

binlog를 기반으로 mysql 행 레코드 수정 분석

최근에 mysql 플래시백 작성을 마쳤는데 갑자기 다음과 같은 사용 시나리오가 있다는 것을 발견했습니다. 어떤 경우에는 특정 기간 동안 MySQL이 얼마나 많은 데이터를 수정했는지 계산할 수 있습니까? 얼마나 많은 거래가 발생했나요? 주로 어떤 양식이 변경되나요? 변화의 정도는 얼마입니까? 하지만 행 레코드를 수정할 필요는 없으며 행 데이터의 변경 사항만 알면 됩니다. 그래서 나도 정리했다.
어젯밤에 작성한 스크립트입니다. 제 python 능력이 부족해서 원래는 이 글을 올리지 않을 생각이었는데, 생각해보니 정원 친구들이 최적화 제안을 해줄 수도 있겠네요.
1 구현 내용
경우에 따라 일정 기간 동안 MySQL이 얼마나 많은 데이터를 수정했는지 계산할 수도 있나요? 얼마나 많은 거래가 발생했나요? 주로 어떤 테이블이 변경되나요? 변화의 정도는 얼마입니까? 하지만 행 레코드를 수정할 필요는 없으며 행 데이터의 변경 사항만 알면 됩니다.
이러한 상황 중 일부는 모니터링을 통해 대략적으로 이해할 수 있지만 binlog를 기반으로 완전히 분석할 수도 있습니다. binlog의 형식은 행 모드입니다.
제가 플래시백을 쓸 때, 그런데 이 단계도 Python으로 작성했습니다. 원리는 동일하지만, 제 Python이 부족해서 여유가 많을 수도 있습니다. 성능 향상을 위해 Garden 친구들이 이를 최적화하는 데 도움을 주기를 바랍니다.
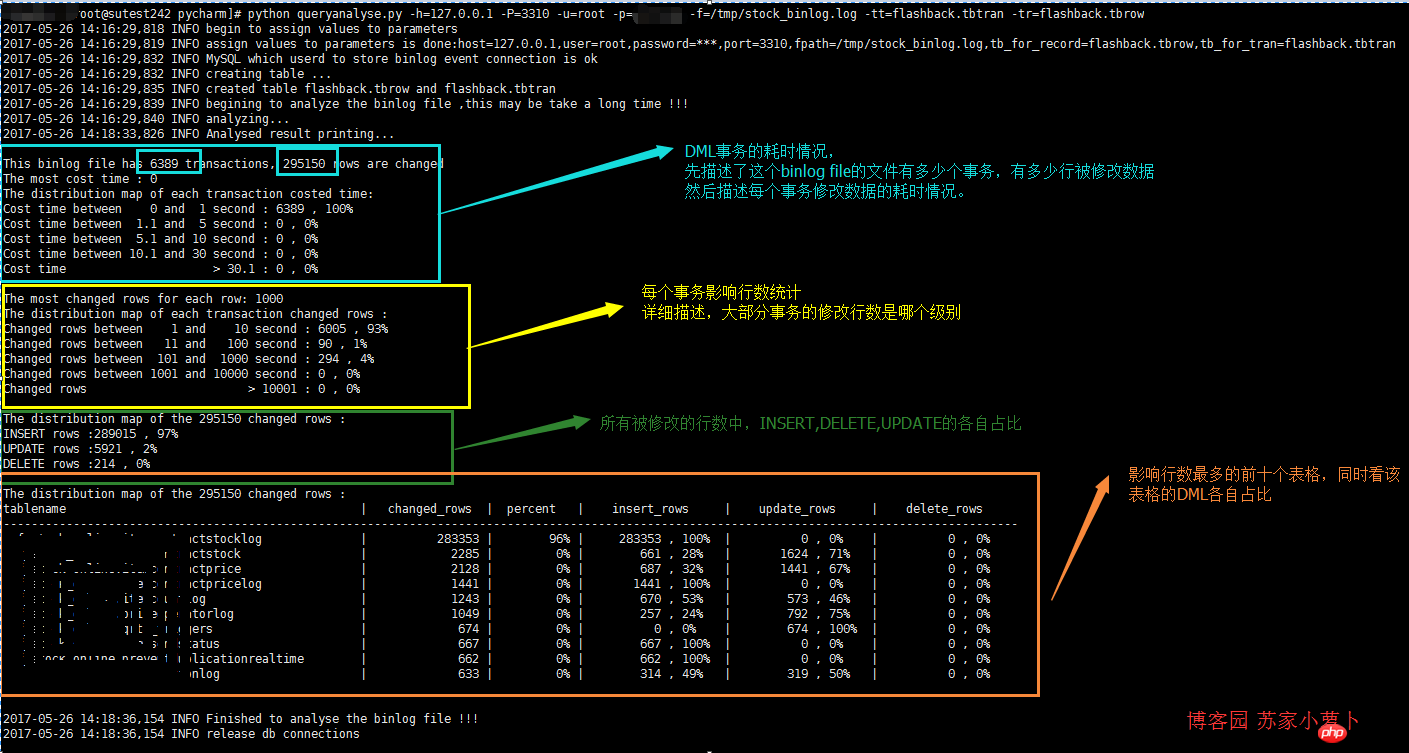
먼저 Python 스크립트의 분석 결과는 트랜잭션 시간 소비, 트랜잭션에 영향을 받는 행 수, DML 행 수, 가장 자주 작동하는 테이블의 테이블 상태 등 4가지 부분으로 나누어 다음과 같이 게시됩니다.
2 스크립트에 대한 간략한 설명
스크립트가 의존하는 모듈 중 pymysql은 직접 설치해야 합니다.
5개의함수가 정의된 queryanalyse 클래스를 만듭니다: _get_db, create_tab, rowrecord, binlogdesc 및 closeconn.
2.1 _get_db
이 함수는 입력 매개변수 값을 구문 분석하는 데 사용됩니다. 매개변수 값은 총 7개이며 모두 입력해야 합니다. 호스트, 사용자, 비밀번호, 포트, 테이블 이름for transaction, 해당 약어는 다음과 같습니다.
file 경로, binlog 파일
-tr : 레코드용 테이블 이름, 행 레코드를 저장할 테이블 이름-tt : 트랜잭션용 테이블 이름, 트랜잭션을 저장할 테이블 이름 예를 들어 다음 스크립트를 실행합니다. python queryanalyse.py - h=127.0.0.1 -P=3310 -u=root -p=password -f=/tmp/stock_binlog.log -tt=flashback.tbtran -tr=flashback.tbrow, 이 함수는 각 옵션의 매개변수 값을 저장합니다.2.2 create_tab
binlog 파일의 분석 결과를 저장하기 위해 두 개의 테이블을 생성합니다. 하나는 트랜잭션의 실행 시작 시간과 종료 시간을 저장하는 데 사용되고, 다른 하나는 -tt 옵션으로 테이블 이름을 지정하고, 다른 하나는 레코드의 각 행에 대한 수정 사항을 저장하는 데 사용되며, 테이블 이름은 옵션 -tr. 거래 테이블 기록 내용: 거래 시작 시간 및 거래 종료 시간. 행 레코드 테이블의 내용: 라이브러리 이름, 테이블 이름, DML 유형 및 트랜잭션에 해당하는 트랜잭션 테이블 번호.root@localhost:mysql3310.sock 14:42:29 [flashback]>show create table tbrow \G*************************** 1. row *************************** Table: tbrowCreate Table: CREATE TABLE `tbrow` ( `auto_id` int(10) unsigned NOT NULL AUTO_INCREMENT, `sqltype` int(11) NOT NULL COMMENT '1 is insert,2 is update,3 is delete', `tran_num` int(11) NOT NULL COMMENT 'the transaction number', `dbname` varchar(50) NOT NULL, `tbname` varchar(50) NOT NULL, PRIMARY KEY (`auto_id`), KEY `sqltype` (`sqltype`), KEY `dbname` (`dbname`), KEY `tbname` (`tbname`) ) ENGINE=InnoDB AUTO_INCREMENT=295151 DEFAULT CHARSET=utf81 row in set (0.00 sec) root@localhost:mysql3310.sock 14:42:31 [flashback]>SHOW CREATE TABLE TBTRAN \G*************************** 1. row *************************** Table: TBTRANCreate Table: CREATE TABLE `tbtran` ( `auto_id` int(10) unsigned NOT NULL AUTO_INCREMENT, `begin_time` datetime NOT NULL, `end_time` datetime NOT NULL, PRIMARY KEY (`auto_id`) ) ENGINE=InnoDB AUTO_INCREMENT=6390 DEFAULT CHARSET=utf81 row in set (0.00 sec)
2.3 rowrecord
주요 기능, binlog 파일의 내용을 분석합니다. 다음은 몇 가지 규칙입니다.每个事务的结束点,是以 'Xid = ' 来查找
事务的开始时间,是事务内的第一个 'Table_map' 行里边的时间
事务的结束时间,是以 'Xid = '所在行的 里边的时间
每个行数据是属于哪个表格,是以 'Table_map'来查找
DML的类型是按照 行记录开头的情况是否为:'### INSERT INTO' 、'### UPDATE' 、'### DELETE FROM'
注意,单个事务可以包含多个表格多种DML多行数据修改的情况。
2.4 binlogdesc
描述分析结果,简单4个SQL分析。
分析修改行数据的 事务耗时情况
分析修改行数据的 事务影响行数情况
分析DML分布情况
分析 最多DML操作的表格 ,取前十个分析
2.5 closeconn
关闭数据库连接。
3 使用说明
首先,确保python安装了pymysql模块,把python脚本拷贝到文件 queryanalyse.py。
然后,把要分析的binlog文件先用 mysqlbinlog 指令分析存储,具体binlog的文件说明,可以查看之前的博文:关于binary log那些事——认真码了好长一篇。mysqlbinlog的指令使用方法,可以详细查看文档:https://dev.mysql.com/doc/refman/5.7/en/mysqlbinlog.html 。
比较常用通过指定开始时间跟结束时间来分析 binlog文件。
mysqlbinlog --start-datetime='2017-04-23 00:00:03' --stop-datetime='2017-04-23 00:30:00' --base64-output=decode-rows -v /data/mysql/logs/mysql-bin.007335 > /tmp/binlog_test.log
分析后,可以把这个 binlog_test.log文件拷贝到其他空闲服务器执行分析,只需要有个空闲的DB来存储分析记录即可。
假设这个时候,拷贝 binlog_test.log到测试服务器上,测试服务器上的数据库可以用来存储分析内容,则可以执行python脚本了,注意要进入到python脚本的目录中,或者指定python脚本路径。
python queryanalyse.py -h=127.0.0.1 -P=3310 -u=root -p=password -f= /tmp/binlog_test.log -tt=flashback.tbtran -tr=flashback.tbrow
没了,就等待输出吧。
性能是硬伤,在虚拟机上测试,大概500M的binlog文件需要分析2-3min,有待提高!
4 python脚本
1 import pymysql 2 from pymysql.cursors import DictCursor 3 import re 4 import os 5 import sys 6 import datetime 7 import time 8 import logging 9 import importlib 10 importlib.reload(logging) 11 logging.basicConfig(level=logging.DEBUG,format='%(asctime)s %(levelname)s %(message)s ') 12 13 14 usage=''' usage: python [script's path] [option] 15 ALL options need to assign: 16 17 -h : host, the database host,which database will store the results after analysis
18 -u : user, the db user 19 -p : password, the db user's password 20 -P : port, the db port 21 -f : file path, the binlog file 22 -tr : table name for record , the table name to store the row record 23 -tt : table name for transaction, the table name to store transactions 24 Example: python queryanalyse.py -h=127.0.0.1 -P=3310 -u=root -p=password -f=/tmp/stock_binlog.log -tt=flashback.tbtran -tr=flashback.tbrow 25 26 ''' 27 28 class queryanalyse: 29 def init(self): 30 #初始化 31 self.host='' 32 self.user='' 33 self.password='' 34 self.port='3306' 35 self.fpath='' 36 self.tbrow='' 37 self.tbtran='' 38 39 self._get_db() 40 logging.info('assign values to parameters is done:host={},user={},password=***,port={},fpath={},tb_for_record={},tb_for_tran={}'.format(self.host,self.user,self.port,self.fpath,self.tbrow,self.tbtran)) 41 42 self.mysqlconn = pymysql.connect(host=self.host, user=self.user, password=self.password, port=self.port,charset='utf8') 43 self.cur = self.mysqlconn.cursor(cursor=DictCursor) 44 logging.info('MySQL which userd to store binlog event connection is ok') 45 46 self.begin_time='' 47 self.end_time='' 48 self.db_name='' 49 self.tb_name='' 50 51 def _get_db(self): 52 #解析用户输入的选项参数值,这里对password的处理是明文输入,可以自行处理成是input格式, 53 #由于可以拷贝binlog文件到非线上环境分析,所以password这块,没有特殊处理 54 logging.info('begin to assign values to parameters') 55 if len(sys.argv) == 1: 56 print(usage) 57 sys.exit(1) 58 elif sys.argv[1] == '--help': 59 print(usage) 60 sys.exit() 61 elif len(sys.argv) > 2: 62 for i in sys.argv[1:]: 63 _argv = i.split('=') 64 if _argv[0] == '-h': 65 self.host = _argv[1] 66 elif _argv[0] == '-u': 67 self.user = _argv[1] 68 elif _argv[0] == '-P': 69 self.port = int(_argv[1]) 70 elif _argv[0] == '-f': 71 self.fpath = _argv[1] 72 elif _argv[0] == '-tr': 73 self.tbrow = _argv[1] 74 elif _argv[0] == '-tt': 75 self.tbtran = _argv[1] 76 elif _argv[0] == '-p': 77 self.password = _argv[1] 78 else: 79 print(usage) 80 81 def create_tab(self): 82 #创建两个表格:一个用户存储事务情况,一个用户存储每一行数据修改的情况 83 #注意,一个事务可以存储多行数据修改的情况 84 logging.info('creating table ...') 85 create_tb_sql ='''CREATE TABLE IF NOT EXISTS {} ( 86 `auto_id` int(10) unsigned NOT NULL AUTO_INCREMENT, 87 `begin_time` datetime NOT NULL, 88 `end_time` datetime NOT NULL, 89 PRIMARY KEY (`auto_id`) 90 ) ENGINE=InnoDB DEFAULT CHARSET=utf8; 91 CREATE TABLE IF NOT EXISTS {} ( 92 `auto_id` int(10) unsigned NOT NULL AUTO_INCREMENT, 93 `sqltype` int(11) NOT NULL COMMENT '1 is insert,2 is update,3 is delete', 94 `tran_num` int(11) NOT NULL COMMENT 'the transaction number', 95 `dbname` varchar(50) NOT NULL, 96 `tbname` varchar(50) NOT NULL, 97 PRIMARY KEY (`auto_id`), 98 KEY `sqltype` (`sqltype`), 99 KEY `dbname` (`dbname`),100 KEY `tbname` (`tbname`)101 ) ENGINE=InnoDB DEFAULT CHARSET=utf8;102 truncate table {};103 truncate table {};104 '''.format(self.tbtran,self.tbrow,self.tbtran,self.tbrow)105 106 self.cur.execute(create_tb_sql)107 logging.info('created table {} and {}'.format(self.tbrow,self.tbtran))108 109 def rowrecord(self):110 #处理每一行binlog111 #事务的结束采用 'Xid =' 来划分112 #分析结果,按照一个事务为单位存储提交一次到db113 try:114 tran_num=1 #事务数115 record_sql='' #行记录的insert sql116 tran_sql='' #事务的insert sql117 118 self.create_tab()119 120 with open(self.fpath,'r') as binlog_file:121 logging.info('begining to analyze the binlog file ,this may be take a long time !!!')122 logging.info('analyzing...')123 124 for bline in binlog_file:125 126 if bline.find('Table_map:') != -1:127 l = bline.index('server')128 n = bline.index('Table_map')129 begin_time = bline[:l:].rstrip(' ').replace('#', '20')130 131 if record_sql=='':132 self.begin_time = begin_time[0:4] + '-' + begin_time[4:6] + '-' + begin_time[6:]133 134 self.db_name = bline[n::].split(' ')[1].replace('`', '').split('.')[0]135 self.tb_name = bline[n::].split(' ')[1].replace('`', '').split('.')[1]136 bline=''137 138 elif bline.startswith('### INSERT INTO'):139 record_sql=record_sql+"insert into {}(sqltype,tran_num,dbname,tbname) VALUES (1,{},'{}','{}');".format(self.tbrow,tran_num,self.db_name,self.tb_name)140 141 elif bline.startswith('### UPDATE'):142 record_sql=record_sql+"insert into {}(sqltype,tran_num,dbname,tbname) VALUES (2,{},'{}','{}');".format(self.tbrow,tran_num,self.db_name,self.tb_name)143 144 elif bline.startswith('### DELETE FROM'):145 record_sql=record_sql+"insert into {}(sqltype,tran_num,dbname,tbname) VALUES (3,{},'{}','{}');".format(self.tbrow,tran_num,self.db_name,self.tb_name)146 147 elif bline.find('Xid =') != -1:148 149 l = bline.index('server')150 end_time = bline[:l:].rstrip(' ').replace('#', '20')151 self.end_time = end_time[0:4] + '-' + end_time[4:6] + '-' + end_time[6:]152 tran_sql=record_sql+"insert into {}(begin_time,end_time) VALUES ('{}','{}')".format(self.tbtran,self.begin_time,self.end_time)153 154 self.cur.execute(tran_sql)155 self.mysqlconn.commit()156 record_sql = ''157 tran_num += 1158 159 except Exception:160 return 'funtion rowrecord error'161 162 def binlogdesc(self):163 sql=''164 t_num=0165 r_num=0166 logging.info('Analysed result printing...\n')167 #分析总的事务数跟行修改数量168 sql="select 'tbtran' name,count(*) nums from {} union all select 'tbrow' name,count(*) nums from {};".format(self.tbtran,self.tbrow)169 self.cur.execute(sql)170 rows=self.cur.fetchall()171 for row in rows:172 if row['name']=='tbtran':173 t_num = row['nums']174 else:175 r_num = row['nums']176 print('This binlog file has {} transactions, {} rows are changed '.format(t_num,r_num))177 178 # 计算 最耗时 的单个事务179 # 分析每个事务的耗时情况,分为5个时间段来描述180 # 这里正常应该是 以毫秒来分析的,但是binlog中,只精确时间到second181 sql='''select
182 count(case when cost_sec between 0 and 1 then 1 end ) cos_1,183 count(case when cost_sec between 1.1 and 5 then 1 end ) cos_5,184 count(case when cost_sec between 5.1 and 10 then 1 end ) cos_10,185 count(case when cost_sec between 10.1 and 30 then 1 end ) cos_30,186 count(case when cost_sec >30.1 then 1 end ) cos_more,187 max(cost_sec) cos_max188 from
189 (190 select
191 auto_id,timestampdiff(second,begin_time,end_time) cost_sec192 from {}193 ) a;'''.format(self.tbtran)194 self.cur.execute(sql)195 rows=self.cur.fetchall()196 197 for row in rows:198 print('The most cost time : {} '.format(row['cos_max']))199 print('The distribution map of each transaction costed time: ')200 print('Cost time between 0 and 1 second : {} , {}%'.format(row['cos_1'],int(row['cos_1']*100/t_num)))201 print('Cost time between 1.1 and 5 second : {} , {}%'.format(row['cos_5'], int(row['cos_5'] * 100 / t_num)))202 print('Cost time between 5.1 and 10 second : {} , {}%'.format(row['cos_10'], int(row['cos_10'] * 100 / t_num)))203 print('Cost time between 10.1 and 30 second : {} , {}%'.format(row['cos_30'], int(row['cos_30'] * 100 / t_num)))204 print('Cost time > 30.1 : {} , {}%\n'.format(row['cos_more'], int(row['cos_more'] * 100 / t_num)))205 206 # 计算 单个事务影响行数最多 的行数量207 # 分析每个事务 影响行数 情况,分为5个梯度来描述208 sql='''select
209 count(case when nums between 0 and 10 then 1 end ) row_1,210 count(case when nums between 11 and 100 then 1 end ) row_2,211 count(case when nums between 101 and 1000 then 1 end ) row_3,212 count(case when nums between 1001 and 10000 then 1 end ) row_4,213 count(case when nums >10001 then 1 end ) row_5,214 max(nums) row_max215 from
216 (217 select
218 count(*) nums219 from {} group by tran_num220 ) a;'''.format(self.tbrow)221 self.cur.execute(sql)222 rows=self.cur.fetchall()223 224 for row in rows:225 print('The most changed rows for each row: {} '.format(row['row_max']))226 print('The distribution map of each transaction changed rows : ')227 print('Changed rows between 1 and 10 second : {} , {}%'.format(row['row_1'],int(row['row_1']*100/t_num)))228 print('Changed rows between 11 and 100 second : {} , {}%'.format(row['row_2'], int(row['row_2'] * 100 / t_num)))229 print('Changed rows between 101 and 1000 second : {} , {}%'.format(row['row_3'], int(row['row_3'] * 100 / t_num)))230 print('Changed rows between 1001 and 10000 second : {} , {}%'.format(row['row_4'], int(row['row_4'] * 100 / t_num)))231 print('Changed rows > 10001 : {} , {}%\n'.format(row['row_5'], int(row['row_5'] * 100 / t_num)))232 233 # 分析 各个行数 DML的类型情况234 # 描述 delete,insert,update的分布情况235 sql='select sqltype ,count(*) nums from {} group by sqltype ;'.format(self.tbrow)236 self.cur.execute(sql)237 rows=self.cur.fetchall()238 239 print('The distribution map of the {} changed rows : '.format(r_num))240 for row in rows:241 242 if row['sqltype']==1:243 print('INSERT rows :{} , {}% '.format(row['nums'],int(row['nums']*100/r_num)))244 if row['sqltype']==2:245 print('UPDATE rows :{} , {}% '.format(row['nums'],int(row['nums']*100/r_num)))246 if row['sqltype']==3:247 print('DELETE rows :{} , {}%\n '.format(row['nums'],int(row['nums']*100/r_num)))248 249 # 描述 影响行数 最多的表格250 # 可以分析是哪些表格频繁操作,这里显示前10个table name251 sql = '''select
252 dbname,tbname ,253 count(*) ALL_rows,254 count(*)*100/{} per,255 count(case when sqltype=1 then 1 end) INSERT_rows,256 count(case when sqltype=2 then 1 end) UPDATE_rows,257 count(case when sqltype=3 then 1 end) DELETE_rows258 from {}
259 group by dbname,tbname
260 order by ALL_rows desc
261 limit 10;'''.format(r_num,self.tbrow)262 self.cur.execute(sql)263 rows = self.cur.fetchall()264 265 print('The distribution map of the {} changed rows : '.format(r_num))266 print('tablename'.ljust(50),267 '|','changed_rows'.center(15),268 '|','percent'.center(10),269 '|','insert_rows'.center(18),270 '|','update_rows'.center(18),271 '|','delete_rows'.center(18)272 )273 print('-------------------------------------------------------------------------------------------------------------------------------------------------')274 for row in rows:275 print((row['dbname']+'.'+row['tbname']).ljust(50),276 '|',str(row['ALL_rows']).rjust(15),277 '|',(str(int(row['per']))+'%').rjust(10),278 '|',str(row['INSERT_rows']).rjust(10)+' , '+(str(int(row['INSERT_rows']*100/row['ALL_rows']))+'%').ljust(5),279 '|',str(row['UPDATE_rows']).rjust(10)+' , '+(str(int(row['UPDATE_rows']*100/row['ALL_rows']))+'%').ljust(5),280 '|',str(row['DELETE_rows']).rjust(10)+' , '+(str(int(row['DELETE_rows']*100/row['ALL_rows']))+'%').ljust(5),281 )282 print('\n')283 284 logging.info('Finished to analyse the binlog file !!!')285 286 def closeconn(self):287 self.cur.close()288 logging.info('release db connections\n')289 290 def main():291 p = queryanalyse()292 p.rowrecord()293 p.binlogdesc()294 p.closeconn()295 296 if name == "main":297 main()위 내용은 binlog를 기반으로 mysql 행 레코드 수정 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7724
7724
 15
1643
14
1396
52
1290
25
1233
29
15
1643
14
1396
52
1290
25
1233
29

 MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템으로, 주로 데이터를 신속하고 안정적으로 저장하고 검색하는 데 사용됩니다. 작업 원칙에는 클라이언트 요청, 쿼리 해상도, 쿼리 실행 및 반환 결과가 포함됩니다. 사용의 예로는 테이블 작성, 데이터 삽입 및 쿼리 및 조인 작업과 같은 고급 기능이 포함됩니다. 일반적인 오류에는 SQL 구문, 데이터 유형 및 권한이 포함되며 최적화 제안에는 인덱스 사용, 최적화 된 쿼리 및 테이블 분할이 포함됩니다.
 MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
데이터베이스 및 프로그래밍에서 MySQL의 위치는 매우 중요합니다. 다양한 응용 프로그램 시나리오에서 널리 사용되는 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) MySQL은 웹, 모바일 및 엔터프라이즈 레벨 시스템을 지원하는 효율적인 데이터 저장, 조직 및 검색 기능을 제공합니다. 2) 클라이언트 서버 아키텍처를 사용하고 여러 스토리지 엔진 및 인덱스 최적화를 지원합니다. 3) 기본 사용에는 테이블 작성 및 데이터 삽입이 포함되며 고급 사용에는 다중 테이블 조인 및 복잡한 쿼리가 포함됩니다. 4) SQL 구문 오류 및 성능 문제와 같은 자주 묻는 질문은 설명 명령 및 느린 쿼리 로그를 통해 디버깅 할 수 있습니다. 5) 성능 최적화 방법에는 인덱스의 합리적인 사용, 최적화 된 쿼리 및 캐시 사용이 포함됩니다. 모범 사례에는 거래 사용 및 준비된 체계가 포함됩니다
 MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL은 성능, 신뢰성, 사용 편의성 및 커뮤니티 지원을 위해 선택됩니다. 1.MYSQL은 효율적인 데이터 저장 및 검색 기능을 제공하여 여러 데이터 유형 및 고급 쿼리 작업을 지원합니다. 2. 고객-서버 아키텍처 및 다중 스토리지 엔진을 채택하여 트랜잭션 및 쿼리 최적화를 지원합니다. 3. 사용하기 쉽고 다양한 운영 체제 및 프로그래밍 언어를 지원합니다. 4. 강력한 지역 사회 지원을 받고 풍부한 자원과 솔루션을 제공합니다.
 Apache의 데이터베이스에 연결하는 방법
Apr 13, 2025 pm 01:03 PM
Apache의 데이터베이스에 연결하는 방법
Apr 13, 2025 pm 01:03 PM
Apache는 데이터베이스에 연결하여 다음 단계가 필요합니다. 데이터베이스 드라이버 설치. 연결 풀을 만들려면 Web.xml 파일을 구성하십시오. JDBC 데이터 소스를 작성하고 연결 설정을 지정하십시오. JDBC API를 사용하여 Connections, 명세서 작성, 매개 변수 바인딩, 쿼리 또는 업데이트 실행 및 처리를 포함하여 Java 코드의 데이터베이스에 액세스하십시오.
 Docker의 MySQL을 시작하는 방법
Apr 15, 2025 pm 12:09 PM
Docker의 MySQL을 시작하는 방법
Apr 15, 2025 pm 12:09 PM
Docker에서 MySQL을 시작하는 프로세스는 다음 단계로 구성됩니다. MySQL 이미지를 가져와 컨테이너를 작성하고 시작하고 루트 사용자 암호를 설정하고 포트 확인 연결을 매핑하고 데이터베이스를 작성하고 사용자는 데이터베이스에 모든 권한을 부여합니다.
 MySQL의 역할 : 웹 응용 프로그램의 데이터베이스
Apr 17, 2025 am 12:23 AM
MySQL의 역할 : 웹 응용 프로그램의 데이터베이스
Apr 17, 2025 am 12:23 AM
웹 응용 프로그램에서 MySQL의 주요 역할은 데이터를 저장하고 관리하는 것입니다. 1. MySQL은 사용자 정보, 제품 카탈로그, 트랜잭션 레코드 및 기타 데이터를 효율적으로 처리합니다. 2. SQL 쿼리를 통해 개발자는 데이터베이스에서 정보를 추출하여 동적 컨텐츠를 생성 할 수 있습니다. 3.mysql은 클라이언트-서버 모델을 기반으로 작동하여 허용 가능한 쿼리 속도를 보장합니다.
 LARAVEL 소개 예
Apr 18, 2025 pm 12:45 PM
LARAVEL 소개 예
Apr 18, 2025 pm 12:45 PM
Laravel은 웹 응용 프로그램을 쉽게 구축하기위한 PHP 프레임 워크입니다. 설치 : Composer를 사용하여 전 세계적으로 Laravel CLI를 설치하고 프로젝트 디렉토리에서 응용 프로그램을 작성하는 등 다양한 기능을 제공합니다. 라우팅 : Routes/Web.php에서 URL과 핸들러 간의 관계를 정의하십시오. 보기 : 리소스/뷰에서보기를 작성하여 응용 프로그램의 인터페이스를 렌더링합니다. 데이터베이스 통합 : MySQL과 같은 데이터베이스와 상자 외 통합을 제공하고 마이그레이션을 사용하여 테이블을 작성하고 수정합니다. 모델 및 컨트롤러 : 모델은 데이터베이스 엔티티를 나타내고 컨트롤러는 HTTP 요청을 처리합니다.
 CentOS7에 MySQL을 설치하는 방법 7
Apr 14, 2025 pm 08:30 PM
CentOS7에 MySQL을 설치하는 방법 7
Apr 14, 2025 pm 08:30 PM
MySQL을 우아하게 설치하는 열쇠는 공식 MySQL 저장소를 추가하는 것입니다. 특정 단계는 다음과 같습니다. 피싱 공격을 방지하기 위해 MySQL 공식 GPG 키를 다운로드하십시오. MySQL 리포지토리 파일 추가 : rpm -uvh https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm yum repository cache : yum 업데이트 설치 mysql : yum 설치 mysql-server startup startup mysql 서비스 : systemctl start mysqlctl start mysqlctl.
