

MySQL의 query최적화에 대해 말하자면, 저는 모두가 많은 기술을 축적했다고 믿습니다. SELECT *를 사용하지 않고, NULL 필드를 사용하지 않고, 합리적으로 인덱스를 만들고, 필드에 적합한 데이터 유형을 선택하는 것. .... 당신은 이러한 최적화 기술을 정말로 이해하고 있습니까? 어떻게 작동하는지 이해하시나요? 실제 시나리오에서 성능이 정말 향상되었나요? 나는 그렇게 생각하지 않습니다. 따라서 이러한 최적화 제안의 이면에 있는 원칙을 이해하는 것이 특히 중요합니다. 이 기사를 통해 이러한 최적화 제안을 다시 검토하고 실제 비즈니스 시나리오에 합리적으로 적용할 수 있기를 바랍니다.
MySQL의 다양한 구성 요소가 어떻게 함께 작동하는지 마음속에 아키텍처 다이어그램을 구축할 수 있다면 MySQL 서버를 더 깊이 이해하는 데 도움이 될 것입니다. 다음 그림은 MySQL의 논리적 아키텍처 다이어그램을 보여줍니다.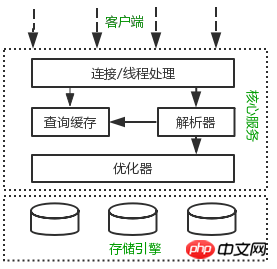
연결 처리, 인증 인증, 보안 및 기타 기능이 모두 이 계층에서 처리됩니다.
쿼리 구문 분석, 분석, 최적화,캐싱, 내장 기능(예: 시간, 수학, 암호화 등)을 포함한 대부분의 MySQL 핵심 서비스는 중간 계층에 있습니다. 저장 프로시저, triggers, views 등 모든 교차 스토리지 엔진 기능도 이 계층에서 구현됩니다.
최하위 계층은 MySQL에서 데이터 저장 및 검색을 담당하는 스토리지 엔진입니다.Linux의 파일 시스템과 유사하게 각 스토리지 엔진에는 장점과 단점이 있습니다. 중간 서비스 계층은 API를 통해 스토리지 엔진과 통신합니다. 이러한 API 인터페이스는 다양한 스토리지 엔진 간의 차이점을 보호합니다.
MySQL 쿼리 프로세스 우리는 항상 MySQL이 더 높은 쿼리 성능을 얻을 수 있기를 바라며, 가장 좋은 방법은 MySQL이 쿼리를 어떻게 최적화하고 실행하는지 파악하는 것입니다. 이것을 이해하고 나면 MySQL 최적화 프로그램이 예상되고 합리적인 방식으로 실행될 수 있도록 많은 쿼리 최적화 작업이 실제로 몇 가지 원칙을 따르는 것임을 알게 될 것입니다. MySQL에 요청을 보낼 때 MySQL은 정확히 무엇을 합니까?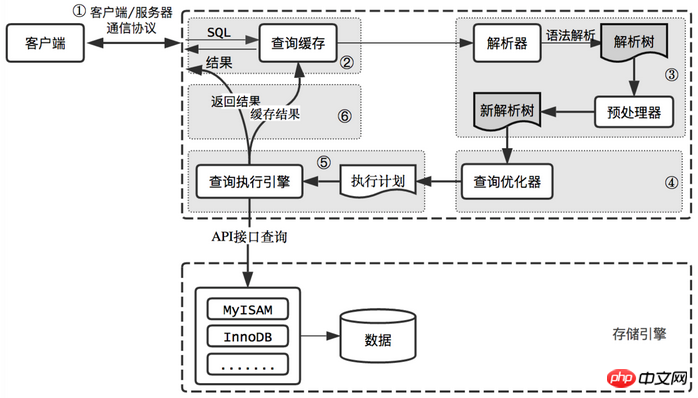
를 보내기 시작하면 다른 쪽 끝에서 응답하기 전에 전체 메시지를 받아야 합니다. 따라서 메시지를 작은 조각으로 나누어 독립적으로 보낼 수도 없고 보낼 필요도 없으며 제어할 방법이 없습니다. 흐름.
클라이언트는 별도의 데이터 패킷으로 서버에 쿼리 요청을 보내기 때문에 쿼리문이 매우 긴 경우에는 max_
allowed_packet 매개변수를 설정해야 합니다. 그러나 쿼리가 너무 크면 서버가 추가 데이터 수신을 거부하고 예외를 발생시킵니다는 점에 유의해야 합니다.
반대로 서버가 사용자에게 응답하는 데이터는 일반적으로 여러 데이터 패킷으로 구성된 많은 양의 데이터입니다. 그러나 서버가 클라이언트의 요청에 응답할 때 클라이언트는 단순히 처음 몇 개의 결과를 가져온 다음 서버에 전송을 중지하도록 요청하는 대신 반환된 전체 결과를 완전히 받아야 합니다. 따라서 실제 개발에서는 쿼리를 최대한 단순하게 유지하고 필요한 데이터만 반환하며, 통신 시 데이터 패킷의 크기와 개수를 줄이는 것이 매우 좋은 습관입니다. 이것이 우리가 SELECT를 사용하지 않으려고 노력하는 이유이기도 합니다. * 쿼리 하나에 LIMIT 제한을 추가합니다.
쿼리 캐시
쿼리 문을 구문 분석하기 전에 쿼리 캐시가 켜져 있으면 MySQL은 쿼리 문이 쿼리 캐시의 데이터에 도달하는지 확인합니다. 현재 쿼리가 쿼리 캐시에 부딪히면 사용자 권한을 한 번 확인한 후 바로 캐시에 있는 결과를 반환합니다. 이 경우 쿼리가 구문 분석되지 않고 실행 계획이 생성되지 않으며 실행되지 않습니다.
MySQL은 해시 값 인덱스를 통해 reference 테이블(테이블로 이해하지 말고 HashMap과 유사한 데이터 구조로 생각할 수 있음)에 캐시를 저장합니다. 이 해시 값은 쿼리 자체를 통해 전달되며, 현재 쿼리할 데이터베이스, 클라이언트 프로토콜 버전 번호 및 결과에 영향을 미칠 수 있는 기타 정보가 계산됩니다. 따라서 두 쿼리 사이의 문자 차이(예: 공백, comments)로 인해 캐시가 누락됩니다.
쿼리에 사용자 사용자 지정 함수, 저장 함수, 사용자 변수, 임시 테이블, mysql 라이브러리의 시스템 테이블이 포함된 경우 쿼리 결과
가 캐시되지 않습니다. 예를 들어 NOW() 또는 CURRENT_DATE() 함수는 쿼리 시간이 다르기 때문에 다른 쿼리 결과를 반환합니다. 또 다른 예는 CURRENT_USER 또는 CONNECION_ID()가 포함된 쿼리 문이 사용자에 따라 다른 결과를 반환하는 것입니다. . 그러한 쿼리 결과를 캐싱하는 것은 의미가 없습니다.
캐시이므로 만료됩니다. 쿼리 캐시는 언제 만료되나요? MySQL의 쿼리 캐싱 시스템은 쿼리에 포함된 각 테이블을 추적합니다. 이러한 테이블(데이터 또는 구조)이 변경되면 이 테이블과 관련된 모든 캐시된 데이터가 유효하지 않게 됩니다. 이 때문에 MySQL은 쓰기 작업 중에 해당 테이블에 대한 모든 캐시를 무효화해야 합니다. 쿼리 캐시가 매우 크거나 조각화되어 있는 경우 이 작업으로 인해 시스템이 많이 소모될 수 있으며 시스템이 잠시 정지될 수도 있습니다. 또한 시스템에서 쿼리 캐시를 추가로 소비하는 것은 쓰기 작업뿐만 아니라 읽기 작업에도 적용됩니다.
이 SQL 문이 캐시에 도달하지 않더라도 시작하기 전에 모든 쿼리 문을 확인해야 합니다
쿼리 결과를 캐시할 수 있으면 실행이 완료된 후 결과가 캐시에 저장되므로 시스템 소모도 늘어나게 됩니다.
이를 바탕으로 쿼리 캐싱이 수행되지 않는다는 점을 알아야 합니다. 모든 상황에서 시스템 성능 향상 캐싱 및 무효화는 추가 소비를 가져옵니다. 캐싱으로 인한 리소스 절약이 자체적으로 소비되는 리소스보다 클 경우에만 시스템 성능이 향상됩니다. 그러나 캐시를 켜면 성능이 향상될 수 있는지 여부를 평가하는 것은 매우 어려우며 이는 이 기사의 범위를 벗어납니다. 시스템에 성능 문제가 있는 경우 쿼리 캐시를 켜고 다음과 같이 데이터베이스 디자인을 일부 최적화할 수 있습니다.
하나의 큰 테이블을 여러 개의 작은 테이블로 바꾸고 과도하게 사용하지 않도록 주의하세요. 디자인해 보세요
일괄 삽입으로 대체 LoopSingle insert
캐시 공간 크기를 합리적으로 제어하세요. 일반적으로 크기를 수십 메가바이트로 설정하는 것이 더 적합합니다
특정 쿼리 문은 SQL_CACHE 및 SQL_NO_CACHE
을 통해 캐시해야 합니다. 마지막 조언은 특히 쓰기 집약적인 애플리케이션의 경우 쿼리 캐시를 쉽게 설정하지 말라는 것입니다. 어쩔 수 없다면 query_cache_type을 DEMAND로 설정할 수 있습니다. 이때 SQL_CACHE를 추가한 쿼리만 캐시되고 다른 쿼리는 캐시되지 않습니다.
물론, 쿼리 캐시 시스템 자체는 매우 복잡하며 여기서 논의되는 내용은 극히 일부에 불과합니다. 캐시는 메모리를 어떻게 사용합니까? 메모리 조각화를 제어하는 방법은 무엇입니까? 독자는 트랜잭션이 쿼리 캐시 등에 미치는 영향에 관한 관련 정보를 스스로 읽을 수 있습니다. 여기서부터 시작하십시오.
문법 구문 분석 및 전처리
MySQL은 키워드를 통해 SQL 문을 구문 분석하고 해당 구문 분석 트리를 생성합니다. 이 프로세스 파서는 주로 문법 규칙을 통해 검증하고 파싱합니다. 예를 들어 SQL에서 잘못된 키워드가 사용되었는지, 키워드의 순서가 올바른지 등이다. 전처리에서는 MySQL 규칙에 따라 구문 분석 트리가 적합한지 추가로 확인합니다. 예를 들어 쿼리할 데이터 테이블과 데이터 컬럼이 존재하는지 등을 확인한다.
쿼리 최적화
이전 단계를 통해 생성된 구문 트리는 합법적인 것으로 간주되며 최적화 프로그램에 의해 쿼리 계획으로 변환됩니다. 대부분의 경우 쿼리는 다양한 방법으로 실행될 수 있으며 모두 해당 결과를 반환합니다. 그 중에서 최적의 실행 계획을 찾는 것이 옵티마이저의 역할입니다.
MySQL은 특정 실행 계획을 사용하여 쿼리 비용을 예측하고 비용이 가장 작은 것을 선택하는 비용 기반 최적화 프로그램을 사용합니다. MySQL에서는 현재 세션의 last_query_cost 값을 쿼리하여 현재 쿼리를 계산하는 비용을 얻을 수 있습니다. mysql > 'last_query_cost'와 같은 상태 표시
최적화된 정렬(이전 버전의 MySQL에서는 두 가지 전송 정렬을 사용합니다. 즉, 먼저 정렬해야 할 행 포인터와 필드를 읽고 메모리에서 정렬한 다음 데이터를 읽습니다. 새 버전에서는 모든 데이터 행을 한 번에 읽은 다음 지정된 열에 따라 정렬하는 단일 전송 정렬을 사용하는 반면, I/O 집약적인 애플리케이션의 경우 효율성이 훨씬 높아집니다. MySQL이 지속적으로 개발됨에 따라 최적화 전략도 지속적으로 발전하고 있습니다. 다음은 매우 일반적으로 사용되며 이해하기 쉬운 최적화 전략입니다. 다른 최적화 전략에 대해서는 직접 확인해 보세요. .
dl
erAPI라고 합니다. 쿼리 프로세스의 각 테이블은 처리기 인스턴스로 표시됩니다. 실제로 MySQL은 쿼리 최적화 단계에서 각 테이블에 대한 핸들러 인스턴스를 생성합니다. 최적화 프로그램은 테이블의 모든 열 이름, 인덱스 통계 등을 포함하여 이러한 인스턴스의 인터페이스를 기반으로 테이블 관련 정보를 얻을 수 있습니다. 스토리지 엔진 인터페이스는 매우 풍부한 기능을 제공하지만 하위 계층에는 수십 개의 인터페이스만 있습니다. 이러한 인터페이스는 대부분의 쿼리 작업을 완료하는 구성 요소와 같습니다.MySQL의 전체 쿼리 실행 프로세스를 다시 요약하면 일반적으로 6단계로 나뉩니다.
클라이언트는 MySQL 서버에 쿼리 요청을 보냅니다
서버는 먼저 쿼리 캐시를 확인하고, 캐시에 도달하면 즉시 캐시에 저장된 결과를 반환합니다. 그렇지 않으면 다음 단계로 진입
서버가 SQL 구문 분석 및 전처리를 수행한 후 옵티마이저가 해당 실행 계획을 생성합니다
MySQL은 스토리지 엔진의 API를 호출하여 실행 계획에 따라 쿼리를 실행합니다
쿼리 결과를 캐싱하는 동안 클라이언트에게 결과를 반환합니다
성능 최적화제안
너무 많이 읽은 후 몇 가지 최적화 방법을 기대할 수 있습니다. 예, 아래에 3가지 최적화 제안이 제공됩니다. 상들. 하지만 먼저 주어야 할 또 다른 조언이 있습니다. 이 기사에서 논의된 내용을 포함하여 최적화에 대해 보는 "절대적인 진실"을 믿지 말고 실제 비즈니스 시나리오에서 테스트를 통해 확인하십시오. 그리고 응답 시간.
계획 설계 및 데이터 유형 최적화
데이터 유형을 선택할 때 작고 단순한 원칙을 따르세요. 일반적으로 데이터 유형이 작을수록 더 빠르고 디스크와 메모리를 덜 차지하며 처리에 필요한 CPU 주기도 적습니다. 예를 들어, 간단한 데이터 유형은 계산 중에 더 적은 CPU 주기를 필요로 하므로 정수는 IP 주소를 저장하는 데 사용되고 DATETIME는 문자를 사용하는 대신 시간을 저장하는 데 사용됩니다.
다음은 이해하기 쉽고 실수할 수 있는 몇 가지 팁입니다.정수 유형에 너비를 지정하는 것은 쓸모가 없습니다. INT는 16을 저장공간으로 사용하므로 그 표현범위가 정해져 있으므로 INT(1)과 INT(20)은 저장과 계산이 동일하다.
일반적으로 인덱스라고 부르는 것은 현재 관계형 데이터베이스에서 데이터를 찾는 데 가장 일반적으로 사용되고 효과적인 인덱스인 B-Tree 인덱스를 나타냅니다. B-Tree라는 용어는 MySQL이 CREATE TABLE이나 다른 문에서 이 키워드를 사용하기 때문에 사용되지만 실제로는 다른 스토리지 엔진이 다른 데이터 구조를 사용할 수 있습니다.
B+Tree의 B는 균형, 즉 균형을 의미합니다. B+ 트리 인덱스는 주어진 키 값을 가진 특정 행을 찾을 수 없으며, 검색 중인 데이터 행이 있는 페이지만 찾습니다. 그런 다음 데이터베이스는 페이지를 메모리로 읽어 들인 다음 메모리에서 검색합니다. , 마지막으로 찾고 있는 데이터를 가져옵니다.
B+Tree를 소개하기 전에 먼저 이진 검색 트리를 이해해 보겠습니다. 이는 고전적인 데이터 구조입니다. 왼쪽 하위 트리의 값은 항상 루트의 값보다 작으며 오른쪽 하위 트리의 값은 항상 입니다. 값은 아래 그림 ①과 같습니다. 이 학습 트리에서 값이 5인 레코드를 찾으려는 경우 일반적인 프로세스는 다음과 같습니다. 먼저 값이 5보다 큰 6인 루트를 찾아서 왼쪽 하위 트리를 검색하여 3을 찾고 5는 다음과 같습니다. 3보다 큰 경우 3개 트리의 올바른 하위 트리를 찾으면 총 3번 찾았습니다. 마찬가지로 값이 8인 레코드를 검색하면 역시 3번 검색해야 합니다. 따라서 이진 검색 트리의 평균 검색 횟수는 (3 + 3 + 3 + 2 + 2 + 1) / 6 = 2.3회가 되며, 순차적으로 검색하면 값이 2인 레코드를 찾는 데 1회만 필요하며, 그러나 검색 값은 8개 레코드에 6회가 필요하므로 순차 검색의 평균 검색 횟수는 다음과 같습니다. (1 + 2 + 3 + 4 + 5 + 6) / 6 = 3.3회. 대부분의 경우 평균 검색 속도는 이진 검색 트리는 순차 검색이 더 빠릅니다.
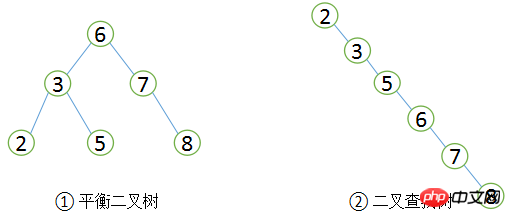
이진 검색 트리와 균형 이진 트리
이진 검색 트리는 동일한 값으로 임의로 구성할 수 있으므로 그림 ②와 같은 이진 검색 트리를 구성할 수 있음은 자명하다. 이 이진 트리의 쿼리 효율성은 순차 검색과 유사합니다. 이진 검색 숫자의 쿼리 성능을 가장 높이려면 균형이 잡힌 이 이진 검색 트리, 즉 균형 이진 트리(AVL 트리)가 필요합니다.
균형 이진 트리는 먼저 이진 검색 트리의 정의를 준수해야 하며, 두 번째로 모든 노드의 두 하위 트리 간의 높이 차이가 1보다 클 수 없다는 점을 만족해야 합니다. 분명히 그림 ②는 균형 이진 트리의 정의를 충족하지 않는 반면, 그림 ①은 균형 이진 트리입니다. 균형 잡힌 이진 트리의 검색 성능은 상대적으로 높습니다(최고의 이진 트리가 최고의 성능을 가집니다). 쿼리 성능이 좋을수록 유지 관리 비용이 커집니다. 예를 들어 그림 1의 균형 이진 트리에서 사용자가 값이 9인 새 노드를 삽입해야 하는 경우 다음과 같이 변경해야 합니다.
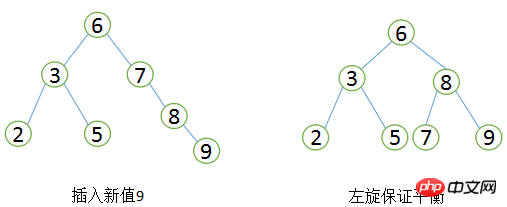
균형 이진 트리 회전
삽입된 트리를 왼쪽 회전 연산을 통해 균형 이진 트리로 다시 바꾸는 가장 간단한 경우입니다. 실제 응용 시나리오에서는 여러 회전이 발생할 수 있습니다. 필수의. 이 시점에서 우리는 균형 이진 트리의 검색 효율성이 매우 좋고 구현이 매우 간단하며 해당 유지 관리 비용이 허용되는 이유는 무엇입니까?
MySQL Index데이터베이스의 데이터가 많아질수록 인덱스 자체의 크기도 커지고, 메모리에 모두 저장하는 것도 불가능해 인덱스 파일 형태로 디스크에 저장되는 경우가 많다. 이 경우 인덱스 검색 프로세스 중에 디스크 I/O 소비가 발생합니다. 메모리 액세스에 비해 I/O 액세스 소비는 몇 배 더 높습니다. 수백만 개의 노드가 있는 이진 트리의 깊이를 상상할 수 있습니까? 그렇게 큰 깊이를 가진 이진 트리가 디스크에 배치되면 노드를 읽을 때마다 디스크에서 I/O 읽기가 필요하며 전체 검색 시간은 당연히 허용되지 않습니다. 그렇다면 검색 프로세스 중에 I/O 액세스 수를 줄이는 방법은 무엇입니까?
효과적인 해결책은 트리의 깊이를 줄여 이진 트리를 m-ary 트리(다중
검색트리)로 바꾸는 것인데, B+Tree는 다방향 검색 트리입니다. B+Tree를 이해하려면 가장 중요한 두 가지 기능만 이해하면 됩니다. 첫째, 모든 키워드(데이터로 이해될 수 있음)는 리프 노드(Leaf Page)에 저장되고 리프가 아닌 노드(Index Page)는 No가 아닙니다. 실제 데이터는 저장되며, 모든 레코드 노드는 키 값 순으로 리프 노드의 동일한 레이어에 저장됩니다. 둘째, 모든 리프 노드는 포인터로 연결됩니다. 아래 그림은 높이가 2인 단순화된 B+Tree를 보여줍니다.
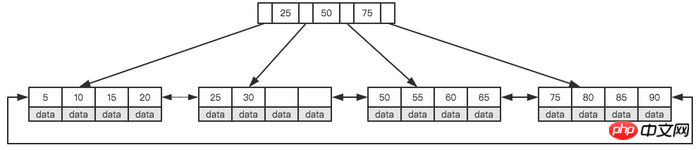
간소화된 B+트리
이 두 가지 특성을 어떻게 이해해야 할까요? MySQL은 각 노드의 크기를 페이지의 정수 배수로 설정합니다(이유는 아래에 소개됩니다). 즉, 노드 공간 크기가 확실할 때 각 노드는 더 많은 내부 노드를 저장할 수 있으므로 각 노드의 범위는 다음과 같습니다. 인덱스가 더 크고 정확해졌습니다. 모든 리프 노드에 대해 포인터 링크를 사용하면 간격 액세스가 가능하다는 장점이 있습니다. 예를 들어 위 그림에서 20보다 크고 30보다 작은 레코드를 찾으려면 노드 20만 찾으면 됩니다. 포인터를 탐색하여 25와 30을 차례로 찾습니다. 링크 포인터가 없으면 간격 검색을 수행할 수 없습니다. 이는 MySQL이 B+Tree를 인덱스 저장 구조로 사용하는 중요한 이유이기도 합니다.
MySQL이 노드 크기를 페이지의 정수배로 설정하는 이유는 디스크의 저장 원리를 이해해야 합니다. 디스크 자체의 액세스 속도는 메인 메모리의 속도보다 훨씬 느립니다(특히 일반 기계식 하드 디스크의 경우). 디스크의 액세스 속도는 메인 메모리의 속도보다 훨씬 느립니다. 디스크 I/O를 최소화하기 위해 디스크는 엄격하게 요구에 따라 읽히지 않고 매번 미리 읽히는 경우가 많습니다. 1바이트만 필요하더라도 디스크는 이 위치에서 시작하여 특정 길이의 데이터를 순차적으로 읽습니다. 미리 읽은 내용의 길이는 일반적으로 페이지의 정수배입니다.
인용문
페이지는 컴퓨터에서 관리하는 메모리의 논리적 블록입니다. 하드웨어와 OS는 종종 주 메모리와 디스크 저장 영역을 동일한 크기의 연속된 블록으로 나눕니다. 페이지는 일반적으로 4K). 메인 메모리와 디스크는 페이지 단위로 데이터를 교환합니다. 프로그램이 읽을 데이터가 메인 메모리에 없으면 페이지 폴트 예외가 발생합니다. 이때 시스템은 읽기 신호를 디스크에 보내고 디스크는 데이터의 시작 위치를 찾습니다. 한 페이지 또는 여러 페이지를 거꾸로 읽어 메모리에 로드한 후 비정상적으로 반환되고 프로그램이 계속 실행됩니다.
MySQL은 디스크 미리 읽기 원칙을 교묘하게 사용하여 노드의 크기를 한 페이지와 동일하게 설정하므로 각 노드는 완전히 로드되는 데 하나의 I/O만 필요합니다. 이 목표를 달성하기 위해 새 노드가 생성될 때마다 공간의 페이지가 직접 적용됩니다. 이를 통해 노드가 물리적으로 페이지에 저장되도록 하여 페이지 정렬을 실현합니다. 노드 읽기는 단 하나의 I/O만 필요합니다. B+Tree의 높이가 h라고 가정하면 검색에는 최대 h-1I/O(루트 노드 상주 메모리)가 필요하고 복잡도는 $O(h) = O(log_{M}N)$입니다. 실제 애플리케이션 시나리오에서 M은 일반적으로 크며 종종 100을 초과하므로 트리의 높이는 일반적으로 작으며 일반적으로 3을 넘지 않습니다.
마지막으로 B+Tree 노드의 동작을 간략하게 이해하고, 인덱스를 전체적으로 유지 관리하는 방법에 대해 전반적으로 이해해 보겠습니다. 인덱스를 사용하면 쿼리 효율성을 크게 향상시킬 수 있지만 여전히 유지 관리 비용이 많이 듭니다. 인덱스를 만드는 것이 합리적이므로 인덱스를 만드는 것이 특히 중요합니다.
위의 트리를 예로 들어 각 노드는 4개의 내부 노드만 저장할 수 있다고 가정합니다. 먼저 아래 그림과 같이 첫 번째 노드(28)를 삽입합니다.
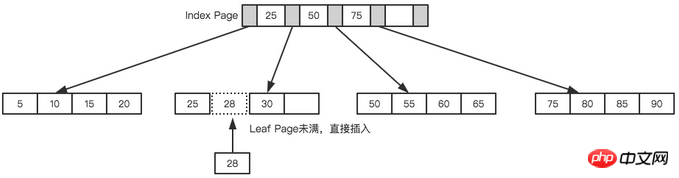
리프 페이지도 인덱스 페이지도 꽉 찼습니다
그리고 다음 노드 70을 삽입합니다. 인덱스 페이지를 쿼리한 결과 리프 노드는 50~70 사이에 삽입해야 한다는 것을 알게 됐고, 하지만 리프 노드가 가득 차게 됩니다. 이때 분할 작업을 수행해야 합니다. 현재 리프 노드의 시작점은 50이므로 아래 그림과 같이 중간 값을 기준으로 리프 노드가 분할됩니다. ㅋㅋㅋ
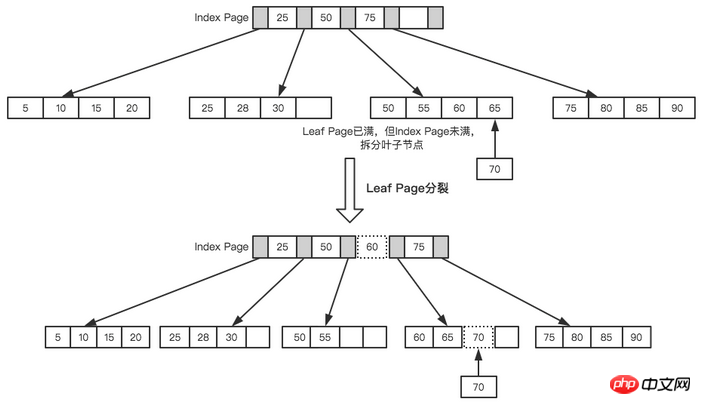
리프 페이지와 인덱스 페이지가 분할됩니다
분할을 거쳐 드디어 이런 트리가 형성됩니다.
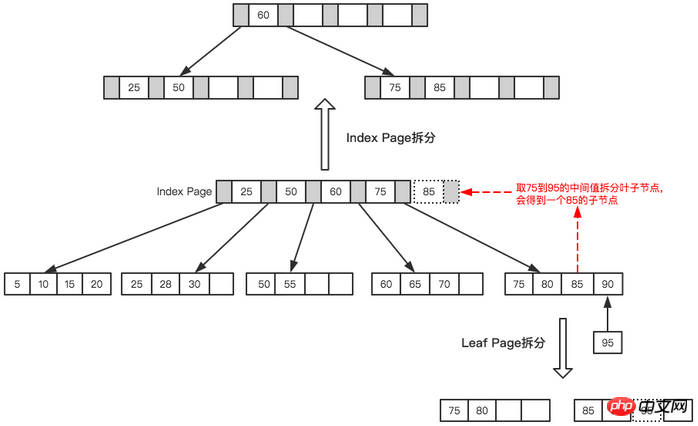
Final tree
B+Tree 균형을 유지하려면 새로 삽입된 값에 대해 많은 분할
paging 작업이 필요하고, 페이지 분할에는 I/O 작업이 필요합니다. 페이지 분할 작업을 잠재적으로 줄이기 위해 B+Tree는 균형 이진 트리와 유사한 회전 기능도 제공합니다. LeafPage가 가득 찼지만 왼쪽 및 오른쪽 형제 노드가 가득 차지 않은 경우 B+Tree는 분할 작업을 수행하지 않고 레코드를 현재 페이지의 형제 노드로 이동합니다. 일반적으로 회전 작업을 위해 왼쪽 형제를 먼저 확인합니다. 예를 들어 위의 두 번째 예에서 70을 삽입하면 페이지 분할이 수행되지 않고 좌회전 작업이 수행됩니다. ㅋㅋㅋ 노드를 삭제하고 노드 유형을 삽입하려면 여전히 회전 및 분할 작업이 필요하므로 여기서는 설명하지 않습니다. 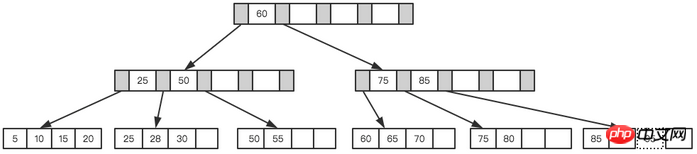
고성능 전략
위를 통해 이미 B+Tree의 데이터 구조에 대한 전반적인 이해가 되셨으리라 믿습니다. 그런데 MySQL의 인덱스는 데이터 저장을 어떻게 구성하나요? 간단한 예로 설명하자면 다음과 같은 데이터 테이블이 있는 경우:
Mysql 코드
CREATE TABLE People(
last_name varchar(50) not null,
first_name varchar(5 0) not null,
dob 날짜는 null이 아님,
성별 enum(`m`,`f`)은 null이 아님,
key(last_name,first_name,dob)
);

표현식의 일부가 될 수도 없고 함수의 매개변수가 될 수도 없음을 의미합니다. 예:
Mysql code2. 접두사 인덱스
열이 매우 긴 경우 일반적으로 일부 문자를 처음부터 인덱스할 수 있으며, 이는 인덱스 공간을 효과적으로 절약하고 인덱스 효율성을 향상시킬 수 있습니다.
3. 다중 열 인덱스 및 인덱스 순서
대부분의 경우 여러 열에 독립 인덱스를 설정해도 쿼리 성능이 향상되지 않습니다. 그 이유는 매우 간단합니다. MySQL은 더 나은 쿼리 효율성을 위해 어떤 인덱스를 선택해야 할지 모르기 때문에 MySQL 5.0 이전 버전에서는 열에 대한 인덱스를 무작위로 선택하는 반면 새 버전에서는 병합 인덱스 전략을 채택합니다. 간단한 예를 들자면, 영화 출연자 목록에서 actor_id 및 film_id 열에 독립 인덱스가 설정되고 다음 쿼리가 있습니다.
Mysql code
MySQL의 이전 버전은 인덱스를 무작위로 선택하지만 새 버전은 다음과 같은 최적화를 수행합니다.
Mysql 코드
앞서 그림에서 볼 수 있듯이 다중 열 인덱스를 사용하는 경우 인덱스의 순서가 쿼리에 중요하다는 것은 분명합니다. 인덱스 앞에 위치하면 조건에 맞지 않는 대부분의 데이터는 첫 번째 필드를 통해 필터링될 수 있습니다.
인용
인덱스 선택성은 데이터 테이블의 총 레코드 수에 대한 고유 인덱스 값의 비율을 의미합니다. 선택성이 높을수록 MySQL은 쿼리할 때 더 많은 행을 필터링할 수 있기 때문입니다. 고유 인덱스의 선택성은 1입니다. 이때 인덱스 선택성이 가장 좋고 성능도 가장 좋습니다.
인덱스 선택성의 개념을 이해한 후에는 어느 필드가 더 선택적인지 결정하는 것은 어렵지 않습니다. 예를 들면 다음과 같습니다.
Mysql 코드
SELECT * Staff_id = 2이고 FROM 결제 customer_id = 584 (staff_id, customer_id) 인덱스를 생성해야 합니까, 아니면 순서를 바꿔야 합니까? 다음 쿼리를 실행하면 필드의 선택도가 1에 더 가까운 것이 먼저 색인화됩니다.
select
count(고유한 직원 ID)/count(*) as Staff_id_selectivity,
count(distinct customer_id)/count(*) as customer_id_selectivity,
대부분의 경우 이 원칙을 사용하면 문제가 없지만, 데이터에 특별한 경우가 있는지 주의하세요. 예를 들어, 특정 사용자 그룹에서 거래한 사용자의 정보를 쿼리하려는 경우:
user_group_id = 1이고 trade_amount >
4. 다중 범위 조건 피하기
실제 개발에서는 종종 다중 범위 조건을 사용합니다. 예를 들어 특정 기간 내에 로그인한 사용자를 쿼리하려는 경우:
Mys 코드
사용자를 선택하세요. * login_time > '2017-04-01'이고 연령이 18세에서 30세 사이인 경우
인덱스가 쿼리해야 하는 모든 필드의 값을 포함하거나 커버하는 경우 쿼리하기 위해 테이블로 돌아갈 필요가 없습니다. . 포함 인덱스는 성능을 크게 향상시킬 수 있는 매우 유용한 도구입니다. 쿼리는 인덱스만 스캔하면 되므로 많은 이점이 있습니다.
인덱스 항목은 데이터 행 크기보다 훨씬 작으므로 인덱스만 읽는 경우 데이터 액세스가 크게 줄어듭니다. amount
인덱스는 열 값 순서로 저장됩니다. I/O 집약적인 범위 쿼리의 경우 디스크에서 각 데이터 행을 무작위로 읽는 것보다 IO가 훨씬 적게 걸립니다.
6. 정렬
인덱스를 설계할 때는 정렬과 쿼리를 모두 만족할 수 있는 인덱스가 가장 좋습니다.
인덱스의 열 순서가 ORDER BY 절의 순서와 완전히 일치하고, 모든 열의 정렬 방향도 동일한 경우에만 인덱스를 사용하여 결과를 정렬할 수 있습니다. 쿼리가 여러 테이블을 연결해야 하는 경우 ORDER BY 절에서 참조하는 모든 필드가 첫 번째 테이블에 있는 경우에만 정렬에 인덱스를 사용할 수 있습니다. ORDER BY 절과 쿼리의 제한 사항은 동일하며, 가장 왼쪽 접두사의 요구 사항을 충족해야 합니다(한 가지 예외가 있는데, 즉 가장 왼쪽 열을 상수로 지정하는 것입니다. 다음은 간단한 예입니다). 그 외의 경우에는 정렬 작업을 수행해야 하며 인덱스 정렬을 사용할 수 없습니다.
Mysql 코드
//가장 왼쪽 열은 상수, 인덱스입니다: (date,staff_id,customer_id)
date = '2015-06-01'인 데모에서 Staff_id,customer_id를 선택하세요. customer_id
7. 중복 및 중복 인덱스
중복 인덱스는 동일한 열에 동일한 순서로 생성된 동일한 유형의 인덱스를 의미하며 이러한 인덱스는 최대한 피하고 발견 후 즉시 삭제해야 합니다. 예를 들어 인덱스(A, B)가 있는 경우 인덱스(A)를 생성하면 중복 인덱스가 됩니다. 예를 들어, 누군가 새 인덱스(A, B)를 생성했지만 이 인덱스는 기존 인덱스(A)를 확장하지 않습니다.
대부분의 경우 새 인덱스를 만드는 대신 기존 인덱스를 확장하는 것이 좋습니다. 그러나 성능을 고려하여 중복 인덱스가 필요한 경우는 드뭅니다. 예를 들어 기존 인덱스를 너무 크게 확장하여 해당 인덱스를 사용하는 다른 쿼리에 영향을 미치는 경우가 있습니다.
8. 오랫동안 사용하지 않은 인덱스 삭제
오랫동안 사용하지 않은 인덱스를 정기적으로 삭제하는 것은 매우 좋은 습관입니다.
인덱싱에 관한 주제는 여기서 끝내겠습니다. 마지막으로 인덱싱은 쿼리 속도를 향상시키는 데 있어 인덱싱의 이점이 추가 작업보다 클 때만 사용되는 것이 아니라는 점을 말씀드리고 싶습니다. 그것은 효과적입니다. 매우 작은 테이블의 경우 간단한 전체 테이블 스캔이 더 효율적입니다. 중대형 테이블의 경우 인덱스가 매우 효과적입니다. 매우 큰 테이블의 경우 인덱스 생성 및 유지 관리 비용이 증가하므로 분할된 테이블과 같은 다른 기술이 더 효과적일 수 있습니다. 마지막으로, 시험을 보기 전에 설명을 해주는 것이 미덕이다.
쿼리 최적화의 특정 유형
COUNT() 쿼리 최적화
COUNT()는 가장 오해되는 함수일 수 있습니다. 하나는 특정 열의 값 수를 계산하는 것입니다. 다른 하나는 특정 열의 값 수를 계산하는 것입니다. 두 번째는 행 수를 계산하는 것입니다. 컬럼 값을 계산할 때 컬럼 값은 Null이 아니어야 하며 NULL은 계산되지 않습니다. 괄호 안의 표현식을 비워둘 수 없음을 확인하면 실제로 행 수를 계산하는 것입니다. 가장 간단한 점은 COUNT(*)를 사용할 때 우리가 상상했던 것처럼 모든 열로 확장되지 않는다는 것입니다. 실제로 모든 열을 무시하고 모든 행을 직접 계산합니다.
여기서 가장 흔히 저지르는 오해는 열을 괄호 안에 지정했지만 통계 결과를 행 수로 기대하고 전자의 성능이 더 좋을 것이라고 잘못 믿는 경우가 많습니다. 그러나 실제로는 그렇지 않습니다. 행 수를 계산하려면 COUNT(*)를 직접 사용하면 의미가 명확하고 성능이 더 좋습니다.
때때로 일부 비즈니스 시나리오에서는 완전히 정확한 COUNT 값이 필요하지 않으며 대략적인 값으로 대체될 수 있습니다. EXPLAIN의 행 수는 좋은 근사치이며 EXPLAIN을 실행하는 데 실제로 쿼리를 실행할 필요가 없으므로 비용이 발생합니다. 매우 낮습니다. 일반적으로 COUNT()를 실행하려면 정확한 데이터를 얻기 위해 많은 수의 행을 스캔해야 하므로 MySQL 수준에서 수행할 수 있는 유일한 작업은 인덱스를 다루는 것뿐입니다. 문제를 해결할 수 없는 경우 요약 테이블을 추가하거나 redis와 같은 외부 캐시 시스템을 사용하는 등 아키텍처 수준에서만 해결할 수 있습니다.
관련 쿼리 최적화
빅 데이터 시나리오에서 테이블은 중복 필드를 통해 관련되어 JOIN을 직접 사용하는 것보다 성능이 더 좋습니다. 관련 쿼리를 꼭 사용해야 하는 경우에는 다음 사항에 특히 주의해야 합니다.
ON 및 USING 절의 열에 인덱스가 있는지 확인하세요. 인덱스를 생성할 때 연결 순서를 고려해야 합니다. 테이블 A와 테이블 B를 컬럼 c를 사용하여 연관시킬 때 옵티마이저 연관 순서가 A, B이면 테이블 A의 해당 컬럼에 인덱스를 생성할 필요가 없습니다. 사용하지 않는 인덱스는 추가 부담을 가져옵니다. 일반적으로 다른 이유가 없는 한 연결 순서에서 두 번째 테이블의 해당 열에만 인덱스를 생성하면 됩니다(구체적인 이유는 아래에서 분석됩니다).
MySQL이 최적화를 위해 인덱스를 사용할 수 있도록 GROUP BY 및 ORDER BY의 모든 표현식은 한 테이블의 열만 포함하는지 확인하세요.
관련 쿼리 최적화의 첫 번째 팁을 이해하려면 MySQL이 관련 쿼리를 수행하는 방법을 이해해야 합니다. 현재 MySQL 연결 실행 전략은 매우 간단합니다. 모든 연결에 대해 중첩 루프 연결 작업을 수행합니다. 즉, 먼저 테이블의 단일 데이터를 루프 아웃한 다음 중첩 루프의 다음 테이블에서 일치하는 행을 검색합니다. , 등, 일치하는 behavior가 모든 테이블에서 발견될 때까지. 그러면 각 테이블의 일치하는 행을 기준으로 쿼리에 필요한 열이 반환됩니다.
너무 추상적인가요? 위의 예를 들어 설명하자면 다음과 같은 쿼리가 있습니다.
Mysql code
SELECT A.xx,B.yy
FROM A INNER JOIN B USING(c)
WHERE A. xx IN (5,6)
MySQL이 쿼리의 연관 순서 A와 B에 따라 연관 작업을 수행한다고 가정하면 다음 의사 코드를 사용하여 MySQL이 이 쿼리를 완료하는 방법을 나타낼 수 있습니다.
Mysql 코드
outer_iterator = A.xx IN(5,6)에서 A.xx,A.c를 선택합니다.
outer_row = external_iterator.next
while( 외부 행) {
inner_iterator = SELECT B.yy FROM B WHERE B.c = external_row.c;
inner_row = inner_iterator.next;
while(inner_row) {
출력 _row.yy,outer_row .xx];
페이징 작업이 필요한 경우 일반적으로 LIMIT와 오프셋을 사용하고 동시에 적절한 ORDER BY 절을 추가하여 구현됩니다. 해당 인덱스가 있으면 일반적으로 효율성이 좋습니다. 그렇지 않으면 MySQL은 많은 파일 정렬 작업을 수행해야 합니다.
일반적인 문제는 오프셋이 매우 큰 경우입니다. 예를 들어 LIMIT 10000 20과 같은 쿼리의 경우 MySQL은 1
002
이런 종류의 쿼리를 최적화하는 가장 간단한 방법 중 하나는 모든 열을 쿼리하는 대신 커버링 인덱스 스캔을 최대한 많이 사용하는 것입니다. 그런 다음 필요에 따라 관련 쿼리를 수행하고 모든 열을 반환합니다. 오프셋이 크면 효율성이 크게 향상됩니다. 다음 쿼리를 고려하십시오.
Mysql code
SELECT film_id,description FROM film ORDER BY title LIMIT 50,5;
이 테이블이 매우 큰 경우 이 쿼리는 다음과 같이 변경하는 것이 가장 좋습니다.
Mysql 코드
SELECT film.film_id,film.description
FROM film INNER JOIN (
) SELECT film_id FROM film ORDER BY title LIMIT 5 0,5
) AS tmp 사용 ( film_id);
사용을 피할 수 있습니다. 다음 쿼리:
이 다음으로 변경되었습니다.
다른 최적화 방법에는 미리 계산된 요약 테이블을 사용하거나 기본 키 열과 정렬해야 하는 열만 포함된 중복 테이블에 연결하는 것이 포함됩니다.
UNION 최적화
MySQL의 UNION 처리 전략은 먼저 임시 테이블을 생성한 후 각 쿼리 결과를 임시 테이블에 삽입하고 마지막으로 쿼리를 수행하는 것입니다. 따라서 UNION 쿼리에서는 많은 최적화 전략이 제대로 작동하지 않습니다. 최적화 프로그램이 이러한 조건을 최대한 활용하여 먼저 최적화할 수 있도록 WHERE, LIMIT, ORDER BY 및 기타 절을 각 하위 쿼리에 수동으로 "푸시다운"해야 하는 경우가 많습니다.
중복 제거를 위해 서버가 꼭 필요한 경우가 아니라면 UNION ALL을 사용해야 합니다. ALL 키워드가 없으면 MySQL은 임시 테이블에 DISTINCT 옵션을 추가하므로 전체 임시 테이블의 데이터가 고유하게 됩니다. 확인하세요. 가격이 매우 높습니다. 물론, ALL 키워드를 사용하더라도 MySQL은 항상 결과를 임시 테이블에 넣은 다음 읽어온 다음 클라이언트에 반환합니다. 예를 들어, 이는 많은 경우에 필요하지 않지만 때로는 각 하위 쿼리의 결과가 클라이언트에 직접 반환될 수 있습니다.
결론
최적화 프로세스에 대한 지식과 함께 쿼리가 실행되는 방식과 시간이 소요되는 위치를 이해하면 모든 사람이 MySQL을 더 잘 이해하고 일반적인 최적화 기술 뒤에 있는 원칙을 이해하는 데 도움이 될 수 있습니다. 이 글의 원리와 사례가 이론과 실제를 더 잘 연결하고 더 많은 이론적 지식을 실제에 적용하는 데 도움이 되기를 바랍니다.
더 이상 드릴 말씀이 없습니다. 두 가지 질문을 남겨드리겠습니다. 머리 속으로 답을 생각해 보세요. 모두가 자주 이야기하지만 그 이유를 생각하는 사람은 거의 없습니다.
공유할 때 이러한 관점을 버리는 프로그래머가 많습니다. 저장 프로시저를 사용하지 마세요. 저장 프로시저는 유지 관리가 매우 어렵고 사용 비용이 증가합니다. 고객. . 클라이언트가 이러한 작업을 수행할 수 있는데 왜 저장 프로시저가 필요한가요?
JOIN 자체도 매우 편리합니다. 왜 뷰가 필요한가요?
[1] 작성: Jiang Chengyao, MySQL Technology Insider-InnoDB Storage Engine, 2013
[2] Baron Scbwartz 외, 번역: ; 고성능 MySQL(제3판); Electronic Industry Press, 2013
[3] B-/B+ 트리에서 MySQL 인덱스 구조 보기
위 내용은 MySQL 최적화 원칙의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



