
이 글은 주로 Power Node Java Academy에서 만든 HashMap_Compiled의 작동 원리를 소개합니다. 필요한 친구들이 참고할 수 있습니다
사실 HashSet과 HashMap 사이에는 유사한 점이 많습니다. HashMap에 대해 설정된 요소를 신속하게 저장하고 검색할 수 있도록 보장하는 집합 요소의 저장 위치를 결정하는 해시 알고리즘, 시스템 키-값은 전체적으로 처리되며 시스템은 항상 키-값 저장을 기반으로 계산합니다. 이는 맵의 키-값 쌍을 빠르게 저장하고 검색할 수 있도록 보장합니다.
컬렉션 저장소를 도입하기 전에 한 가지 짚고 넘어가야 할 점은 컬렉션이 Java 객체를 저장한다고 주장하지만 실제로는 Set 컬렉션에 Java 객체를 넣지 않는다는 것입니다. Set 컬렉션에 있는 이러한 개체에 대한 참조. 즉, Java 컬렉션은 실제로 실제 Java 개체를 가리키는 여러 참조 변수 의 컬렉션입니다. 참조 유형 array와 마찬가지로 Java 객체를 배열에 넣는 것은 실제로 Java 객체를 배열에 넣는 것이 아니라 객체의 참조를 배열에 각각 넣는 것입니다. 요소는 참조 변수입니다.
HashMap 저장(put() 메소드) 구현
프로그램이 HashMap에 여러 키-값을 넣으려고 할 때, 다음 코드 조각을 예로 들어 보겠습니다.
HashMap<String , Double> map = new HashMap<String , Double>();
map.put("语文" , 80.0);
map.put("数学" , 89.0);
map.put("英语" , 78.2);HashMap은 소위 "해시 알고리즘"을 사용하여 각 요소의 저장 위치를 결정합니다.
프로그램이 map.put("중국어",80.0)을 실행하면 시스템은 "중국어"(예: 키)의 hashCode() 메서드를 호출하여 해당 hashCode 값을 가져옵니다.---각 Java 개체에는 hashCode() 메소드를 사용하면 이 메소드를 통해 hashCode 값을 얻을 수 있습니다. 이 객체의 hashCode 값을 얻은 후 시스템은 hashCode 값을 기반으로 요소의 저장 위치를 결정합니다.
HashMap 클래스의 put(K 키, V 값) 메소드의 소스 코드를 볼 수 있습니다.
public V put(K key, V value)
{
// 如果 key 为 null,调用 putForNullKey 方法进行处理
if (key == null)
return putForNullKey(value);
// 根据 key 的 keyCode 计算 Hash 值
int hash = hash(key.hashCode());
// 搜索指定 hash 值在对应 table 中的索引
int i = indexFor(hash, table.length);
// 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素
for (Entry<K,V> e = table[i]; e != null; e = e.next)
{
Object k;
// 找到指定 key 与需要放入的 key 相等(hash 值相同
// 通过 equals 比较放回 true)
if (e.hash == hash && ((k = e.key) == key
|| key.equals(k)))
{
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果 i 索引处的 Entry 为 null,表明此处还没有 Entry
modCount++;
// 将 key、value 添加到 i 索引处
addEntry(hash, key, value, i);
return null;
}static int hash(int h)
{
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}static int indexFor(int h, int length)
{
return h & (length-1);
}当向 HashMap 中添加 key-value 对,由其 key 的 hashCode() 返回值决定该 key-value 对(就是 Entry 对象)的存储位置。当两个 Entry 对象的 key 的 hashCode() 返回值相同时,将由 key 通过 eqauls() 比较值决定是采用覆盖行为(返回 true),还是产生 Entry 链(返回 false)。
上面程序中还调用了 addEntry(hash, key, value, i); 代码,其中 addEntry 是 HashMap 提供的一个包访问权限的方法,该方法仅用于添加一个 key-value 对。下面是该方法的代码:
void addEntry(int hash, K key, V value, int bucketIndex)
{
// 获取指定 bucketIndex 索引处的 Entry
Entry<K,V> e = table[bucketIndex]; // ①
// 将新创建的 Entry 放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entry
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
// 如果 Map 中的 key-value 对的数量超过了极限
if (size++ >= threshold)
// 把 table 对象的长度扩充到 2 倍。
resize(2 * table.length); // ②
}上面方法的代码很简单,但其中包含了一个非常优雅的设计:系统总是将新添加的 Entry 对象放入 table 数组的 bucketIndex 索引处——如果 bucketIndex 索引处已经有了一个 Entry 对象,那新添加的 Entry 对象指向原有的 Entry 对象(产生一个 Entry 链),如果 bucketIndex 索引处没有 Entry 对象,也就是上面程序①号代码的 e 变量是 null,也就是新放入的 Entry 对象指向 null,也就是没有产生 Entry 链。
什么是Map.Entry?
Map是java中的接口,Map.Entry是Map的一个内部接口。
Map提供了一些常用方法,如keySet()、entrySet()等方法,keySet()方法返回值是Map中key值的集合;entrySet()的返回值也是返回一个Set集合,此集合的类型为Map.Entry。
Map.Entry是Map声明的一个内部接口,此接口为泛型,定义为Entry
由以上可以得出,遍历Map的常用方法:
1. Map map = new HashMap();
Irerator iterator = map.entrySet().iterator();
while(iterator.hasNext()) {
Map.Entry entry = iterator.next();
Object key = entry.getKey();
//
}
2.Map map = new HashMap();
Set keySet= map.keySet();
Irerator iterator = keySet.iterator;
while(iterator.hasNext()) {
Object key = iterator.next();
Object value = map.get(key);
//
}另外,还有一种遍历方法是,单纯的遍历value值,Map有一个values方法,返回的是value的Collection集合。通过遍历collection也可以遍历value,如
Map map = new HashMap();
Collection c = map.values();
Iterator iterator = c.iterator();
while(iterator.hasNext()) {
Object value = iterator.next();
}Map.Entry是Map内部定义的一个接口,专门用来保存key→value的内容。Map.Entry的定义如下:
1. public static interface Map.Entry
Map.Entry是使用static关键字声明的内部接口,此接口可以由外部通过"外部类.内部类"的形式直接调用。
Map.Entry接口的常用方法
序号 | 方法 | 类型 | 描述 |
1 | public boolean equals(Object o) | 보통 | |
2 | public K getKey() | 일반 | 키 가져오기 |
3 | 공개 V getValue() | 보통 | 가치 얻기 |
4 | public int hashCode() | 보통 | 반환 하 히마 |
5 | 공용 V setValue(V value ) | 普通 | 设置value的值 |
从之前的内容可以知道,在Map的操作中,所有的内容都是通过key→value的形式保存数据的,那么对于集合来讲,实际上是将key→value的数据保存在了Map.Entry的实例之后,再在Map集合中插入的是一个Map.Entry的实例化对象,如下图所示。
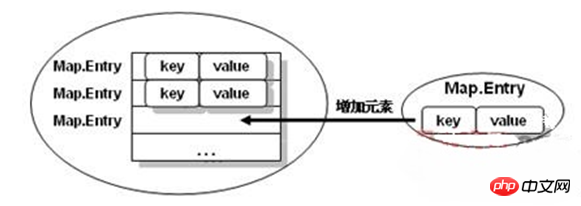
提示:Map.Entry在集合输出时会使用到。
在一般的Map操作中(例如,增加或取出数据等操作)不用去管Map.Entry接口,但是在将Map中的数据全部输出时就必须使用Map.Entry接口
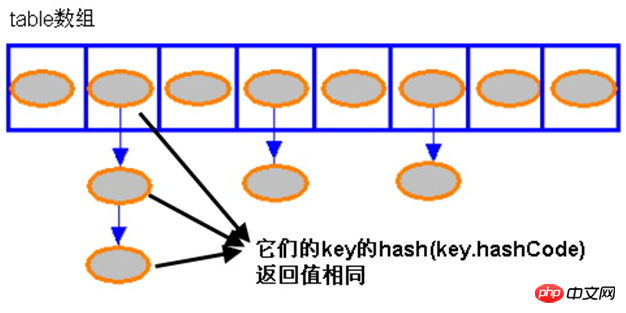
HashMap 的存储示意
HashMap 的读取实现()
当 HashMap 的每个 bucket 里存储的 Entry 只是单个 Entry ——也就是没有通过指针产生 Entry 链时,此时的 HashMap 具有最好的性能:当程序通过 key 取出对应 value 时,系统只要先计算出该 key 的 hashCode() 返回值,在根据该 hashCode 返回值找出该 key 在 table 数组中的索引,然后取出该索引处的 Entry,最后返回该 key 对应的 value 即可。看 HashMap 类的 get(K key) 方法代码:
public V get(Object key)
{
// 如果 key 是 null,调用 getForNullKey 取出对应的 value
if (key == null)
return getForNullKey();
// 根据该 key 的 hashCode 值计算它的 hash 码
int hash = hash(key.hashCode());
// 直接取出 table 数组中指定索引处的值,
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
// 搜索该 Entry 链的下一个 Entr
e = e.next) // ①
{
Object k;
// 如果该 Entry 的 key 与被搜索 key 相同
if (e.hash == hash && ((k = e.key) == key
|| key.equals(k)))
return e.value;
}
return null;
}从上面代码中可以看出,如果 HashMap 的每个 bucket 里只有一个 Entry 时,HashMap 可以根据索引、快速地取出该 bucket 里的 Entry;在发生“Hash 冲突”的情况下,单个 bucket 里存储的不是一个 Entry,而是一个 Entry 链,系统只能必须按顺序遍历每个 Entry,直到找到想搜索的 Entry 为止——如果恰好要搜索的 Entry 位于该 Entry 链的最末端(该 Entry 是最早放入该 bucket 中),那系统必须循环到最后才能找到该元素。
归纳起来简单地说,HashMap 在底层将 key-value 当成一个整体进行处理,这个整体就是一个 Entry 对象。HashMap 底层采用
一个 Entry[] 数组来保存所有的 key-value 对,当需要存储一个 Entry 对象时,会根据 Hash 算法来决定其存储位置;当需要取出一个 Entry 时,也会根据 Hash 算法找到其存储位置,直接取出该 Entry。由此可见:HashMap 之所以能快速存、取它所包含的 Entry,完全类似于现实生活中母亲从小教我们的:不同的东西要放在不同的位置,需要时才能快速找到它。
当创建 HashMap 时,有一个默认的负载因子(load factor),其默认值为 0.75,这是时间和空间成本上一种折衷:增大负载因子可以减少 Hash 表(就是那个 Entry 数组)所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的的操作(HashMap 的 get() 与 put() 方法都要用到查询);减小负载因子会提高数据查询的性能,但会增加 Hash 表所占用的内存空间。
掌握了上面知识之后,我们可以在创建 HashMap 时根据实际需要适当地调整 load factor 的值;如果程序比较关心空间开销、内存比较紧张,可以适当地增加负载因子;如果程序比较关心时间开销,内存比较宽裕则可以适当的减少负载因子。通常情况下,程序员无需改变负载因子的值。
如果开始就知道 HashMap 会保存多个 key-value 对,可以在创建时就使用较大的初始化容量,如果 HashMap 中 Entry 的数量一直不会超过极限容量(capacity * load factor),HashMap 就无需调用 resize() 方法重新分配 table 数组,从而保证较好的性能。当然,开始就将初始容量设置太高可能会浪费空间(系统需要创建一个长度为 capacity 的 Entry 数组),因此创建 HashMap 时初始化容量设置也需要小心对待。
【相关推荐】
1. Java免费视频教程
2. Java教程手册
3. 极客学院Java视频教程
위 내용은 Java 컬렉션 저장을 위한 HashMap 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



