

dom4j를 통해 xml 문자열을 구문 분석하는 방법 공유
May 04, 2017 pm 03:46 PMDOM4J
XML을 구문 분석하기 위해 DOM, SAX 및 JAXP 메커니즘을 사용하는 것과 비교할 때 DOM4J는 더 나은 성능을 발휘하고 탁월한 성능과 강력한 기능을 제공하며 매우 사용하기 쉽다는 특징으로 DOM의 기본 개념만 이해하면 dom4j의 api 문서를 통해 xml을 파싱할 수 있습니다. dom4j는 오픈 소스 API 세트입니다. 실제 프로젝트에서는 xml 구문 분석 도구로 dom4j를 선택하는 경우가 많습니다.
먼저 dom4j의 XML에 해당하는 DOM 트리에 의해 성립되는 상속 관계를 살펴보겠습니다
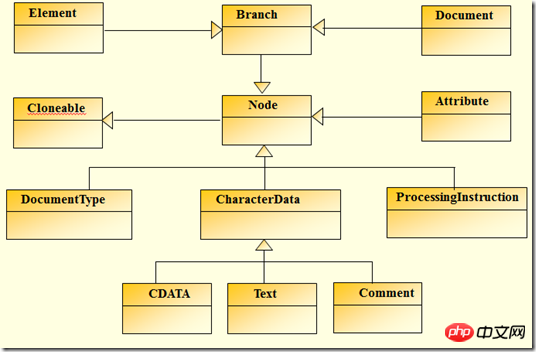
그림 2-1에 나열된 콘텐츠에 해당하는 XML 표준 정의의 경우 dom4j는 다음 구현을 제공합니다.
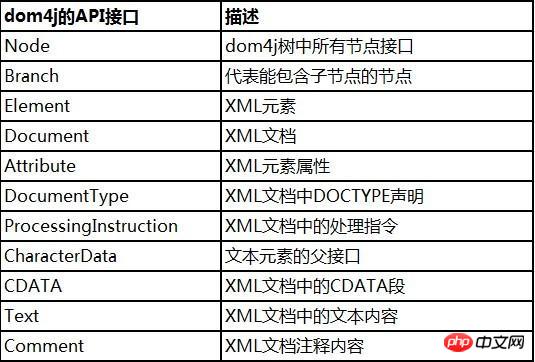
동시에 dom4j의 NodeType 열거는 XML 사양에 정의된 노드 유형을 구현합니다. 이런 식으로 XML 문서를 순회할 때 상수 를 통해 노드 유형을 결정할 수 있습니다.
공통 API
class org.dom4j.io.SAXReader
read는 xml 파일을 읽는 다양한 방법을 제공하고 Domcument 객체
iterator 이 방법을 사용하여 노드
를 가져옵니다. getRootElement 루트 노드 가져오기
interface org.dom4j.Node
-
getName 노드 이름을 가져옵니다. 예를 들어 루트 노드 이름은 bookstore입니다.
getNodeType 노드 유형 상수 값을 가져옵니다(예: bookstore 유형) 1 - Element
getNodeTypeName 노드 유형 이름을 가져옵니다. 예를 들어 가져온 서점 유형 이름은 Element
- attributes 요소의
- attributeValue 전달된 속성 이름을 기반으로 속성 값을 가져옵니다.
- elementIterator 하위 요소를 포함하는 반복자를 반환합니다. 🎜>
- getName 속성 이름 가져오기
-
- getText 텍스트 노드 값 가져오기
- getText CDATA 섹션 값 가져오기
getText 获取注释
实例一:
1 //先加入dom4j.jar包 2 import java.util.HashMap; 3 import java.util.Iterator; 4 import java.util.Map; 5 6 import org.dom4j.Document; 7 import org.dom4j.DocumentException; 8 import org.dom4j.DocumentHelper; 9 import org.dom4j.Element; 10 11 /** 12 * @Title: TestDom4j.java 13 * @Package
14 * @Description: 解析xml字符串 15 * @author 无处不在 16 * @date 2012-11-20 下午05:14:05 17 * @version V1.0
18 */ 19 public class TestDom4j { 20 21 public void readStringXml(String xml) { 22 Document doc = null; 23 try { 24 25 // 读取并解析XML文档 26 // SAXReader就是一个管道,用一个流的方式,把xml文件读出来 27 // 28 // SAXReader reader = new SAXReader(); //User.hbm.xml表示你要解析的xml文档 29 // Document document = reader.read(new File("User.hbm.xml")); 30 // 下面的是通过解析xml字符串的 31 doc = DocumentHelper.parseText(xml); // 将字符串转为XML 32 33 Element rootElt = doc.getRootElement(); // 获取根节点 34 System.out.println("根节点:" + rootElt.getName()); // 拿到根节点的名称 35 36 Iterator iter = rootElt.elementIterator("head"); // 获取根节点下的子节点head 37 38 // 遍历head节点 39 while (iter.hasNext()) { 40 41 Element recordEle = (Element) iter.next(); 42 String title = recordEle.elementTextTrim("title"); // 拿到head节点下的子节点title值 43 System.out.println("title:" + title); 44 45 Iterator iters = recordEle.elementIterator("script"); // 获取子节点head下的子节点script 46 47 // 遍历Header节点下的Response节点 48 while (iters.hasNext()) { 49 50 Element itemEle = (Element) iters.next(); 51 52 String username = itemEle.elementTextTrim("username"); // 拿到head下的子节点script下的字节点username的值 53 String password = itemEle.elementTextTrim("password"); 54 55 System.out.println("username:" + username); 56 System.out.println("password:" + password); 57 } 58 } 59 Iterator iterss = rootElt.elementIterator("body"); ///获取根节点下的子节点body 60 // 遍历body节点 61 while (iterss.hasNext()) { 62 63 Element recordEless = (Element) iterss.next(); 64 String result = recordEless.elementTextTrim("result"); // 拿到body节点下的子节点result值 65 System.out.println("result:" + result); 66 67 Iterator itersElIterator = recordEless.elementIterator("form"); // 获取子节点body下的子节点form 68 // 遍历Header节点下的Response节点 69 while (itersElIterator.hasNext()) { 70 71 Element itemEle = (Element) itersElIterator.next(); 72 73 String banlce = itemEle.elementTextTrim("banlce"); // 拿到body下的子节点form下的字节点banlce的值 74 String subID = itemEle.elementTextTrim("subID"); 75 76 System.out.println("banlce:" + banlce); 77 System.out.println("subID:" + subID); 78 } 79 } 80 } catch (DocumentException e) { 81 e.printStackTrace(); 82 83 } catch (Exception e) { 84 e.printStackTrace(); 85 86 } 87 } 88 89 /** 90 * @description 将xml字符串转换成map 91 * @param xml 92 * @return Map 93 */ 94 public static Map readStringXmlOut(String xml) { 95 Map map = new HashMap(); 96 Document doc = null; 97 try { 98 // 将字符串转为XML 99 doc = DocumentHelper.parseText(xml);
100 // 获取根节点101 Element rootElt = doc.getRootElement();
102 // 拿到根节点的名称103 System.out.println("根节点:" + rootElt.getName());
104 105 // 获取根节点下的子节点head106 Iterator iter = rootElt.elementIterator("head");
107 // 遍历head节点108 while (iter.hasNext()) {109 110 Element recordEle = (Element) iter.next();111 // 拿到head节点下的子节点title值112 String title = recordEle.elementTextTrim("title");
113 System.out.println("title:" + title);114 map.put("title", title);115 // 获取子节点head下的子节点script116 Iterator iters = recordEle.elementIterator("script");
117 // 遍历Header节点下的Response节点118 while (iters.hasNext()) {119 Element itemEle = (Element) iters.next();120 // 拿到head下的子节点script下的字节点username的值121 String username = itemEle.elementTextTrim("username");
122 String password = itemEle.elementTextTrim("password");123 124 System.out.println("username:" + username);125 System.out.println("password:" + password);126 map.put("username", username);127 map.put("password", password);128 }129 }130 131 //获取根节点下的子节点body132 Iterator iterss = rootElt.elementIterator("body");
133 // 遍历body节点134 while (iterss.hasNext()) {135 Element recordEless = (Element) iterss.next();136 // 拿到body节点下的子节点result值137 String result = recordEless.elementTextTrim("result");
138 System.out.println("result:" + result);139 // 获取子节点body下的子节点form140 Iterator itersElIterator = recordEless.elementIterator("form");
141 // 遍历Header节点下的Response节点142 while (itersElIterator.hasNext()) {143 Element itemEle = (Element) itersElIterator.next();144 // 拿到body下的子节点form下的字节点banlce的值145 String banlce = itemEle.elementTextTrim("banlce");
146 String subID = itemEle.elementTextTrim("subID");147 148 System.out.println("banlce:" + banlce);149 System.out.println("subID:" + subID);150 map.put("result", result);151 map.put("banlce", banlce);152 map.put("subID", subID);153 }154 }155 } catch (DocumentException e) {156 e.printStackTrace();157 } catch (Exception e) {158 e.printStackTrace();159 }160 return map;161 }162 163 public static void main(String[] args) {164 165 // 下面是需要解析的xml字符串例子166 String xmlString = "<html>" + "<head>" + "<title>dom4j解析一个例子</title>"167 + "<script>" + "<username>yangrong</username>"168 + "<password>123456</password>" + "</script>" + "</head>"169 + "<body>" + "<result>0</result>" + "<form>"170 + "<banlce>1000</banlce>" + "<subID>36242519880716</subID>"171 + "</form>" + "</body>" + "</html>";172 173 /*174 * Test2 test = new Test2(); test.readStringXml(xmlString);175 */176 Map map = readStringXmlOut(xmlString);177 Iterator iters = map.keySet().iterator();178 while (iters.hasNext()) {179 String key = iters.next().toString(); // 拿到键180 String val = map.get(key).toString(); // 拿到值181 System.out.println(key + "=" + val);182 }183 }184 185 }实例二: 1 /** 2 * 解析包含有DB连接信息的XML文件 3 * 格式必须符合如下规范: 4 * 1. 最多三级,每级的node名称自定义; 5 * 2. 二级节点支持节点属性,属性将被视作子节点; 6 * 3. CDATA必须包含在节点中,不能单独出现。 7 * 8 * 示例1——三级显示: 9 * <db-connections>10 * <connection>11 * <name>DBTest</name>12 * <jndi></jndi>13 * <url>14 * <![CDATA[jdbc:mysql://localhost:3306/db_test?useUnicode=true&characterEncoding=UTF8]]>15 * </url>16 * <driver>org.gjt.mm.mysql.Driver</driver>17 * <user>test</user>18 * <password>test2012</password>19 * <max-active>10</max-active>20 * <max-idle>10</max-idle>21 * <min-idle>2</min-idle>22 * <max-wait>10</max-wait>23 * <validation-query>SELECT 1+1</validation-query>24 * </connection>25 * </db-connections>26 *27 * 示例2——节点属性:28 * <bookstore>29 * <book category="cooking">30 * <title lang="en">Everyday Italian</title>31 * <author>Giada De Laurentiis</author>32 * <year>2005</year>33 * <price>30.00</price>34 * </book>35 *36 * <book category="children" title="Harry Potter" author="J K. Rowling" year="2005" price="$29.9"/>37 * </bookstore>38 *39 * @param configFile40 * @return41 * @throws Exception42 */43 public static List<Map<String, String>> parseDBXML(String configFile) throws Exception {44 List<Map<String, String>> dbConnections = new ArrayList<Map<String, String>>();45 InputStream is = Parser.class.getResourceAsStream(configFile);46 SAXReader saxReader = new SAXReader();47 Document document = saxReader.read(is);48 Element connections = document.getRootElement();49 50 Iterator<Element> rootIter = connections.elementIterator();51 while (rootIter.hasNext()) {52 Element connection = rootIter.next();53 Iterator<Element> childIter = connection.elementIterator();54 Map<String, String> connectionInfo = new HashMap<String, String>();55 List<Attribute> attributes = connection.attributes();56 for (int i = 0; i < attributes.size(); ++i) { // 添加节点属性57 connectionInfo.put(attributes.get(i).getName(), attributes.get(i).getValue());58 }59 while (childIter.hasNext()) { // 添加子节点60 Element attr = childIter.next();61 connectionInfo.put(attr.getName().trim(), attr.getText().trim());62 }63 dbConnections.add(connectionInfo);64 }65 66 return dbConnections;67 }【相关推荐】
1. XML免费视频教程
2. XML技术手册
위 내용은 dom4j를 통해 xml 문자열을 구문 분석하는 방법 공유의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

인기 기사


인기 기사

뜨거운 기사 태그

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7131
7131
 9
1534
14
1256
25
1205
29
1153
46
9
1534
14
1256
25
1205
29
1153
46



 Golang에서 문자열이 특정 문자로 시작하는지 확인하는 방법은 무엇입니까?
Mar 12, 2024 pm 09:42 PM
Golang에서 문자열이 특정 문자로 시작하는지 확인하는 방법은 무엇입니까?
Mar 12, 2024 pm 09:42 PM
Golang에서 문자열이 특정 문자로 시작하는지 확인하는 방법은 무엇입니까?
 python_python 반복 문자열 튜토리얼에서 문자열을 반복하는 방법
Apr 02, 2024 pm 03:58 PM
python_python 반복 문자열 튜토리얼에서 문자열을 반복하는 방법
Apr 02, 2024 pm 03:58 PM
python_python 반복 문자열 튜토리얼에서 문자열을 반복하는 방법
 PHP에서 16진수를 문자열로 변환할 때 중국어 문자가 깨지는 문제를 해결하는 방법
Mar 04, 2024 am 09:36 AM
PHP에서 16진수를 문자열로 변환할 때 중국어 문자가 깨지는 문제를 해결하는 방법
Mar 04, 2024 am 09:36 AM
PHP에서 16진수를 문자열로 변환할 때 중국어 문자가 깨지는 문제를 해결하는 방법



