
이 글은 주로 Java String 클래스에 대한 자세한 설명을 소개합니다. 이 글은 여러 출처에서 수집, 정리, 요약되어 마침내 글로 작성되었습니다. 필요한 사람은 참고하세요
소개 질문
Java 언어의 모든 데이터 유형 중에서 문자열 유형은 특수한 유형이며 인터뷰를 읽을 때 자주 묻는 지식 포인트입니다. 이 기사에서는 문자열에 관한 여러 가지 혼란스러운 문제에 대한 심층 분석을 Java 메모리 할당과 결합합니다. 다음은 이 문서에서 다룰 몇 가지 문제입니다. 독자가 이러한 문제에 대해 잘 알고 있으면 이 문서를 무시해도 됩니다.
1. 자바 메모리란 구체적으로 어떤 메모리를 지칭하나요? 왜 이 메모리 영역을 나누어야 할까요? 어떻게 나누어지나요? 분할 후 각 영역의 역할은 무엇입니까? 각 영역의 크기는 어떻게 설정하나요?
2. 연결 작업을 수행할 때 String 유형이 StringBuffer 또는 StringBuilder보다 효율성이 떨어지는 이유는 무엇입니까? StringBuffer와 StringBuilder의 연결과 차이점은 무엇입니까?
3. Java에서 상수란 무엇을 의미하나요? String s = "s"와 String s = new String("s")의 차이점은 무엇입니까?
이 글은 다양한 출처에서 취합, 요약하여 최종적으로 작성한 글입니다. 혹시 오류가 있으면 알려주세요!
Java 메모리 할당
1. JVM소개
Java 가상 머신(Java Virtual Machine, JVM이라고도 함)은 모든 Java 프로그램을 실행하는 추상적인 컴퓨터입니다. Java 언어의 실행 환경은 Java의 가장 매력적인 기능 중 하나입니다. 자바 가상 머신은 프로세서, 스택, 레지스터 등과 같은 완전한 하드웨어 아키텍처 를 가지며 이에 상응하는 명령어 시스템도 가지고 있습니다. JVM은 특정 운영 체제 플랫폼과 관련된 정보를 보호하므로 Java 프로그램은 Java 가상 머신에서 실행되는 대상 코드(바이트코드)만 생성하면 되며 수정 없이 여러 플랫폼에서 실행될 수 있습니다.
런타임 Java 가상 머신 인스턴스의 의무는 다음과 같습니다. Java 프로그램 실행을 담당합니다. Java 프로그램이 시작되면 가상 머신 인스턴스가 생성됩니다. 프로그램이 닫히고 종료되면 가상 머신 인스턴스도 종료됩니다. 세 개의 Java 프로그램이 동일한 컴퓨터에서 동시에 실행되면 세 개의 Java 가상 머신 인스턴스가 확보됩니다. 각 Java 프로그램은 자체 Java 가상 머신 인스턴스에서 실행됩니다.
아래 그림에 표시된 것처럼 JVM 아키텍처에는 여러 주요 하위 시스템과 메모리 영역이 포함됩니다.
힙 메모리(Heap)에서 사용되지 않는 객체를 재활용합니다. 더 이상 참조되지 않습니다. |
실행 엔진(실행 엔진): 로드된 클래스의 메서드에 포함된 명령을 실행하는 역할을 담당합니다.
런타임 데이터 영역 (Java 메모리 할당 영역): 가상 머신 메모리 또는 Java 메모리라고도 하며, 가상 머신이 실행될 때 컴퓨터 전체 메모리에서 메모리 영역을 나누어 많은 양을 저장해야 합니다. 것들. 예: 바이트코드, 로드된 클래스 파일에서 얻은 기타 정보, 프로그램에서 생성된 객체, 메서드에 전달된 매개변수, 반환 값, 지역 변수 등.
2. Java 메모리 파티션

프로그램 카운터(프로그램 카운트 레지스터): 프로그램 레지스터라고도 합니다. JVM은 동시에 실행되는 여러 스레드를 지원합니다. 각각의 새 스레드가 생성되면 자체 PC 레지스터(프로그램 카운터)를 갖게 됩니다. 스레드가 Java 메소드(비네이티브)를 실행하는 경우 PC 레지스터의 값은 항상 실행할 다음 명령을 가리킵니다. 메소드가 네이티브인 경우 프로그램 카운터 레지스터의 값은 정의되지 않습니다. JVM의 프로그램 카운터 레지스터는 반환 주소나 기본 포인터를 보유할 만큼 충분히 넓습니다. ~ JVM은 새로 생성된 각 스레드에 대해 스택을 할당합니다. 즉, Java 프로그램의 경우 스택의 연산을 통해 해당 작업이 완료됩니다. 스택은 스레드의 • -Xss --메서드 스택의 최대값 설정 메소드 영역 메소드의 유형 정보를 구문 분석한 후 유형 정보(클래스 정보, 상수, 정적 힙 (힙): Java 힙(Java Heap)은 Java 가상 머신이 관리하는 가장 큰 메모리 조각입니다. Java 힙은 모든 스레드가 공유하는 메모리 영역입니다. 이 영역의 유일한 목적은 객체 인스턴스를 저장하는 것입니다. 거의 모든 객체 인스턴스가 여기에 메모리를 할당하지만 이 객체에 대한 참조는 스택에 할당됩니다. 따라서 String s = new String("s")을 실행할 때 메모리는 두 위치에서 할당되어야 합니다. 메모리는 힙의 String 객체에 할당되고 는 스택의 참조(메모리 주소)입니다. 이 힙 객체, 즉 포인터)는 아래 그림과 같이 메모리를 할당합니다. • -Xms -- 힙 메모리의 초기 크기 설정 • -XX :MaxTenuringThreshold -- 객체가 새 세대에서 생존하는 횟수 설정 Java 힙은 Garbage Collector가 관리하는 주요 영역이므로 "GC Heap"(Garbage Collectioned Heap)이라고도 합니다. 오늘날의 가비지 수집기는 기본적으로 세대별 수집 알고리즘을 사용하므로 Java 힙은 아래 그림과 같이 Young Generation과 Old Generation으로 세분화될 수 있습니다. 세대별 수집 알고리즘 아이디어: 첫 번째 방법은 젊은 개체(young Generation)를 더 높은 빈도로 스캔하고 재활용하는 것입니다. 이를 마이너 컬렉션이라고 하며, 오래된 개체(old Generation)를 확인하고 재활용하는 빈도는 낮습니다. 많이, 메이저 컬렉션이라고 부릅니다. 이렇게 하면 GC를 사용할 때마다 메모리의 모든 개체를 확인할 필요가 없으므로 응용 프로그램 시스템에서 사용할 수 있는 시스템 리소스를 더 많이 확보할 수 있습니다. 메모리, 새로운 세대(Young GC)에서 먼저 GC가 수행되고, 새로운 세대 GC가 여전히 메모리 공간 할당 요구 사항을 충족할 수 없는 경우 전체 힙 공간 및 메서드 영역에서 GC(Full GC)가 수행됩니다. 일부 독자는 여기에 질문이 있을 수 있습니다. 영구 세대(Permanent Generation)가 있다는 것을 기억하세요. 이는 Java 힙에 속하지 않습니까? 친애하는, 당신 말이 맞았어! 실제로 전설적인 영구 생성은 위에서 언급한 메소드 영역으로, jvm이 초기화될 때 로더에 의해 로드되는 일부 유형 정보(클래스 정보, 상수, 정적 변수 등 포함)를 저장합니다. 이 정보의 수명 주기는 상대적으로 짧습니다. PermGen Space는 기본 프로그램 실행 중에 정리되므로 애플리케이션에 CLASS가 많으면 PermGen Space 오류가 발생할 가능성이 높습니다. 관련 설정 매개변수: • -XX:PermSize --Perm 영역의 초기 크기 설정 • -XX:MaxPermSize --Perm 영역의 최대값 설정 🎜>신세대(Young Generation)는 에덴(Eden) 영역과 서바이버(Survivor) 영역으로 나누어집니다. Eden 영역은 객체가 처음 할당되는 곳입니다. 기본적으로 From Space와 To Space의 영역은 크기가 동일합니다. JVM은 Minor GC를 수행할 때 Eden에서 살아남은 객체를 Survivor 영역에 복사하고, Survivor 영역에서 살아남은 객체도 Tenured 영역에 복사합니다. 이 GC 모드에서는 GC 효율성을 높이기 위해 JVM이 Survivor를 From Space와 To Space로 나누어 객체 재활용과 객체 승격을 분리할 수 있습니다. 새로운 세대의 크기 설정에는 두 가지 관련 매개변수가 있습니다: 3. String 유형 심층 분석 Java 데이터 유형부터 살펴보겠습니다! Java 데이터 유형은 일반적으로 기본 유형과 참조 유형의 두 가지 범주로 나뉩니다. 기본 유형의 변수는 기본 값을 보유하고 참조 유형의 변수는 일반적으로 실제 객체에 대한 참조를 나타냅니다. 개체. String의 소스코드를 열어보면 클래스 댓글 다음으로 String 클래스는 String 클래스의 두 번째 기능을 나타내는 final 수정자를 사용합니다. 즉, String 클래스는 상속 다음은 String 클래스의 멤버 변수 정의로, 클래스 구현 시 String 값이 불변(immutable)임을 명시합니다. 그래서 String 클래스의 concat 메소드를 살펴보겠습니다. 이 방법을 구현하기 위한 첫 번째 단계는 멤버 변수 값의 용량을 확장하는 것입니다. 확장 방법은 대용량 문자 배열 buf를 재정의하는 것입니다. 두 번째 단계는 원래 값의 문자를 buf에 복사한 다음, 연결해야 할 문자열 값을 buf에 복사하는 것입니다. 이런 방식으로 buf에는 concat 뒤에 문자열 값이 포함됩니다. 문제의 핵심은 다음과 같습니다. 값이 최종 값이 아닌 경우 값을 buf에 직접 지정한 다음 이를 반환하면 새 String 개체를 반환할 필요가 없습니다. 하지만. . . 연민. . . 값은 최종이므로 새로 정의된 대용량 배열 buf를 가리킬 수 없습니다. 어떻게 해야 합니까? "return new String(0, count + otherLen, buf);"는 String 클래스 concat 구현 메소드의 마지막 명령문이며, 새로운 String 객체를 반환합니다. 이제 진실이 드러납니다! 요약: 문자열은 기본적으로 두 가지 특성을 지닌 문자 배열입니다. 1. 이 클래스는 상속될 수 없습니다. 2. 변경할 수 없습니다. 2. String의 정의 방법 String의 정의 방법을 논하기 전에 먼저 Constant Pool의 개념을 이해해보자. 앞서 지구에서 언급한 바 있다. 약간 공식적인 정의를 내려 보겠습니다. 상수 풀은 컴파일 중에 결정되어 컴파일된 .class 파일에 저장되는 일부 데이터를 의미합니다. 여기에는 클래스, 메서드, 인터페이스 등의 상수와 문자열 상수가 포함됩니다. 상수 풀도 동적이며 런타임 중에 새 상수를 풀에 넣을 수 있습니다. String 클래스의 intern() 메서드는 이 기능의 일반적인 응용 프로그램입니다. 이해가 안 되나요? 인턴 방법은 추후에 소개하겠습니다. 가상 머신은 로드된 각 유형에 대해 상수 풀을 유지 관리합니다. 풀은 직접 상수(문자열, 정수 및 부동 소수점 상수)와 다른 유형, 필드 및 메소드에 대한 기호 참조를 포함하여 유형에서 사용되는 순서가 지정된 상수 모음입니다. 그것과 객체 참조의 차이점은 독자가 스스로 알 수 있습니까? string의 정의 방법을 총 정리하면 다음과 같습니다. • New 키워드를 사용합니다. 예: string s1 = new string ("mystring" ("mystring" ) ; • 다음과 같은 직접 정의: String s1 = "myString"; • 다음과 같은 연결 생성: String s1 = "my" + "String" 이 방법은 더 복잡합니다. . 여기서는 자세히 설명하지 않겠습니다. 첫 번째 방법은 new 키워드를 통해 프로세스를 정의하는 것입니다. 프로그램을 컴파일하는 동안 컴파일러는 먼저 문자열 상수 풀을 확인하여 "myString"이 존재하지 않는지 확인합니다. 상수 풀. 공간에 "myString"이 저장되어 있으면 상수 풀에 "myString" 상수가 하나만 있는지 확인하기 위해 공간을 다시 열 필요가 없으므로 메모리 공간이 절약됩니다. 그런 다음 메모리 힙에 공간을 열어 새 String 인스턴스를 저장합니다. 스택에 공간을 만들고 이름을 "s1"로 지정합니다. 이 프로세스는 힙에 있는 String 인스턴스의 메모리 주소입니다. s1을 새 인스턴스로 참조합니다. 두 번째 방법은 프로세스를 직접 정의하는 것입니다. 프로그램을 컴파일하는 동안 컴파일러는 먼저 문자열 상수 풀을 확인하여 "myString"이 존재하지 않는 경우 메모리를 엽니다. 상수 풀. 공간에 "myString"이 저장되어 있으면 공간을 다시 열 필요가 없습니다. 그런 다음 스택에서 공간을 열고 이름을 "s1"로 지정한 다음 값을 상수 풀에 "myString"의 메모리 주소로 저장합니다. 질문이 많기 때문에 힙에 있는 String 객체와 상수 풀에 있는 String 상수 사이의 관계에 대해 논의하겠습니다. 이 주제. 第一种猜想:因为直接定义的字符串也可以调用String对象的各种方法,那么可以认为其实在常量池中创建的也是一个String实例(对象)。 这种猜想认为:常量池中的字符串常量实质上是一个String实例,与堆中的String实例是克隆关系。 第二种猜想也是目前网上阐述的最多的,但是思路都不清晰,有些问题解释不通。下面引用《JAVA String对象和字符串常量的关系解析》一段内容。 在解析阶段,虚拟机发现字符串常量"myString",它会在一个内部字符串常量列表中查找,如果没有找到,那么会在堆里面创建一个包含字符序列[myString]的String对象s1,然后把这个字符序列和对应的String对象作为名值对( [myString], s1 )保存到内部字符串常量列表中。如下图所示: 如果虚拟机后面又发现了一个相同的字符串常量myString,它会在这个内部字符串常量列表内找到相同的字符序列,然后返回对应的String对象的引用。维护这个内部列表的关键是任何特定的字符序列在这个列表上只出现一次。 这个猜想有一个比较明显的问题,红色字体标示的地方就是问题的所在。证明方式很简单,下面这段代码的执行结果,javaer都应该知道。
상태
변수 포함)를 입력합니다. 등)을 메소드 영역에 추가합니다. 아래 그림과 같이 이 메모리 영역은 모든 스레드에서 공유됩니다. 로컬 메소드 영역에는 상수 풀(Constant Pool)이라는 특수 메모리 영역이 있습니다. 이 메모리는 문자열 유형 분석과 밀접한 관련이 있습니다. 

• -Xmx -- 힙 메모리의 최대 크기 설정 

1. String의 본질 private final char value[];
private final int count;
String s1 = new String("myString");先在编译期的时候在常量池创建了一个String实例,然后clone了一个String实例存储在堆中,引用s1指向堆中的这个实例。此时,池中的实例没有被引用。当接着执行String s1 = "myString";时,因为池中已经存在“myString”的实例对象,则s1直接指向池中的实例对象;否则,在池中先创建一个实例对象,s1再指向它。如下图所示: 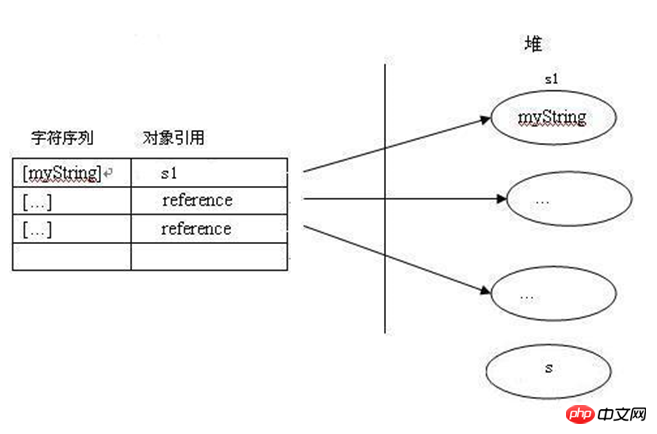
例如,String s2 = "myString",运行时s2会从内部字符串常量列表内得到s1的返回值,所以s2和s1都指向同一个String对象。String s1 = new String("myString");
String s2 = "myString";
System.out.println(s1 == s2); //按照上面的推测逻辑,那么打印的结果为true;而实际上真实的结果是false,因为s1指向的是堆中String对象,而s2指向的是常量池中的String常量。
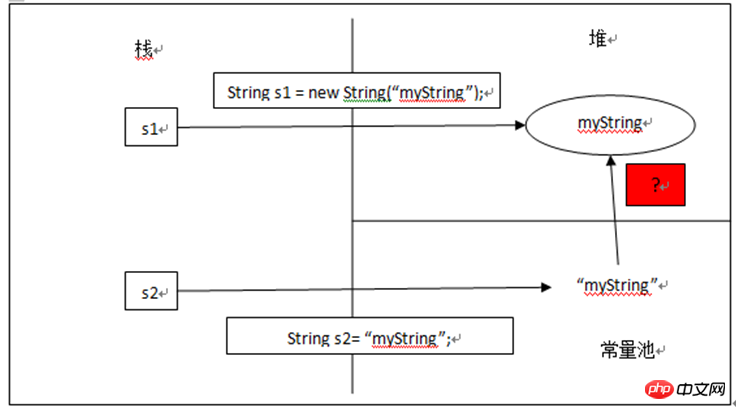
虽然这段内容不那么有说服力,但是文章提到了一个东西——字符串常量列表,它可能是解释这个问题的关键。
文中提到的三个问题,本文仅仅给出了猜想,具体请自己考证!
• 堆中new出来的实例和常量池中的“myString”是什么关系呢?
• 常量池中的字符串常量与堆中的String对象有什么区别呢?
• 为什么直接定义的字符串同样可以调用String对象的各种方法呢?
3、String、StringBuffer、StringBuilder的联系与区别
上面已经分析了String的本质了,下面简单说说StringBuffer和StringBuilder。
StringBuffer和StringBuilder都继承了抽象类AbstractStringBuilder,这个抽象类和String一样也定义了char[] value和int count,但是与String类不同的是,它们没有final修饰符。因此得出结论:String、StringBuffer和StringBuilder在本质上都是字符数组,不同的是,在进行连接操作时,String每次返回一个新的String实例,而StringBuffer和StringBuilder的append方法直接返回this,所以这就是为什么在进行大量字符串连接运算时,不推荐使用String,而推荐StringBuffer和StringBuilder。那么,哪种情况使用StringBuffe?哪种情况使用StringBuilder呢?
关于StringBuffer和StringBuilder的区别,翻开它们的源码,下面贴出append()方法的实现。

위의 첫 번째 그림은 StringBuffer의 Append() 메소드 구현이고, 두 번째 그림은 StringBuilder의 Append() 메소드 구현입니다. StringBuffer는 동기화 역할을 하며 멀티 스레드 환경에서 사용할 수 있는 메서드 앞에 동기화된 수정 사항을 추가합니다. 이에 대한 대가로 실행 효율성이 저하됩니다. 따라서 다중 스레드 환경에서 문자열 연결 작업에 StringBuffer를 사용할 수 있다면 단일 스레드 환경에서 StringBuilder를 사용하는 것이 더 효율적입니다.
위 내용은 Java의 String 클래스에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



