

Node.js를 사용하여 텍스트 콘텐츠를 분할하고 키워드를 추출하는 방법에 대한 자세한 설명

이 글에서는 주로 텍스트 콘텐츠 분할 및 키워드 추출을 위한 Node.js의 사용을 소개합니다. 필요한 친구들은 참고해도 됩니다.
기술을 논의하기 전에, 여러분은 의 세계를 이해하지 못합니다. foodies~~
Zhongcheng이 번역한 기사에는 태그가 있습니다. 사용자는 태그를 기반으로 관심 있는 기사를 빠르게 필터링할 수 있으며 태그 연관을 기반으로 추천할 수도 있습니다. 하지만 이제 Zhongcheng Translation의 태그는 기사 추천시 설정되고 모두 영어로되어 있으며 수동 설정은 필연적으로 표준화되지 않고 완전하지 않습니다. 기사를 게시한 후 수동으로 편집할 수 있지만 사용자나 관리자가 항상 적절한 태그를 편집할 것이라고 기대할 수는 없으므로 태그를 자동으로 생성하는 도구를 사용해야 합니다.
현재 오픈 소스 단어 분할 도구 중 jieba는 강력한 기능과 뛰어난 성능을 갖춘 단어 분할 구성 요소입니다. 다행히 노드 버전이 있습니다. ㅋㅋㅋ 9999n
9999로 딱이네요var nodejieba = require("nodejieba");
nodejieba.load({
userDict: './user.utf8',
});
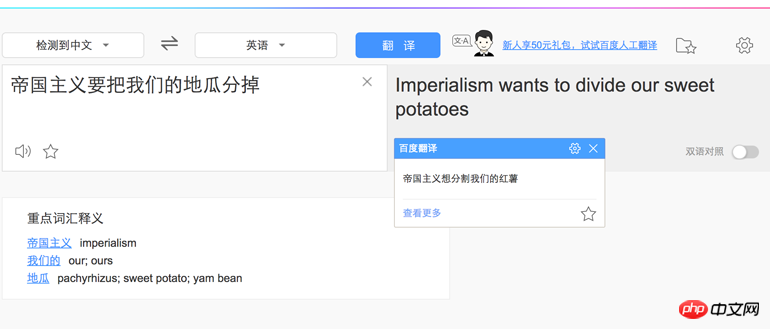
var result = nodejieba.cut("帝国主义要把我们的地瓜分掉");
console.log(result);
//[ '帝国主义', '要', '把', '我们', '的', '地瓜', '分', '掉' ]
result = nodejieba.cut('土地,俺老孙的金箍棒在哪里?');
console.log(result);
//[ '土地', ',', '俺', '老', '孙', '的', '金箍棒', '在', '哪里', '?' ]
result = nodejieba.cut('大圣,您的金箍棒就棒在特别配您的头型!');
console.log(result);
//[ '大圣', ',', '您', '的', '金箍', '棒就棒在', '特别', '配', '您', '的', '头型', '!' ]HTTP, HTTP/2 및
성능 최적화
이 기사의 목적은 HTTP에서 HTTP로 마이그레이션해야 하는 이유를 비교를 통해 알려주는 것입니다. HTTPS, 그리고 HTTP/2에 대한 지원을 추가해야 하는 이유. HTTP와 HTTP/2를 비교하기 전에 먼저 HTTP가 무엇인지 살펴보겠습니다.
HTTP란 무엇인가요
HTTP는 World Wide Web에서의 통신 규칙 집합입니다. HTTP는
TCP/IP계층 위에서 실행되는 애플리케이션 계층 프로토콜입니다. 사용자가 브라우저를 통해 웹 페이지를 요청하면 HTTP는 요청을 처리하고 웹 서버와 클라이언트 간의 연결을 설정합니다.
HTTP/2를 사용하면 스프라이트 이미지, 압축 또는 접합을 사용하지 않고도 성능을 향상시킬 수 있습니다. 그러나 이것이 이러한 기술을 사용해서는 안된다는 의미는 아닙니다. 그러나 이는 HTTP/1.1에서 HTTP/2로 전환해야 할 필요성을 분명히 보여주었습니다. `;const content = `
const nodejieba = require("nodejieba");
const result = nodejieba.extract(content, 20);
console.log(result);PerformanceHTTP/2
출력 결과는 다음과 같습니다.
[ { word: 'HTTP', weight: 140.8704516850025 },
{ word: '请求', weight: 14.23018001394 },
{ word: '应该', weight: 14.052171126120001 },
{ word: '万维网', weight: 12.2912397395 },
{ word: 'TCP', weight: 11.739204307083542 },
{ word: '1.1', weight: 11.739204307083542 },
{ word: 'Web', weight: 11.739204307083542 },
{ word: '雪碧图', weight: 11.739204307083542 },
{ word: 'HTTPS', weight: 11.739204307083542 },
{ word: 'IP', weight: 11.739204307083542 },
{ word: '应用层', weight: 11.2616203224 },
{ word: '客户端', weight: 11.1926274509 },
{ word: '浏览器', weight: 10.8561552143 },
{ word: '拼接', weight: 9.85762638414 },
{ word: '比较', weight: 9.5435285574 },
{ word: '网页', weight: 9.53122979951 },
{ word: '服务器', weight: 9.41204128224 },
{ word: '使用', weight: 9.03259988558 },
{ word: '必要性', weight: 8.81927328699 },
{ word: '添加', weight: 8.0484751722 } ][ { word: 'HTTP', weight: 105.65283876375187 },
{ word: 'HTTP/2', weight: 58.69602153541771 },
{ word: '请求', weight: 14.23018001394 },
{ word: '应该', weight: 14.052171126120001 },
{ word: '性能', weight: 12.61259281884 },
{ word: '万维网', weight: 12.2912397395 },
{ word: 'IP', weight: 11.739204307083542 },
{ word: 'HTTPS', weight: 11.739204307083542 },
{ word: '1.1', weight: 11.739204307083542 },
{ word: 'TCP', weight: 11.739204307083542 },
{ word: 'Web', weight: 11.739204307083542 },
{ word: '雪碧图', weight: 11.739204307083542 },
{ word: '应用层', weight: 11.2616203224 },
{ word: '客户端', weight: 11.1926274509 },
{ word: '浏览器', weight: 10.8561552143 },
{ word: '拼接', weight: 9.85762638414 },
{ word: '比较', weight: 9.5435285574 },
{ word: '网页', weight: 9.53122979951 },
{ word: '服务器', weight: 9.41204128224 },
{ word: '使用', weight: 9.03259988558 } ]이 문서의 목적은 HTTP에서 마이그레이션해야 하는 이유를 비교를 통해 설명하는 것입니다. HTTPS에, 그리고 HTTP/2에 대한 지원을 추가해야 하는 이유. HTTP와 HTTP/2를 비교하기 전에 먼저 HTTP가 무엇인지 살펴보겠습니다.
HTTP란 무엇인가요HTTP는 World Wide Web에서의 통신 규칙 집합입니다. HTTP는 TCP/IP 계층 위에서 실행되는 애플리케이션 계층 프로토콜입니다. 사용자가 브라우저를 통해 웹 페이지를 요청하면 HTTP는 요청을 처리하고 웹 서버와 클라이언트 간의 연결을 설정합니다.
HTTP/2를 사용하면 스프라이트 이미지, 압축 또는 접합을 사용하지 않고도 성능을 향상시킬 수 있습니다. 그러나 이것이 이러한 기술을 사용해서는 안된다는 의미는 아닙니다. 그러나 이는 HTTP/1.1에서 HTTP/2로 전환해야 할 필요성을 분명히 보여주었습니다.
`;const content = `
const nodejieba = require("nodejieba");
nodejieba.load({
userDict: './user.utf8',
});
const result = nodejieba.extract(content, 20);
const tagList = ['HTTPS', 'HTTP', 'HTTP/2', 'Web', '浏览器', '性能'];
console.log(result.filter(item => tagList.indexOf(item.word) >= 0));위 내용은 Node.js를 사용하여 텍스트 콘텐츠를 분할하고 키워드를 추출하는 방법에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7345
7345
 15
1627
14
1352
52
1265
25
1214
29
15
1627
14
1352
52
1265
25
1214
29

 Node의 메모리 제어에 관한 기사
Apr 26, 2023 pm 05:37 PM
Node의 메모리 제어에 관한 기사
Apr 26, 2023 pm 05:37 PM
Non-Blocking, Event-Driven 기반으로 구축된 Node 서비스는 메모리 소모가 적다는 장점이 있으며, 대규모 네트워크 요청을 처리하는데 매우 적합합니다. 대규모 요청을 전제로 '메모리 제어'와 관련된 문제를 고려해야 합니다. 1. V8의 가비지 수집 메커니즘과 메모리 제한 Js는 가비지 수집 기계에 의해 제어됩니다.
 Node V8 엔진의 메모리와 GC에 대한 자세한 그래픽 설명
Mar 29, 2023 pm 06:02 PM
Node V8 엔진의 메모리와 GC에 대한 자세한 그래픽 설명
Mar 29, 2023 pm 06:02 PM
이 기사는 NodeJS V8 엔진의 메모리 및 가비지 수집기(GC)에 대한 심층적인 이해를 제공할 것입니다. 도움이 되기를 바랍니다.
 Node.js 19가 공식적으로 출시되었습니다. Node.js의 6가지 주요 기능에 대해 이야기해 보겠습니다!
Nov 16, 2022 pm 08:34 PM
Node.js 19가 공식적으로 출시되었습니다. Node.js의 6가지 주요 기능에 대해 이야기해 보겠습니다!
Nov 16, 2022 pm 08:34 PM
Node 19가 정식 출시되었습니다. 이 글에서는 Node.js 19의 6가지 주요 기능에 대해 자세히 설명하겠습니다. 도움이 되셨으면 좋겠습니다!
 Node의 파일 모듈에 대해 자세히 이야기해 보겠습니다.
Apr 24, 2023 pm 05:49 PM
Node의 파일 모듈에 대해 자세히 이야기해 보겠습니다.
Apr 24, 2023 pm 05:49 PM
파일 모듈은 파일 읽기/쓰기/열기/닫기/삭제 추가 등과 같은 기본 파일 작업을 캡슐화한 것입니다. 파일 모듈의 가장 큰 특징은 모든 메소드가 **동기** 및 ** 두 가지 버전을 제공한다는 것입니다. 비동기**, sync 접미사가 있는 메서드는 모두 동기화 메서드이고, 없는 메서드는 모두 이기종 메서드입니다.
 최고의 Node.js Docker 이미지를 선택하는 방법에 대해 이야기해 볼까요?
Dec 13, 2022 pm 08:00 PM
최고의 Node.js Docker 이미지를 선택하는 방법에 대해 이야기해 볼까요?
Dec 13, 2022 pm 08:00 PM
Node용 Docker 이미지를 선택하는 것은 사소한 문제처럼 보일 수 있지만 이미지의 크기와 잠재적인 취약점은 CI/CD 프로세스와 보안에 상당한 영향을 미칠 수 있습니다. 그렇다면 최고의 Node.js Docker 이미지를 어떻게 선택합니까?
 노드가 npm 명령을 사용할 수 없으면 어떻게 해야 합니까?
Feb 08, 2023 am 10:09 AM
노드가 npm 명령을 사용할 수 없으면 어떻게 해야 합니까?
Feb 08, 2023 am 10:09 AM
노드가 npm 명령을 사용할 수 없는 이유는 환경 변수가 올바르게 구성되지 않았기 때문입니다. 해결 방법은 다음과 같습니다. 1. "시스템 속성"을 엽니다. 2. "환경 변수" -> "시스템 변수"를 찾은 다음 환경을 편집합니다. 3. nodejs 폴더의 위치를 찾습니다. 4. "확인"을 클릭합니다.
 Node.js의 GC(가비지 수집) 메커니즘에 대해 이야기해 보겠습니다.
Nov 29, 2022 pm 08:44 PM
Node.js의 GC(가비지 수집) 메커니즘에 대해 이야기해 보겠습니다.
Nov 29, 2022 pm 08:44 PM
Node.js는 GC(가비지 수집)를 어떻게 수행하나요? 다음 기사에서는 이에 대해 설명합니다.
 Node의 이벤트 루프에 대해 이야기해 봅시다.
Apr 11, 2023 pm 07:08 PM
Node의 이벤트 루프에 대해 이야기해 봅시다.
Apr 11, 2023 pm 07:08 PM
이벤트 루프는 Node.js의 기본 부분이며 메인 스레드가 차단되지 않도록 하여 비동기 프로그래밍을 가능하게 합니다. 이벤트 루프를 이해하는 것은 효율적인 애플리케이션을 구축하는 데 중요합니다. 다음 기사는 Node.js의 이벤트 루프에 대한 심층적인 이해를 제공할 것입니다. 도움이 되기를 바랍니다!
