요구 사항에서는 지속성을 위해 RDB를 사용하는 것이 좋습니다. 그 이유는 RDB의 오버헤드가 AOF 로그보다 훨씬 낮기 때문입니다. 데이터 손실을 허용할 수 없는 애플리케이션의 경우 AOF 로그를 사용하는 것이 좋습니다.
Memcached는 전체 메모리 데이터 버퍼링 시스템입니다. Redis는 데이터 지속성을 지원하지만 고성능의 핵심은 전체 메모리입니다. 메모리 기반 스토리지 시스템으로서, 머신의 물리적 메모리 크기는 시스템이 수용할 수 있는 최대 데이터 양입니다. 처리해야 할 데이터의 양이 단일 머신의 물리적 메모리 크기를 초과하는 경우 분산 클러스터를 구축하여 스토리지 용량을 확장해야 합니다.
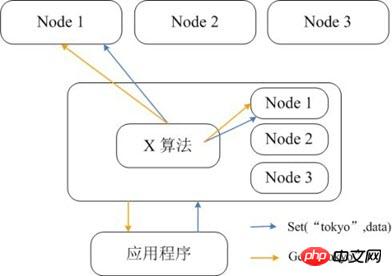
Memcached 자체는 분산을 지원하지 않으므로 Memcached의 분산 스토리지는 컨시스턴트 해싱(Consistency Hashing)과 같은 분산 알고리즘을 통해서만 클라이언트에서 구현될 수 있습니다. 아래 그림은 Memcached의 분산 스토리지 구현 아키텍처를 보여줍니다. 클라이언트가 Memcached 클러스터에 데이터를 보내기 전에 먼저 내장된 분산 알고리즘을 통해 데이터의 대상 노드를 계산한 다음 데이터를 노드에 직접 전송하여 저장합니다. 그러나 클라이언트가 데이터를 쿼리할 때는 쿼리 데이터가 있는 노드도 계산한 다음 해당 노드에 직접 쿼리 요청을 보내 데이터를 가져와야 합니다.
분산 스토리지를 구현하기 위해 클라이언트만 사용할 수 있는 Memcached와 비교할 때 Redis는 서버 측에서 분산 스토리지를 구축하는 것을 선호합니다. 최신 버전의 Redis는 이미 분산 스토리지 기능을 지원합니다. Redis Cluster는 분산을 구현하고 단일 장애 지점을 허용하는 Redis의 고급 버전입니다. 중앙 노드가 없으며 선형 확장성을 갖습니다. 아래 그림은 노드간은 바이너리 프로토콜로 통신하고, 노드와 클라이언트간은 ASCII 프로토콜로 통신하는 Redis Cluster의 분산 스토리지 아키텍처를 보여준다. 데이터 배치 전략 측면에서 Redis Cluster는 전체 키 값 필드를 4096개의 해시 슬롯으로 나누고 각 노드는 하나 이상의 해시 슬롯을 저장할 수 있습니다. 즉, 현재 Redis Cluster에서 지원하는 최대 노드 수는 4096개입니다. Redis Cluster에서 사용하는 분산 알고리즘도 매우 간단합니다: crc16(key) % HASH_SLOTS_NUMBER.
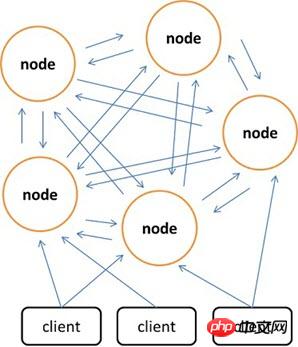
단일 장애 지점에서 데이터 가용성을 보장하기 위해 Redis 클러스터는 마스터 노드와 슬레이브 노드를 도입합니다. Redis 클러스터에서 각 마스터 노드에는 중복성을 위한 두 개의 해당 슬레이브 노드가 있습니다. 이러한 방식으로 전체 클러스터에서 두 노드의 가동 중지 시간으로 인해 데이터 가용성이 저하되지 않습니다. 마스터 노드가 종료되면 클러스터는 새 마스터 노드가 될 슬레이브 노드를 자동으로 선택합니다.
위 내용은 Redis와 Memcached의 차이점에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



