

Python 크롤링 기술의 IP 자동 프록시 예

최근 시험을 위해 인터넷에서 소프트 시험 문제를 크롤링할 계획인데 크롤링 중에 몇 가지 문제가 발생했습니다. 다음 기사에서는 주로 Python을 사용하여 소프트 시험 문제를 크롤링하는 방법과 IP 자동 프록시 관련 정보를 소개합니다. . 기사에 아주 자세하게 소개되어 있으니, 필요한 친구들은 아래에서 구경해 보세요.
서문
최근 소프트웨어 전문가 수준 시험이 있습니다. 이하 소프트 시험이라고 합니다. 시험이 끝나면 rkpass.cn에서 소프트 테스트 문제를 볼 계획입니다.
먼저 제가 소프트 시험 문제를 크롤링했던 사연(켁)을 말씀드리겠습니다. 이제 아래와 같이 특정 모듈의 모든 문제를 자동으로 캡처할 수 있습니다.
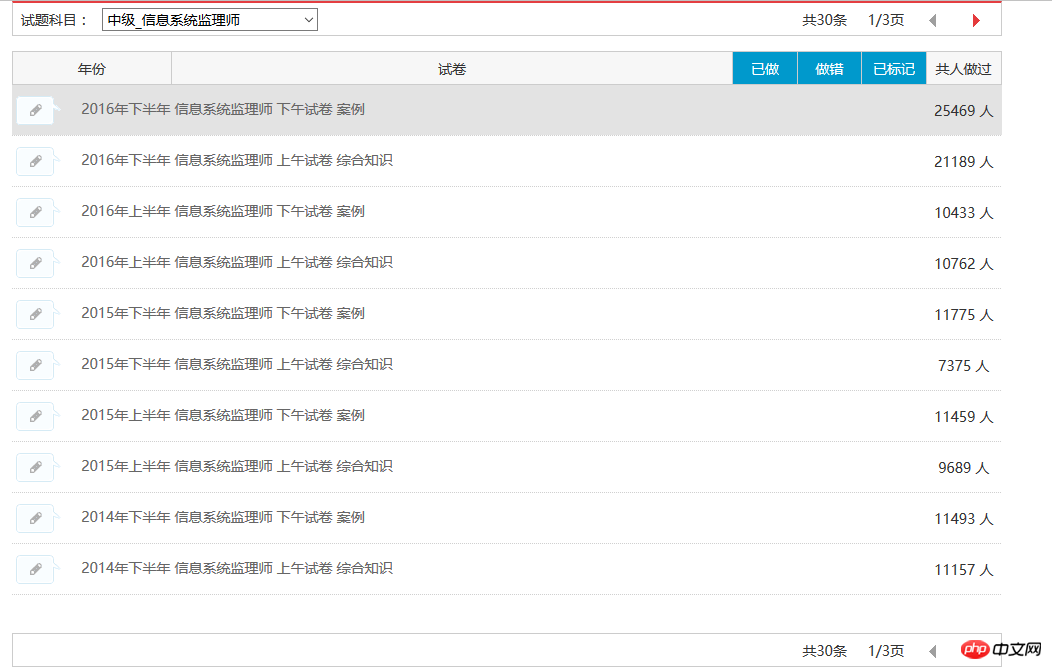
현재 정보 시스템 감독자의 시험 문제 기록 30개를 모두 캡처할 수 있습니다.
캡쳐된 콘텐츠 이미지 :

일부 정보는 캡쳐 가능하지만 화질은 캡쳐정보시스템 감독자를 예로 들면, 목표가 명확하고 매개변수도 명확하기 때문에, 어제는 시험지 정보를 캡쳐하기 위해 어떠한 예외 처리도 하지 않았습니다. 밤에 오랫동안 구멍을 메웠어요.
본론으로 돌아가서, 오늘 제가 이 블로그를 쓰는 이유는 새로운 함정에 직면했기 때문입니다. 기사 제목을 보면 요청이 너무 많아서 웹사이트의 크롤러 방지 메커니즘에 의해 IP가 차단되었음을 짐작할 수 있습니다.
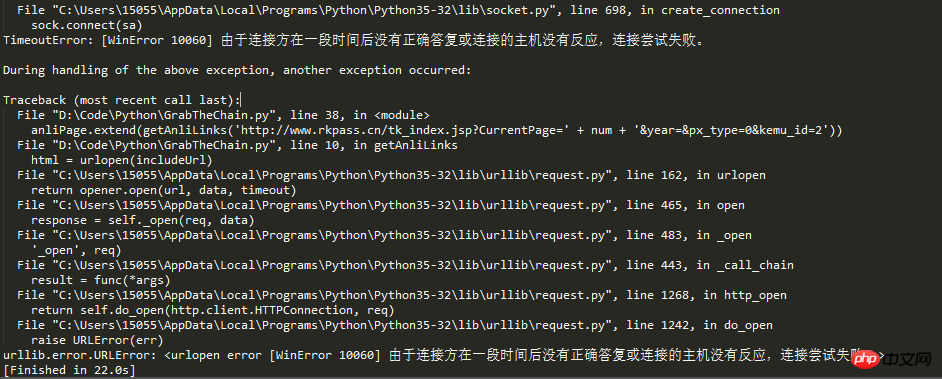
산 사람이 소변으로 죽을 수는 없습니다. 우리 혁명가들의 업적은 사회주의의 계승자인 우리가 어려움에 굴하지 않고 산을 넘어 길을 개척할 수 없음을 말해줍니다. 강을 건너는 다리, IP 문제를 해결하기 위해 IP 프록시 아이디어가 나왔습니다.
웹 크롤러가 정보를 수집하는 과정에서 크롤링 빈도가 웹 사이트에서 설정한 임계값을 초과하면 접근이 금지됩니다. 일반적으로 웹사이트의 크롤러 방지 메커니즘은 IP를 기반으로 크롤러를 식별합니다.
따라서 크롤러 개발자는 일반적으로 이 문제를 해결하기 위해 두 가지 방법을 취해야 합니다.
1. 대상 웹사이트에 대한 압력. 그러나 이렇게 하면 단위 시간당 크롤링 양이 줄어듭니다.
2. 두 번째 방법은 크롤러 방지 메커니즘을 돌파하고 프록시 IP 설정 등을 통해 고주파 크롤링을 지속하는 것입니다. 그러나 이를 위해서는 여러 개의 안정적인 프록시 IP가 필요합니다.
말할 것도 없이 바로 코드로 넘어가겠습니다:
# IP地址取自国内髙匿代理IP网站:www.xicidaili.com/nn/
# 仅仅爬取首页IP地址就足够一般使用
from bs4 import BeautifulSoup
import requests
import random
#获取当前页面上的ip
def get_ip_list(url, headers):
web_data = requests.get(url, headers=headers)
soup = BeautifulSoup(web_data.text)
ips = soup.find_all('tr')
ip_list = []
for i in range(1, len(ips)):
ip_info = ips[i]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
return ip_list
#从抓取到的Ip中随机获取一个ip
def get_random_ip(ip_list):
proxy_list = []
for ip in ip_list:
proxy_list.append('http://' + ip)
proxy_ip = random.choice(proxy_list)
proxies = {'http': proxy_ip}
return proxies
#国内高匿代理IP网主地址
url = 'http://www.xicidaili.com/nn/'
#请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'}
#计数器,根据计数器来循环抓取所有页面的ip
num = 0
#创建一个数组,将捕捉到的ip存放到数组
ip_array = []
while num < 1537:
num += 1
ip_list = get_ip_list(url+str(num), headers=headers)
ip_array.append(ip_list)
for ip in ip_array:
print(ip)
#创建随机数,随机取到一个ip
# proxies = get_random_ip(ip_list)
# print(proxies)실행 결과 스크린샷:
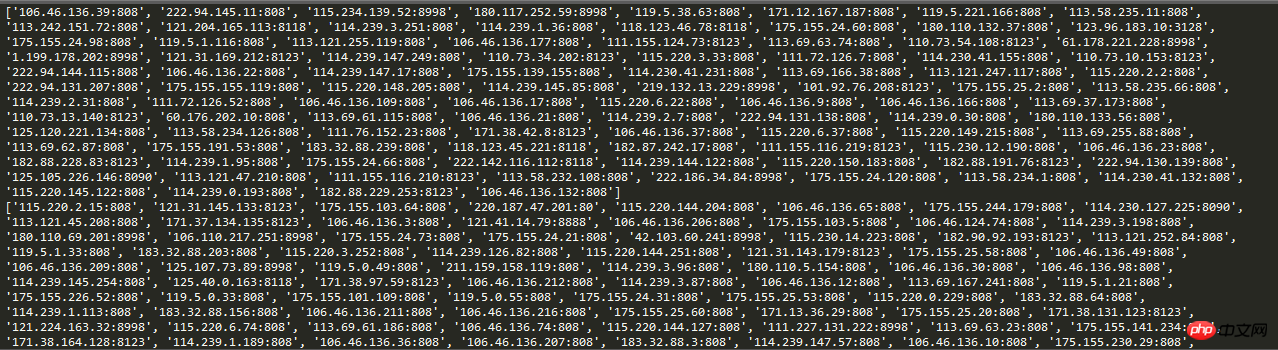
이런 식으로, 크롤러가 요청할 때 요청 IP를 자동 IP로 설정하면 크롤러 방지 메커니즘의 단순 차단 및 고정 IP를 효과적으로 피할 수 있습니다.
------------------------------- ------ ------------------ ------ -------------
웹사이트의 안정성을 위해서는 누구나 크롤러의 속도를 통제해야 하는데, 결국 웹마스터에게도 쉽지 않은 일입니다. 이 기사의 테스트에서는 17개의 IP 페이지만 캡처했습니다.
요약
위 내용은 Python 크롤링 기술의 IP 자동 프록시 예의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7517
7517
 15
1378
52
79
11
53
19
21
66
15
1378
52
79
11
53
19
21
66

 웹 사이트 성과를 향상시키기 위해 Debian Apache Logs를 사용하는 방법
Apr 12, 2025 pm 11:36 PM
웹 사이트 성과를 향상시키기 위해 Debian Apache Logs를 사용하는 방법
Apr 12, 2025 pm 11:36 PM
이 기사는 데비안 시스템에서 Apache Logs를 분석하여 웹 사이트 성능을 향상시키는 방법을 설명합니다. 1. 로그 분석 기본 사항 Apache Log는 IP 주소, 타임 스탬프, 요청 URL, HTTP 메소드 및 응답 코드를 포함한 모든 HTTP 요청의 자세한 정보를 기록합니다. 데비안 시스템 에서이 로그는 일반적으로 /var/log/apache2/access.log 및 /var/log/apache2/error.log 디렉토리에 있습니다. 로그 구조를 이해하는 것은 효과적인 분석의 첫 번째 단계입니다. 2. 로그 분석 도구 다양한 도구를 사용하여 Apache 로그를 분석 할 수 있습니다.
 파이썬 : 게임, Guis 등
Apr 13, 2025 am 12:14 AM
파이썬 : 게임, Guis 등
Apr 13, 2025 am 12:14 AM
Python은 게임 및 GUI 개발에서 탁월합니다. 1) 게임 개발은 Pygame을 사용하여 드로잉, 오디오 및 기타 기능을 제공하며 2D 게임을 만드는 데 적합합니다. 2) GUI 개발은 Tkinter 또는 PYQT를 선택할 수 있습니다. Tkinter는 간단하고 사용하기 쉽고 PYQT는 풍부한 기능을 가지고 있으며 전문 개발에 적합합니다.
 PHP 및 Python : 두 가지 인기있는 프로그래밍 언어를 비교합니다
Apr 14, 2025 am 12:13 AM
PHP 및 Python : 두 가지 인기있는 프로그래밍 언어를 비교합니다
Apr 14, 2025 am 12:13 AM
PHP와 Python은 각각 고유 한 장점이 있으며 프로젝트 요구 사항에 따라 선택합니다. 1.PHP는 웹 개발, 특히 웹 사이트의 빠른 개발 및 유지 보수에 적합합니다. 2. Python은 간결한 구문을 가진 데이터 과학, 기계 학습 및 인공 지능에 적합하며 초보자에게 적합합니다.
 DDOS 공격 탐지에서 데비안 스나이퍼의 역할
Apr 12, 2025 pm 10:42 PM
DDOS 공격 탐지에서 데비안 스나이퍼의 역할
Apr 12, 2025 pm 10:42 PM
이 기사에서는 DDOS 공격 탐지 방법에 대해 설명합니다. "Debiansniffer"의 직접적인 적용 사례는 발견되지 않았지만 DDOS 공격 탐지에 다음과 같은 방법을 사용할 수 있습니다. 효과적인 DDOS 공격 탐지 기술 : 트래픽 분석을 기반으로 한 탐지 : 갑작스런 트래픽 성장, 특정 포트에서의 연결 감지 등의 비정상적인 네트워크 트래픽 패턴을 모니터링하여 DDOS 공격을 식별합니다. 예를 들어, Pyshark 및 Colorama 라이브러리와 결합 된 Python 스크립트는 실시간으로 네트워크 트래픽을 모니터링하고 경고를 발행 할 수 있습니다. 통계 분석에 기반한 탐지 : 데이터와 같은 네트워크 트래픽의 통계적 특성을 분석하여
 NGINX SSL 인증서 업데이트 Debian Tutorial
Apr 13, 2025 am 07:21 AM
NGINX SSL 인증서 업데이트 Debian Tutorial
Apr 13, 2025 am 07:21 AM
이 기사에서는 Debian 시스템에서 NginxSSL 인증서를 업데이트하는 방법에 대해 안내합니다. 1 단계 : CertBot을 먼저 설치하십시오. 시스템에 CERTBOT 및 PYTHON3-CERTBOT-NGINX 패키지가 설치되어 있는지 확인하십시오. 설치되지 않은 경우 다음 명령을 실행하십시오. sudoapt-getupdatesudoapt-getinstallcertbotpython3-certbot-nginx 2 단계 : 인증서 획득 및 구성 rectbot 명령을 사용하여 nginx를 획득하고 nginx를 구성하십시오.
 Debian Readdir가 다른 도구와 통합하는 방법
Apr 13, 2025 am 09:42 AM
Debian Readdir가 다른 도구와 통합하는 방법
Apr 13, 2025 am 09:42 AM
데비안 시스템의 readdir 함수는 디렉토리 컨텐츠를 읽는 데 사용되는 시스템 호출이며 종종 C 프로그래밍에 사용됩니다. 이 기사에서는 ReadDir를 다른 도구와 통합하여 기능을 향상시키는 방법을 설명합니다. 방법 1 : C 언어 프로그램을 파이프 라인과 결합하고 먼저 C 프로그램을 작성하여 readDir 함수를 호출하고 결과를 출력하십시오.#포함#포함#포함#포함#includinTmain (intargc, char*argv []) {dir*dir; structdirent*entry; if (argc! = 2) {
 파이썬과 시간 : 공부 시간을 최대한 활용
Apr 14, 2025 am 12:02 AM
파이썬과 시간 : 공부 시간을 최대한 활용
Apr 14, 2025 am 12:02 AM
제한된 시간에 Python 학습 효율을 극대화하려면 Python의 DateTime, Time 및 Schedule 모듈을 사용할 수 있습니다. 1. DateTime 모듈은 학습 시간을 기록하고 계획하는 데 사용됩니다. 2. 시간 모듈은 학습과 휴식 시간을 설정하는 데 도움이됩니다. 3. 일정 모듈은 주간 학습 작업을 자동으로 배열합니다.
 Debian OpenSSL에서 HTTPS 서버를 구성하는 방법
Apr 13, 2025 am 11:03 AM
Debian OpenSSL에서 HTTPS 서버를 구성하는 방법
Apr 13, 2025 am 11:03 AM
데비안 시스템에서 HTTPS 서버를 구성하려면 필요한 소프트웨어 설치, SSL 인증서 생성 및 SSL 인증서를 사용하기 위해 웹 서버 (예 : Apache 또는 Nginx)를 구성하는 등 여러 단계가 포함됩니다. 다음은 Apacheweb 서버를 사용하고 있다고 가정하는 기본 안내서입니다. 1. 필요한 소프트웨어를 먼저 설치하고 시스템이 최신 상태인지 확인하고 Apache 및 OpenSSL을 설치하십시오 : Sudoaptupdatesudoaptupgradesudoaptinsta
