
크롤링 과정에서 일부 페이지는 로그인 전 크롤링이 금지됩니다. 이때 로그인을 시뮬레이션해야 합니다. 다음 글에서는 주로 Pythoncrawler를 사용하여 Zhihu 로그인을 시뮬레이션하는 방법을 소개합니다. 방법 튜토리얼은 기사에 매우 자세히 설명되어 있습니다. 필요한 친구들은 함께 참고할 수 있습니다.
Preface
크롤러를 자주 작성하는 모든 사람은 Zhihu의 주제 페이지와 같이 로그인하기 전에 일부 페이지가 크롤링이 금지되어 있다는 것을 알고 있습니다. 액세스하려면 로그인해야 하며 "로그인"은 HTTP의 Cookie 기술과 분리될 수 없습니다.
로그인 원칙
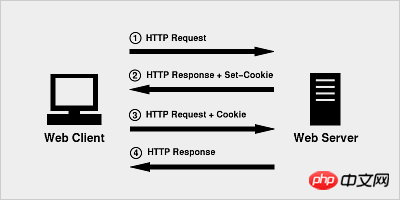
쿠키의 원리는 매우 간단합니다. HTTP는 Stateless 프로토콜이기 때문에 Stateless HTTP 프로토콜을 사용하려면 session 상태는 서버가 현재 어떤 클라이언트를 다루고 있는지 알려주기 위해 유지됩니다. 쿠키는 서버가 클라이언트에게 할당하는 식별자와 같습니다.
 @
@
브라우저가 처음으로 HTTP 요청을 시작할 때 쿠키 정보를 전달하지 않습니다
서버의 HTTP 응답과 브라우저로 반환되는 쿠키 정보도 있습니다
브라우저는 서버가 반환한 쿠키 정보를 다음과 함께 서버로 보냅니다. 두 번째 request
서버는 HTTP 요청을 수신하고 요청 헤더에 쿠키 필드가 있음을 발견하므로 이전에 이 사용자를 처리했음을 알 수 있습니다.
실용적 적용
@Zhihu를 사용해 본 모든 사람은 사용자 이름만 제공하면 알 수 있습니다. 비밀번호 및 인증번호를 입력하신 후 로그인이 가능합니다. 물론 이것은 우리가 보는 것뿐입니다. 그 뒤에 숨겨진 기술적인 세부 사항은 브라우저의 도움으로 발견되어야 합니다. 이제 Chrome를 사용하여 양식을 작성한 후 어떤 일이 일어나는지 살펴보겠습니다.
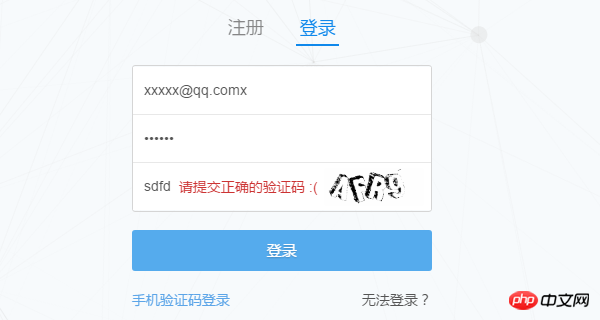
(이미 로그인한 경우 먼저 로그아웃하세요.) 먼저 Zhihu 로그인 페이지 www.zhihu.com/#signin에 들어가서 Chrome 개발자 툴바를 엽니다(F12 누르기) ) 먼저 잘못된 인증 코드를 입력하고 브라우저가 요청을 어떻게 보내는지 관찰해 보세요.
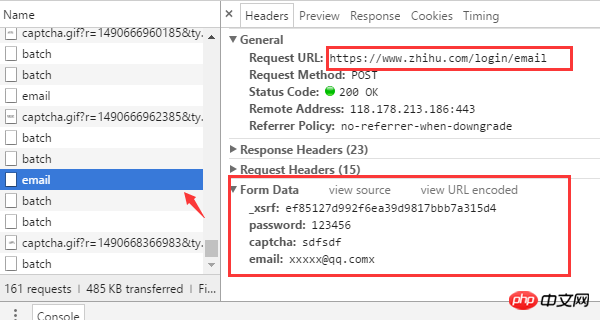
브라우저에서 몇 가지 주요 정보를 확인할 수 있습니다. request
로그인 URL 주소는 https://www입니다. com/login/email
로그인을 위해 제공해야 하는 양식 데이터는 사용자 이름(이메일), 비밀번호(password), 확인 코드(captcha), _xsrf의 4가지입니다.
인증 코드를 받을 수 있는 URL 주소는 https://www.zhihu.com/captcha.gif?r=1490690391695&type=login
 입니다.
입니다.
pip install beautifulsoup4==4.5.3
pip install requests==2.13.0
세션 객체는 쿠키 지속성과 연결 풀링 기능을 제공합니다. 세션 객체를 통해 요청을 보낼 수 있습니다.
에 대한 쿠키가 없기 때문에 먼저 cookie.txt 파일에서 쿠키 정보를 로드합니다. 처음 실행하면 LoadError 예외가 발생합니다.
from http import cookiejar
session = requests.session()
session.cookies = cookiejar.LWPCookieJar(filename='cookies.txt')
try:
session.cookies.load(ignore_discard=True)
except LoadError:
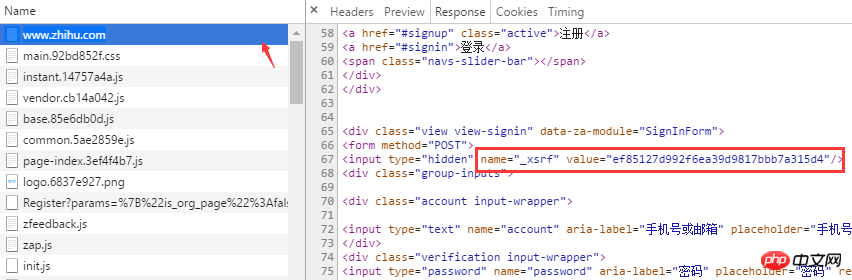
print("load cookies failed")Get xsrf@xsrf가 위치한 태그를 이미 찾았으며 BeatifulSoup의 find 메소드를 사용하여 가져올 수 있습니다. 매우 편리하게 값을 입력하세요
def get_xsrf():
response = session.get("https://www.zhihu.com", headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
xsrf = soup.find('input', attrs={"name": "_xsrf"}).get("value")
return xsrf인증 코드 받기@인증 코드는 /captcha를 통해 반환됩니다. .gif 인터페이스, 여기서는 수동 식별을 위해 확인 코드 이미지를 다운로드하여 현재 디렉터리에 저장합니다. 물론 pytesser와 같은 타사 지원 라이브러리를 사용하여 자동으로 식별할 수도 있습니다.
def get_captcha():
"""
把验证码图片保存到当前目录,手动识别验证码
:return:
"""
t = str(int(time.time() * 1000))
captcha_url = 'https://www.zhihu.com/captcha.gif?r=' + t + "&type=login"
r = session.get(captcha_url, headers=headers)
with open('captcha.jpg', 'wb') as f:
f.write(r.content)
captcha = input("验证码:")
return captcha로그인@ 一切参数准备就绪之后,就可以请求登录接口了。 请求成功后,session 会自动把 服务端的返回的cookie 信息填充到 session.cookies 对象中,下次请求时,客户端就可以自动携带这些cookie去访问那些需要登录的页面了。 auto_login.py 示例代码 【相关推荐】 1. python爬虫入门(4)--详解HTML文本的解析库BeautifulSoup 2. python爬虫入门(3)--利用requests构建知乎APIdef login(email, password):
login_url = 'www.zhihu.com/login/email'
data = {
'email': email,
'password': password,
'_xsrf': get_xsrf(),
"captcha": get_captcha(),
'remember_me': 'true'}
response = session.post(login_url, data=data, headers=headers)
login_code = response.json()
print(login_code['msg'])
for i in session.cookies:
print(i)
session.cookies.save()# encoding: utf-8
# !/usr/bin/env python
"""
作者:liuzhijun
"""
import time
from http import cookiejar
import requests
from bs4 import BeautifulSoup
headers = {
"Host": "www.zhihu.com",
"Referer": "www.zhihu.com/",
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87'
}
# 使用登录cookie信息
session = requests.session()
session.cookies = cookiejar.LWPCookieJar(filename='cookies.txt')
try:
print(session.cookies)
session.cookies.load(ignore_discard=True)
except:
print("还没有cookie信息")
def get_xsrf():
response = session.get("www.zhihu.com", headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
xsrf = soup.find('input', attrs={"name": "_xsrf"}).get("value")
return xsrf
def get_captcha():
"""
把验证码图片保存到当前目录,手动识别验证码
:return:
"""
t = str(int(time.time() * 1000))
captcha_url = 'www.zhihu.com/captcha.gif?r=' + t + "&type=login"
r = session.get(captcha_url, headers=headers)
with open('captcha.jpg', 'wb') as f:
f.write(r.content)
captcha = input("验证码:")
return captcha
def login(email, password):
login_url = 'www.zhihu.com/login/email'
data = {
'email': email,
'password': password,
'_xsrf': get_xsrf(),
"captcha": get_captcha(),
'remember_me': 'true'}
response = session.post(login_url, data=data, headers=headers)
login_code = response.json()
print(login_code['msg'])
for i in session.cookies:
print(i)
session.cookies.save()
if name == 'main':
email = "xxxx"
password = "xxxxx"
login(email, password)
위 내용은 Python 크롤러를 사용하여 Zhihu 로그인을 시뮬레이션하는 예 공유의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



