
인터넷에 있는 대부분의 Python 튜토리얼은 2.X 버전입니다. python3.X와 비교하면 python2.X는 많은 라이브러리가 다르게 설치되어 있습니다. .예
0x01
봄 축제 기간 동안 할 일이 없어서(얼마나 한가한지) 농담을 하고 프로그램 작성 과정을 기록하기 위해 간단한 프로그램을 작성했습니다. 제가 크롤러들과 처음 접한 건 이런 글을 봤을 때였습니다. 오믈렛에서 여자들이 크롤링하는 사진에 대한 재미있는 글이었죠. 그래서 고양이와 호랑이를 직접 흉내내기 시작했고 사진도 몇장 담아봤습니다.
기술은 미래에 영감을 줍니다. 프로그래머로서 어떻게 그런 일을 할 수 있습니까? 신체적, 정신적 건강에 더 좋은 농담을 만드는 것이 더 낫습니다.

0x02
팔을 걷어붙이고 시작하기 전에 몇 가지 이론적 지식을 대중화해 보겠습니다.
간단히 말하면 웹페이지의 특정 위치에 콘텐츠를 끌어내려야 합니다. 어떻게 끌어내려야 할까요? 먼저 웹페이지를 분석하여 어떤 콘텐츠가 있는지 확인해야 합니다. 필요. 예를 들어, 이번에는 재미있는 웹사이트에서 농담을 크롤링했는데, 재미있는 웹사이트에서 농담 페이지를 열면 우리의 목적은 이러한 콘텐츠를 얻는 것입니다. 읽고 나서 진정하세요. 계속 이렇게 웃으면 우리는 코드를 작성할 수 없습니다. chrome에서 Inspect Element를 연 다음 HTML 태그를 레벨별로 확장하거나 작은 마우스를 클릭하여 필요한 요소를 찾습니다.
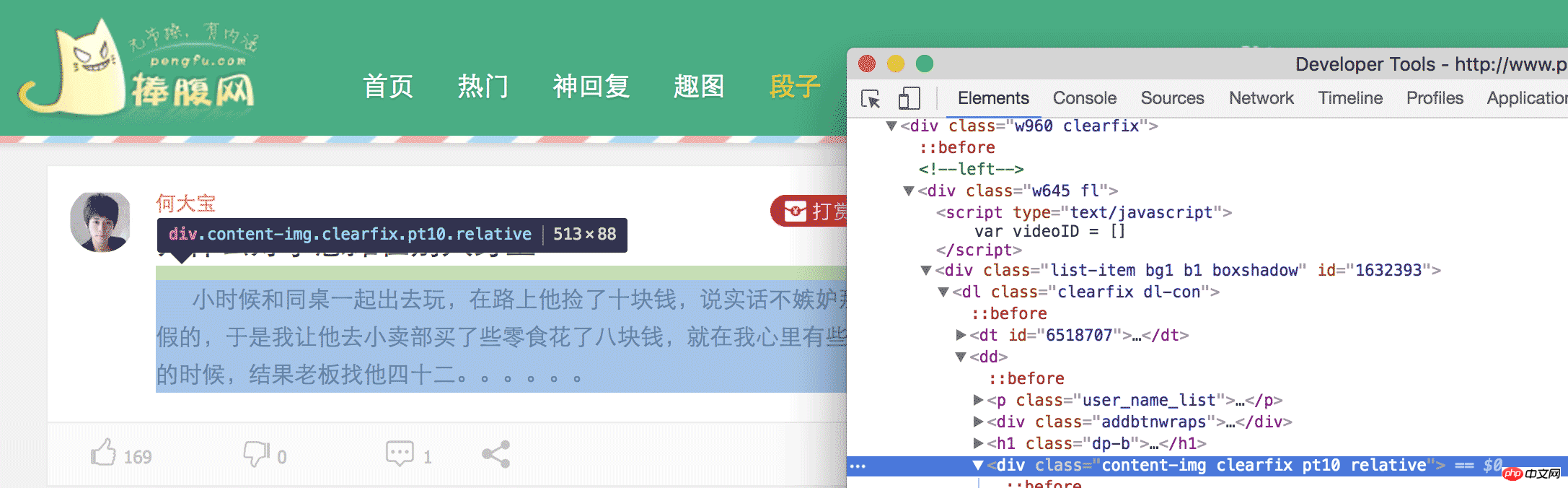
마지막으로
의 내용이 우리에게 필요한 농담임을 알 수 있습니다. . 따라서 이 웹페이지에서 모든
를 찾은 다음 내부 콘텐츠를 추출하면 작업이 완료됩니다.
0x03
자, 이제 목적을 알았으니 이제 본격적으로 시작하겠습니다. 여기서는 python3을 사용합니다. python2와 python3의 선택은 누구나 스스로 결정할 수 있지만 몇 가지 차이점이 있습니다. 그러나 여전히 python3을 사용하는 것이 좋습니다.
필요한 콘텐츠를 내려야 합니다. 먼저 이 웹페이지를 내려야 합니다. 여기서는 urllib라는 라이브러리를 사용하여 가져옵니다. 전체 웹페이지.
먼저 urllib를 가져옵니다
코드는 다음과 같습니다.
import urllib.request as request
그런 다음 request를 사용하여 웹페이지를 가져올 수 있습니다.
코드
return request.urlopen(url).read()
인생은 짧다, 나는 파이썬을 사용하고, 코드 한 줄, 웹 페이지를 다운로드하고, 파이썬을 사용하지 않을 이유가 없다고 하셨는데요.
웹페이지를 다운로드한 후 웹페이지를 구문 분석하여 필요한 요소를 가져와야 합니다. 요소를 구문 분석하려면 Beautiful Soup이라는 또 다른 도구를 사용해야 합니다. 이 도구를 사용하면 HTML과 XML을 빠르게 구문 분석하고 필요한 요소를 얻을 수 있습니다.
코드는 다음과 같습니다.
soup = BeautifulSoup(getHTML("http://www.pengfu.com/xiaohua_1.html"))BeautifulSoup을 사용하여 웹 페이지를 구문 분석하는 것은 한 문장에 불과하지만 코드를 실행하면 이러한 경고가 나타나서 다음을 수행하라는 메시지가 나타납니다. 파서를 지정하지 않으면 다른 플랫폼이나 시스템에서 오류가 보고될 수 있습니다.
코드는 다음과 같습니다.
/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/bs4/init.py:181: UserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("lxml"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
The code that caused this warning is on line 64 of the file joke.py. To get rid of this warning, change code that looks like this:
BeautifulSoup([your markup])
to this:
BeautifulSoup([your markup], "lxml")
markup_type=markup_type))파서의 종류와 파서 간의 차이점은 공식 문서에 자세히 설명되어 있으므로 현재는 lxml 파싱을 사용하는 것이 더 안정적입니다.
수정 후
코드는 다음과 같습니다.
soup = BeautifulSoup(getHTML("http://www.pengfu.com/xiaohua_1.html", 'lxml'))이렇게 하면 위의 경고가 발생하지 않습니다.
코드는 다음과 같습니다.
p_array = soup.find_all('p', {'class':"content-img clearfix pt10 relative"})find_all 함수를 사용하여 클래스 = content-imgclearfix pt10 상대인 모든 p 태그를 찾은 다음 이를 순회합니다 array
코드는 다음과 같습니다.
for x in p_array: content = x.string
이런 방식으로 대상 p의 내용을 가져옵니다. 이 시점에서 우리는 목표를 달성했고 농담에 이르렀습니다.
그러나 같은 방식으로 크롤링을 하면 이런 오류가 보고됩니다
코드는 다음과 같습니다
raise RemoteDisconnected("Remote end closed connection without" http.client.RemoteDisconnected: Remote end closed connection without response说远端无响应,关闭了链接,看了下网络也没有问题,这是什么情况导致的呢?莫非是我姿势不对?
打开 charles 抓包,果然也没反应。唉,这就奇怪了,好好的一个网站,怎么浏览器可以访问,python 无法访问呢,是不是 UA 的问题呢?看了下 charles,发现,利用 urllib 发起的请求,UA 默认是 Python-urllib/3.5 而在 chrome 中访问 UA 则是 User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36,那会不会是因为服务器根据 UA 来判断拒绝了 python 爬虫。我们来伪装下试试看行不行
代码如下:
def getHTML(url):
head
ers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
req = request.Request(url, headers=headers)
return request.urlopen(req).read()这样就把 python 伪装成 chrome 去获取糗百的网页,可以顺利的得到数据。
至此,利用 python 爬取糗百和捧腹网的笑话已经结束,我们只需要分析相应的网页,找到我们感兴趣的元素,利用 python 强大的功能,就可以达到我们的目的,不管是 XXOO 的图,还是内涵段子,都可以一键搞定,不说了,我去找点妹子图看看。
# -*- coding: utf-8 -*-
import sys
import urllib.request as request
from bs4 import BeautifulSoup
def getHTML(url):
headers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
req = request.Request(url, headers=headers)
return request.urlopen(req).read()
def get_pengfu_results(url):
soup = BeautifulSoup(getHTML(url), 'lxml')
return soup.find_all('p', {'class':"content-img clearfix pt10 relative"})
def get_pengfu_joke():
for x in range(1, 2):
url = 'http://www.pengfu.com/xiaohua_%d.html' % x
for x in get_pengfu_results(url):
content = x.string
try:
string = content.lstrip()
print(string + '\n\n')
except:
continue
return
def get_qiubai_results(url):
soup = BeautifulSoup(getHTML(url), 'lxml')
contents = soup.find_all('p', {'class':'content'})
restlus = []
for x in contents:
str = x.find('span').getText('\n','<br/>')
restlus.append(str)
return restlus
def get_qiubai_joke():
for x in range(1, 2):
url = 'http://www.qiushibaike.com/8hr/page/%d/?s=4952526' % x
for x in get_qiubai_results(url):
print(x + '\n\n')
return
if name == 'main':
get_pengfu_joke()
get_qiubai_joke()【相关推荐】
1. Python免费视频教程
3. Python基础入门手册
위 내용은 네트워크 단락 페이지 크롤러 사례의 Python 구현의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



