

크롤러가 캡처하는 데이터가 계속 증가함에 따라 지난 이틀 동안 데이터베이스 및 쿼리 문이 지속적으로 최적화되었습니다. 테이블 구조 중 하나는 다음과 같습니다.
CREATE TABLE `newspaper_article` ( `id` varchar(50) NOT NULL COMMENT '编号', `title` varchar(190) NOT NULL COMMENT '标题', `author` varchar(255) DEFAULT NULL COMMENT '作者', `date` date NULL DEFAULT NULL COMMENT '发表时间', `content` longtext COMMENT '正文', `status` tinyint(4) DEFAULT '0', PRIMARY KEY (`id`), KEY `idx_status_date` (`status`,`date`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='文章表';
비즈니스 요구에 따라 idx_status_date 인덱스가 추가되었습니다. 특히 다음 SQL을 실행할 때 시간이 많이 걸립니다.
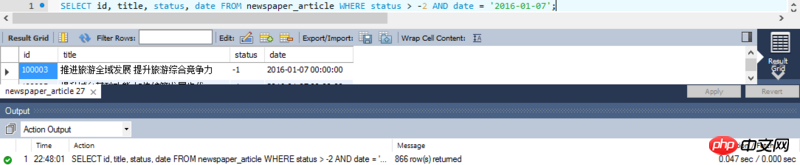
SELECT id, title, status, date FROM article WHERE status > -2 AND date = '2016-01-07';
관찰에 따르면 새로운 데이터 수가 매일 추가되는 건 대략 2,500개 이하인 것 같아요. 특정 날짜'2016-01-07'에 실제로 스캔해야 하는 데이터 양은 2,500개 이내여야 하는데 그렇지 않습니다. 
실제로 스캔된 데이터는 총 185,589개로 추정치인 2500개보다 훨씬 많으며, 실제 실행 시간은 거의 3초에 가깝습니다.

이게 왜죠?
idx_status_date (status, date)을 idx_status (status)으로 변경한 후 MySQL 실행 계획을 확인하세요.

다중 컬럼 인덱스를 단일 컬럼 인덱스로 변경한 후에도 실행 계획에 의해 스캔되는 전체 데이터 양에는 변화가 없음을 알 수 있다. 다중 열 인덱스가 가장 왼쪽 접두사 원칙을 따른다는 사실과 결합하여 위 쿼리 문은 idx_status_date의 가장 왼쪽 status 인덱스만 사용하는 것으로 추측됩니다.
"고성능 MySQL"을 뒤져보니 다음 구절이 내 생각을 확증해주었습니다.
쿼리의 특정 열에 대한 범위 쿼리가 있는 경우 모든 열의 오른쪽은 인덱스 최적화를 사용하여 조회할 수 없습니다. 예를 들어
WHERE last_name = 'Smith' AND first_name LIKE 'J%' AND dob = '1976-12-23'쿼리가 있습니다. 여기서LIKE는 범위 조건이므로 이 쿼리는 인덱스의 처음 두 열만 사용할 수 있습니다(그러나 서버는 나머지 열을 다른 목적으로 사용할 수 있습니다). 범위 쿼리 열 값의 개수가 제한되어 있는 경우 여러 개의 동일 조건을 사용하여 범위 조건을 대체할 수 있습니다.
따라서 여기에는 두 가지 해결 방법이 있습니다.
여러 등호 조건을 사용하여 범위 조건을 바꿀 수 있습니다.
idx_status_date (status, date)을 수정하여 idx_date_status (date, status) 인덱스를 만들고 새 idx_status 인덱스를 만들어 동일한 효과를 얻으세요.
최적 실행 계획:

실제 실행 결과:
사람들이 인덱스에 대해 이야기할 때, 유형을 지정하지 않으면 아마도 B-Tree 데이터를 사용하는 B-Tree 인덱스에 대해 이야기하고 있을 것입니다. 데이터를 저장하는 구조. MySQL도 CREATE TABLE 및 기타 명령문에서 이 키워드를 사용하기 때문에 "B-Tree"라는 용어를 사용합니다. 그러나 기본 스토리지 엔진은 다른 스토리지 구조를 사용할 수도 있습니다. InnoDB는 B+Tree를 사용합니다.
다음과 같은 데이터 테이블이 있다고 가정합니다.
CREATE TABLE People ( last_name varchar(50) not null, first_name varchar(50) not null, dob date not null, gender enum('m', 'f') not null, key(last_name, first_name, dob) );
전체 값 일치
전체 값 일치는 인덱스의 모든 열 일치를 의미합니다. 예를 들어 위 표의 인덱스는 이름이 Cuba Allen이고 1960년 1월 1일에 태어난 사람을 찾는 데 사용될 수 있습니다.
가장 왼쪽 접두사와 일치
위 표의 색인은 성이 Allen인 모든 사람을 찾는 데 사용할 수 있습니다. 즉, 색인의 첫 번째 열만 사용됩니다. .
열 접두사 일치
열 값의 시작 부분만 일치합니다. 예를 들어 위 표의 색인을 사용하면 성이 J로 시작하는 모든 사람을 찾을 수 있습니다. 여기서는 인덱스의 첫 번째 열만 사용됩니다.
일치 범위 값
예를 들어 위 표의 색인을 사용하면 성이 Allen과 Barrymore 사이인 사람을 찾을 수 있습니다. 여기서는 인덱스의 첫 번째 열만 사용됩니다.
특정 열과 범위가 정확히 일치하고 다른 열과 범위가 일치
위 표의 인덱스를 사용하여 성이 Allen이고 이름이 다음으로 시작하는 모든 사람을 찾을 수도 있습니다. 문자 K(예: Kim, Karl 등) 사람. 즉, 첫 번째 열 last_name은 완전히 일치하고 두 번째 열 first_name은 범위와 일치합니다.
인덱스에만 접근하는 쿼리
B-Tree는 보통 "인덱스에만 접근하는 쿼리"를 지원한다. 즉, 쿼리는 인덱스에 접근하지 않고 인덱스에만 접근하면 된다. 데이터 행.
인덱스의 가장 왼쪽 열부터 검색이 시작되지 않으면 인덱스를 사용할 수 없습니다. 예를 들어 위 테이블의 인덱스는 Bill이라는 사람을 찾는 데 사용할 수 없으며 특정 생일을 가진 사람을 찾는 데 사용할 수도 없습니다. 두 열 모두 가장 왼쪽 데이터 열이 아니기 때문입니다. 마찬가지로 성이 특정 문자로 끝나는 사람을 찾을 방법도 없습니다.
인덱스의 열을 건너뛸 수 없습니다. 즉, 위 표의 색인은 특정 날짜에 태어난 Smith라는 성을 가진 사람을 찾는 데 사용할 수 없습니다. 이름(first_name)을 지정하지 않으면 MySQL은 인덱스의 첫 번째 열만 사용할 수 있습니다.
쿼리의 특정 열에 대한 범위 쿼리가 있는 경우 인덱스 최적화를 사용하여 그 오른쪽에 있는 모든 열을 검색할 수 없습니다. 예를 들어 WHERE last_name = 'Smith' AND first_name LIKE 'J%' AND dob = '1976-12-23' 쿼리가 있습니다. 여기서 LIKE는 범위 조건이므로 이 쿼리는 인덱스의 처음 두 열만 사용할 수 있습니다(그러나 서버는 나머지 열을 다른 목적으로 사용할 수 있습니다). 범위 쿼리 열 값의 개수가 제한되어 있는 경우 여러 개의 동일 조건을 사용하여 범위 조건을 대체할 수 있습니다.
위 내용은 MySQL 다중 열 인덱스 최적화 예제 코드 공유의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



