

Python에서 memcached 동작에 대한 자세한 설명(그림 및 텍스트)

머리말
많은 웹 애플리케이션은 MySQL과 같은 관계형 데이터베이스 관리 시스템에 데이터를 저장합니다. 그것에서 그것을 브라우저에 표시합니다. 그러나 데이터의 양이 증가하고 접속이 집중될수록 데이터베이스에 대한 부담 증가, 데이터베이스 응답 저하, 웹 사이트 표시 지연 등의 부작용이 발생할 수 있습니다. 분산 캐싱은 웹사이트 성능을 최적화하는 중요한 수단입니다. 많은 사이트가 확장 가능한 서버 클러스터를 통해 대규모 핫 데이터 캐싱 서비스를 제공하고 있습니다. 데이터 캐싱 라이브러리 쿼리 결과를 저장하고 데이터베이스 액세스 횟수를 줄임으로써 동적 웹 애플리케이션의 속도와 확장성을 크게 향상시킬 수 있습니다. 업계에서 흔히 사용하는 것으로는 redis, memcached 등이 있습니다. 오늘 이야기하고 싶은 것은 python 프로젝트에서 memcached 캐시 서비스를 사용하는 방법입니다. .
memcached소개
memcached는 오픈 소스, 고성능, 분산 메모리 객체캐싱 시스템입니다. 적용 다양한 시나리오에 캐싱이 필요하며, 그 주요 목적은 데이터베이스에 대한 액세스를 줄여 웹 애플리케이션 속도를 높이는 것입니다.
Memcached 자체는 실제로 분산 솔루션을 제공하지 않습니다. 서버 측에서 memcached 클러스터 환경은 실제로 memcached 서버의 축적이며, 환경 구성은 상대적으로 간단합니다. 캐시 배포는 주로 클라이언트에서 구현되며 클라이언트의 를 통해 처리됩니다. 라우팅 분산 솔루션의 목적을 달성합니다. 클라이언트 라우팅의 원리는 매우 간단합니다. 애플리케이션 서버는 특정 키의 값에 액세스할 때마다 라우팅 알고리즘을 통해 해당 키를 특정 memcached 서버 nodeA에 매핑합니다. nodeA에서 수행됩니다. 서버가 여전히 데이터를 캐시하는 한 캐시 적중은 보장됩니다. 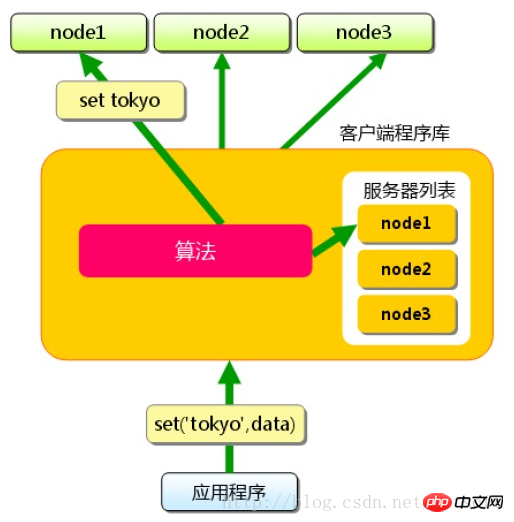
라우팅 알고리즘
간단한 라우팅 알고리즘
나머지를 이용한 단순 라우팅 알고리즘해시: 해시 값을 사용 캐시된 데이터 키를 서버 수로 나눈 나머지는 서버 목록 아래 표의 숫자입니다. 이 알고리즘은 memcached 클러스터 전체에 캐시 데이터를 균등하게 배포할 수 있으며 대부분의 캐시 라우팅 요구 사항도 충족할 수 있습니다.
그러나 memcached 클러스터를 확장해야 하는 경우 문제가 발생합니다. 예를 들어 웹사이트는 3개의 캐시 서버 용량을 4개의 캐시 서버로 확장해야 합니다. 서버 목록을 변경한 후에도 나머지 해시를 계속 사용한다면 요청의 75%가 캐시에 도달하지 않을 것이라고 쉽게 계산할 수 있습니다. 서버 클러스터의 규모가 커질수록 미스율도 높아집니다.
1%3 = 1 1%4 = 1 2%3 = 2 2%4 = 2 3%3 = 0 3%4 = 3 4%4 = 1 4%4 = 0 #以此类推
이러한 확장 작업은 매우 위험하며 데이터베이스에 즉각적인 압력을 가할 수 있으며 심지어 데이터베이스 충돌을 일으킬 수도 있습니다. 이 문제를 해결하는 방법에는 두 가지가 있습니다. 1. 액세스가 적을 때 용량을 확장하고 확장 후 데이터를 준비합니다. 2. 더 나은 라우팅 알고리즘을 사용합니다. 현재 가장 일반적으로 사용되는 알고리즘은 일관된 해시 알고리즘입니다.
일관적 해시
그림과 같이 Memcached 클라이언트는 일관적 해시 알고리즘을 라우팅 전략으로 사용할 수 있습니다. 알고리즘 제외 키의 해시 값을 계산하는 것 외에도 각 서버에 해당하는 해시 값도 계산한 다음 이러한 해시 값을 제한된 값 범위(예: 0~2^32)에 매핑합니다. 해시(키)보다 큰 해시 값을 갖는 가장 작은 서버를 찾아 키 데이터를 저장하는 대상 서버로 사용합니다. 찾을 수 없는 경우에는 해시 값이 가장 작은 서버를 바로 대상 서버로 사용합니다. 동시에 단일 노드를 추가하거나 삭제해도 전체 클러스터에 큰 영향을 미치지 않습니다. 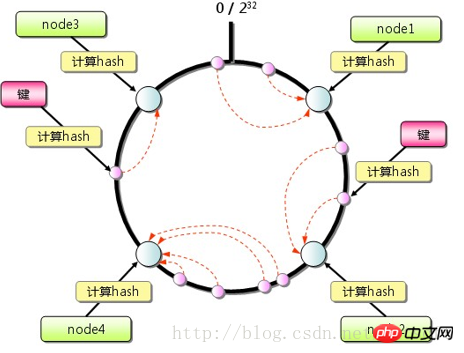 가상 레이어
가상 레이어
일관적 해싱도 완벽하지 않으며 확장 중에 로드 불균형이 발생할 수 있습니다. 최신 버전에서는 가상노드 디자인이 추가되어 활용성을 더욱 향상시켰습니다. 확장 시 클러스터 내 기존 서버에 더 균등하게 영향을 미치고 부하를 균등하게 분산시킵니다. 여기서는 더 자세한 내용을 설명하지 않습니다.
内存管理
存储方式
为了提高性能,memcached中保存的数据都存储在memcached内置的内存存储空间中。由于数据仅存在于内存中,因此重启memcached、重启操作系统会导致全部数据消失。另外,缓存的内容容量达到指定值之后,就基于LRU(Least Recently Used)算法自动删除不使用的缓存。memcached本身是为缓存而设计的服务,因此并没有过多考虑数据的永久性问题。
内存结构
memcached仅支持基础的key-value键值对类型数据存储。在memcached内存结构中有两个非常重要的概念:slab和chunk。
slab是一个内存块,它是memcached一次申请内存的最小单位。在启动memcached的时候一般会使用参数-m指定其可用内存,但是并不是在启动的那一刻所有的内存就全部分配出去了,只有在需要的时候才会去申请,而且每次申请一定是一个slab。Slab的大小固定为1M(1048576 Byte),一个slab由若干个大小相等的chunk组成。每个chunk中都保存了一个item结构体、一对key和value。
虽然在同一个slab中chunk的大小相等的,但是在不同的slab中chunk的大小并不一定相等,在memcached中按照chunk的大小不同,可以把slab分为很多种类(class),默认情况下memcached把slab分为40类(class1~class40),在class 1中,chunk的大小为80字节,由于一个slab的大小是固定的1048576字节(1M),因此在class1中最多可以有13107个chunk(也就是这个slab能存最多13107个小于80字节的key-value数据)。 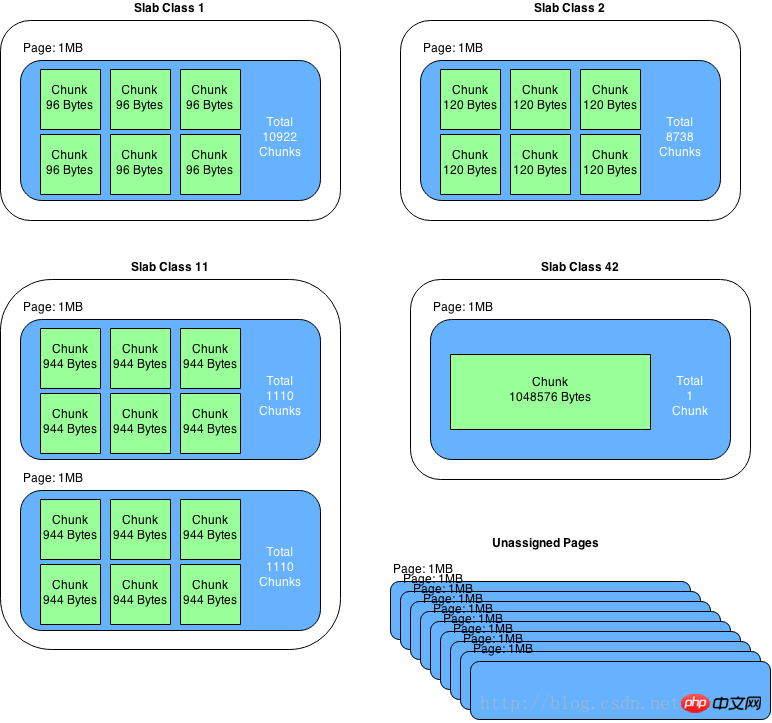
memcached内存管理采取预分配、分组管理的方式,分组管理就是我们上面提到的slab class,按照chunk的大小slab被分为很多种类。内存预分配过程是怎样的呢?向memcached添加一个item时候,memcached首先会根据item的大小,来选择最合适的slab class:例如item的大小为190字节,默认情况下class 4的chunk大小为160字节显然不合适,class 5的chunk大小为200字节,大于190字节,因此该item将放在class 5中(显然这里会有10字节的浪费是不可避免的),计算好所要放入的chunk之后,memcached会去检查该类大小的chunk还有没有空闲的,如果没有,将会申请1M(1个slab)的空间并划分为该种类chunk。例如我们第一次向memcached中放入一个190字节的item时,memcached会产生一个slab class 2(也叫一个page),并会用去一个chunk,剩余5241个chunk供下次有适合大小item时使用,当我们用完这所有的5242个chunk之后,下次再有一个在160~200字节之间的item添加进来时,memcached会再次产生一个class 5的slab(这样就存在了2个pages)。
注意事项
chunk是在page里面划分的,而page固定为1m,所以chunk最大不能超过1m。
chunk实际占用内存要加48B,因为chunk数据结构本身需要占用48B。
如果用户数据大于1m,则memcached会将其切割,放到多个chunk内。
已分配出去的page不能回收。
-对于key-value信息,最好不要超过1m的大小;同时信息长度最好相对是比较均衡稳定的,这样能够保障最大限度的使用内存;同时,memcached采用的LRU清理策略,合理甚至过期时间,提高命中率。
使用场景
key-value能满足需求的前提下,使用memcached分布式集群是较好的选择,搭建与操作使用都比较简单;分布式集群在单点故障时,只影响小部分数据异常,目前还可以通过Magent缓存代理模式,做单点备份,提升高可用;整个缓存都是基于内存的,因此响应时间是很快,不需要额外的序列化、反序列化的程序,但同时由于基于内存,数据没有持久化,集群故障重启数据无法恢复。高版本的memcached已经支持CAS模式的原子操作,可以低成本的解决并发控制问题。
安装启动
$ sudo apt-get install memcached $ memcached -m 32 -p 11211 -d # memcached将会以守护程序的形式启动 memcached(-d),为其分配32M内存(-m 32),并指定监听 localhost的11211端口。
python操作memcached
在python中可通过memcache库来操作memcached,这个库使用很简单,声明一个client就可以读写memcached缓存了。
python访问memcached
#!/usr/bin/env pythonimport memcache
mc = memcache.Client(['127.0.0.1:12000'],debug=0)
mc.set("some_key", "Some value")
value = mc.get("some_key")
mc.set("another_key", 3)
mc.delete("another_key")
mc.set("key", "1") # note that the key used for incr/decr must be a string.
mc.incr("key")
mc.decr("key")然而,python-memcached默认的路由策略没有使用一致性哈希。
def _get_server(self, key):
if isinstance(key, tuple):
serverhash, key = key
else:
serverhash = serverHashFunction(key)
if not self.buckets:
return None, None
for i in range(Client._SERVER_RETRIES):
server = self.buckets[serverhash % len(self.buckets)]
if server.connect():
# print("(using server %s)" % server,)
return server, key
serverhash = serverHashFunction(str(serverhash) + str(i))
return None, None从源码中可以看到:server = self.buckets[serverhash % len(self.buckets)],只是根据key进行了简单的取模。我们可以通过重写_get_server方法,让python-memcached支持一致性哈希。
import memcacheimport typesfrom hash_ring import HashRingclass MemcacheRing(memcache.Client):
"""Extends python-memcache so it uses consistent hashing to
distribute the keys.
"""
def init(self, servers, *k, **kw):
self.hash_ring = HashRing(servers)
memcache.Client.init(self, servers, *k, **kw)
self.server_mapping = {}
for server_uri, server_obj in zip(servers, self.servers):
self.server_mapping[server_uri] = server_obj
def _get_server(self, key):
if type(key) == types.TupleType:
return memcache.Client._get_server(key)
for i in range(self._SERVER_RETRIES):
iterator = self.hash_ring.iterate_nodes(key)
for server_uri in iterator:
server_obj = self.server_mapping[server_uri]
if server_obj.connect():
return server_obj, key
return None, Nonetorando项目中使用memcached
这里采用的策略是:1. 应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。2. 应用程序从cache中取数据,取到后返回。缓存更新是一个很复杂的问题,一般是先把数据存到数据库中,成功后,再让缓存失效。后面会再写文单独讨论memcached缓存更新的问题。
代码
# coding: utf-8import sysimport tornado.ioloopimport tornado.webimport loggingimport memcacheimport jsonimport urllib# 初始化memcache clientmc = memcache.Client(['127.0.0.1:11211'], debug=0)
mc_prefix = 'demo'class BaseHandler(tornado.web.RequestHandler):
""" 把缓存处理抽象到BaseHandler基类 """
USE_CACHE = False # 控制是否使用缓存
def format_args(self):
arg_list = []
for a in self.request.arguments:
for value in self.request.arguments[a]:
arg_list.append('%s=%s' % (a, urllib.quote(value.replace(' ', ''))))
# 根据请求的URL产生key
arg_list.sort()
key = '%s?%s' % (self.request.path, '&'.join(arg_list)) if arg_list else self.request.path
key = '%s_%s' % (mc_prefix, key)
# key太长,不进行缓存处理
if len(key) > 250:
logging.error('key out of length: %s', key)
return None
return key def get(self, *args, **kwargs):
if self.USE_CACHE:
try:
# 根据请求获取key
self.key = self.format_args()
if self.key:
data = mc.get(self.key)
# 若缓存命中,则直接返回数据
if data:
logging.info('get data from memecahce')
self.finish(data)
return
except Exception, e:
logging.exception(e)
# 若未命中缓存,调用do_get处理请求,获取数据
data = self.do_get()
data_str = json.dumps(data)
# 把成功获取到的数据,放入memcache缓存
if self.USE_CACHE and data and data.get('result', -1) == 0 and self.key:
try:
mc.set(self.key, data_str, 60)
except Exception, e:
logging.exception(e)
self.finish(data_str) def do_get(self):
return Noneclass DemoHandler(BaseHandler):
USE_CACHE = True
def do_get(self):
a = self.get_argument('a', 'test')
b = self.get_argument('b', 'test')
# 访问数据库获取数据,此处略去
data = {'result': 0, 'a': a, 'b': b} return datadef make_app():
return tornado.web.Application([
(r"/", DemoHandler),
])if name == "main":
logging.basicConfig(stream=sys.stdout, level=logging.INFO,
format='%(asctime)s %(levelno)s %(message)s',
)
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()测试结果
在浏览器访问http://127.0.0.1:8888/?a=1&b=3,终端打印的log如下:
2017-02-21 22:45:05,987 20 304 GET /?a=1&b=2 (127.0.0.1) 3.11ms 2017-02-21 22:45:07,427 20 get data from memecahce 2017-02-21 22:45:07,427 20 304 GET /?a=1&b=2 (127.0.0.1) 0.71ms 2017-02-21 22:45:10,350 20 200 GET /?a=1&b=3 (127.0.0.1) 0.82ms 2017-02-21 22:45:13,586 20 get data from memecahce
从日志可以看到,缓存命中的情况。
小结
本文介绍了memcached的路由算法、内存管理、使用场景等基本概念,然后举例说明了在python项目中如何使用memcached缓存。缓存更新的问题还需要进一步分析讨论。
위 내용은 Python에서 memcached 동작에 대한 자세한 설명(그림 및 텍스트)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7622
7622
 15
1389
52
89
11
70
19
31
138
15
1389
52
89
11
70
19
31
138

 Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
VS 코드는 Windows 8에서 실행될 수 있지만 경험은 크지 않을 수 있습니다. 먼저 시스템이 최신 패치로 업데이트되었는지 확인한 다음 시스템 아키텍처와 일치하는 VS 코드 설치 패키지를 다운로드하여 프롬프트대로 설치하십시오. 설치 후 일부 확장은 Windows 8과 호환되지 않을 수 있으며 대체 확장을 찾거나 가상 시스템에서 새로운 Windows 시스템을 사용해야합니다. 필요한 연장을 설치하여 제대로 작동하는지 확인하십시오. Windows 8에서는 VS 코드가 가능하지만 더 나은 개발 경험과 보안을 위해 새로운 Windows 시스템으로 업그레이드하는 것이 좋습니다.
 VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VS 코드 확장은 악의적 인 코드 숨기기, 취약성 악용 및 합법적 인 확장으로 자위하는 등 악성 위험을 초래합니다. 악의적 인 확장을 식별하는 방법에는 게시자 확인, 주석 읽기, 코드 확인 및주의해서 설치가 포함됩니다. 보안 조치에는 보안 인식, 좋은 습관, 정기적 인 업데이트 및 바이러스 백신 소프트웨어도 포함됩니다.
 터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
vs 코드에서는 다음 단계를 통해 터미널에서 프로그램을 실행할 수 있습니다. 코드를 준비하고 통합 터미널을 열어 코드 디렉토리가 터미널 작업 디렉토리와 일치하는지 확인하십시오. 프로그래밍 언어 (예 : Python의 Python Your_file_name.py)에 따라 실행 명령을 선택하여 성공적으로 실행되는지 여부를 확인하고 오류를 해결하십시오. 디버거를 사용하여 디버깅 효율을 향상시킵니다.
 PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP는 웹 개발 및 빠른 프로토 타이핑에 적합하며 Python은 데이터 과학 및 기계 학습에 적합합니다. 1.PHP는 간단한 구문과 함께 동적 웹 개발에 사용되며 빠른 개발에 적합합니다. 2. Python은 간결한 구문을 가지고 있으며 여러 분야에 적합하며 강력한 라이브러리 생태계가 있습니다.
 PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP는 주로 절차 적 프로그래밍이지만 객체 지향 프로그래밍 (OOP)도 지원합니다. Python은 OOP, 기능 및 절차 프로그래밍을 포함한 다양한 패러다임을 지원합니다. PHP는 웹 개발에 적합하며 Python은 데이터 분석 및 기계 학습과 같은 다양한 응용 프로그램에 적합합니다.
 Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
VS 코드는 파이썬을 작성하는 데 사용될 수 있으며 파이썬 애플리케이션을 개발하기에 이상적인 도구가되는 많은 기능을 제공합니다. 사용자는 다음을 수행 할 수 있습니다. Python 확장 기능을 설치하여 코드 완료, 구문 강조 및 디버깅과 같은 기능을 얻습니다. 디버거를 사용하여 코드를 단계별로 추적하고 오류를 찾아 수정하십시오. 버전 제어를 위해 git을 통합합니다. 코드 서식 도구를 사용하여 코드 일관성을 유지하십시오. 라인 도구를 사용하여 잠재적 인 문제를 미리 발견하십시오.
 vScode를 Mac에 사용할 수 있습니다
Apr 15, 2025 pm 07:36 PM
vScode를 Mac에 사용할 수 있습니다
Apr 15, 2025 pm 07:36 PM
VS 코드는 Mac에서 사용할 수 있습니다. 강력한 확장, GIT 통합, 터미널 및 디버거가 있으며 풍부한 설정 옵션도 제공합니다. 그러나 특히 대규모 프로젝트 또는 고도로 전문적인 개발의 경우 VS 코드는 성능 또는 기능 제한을 가질 수 있습니다.
 vscode가 ipynb를 실행할 수 있습니다
Apr 15, 2025 pm 07:30 PM
vscode가 ipynb를 실행할 수 있습니다
Apr 15, 2025 pm 07:30 PM
Code vs Code에서 Jupyter 노트북을 실행하는 핵심은 Python 환경이 올바르게 구성되어 있는지 확인하고 코드 실행 순서가 셀 순서와 일치하고 성능에 영향을 줄 수있는 큰 파일 또는 외부 라이브러리를 알고 있어야합니다. VS 코드에서 제공하는 코드 완료 및 디버깅 기능은 코딩 효율성을 크게 향상시키고 오류를 줄일 수 있습니다.
