
XML 파일을 구문 분석하려면 다음과 같이 xml.etree.ElementTree 모듈을 사용하세요. ElementTree 모듈은 이 목적을 달성하기 위해 두 가지 클래스를 제공합니다.
ElementTree는 전체 XML 파일(트리 구조)을 나타냅니다.
요소는 트리의 요소(노드)를 나타냅니다.
다음 XML 파일을 운영합니다: migapp.xml

다음과 같이 ElementTree 모듈을 가져올 수 있습니다: import xml.etree.ElementTree as ET
또는 구문 분석기만 가져올 수 있습니다: from xml.etree.ElementTree import pars
먼저 xml 파일을 열어야 합니다. 로컬 파일의 경우 open 기능을 사용하세요. 인터넷 파일인 경우 urlopen:
f = open( ' migapp.xml ' , ' rt ' , 인코딩을 사용하세요. = ' utf -8 ' )
그런 다음 XML을 구문 분석합니다.
1.1 루트 요소 구문 분석
tree = ET.parse(f) root = tree.getroot() print('root.tag =', root.tag) print('root.attrib =', root.attrib)

1.2 아들 구문 분석 루트의
for child in root: # 仅可以解析出root的儿子,不能解析出root的子孙
print(child.tag)
print(child.attrib) # attrib is a dict
1.3 인덱스로 루트의 하위 항목 해결
print(root[1][1].tag) print(root[1][1].text)

1.4 지정된 모든 요소를 반복적으로 구문 분석
for element in root.iter('environment'):
print(element.attrib)
1.5 여러 가지 유용한 방법
# element.findall()解析出指定element的所有儿子
# element.find()解析出指定element的第一个儿子
# element.get()解析出指定element的属性attrib
for environment in root.findall('environment'):
first_variable = environment.find('variable')
print(first_variable.get('name'))
각 텍스트 요소에 size="50" 속성을 추가하고 해당 텍스트를 "Benxin Tuzi"로 수정한 다음 하위 요소 date="를 추가해야 한다고 가정해 보겠습니다. 2016/01/16"
for text in root.iter('text'):
text.set('size', '50')
text.text = 'Benxin Tuzi'
text.append(ET.Element('date', attrib={}, text='2016/01/16'))
tree.write('output.xml')migapp.xml 일부:
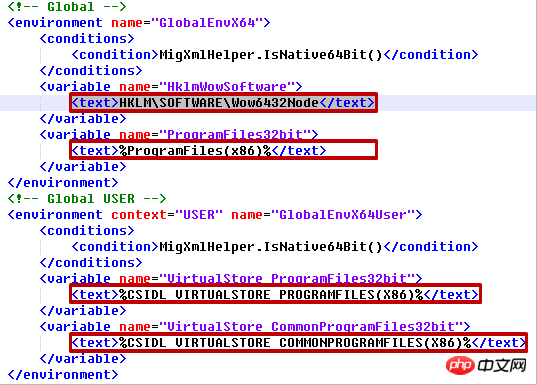
output.xml 해당 부분:
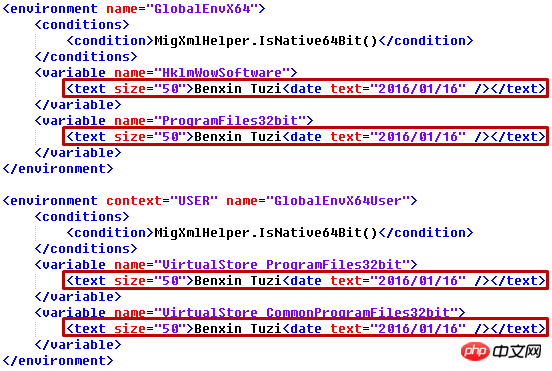
xml.py를 파일 이름으로 사용하지 마세요. 그렇지 않으면 다음 오류가 발생합니다.
ImportError: 'xml.etree'라는 모듈이 없습니다. 'xml'은 패키지가 아닙니다.
분석:
이것은 가져오기 때문입니다. 먼저 현재 경로를 검색한 후 xml.py 모듈이 존재한다는 것을 알게 되며, 우리가 직접 작성한 xml.py는 물론 패키지가 아닙니다
참고:
이후 xml.py를 삭제해도 여전히 성공적으로 설명할 수 없습니다. 이는 xml.pyc도 현재 경로에 생성되고 이 파일의 우선순위가 xml.py보다 높기 때문에 인터프리터가 여전히 xml.pyc에서 먼저 해당 파일을 찾기 때문입니다. 이므로 이 파일도 삭제해야 합니다.
결론:
스크립트에서 모듈이나 패키지를 사용하지 않더라도 파일 이름이 패키지 이름이나 모듈 이름과 동일하지 않도록 하세요. 그렇지 않으면 이상한 오류가 발생합니다. 발생할 수 있습니다.
ElementTree 모듈에서 제공되는 많은 구문 분석 기능은 전체 XML 문서를 미리 메모리로 읽어야 하는데, 이는 특히 대용량 XML 구문 분석에 좋지 않습니다. 네트워크나 파이프라인의 XML에서는 비차단 구문 분석이 매우 중요합니다. 이 시점에서 ElementTree 모듈의 XMLPullParse 클래스를 사용하여 이를 처리할 수 있습니다. 물론 대신 ElementTree 모듈의 iterparse()를 선택할 수도 있습니다. 이 메서드는 구문 분석 시 대용량 XML을 모두 메모리로 읽어올 필요가 없습니다.
위 내용은 Python 구문 분석 XML 파일 예제(그림)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



