

효율적인 코드 작성 (1) 배열과 컬렉션에 대하여
목차 읽기
제안 65: 기본 유형 배열 변환 목록 함정을 피하세요
제안 66: asList 메소드로 생성된 List 객체는 변경할 수 없습니다
제안 67: 다른 것을 선택하세요 다른 목록에 대한 목록 순회 알고리즘
권장 사항 68: 자주 삽입하고 삭제할 때 LinkList를 사용하세요.
권장 사항 69: 목록 동일성은 요소 데이터에만 관심이 있습니다.
권장 사항 65: 기본 유형을 피하세요. 배열 변환 목록 트랩
우리는 개발 중에 목록과 목록 사이를 변환하기 위해 배열과 컬렉션이라는 두 가지 도구 클래스를 자주 사용합니다. 이는 매우 편리하지만 때로는 이상한 문제가 발생할 수 있습니다.

1 public class Client65 {
2 public static void main(String[] args) {
3 int data [] = {1,2,3,4,5};
4 List list= Arrays.asList(data);
5 System.out.println("列表中的元素数量是:"+list.size());
6 }
7 }
아마도 이것은 매우 간단하다고 말할 것입니다. 물론 목록 변수의 요소 수는 5입니다. 하지만 실행 후 출력되는 목록의 개수는 1개입니다.
사실 데이터는 5개의 요소로 구성된 int형 배열인데, asList를 통해 리스트로 변환하고 나면 요소가 1개밖에 남지 않는 이유는 무엇일까요? 나머지 4개 요소는 어디로 갔나요?
Arrays.asList의 메소드 설명을 자세히 살펴보겠습니다. 가변 길이 매개변수를 입력하고 고정 길이 목록을 반환합니다. 이는 가변 길이 매개변수입니다. 소스 코드를 참조하세요.
public static <t> List<t> asList(T... a) {
return new ArrayList(a);
}</t></t>asList 메소드의 입력은 일반 가변 길이 매개변수이며 기본 유형은 일반화할 수 없다는 것을 알고 있습니다. 즉, 8가지 기본 유형이 있습니다. 제네릭으로 사용할 수 없습니다. 매개변수를 일반 매개변수로 사용하려면 해당 패키징 유형을 사용해야 합니다. 이전 예에서 프로그램이 컴파일 오류를 보고하지 않은 이유는 무엇입니까?
Java에서 배열은 객체이고 일반화될 수 있습니다. 즉, 이 예에서는 int 유형의 배열이 T의 유형으로 사용되므로 변환 후에는 하나의 유형만 있게 됩니다. int 배열의 요소를 인쇄하여 살펴보겠습니다. 코드는 다음과 같습니다.

1 public class Client65 {
2 public static void main(String[] args) {
3 int data [] = {1,2,3,4,5};
4 List list= Arrays.asList(data);
5 System.out.println("元素类型是:"+list.get(0).getClass());
6 System.out.println("前后是否相等:"+data.equals(list.get(0)));
7 }
8 }
출력 결과는 다음과 같습니다. 요소 유형은: class [ I 앞면과 뒷면이 같은지 여부: true
분명히 목록에 배치된 요소는 int 배열입니다. 누군가는 "element type:" 다음의 클래스가 "[I"인 이유는 무엇입니까? 배열 유형을 지정하지 않았습니다! Array는 리플렉션을 통해 배열 요소에 접근하기 위한 툴 클래스인 java.lang.reflect 패키지에 속해 있기 때문에 JVM에서는 Array 타입을 출력하는 것이 불가능하기 때문이다. Java에서 1차원 배열의 유형은 "[I"입니다. 그 이유는 Java가 배열 클래스를 정의하지 않기 때문입니다. 이는 컴파일 중에 컴파일러에 의해 생성되며 JDK에는 이에 대한 정보가 없습니다. 도움말의 배열 클래스 중 하나입니다.
문제를 알아냈고 수정하기 쉽습니다. 패키징 클래스를 직접 사용하면 됩니다. 코드의 일부는 다음과 같습니다.
Integer data [] = {1,2,3,4,5};int를 Integer로 바꾸어 출력 요소 수를 5로 만듭니다. int 유형의 배열에만 이 문제가 있는 것이 아니라 다른 7가지 기본 유형의 배열에도 비슷한 문제가 있습니다. 이는 기본 유형 배열을 목록으로 변환할 때 프로그램을 피하기 위해 asList 메소드의 트랩에 특히 주의해야 합니다. 논리.
참고: 기본 유형 배열은 asList의 입력 매개변수로 사용할 수 없습니다. 그렇지 않으면 프로그램 논리에 혼란이 발생할 수 있습니다.
제안 66: asList 메소드로 생성된 List 객체는 변경할 수 없습니다.
이전 제안에서는 기본 유형 배열 변환 시 asList 메소드의 문제점을 지적했습니다. asList 메소드에 의해 반환된 목록, 코드는 다음과 같습니다:

1 public class Client66 {
2 public static void main(String[] args) {
3 // 五天工作制
4 Week days[] = { Week.Mon, Week.Tue, Week.Wed, Week.Thu, Week.Fri };
5 // 转换为列表
6 List<week> list = Arrays.asList(days);
7 // 增加周六为工作日
8 list.add(Week.Sat);
9 /* do something */
10 }
11 }
12 enum Week {
13 Sun, Mon, Tue, Wed, Thu, Fri, Sat
14 }</week>
很简单的程序呀,默认声明的工作日(workDays)是从周一到周五,偶尔周六也会算作工作日加入到工作日列表中,不过,这段程序执行时会不会有什么问题呢?编译没有任何问题,但是一运行,却出现了如下结果:
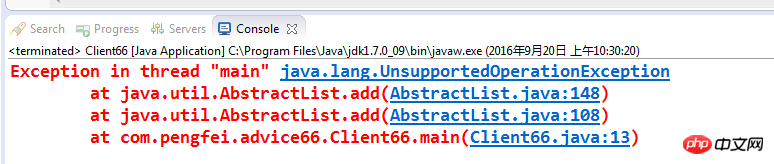
UnsupportedOperationException,不支持的操作,居然不支持list的add方法,这是什么原因呢?我们看看asList方法的源代码:
public static <t> List<t> asList(T... a) {
return new ArrayList(a);
}</t></t>直接new了一个ArrayList对象返回,难道ArrayList不支持add方法,不可能呀!可能,问题就出现在这个ArrayList类上,此ArrayList非java.util.ArrayList,而是Arrays工具类的一个内部类,其构造函数如下所示:

1 private static class ArrayList<e> extends AbstractList<e>
2 implements RandomAccess, java.io.Serializable
3 {
4 private static final long serialVersionUID = -2764017481108945198L;
5 private final E[] a;
6
7 ArrayList(E[] array) {
8 if (array==null)
9 throw new NullPointerException();
10 a = array;
11 }
12 /*其它方法略*/
13 }</e></e>
这个ArrayList是一个静态私有内部类,除了Arrays能访问外,其它类都不能访问,仔细看这个类,它没有提供add方法,那肯定是父类AbstractList提供了,来看代码:

1 public boolean add(E e) {
2 add(size(), e);
3 return true;
4 }
5
6 public void add(int index, E element) {
7 throw new UnsupportedOperationException();
8 }
父类确实提供了,但没有提供具体的实现,所以每个子类都需要自己覆写add方法,而Arrays的内部类ArrayList没有覆写,因此add一个元素就报错了。
我们深入地看看这个ArrayList静态内部类,它仅仅实现了5个方法:
size:元素数量
get:获得制定元素
set:重置某一元素值
contains:是否包含某元素
toArray:转化为数组,实现了数组的浅拷贝
把这几个方法的源代码展示一下:

1 //元素数量
2 public int size() {
3 return a.length;
4 }
5
6 public Object[] toArray() {
7 return a.clone();
8 }
9 //转化为数组,实现了数组的浅拷贝
10 public <t> T[] toArray(T[] a) {
11 int size = size();
12 if (a.length ) a.getClass());
15 System.arraycopy(this.a, 0, a, 0, size);
16 if (a.length > size)
17 a[size] = null;
18 return a;
19 }
20 //获得指定元素
21 public E get(int index) {
22 return a[index];
23 }
24 //重置某一元素
25 public E set(int index, E element) {
26 E oldValue = a[index];
27 a[index] = element;
28 return oldValue;
29 }
30
31 public int indexOf(Object o) {
32 if (o==null) {
33 for (int i=0; i<a.length><div class="cnblogs_code_toolbar"><span class="cnblogs_code_copy"><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/001/10e7d93a4ad9e6e22a94ae46c1beee95-12.gif" class="lazy" alt="효율적인 코드 작성 (1) 배열과 컬렉션에 대하여"></span></div></a.length></t>对于我们经常使用list.add和list.remove方法它都没有实现,也就是说asList返回的是一个长度不可变的列表,数组是多长,转换成的列表也就是多长,换句话说此处的列表只是数组的一个外壳,不再保持列表的动态变长的特性,这才是我们关注的重点。有些开发人员喜欢这样定义个初始化列表:
List<string> names= Arrays.asList("张三","李四","王五");</string>一句话完成了列表的定义和初始化,看似很便捷,却隐藏着重大隐患---列表长度无法修改。想想看,如果这样一个List传递到一个允许添加的add操作的方法中,那将会产生何种结果,如果有这种习惯的javaer,请慎之戒之,除非非常自信该List只用于只读操作。
建议67:不同的列表选择不同的遍历算法
我们思考这样一个案例:统计一个省的各科高考平均值,比如数学平均分是多少,语文平均分是多少等,这是每年招生办都会公布的数据,我们来想想看该算法应如何实现。当然使用数据库中的一个SQL语句就可能求出平均值,不过这不再我们的考虑之列,这里还是使用纯Java的算法来解决之,看代码:

1 public class Client67 {
2 public static void main(String[] args) {
3 // 学生数量 80万
4 int stuNum = 80 * 10000;
5 // List集合,记录所有学生的分数
6 List<integer> scores = new ArrayList<integer>(stuNum);
7 // 写入分数
8 for (int i = 0; i scores) {
19 int sum = 0;
20 // 遍历求和
21 for (int i : scores) {
22 sum += i;
23 }
24 return sum / scores.size();
25 }
26 }</integer></integer>
把80万名学生的成绩放到一个ArrayList数组中,然后通过foreach方法遍历求和,再计算平均值,程序很简单,输出结果:
平均分是:74
执行时间:11ms
仅仅计算一个算术平均值就花了11ms,不要说什么其它诸如加权平均值,补充平均值等算法,那花的时间肯定更长。我们仔细分析一下average方法,加号操作是最基本的,没有什么可以优化的,剩下的就是一个遍历了,问题是List的遍历可以优化吗?
我们尝试一下,List的遍历还有另外一种方式,即通过下标方式来访问,代码如下:

1 public static int average(List<integer> scores) {
2 int sum = 0;
3 // 遍历求和
4 for (int i = 0; i <div class="cnblogs_code_toolbar"><span class="cnblogs_code_copy"><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/001/10e7d93a4ad9e6e22a94ae46c1beee95-16.gif" class="lazy" alt="효율적인 코드 작성 (1) 배열과 컬렉션에 대하여"></span></div></integer>不再使用foreach遍历,而是采用下标方式遍历,我们看看输出结果:
平均分是:74
执行时间:8ms
执行时间已经下降,如果数据量更大,会更明显。那为什么我们使用下标方式遍历数组可以提高的性能呢?
这是因为ArrayList数组实现了RandomAccess接口(随机存取接口),这样标志着ArrayList是一个可以随机存取的列表。在Java中,RandomAccess和Cloneable、Serializable一样,都是标志性接口,不需要任何实现,只是用来表明其实现类具有某种特质的,实现了Cloneable表明可以被拷贝,实现了Serializable接口表明被序列化了,实现了RandomAccess接口则表明这个类可以随机存取,对我们的ArrayList来说也就标志着其数据元素之间没有关联,即两个位置相邻的元素之间没有相互依赖和索引关系,可以随机访问和存取。我们知道,Java的foreach语法时iterator(迭代器)的变形用法,也就是说上面的foreach与下面的代码等价:
for (Iterator<integer> i = scores.iterator(); i.hasNext();) {
sum += i.next();
}</integer>那我们再想想什么是迭代器,迭代器是23中设计模式中的一种,"提供一种方法访问一个容器对象中的各个元素,同时又无须暴露该对象的内部细节",也就是说对于ArrayList,需要先创建一个迭代器容器,然后屏蔽内部遍历细节,对外提供hasNext、next等方法。问题是ArrayList实现RandomAccess接口,表明元素之间本来没有关系,可是,为了使用迭代器就需要强制建立一种相互"知晓"的关系,比如上一个元素可以判断是否有下一个元素,以及下一个元素时什么等关系,这也就是foreach遍历耗时的原因。
Java的ArrayList类加上了RandomAccess接口,就是在告诉我们,“ArrayList是随机存取的,采用下标方式遍历列表速度回更快”,接着又有一个问题,为什么不把RandomAccess接口加到所有List的实现类上呢?
那是因为有些List的实现类不是随机存取的,而是有序存取的,比如LinkedList类,LinkedList类也是一个列表,但它实现了双向链表,每个数据节点都有三个数据项:前节点的引用(Previous Node)、本节点元素(Node Element)、后继结点的引用(Next Node),这是数据结构的基本知识,不多讲了,也就是说在LinkedList中的两个元素本来就是有关联的,我知道你的存在,你也知道我的存在。那大家想想看,元素之间已经有关联了,使用foreach也就是迭代器方式是不是效率更高呢?我们修改一下例子,代码如下:

1 public static void main(String[] args) {
2 // 学生数量 80万
3 int stuNum = 80 * 10000;
4 // List集合,记录所有学生的分数
5 List<integer> scores = new LinkedList<integer>();
6 // 写入分数
7 for (int i = 0; i scores) {
18 int sum = 0;
19 // 遍历求和
20 for (int i : scores) {
21 sum += i;
22 }
23 return sum / scores.size();
24 }</integer></integer>
输出结果为: 平均分是:74 执行时间:12ms 。执行效率还好。但是比ArrayList就慢了,但如果LinkedList采用下标方式遍历:效率会如何呢?我告诉你会很慢。直接分析一下源码:
1 public E get(int index) {
2 checkElementIndex(index);
3 return node(index).item;
4 }由node方法查找指定下标的节点,然后返回其包含的元素,看node方法:

1 Node<e> node(int index) {
2 // assert isElementIndex(index);
3
4 if (index > 1)) {
5 Node<e> x = first;
6 for (int i = 0; i x = last;
11 for (int i = size - 1; i > index; i--)
12 x = x.prev;
13 return x;
14 }
15 }</e></e>
看懂了吗?程序会先判断输入的下标与中间值(size右移一位,也就是除以2了)的关系,小于中间值则从头开始正向搜索,大于中间值则从尾节点反向搜索,想想看,每一次的get方法都是一个遍历,"性能"两字从何说去呢?
明白了随机存取列表和有序存取列表的区别,我们的average方法就必须重构了,以便实现不同的列表采用不同的遍历方式,代码如下:

1 public static int average(List<integer> scores) {
2 int sum = 0;
3
4 if (scores instanceof RandomAccess) {
5 // 可以随机存取,则使用下标遍历
6 for (int i = 0; i <div class="cnblogs_code_toolbar"><span class="cnblogs_code_copy"><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/001/f643995e92903b9d3b9c1026c06966b3-22.gif" class="lazy" alt="효율적인 코드 작성 (1) 배열과 컬렉션에 대하여"></span></div></integer>如此一来,列表的遍历就可以"以不变应万变"了,无论是随机存取列表还是有序列表,它都可以提供快速的遍历。
注意:列表遍历不是那么简单的,适时选择最优的遍历方式,不要固化为一种。
建议68:频繁插入和删除时使用LinkList
上一个建议介绍了列表的遍历方式,也就是“读” 操作,本建议将介绍列表的"写"操作:即插入、删除、修改动作。
(1)、插入元素:列表中我们使用最多的是ArrayList,下面来看看它的插入(add方法)算法,源代码如下:

1 public void add(int index, E element) {
2 //检查下标是否越界
3 rangeCheckForAdd(index);
4 //若需要扩容,则增大底层数组的长度
5 ensureCapacityInternal(size + 1); // Increments modCount!!
6 //给index下标之后的元素(包括当前元素)的下标加1,空出index位置
7 System.arraycopy(elementData, index, elementData, index + 1,
8 size - index);
9 //赋值index位置元素
10 elementData[index] = element;
11 //列表长度加1
12 size++;
13 }
注意看arrayCopy方法,只要插入一个元素,其后的元素就会向后移动一位,虽然arrayCopy是一个本地方法,效率非常高,但频繁的插入,每次后面的元素都要拷贝一遍,效率就更低了,特别是在头位置插入元素时,现在的问题是,开发中确实会遇到要插入的元素的情况,哪有什么更好的方法解决此效率问题吗?
有,使用LinkedList即可。我么知道LinkedList是一个双向列表,它的插入只是修改了相邻元素的next和previous引用,其插入算法(add方法)如下:

1 public void add(int index, E element) {
2 checkPositionIndex(index);
3
4 if (index == size)
5 linkLast(element);
6 else
7 linkBefore(element, node(index));
8 }

1 void linkLast(E e) {
2 final Node<e> l = last;
3 final Node<e> newNode = new Node(l, e, null);
4 last = newNode;
5 if (l == null)
6 first = newNode;
7 else
8 l.next = newNode;
9 size++;
10 modCount++;
11 }</e></e>

1 void linkBefore(E e, Node<e> succ) {
2 // assert succ != null;
3 final Node<e> pred = succ.prev;
4 final Node<e> newNode = new Node(pred, e, succ);
5 succ.prev = newNode;
6 if (pred == null)
7 first = newNode;
8 else
9 pred.next = newNode;
10 size++;
11 modCount++;
12 }</e></e></e>
这个方法,第一步检查是否越界,下来判断插入元素的位置与列表的长度比较,如果相等,调用linkLast,否则调用linkBefore方法。但这两个方法的共同点都是双向链表插入算法,把自己插入到链表,然后再把前节点的next和后节点的previous指向自己。想想看,这样插入一个元素的过程中,没有任何元素会有拷贝过程,只是引用地址变了,那效率自然就高了。
(2)、删除元素:插入了解清楚了,我们再来看看删除动作。ArrayList提供了删除指定位置上的元素,删除指定元素,删除一个下标范围内的元素集等删除动作。三者的实现原理基本相似,都是找索引位置,然后删除。我们以最常用的删除指定下标的方法(remove方法)为例来看看删除动作的性能到底如何,源码如下:

1 public E remove(int index) {
2 //下标校验
3 rangeCheck(index);
4 //修改计数器加1
5 modCount++;
6 //记录要删除的元素
7 E oldValue = elementData(index);
8 //有多少个元素向前移动
9 int numMoved = size - index - 1;
10 if (numMoved > 0)
11 //index后的元素向前移动一位
12 System.arraycopy(elementData, index+1, elementData, index,
13 numMoved);
14 //列表长度减1
15 elementData[--size] = null; // Let gc do its work
16 //返回删除的值
17 return oldValue;
18 }
注意看,index位置后的元素都向前移动了一位,最后一个位置空出来了,这又是一个数组拷贝,和插入一样,如果数据量大,删除动作必然会暴露出性能和效率方面的问题。ArrayList其它的两个删除方法与此类似,不再赘述。
我么再来看LinkedList的删除动作。LinkedList提供了非常多的删除操作,比如删除指定位置元素,删除头元素等,与之相关的poll方法也会执行删除动作,下面来看最基本的删除指定位置元素的方法remove,源代码如下:
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
1 E unlink(Node<e> x) {
2 // assert x != null;
3 final E element = x.item;
4 final Node<e> next = x.next;
5 final Node<e> prev = x.prev;
6
7 if (prev == null) {
8 first = next;
9 } else {
10 prev.next = next;
11 x.prev = null;
12 }
13
14 if (next == null) {
15 last = prev;
16 } else {
17 next.prev = prev;
18 x.next = null;
19 }
20
21 x.item = null;
22 size--;
23 modCount++;
24 return element;
25 }</e></e></e>

1 private static class Node<e> {
2 E item;
3 Node<e> next;
4 Node<e> prev;
5
6 Node(Node<e> prev, E element, Node<e> next) {
7 this.item = element;
8 this.next = next;
9 this.prev = prev;
10 }
11 }</e></e></e></e></e>
这也是双向链表标准删除算法,没有任何耗时的操作,全部都是引用指针的变更,效率自然高了。
(3)、修改元素:写操作还有一个动作,修改元素值,在这一点上LinkedList输给了ArrayList,这是因为LinkedList是按顺序存储的,因此定位元素必然是一个遍历过程,效率大打折扣,我们来看Set方法的代码:

1 public E set(int index, E element) {
2 checkElementIndex(index);
3 //定位节点
4 Node<e> x = node(index);
5 E oldVal = x.item;
6 //节点元素替换
7 x.item = element;
8 return oldVal;
9 }</e>
看似很简洁,但是这里使用了node方法定位元素,上一个建议中我们已经说明了LinkedList这种顺序存取列表的元素定位方式会折半遍历,这是一个极耗时的操作,而ArrayList的修改动作则是数组元素的直接替换,简单高效。
在修改动作上,LinkedList比ArrayList慢很多,特别是要进行大量的修改时,两者完全不在一个数量级上。
上面通过分析源码完成了LinkedList与ArrayList之间的PK,其中LinkedList胜两局:删除和插入效率高;ArrayList胜一局:修改元素效率高。总体来说,在写方面LinkedList占优势,而且在实际使用中,修改是一个比较少的动作。因此有大量写的操作(更多的是插入和删除),推荐使用LinkedList。不过何为少量?何为大量呢?
这就依赖于咱们在开发中系统了,具体情况具体分析了。
建议69:列表相等只关心元素数据
我们来看一个比较列表相等的例子,代码如下:

1 public class Client69 {
2 public static void main(String[] args) {
3 ArrayList<string> strs = new ArrayList<string>();
4 strs.add("A");
5
6 Vector<string> strs2 = new Vector<string>();
7 strs2.add("A");
8
9 System.out.println(strs.equals(strs2));
10 }
11 }</string></string></string></string>
两个类都不同,一个是ArrayList,一个是Vector,那结果肯定不相等了。真是这样吗?但其实结果为true,也就是两者相等。
我们分析一下,两者为何相等,两者都是列表(List),都实现了List接口,也都继承了AbstractList抽象类,其equals方法是在AbstractList中定义的,我们来看源代码:

1 public boolean equals(Object o) {
2 if (o == this)
3 return true;
4 //是否是列表,注意这里:只要实现List接口即可
5 if (!(o instanceof List))
6 return false;
7 //通过迭代器访问List的所有元素
8 ListIterator<e> e1 = listIterator();
9 ListIterator e2 = ((List) o).listIterator();
10 //遍历两个List的元素
11 while (e1.hasNext() && e2.hasNext()) {
12 E o1 = e1.next();
13 Object o2 = e2.next();
14 //只要存在着不相等就退出
15 if (!(o1==null ? o2==null : o1.equals(o2)))
16 return false;
17 }
18 //长度是否也相等
19 return !(e1.hasNext() || e2.hasNext());
20 }</e>
看到没,这里只要实现了List接口就成,它不关心List的具体实现类,只要所有元素相等,并且长度也相等就表明两个List是相等的,与具体的容量类型无关。也就是说,上面的例子虽然一个是Arraylist,一个是Vector,只要里面的元素相等,那结果也就相等。
Java如此处理也确实是在为开发者考虑,列表只是一个容器,只要是同一种类型的容器(如List),不用关心,容器的细节差别,只要确定所有的元素数据相等,那这两个列表就是相等的,如此一来,我们在开发中就不用太关注容器的细节了,可以把注意力更多地放在数据元素上,而且即使中途重构容器类型,也不会对相等的判断产生太大的影响。
其它的集合类型,如Set、Map等于此相同,也是只关心集合元素,不用考虑集合类型。
注意:判断集合是否相等时只须关注元素是否相等即可。
위 내용은 효율적인 코드 작성 (1) 배열과 컬렉션에 대하여의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7461
7461
 15
1376
52
77
11
44
19
17
17
15
1376
52
77
11
44
19
17
17

 win7 드라이버 코드 28을 해결하는 방법
Dec 30, 2023 pm 11:55 PM
win7 드라이버 코드 28을 해결하는 방법
Dec 30, 2023 pm 11:55 PM
일부 사용자는 장치를 설치할 때 오류 코드 28을 표시하는 오류가 발생했습니다. 실제로 이는 주로 드라이버 때문입니다. win7 드라이버 코드 28의 문제만 해결하면 됩니다. 수행해야 할 작업을 살펴보겠습니다. 그것. win7 드라이버 코드 28로 수행할 작업: 먼저 화면 왼쪽 하단에 있는 시작 메뉴를 클릭해야 합니다. 그런 다음 팝업 메뉴에서 "제어판" 옵션을 찾아 클릭하세요. 이 옵션은 일반적으로 메뉴 하단이나 그 근처에 있습니다. 클릭하면 시스템이 자동으로 제어판 인터페이스를 엽니다. 제어판에서는 다양한 시스템 설정 및 관리 작업을 수행할 수 있습니다. 이것이 향수 청소 수준의 첫 번째 단계입니다. 도움이 되기를 바랍니다. 그런 다음 계속해서 시스템에 들어가야 합니다.
 블루 스크린 코드 0x0000001이 발생하는 경우 대처 방법
Feb 23, 2024 am 08:09 AM
블루 스크린 코드 0x0000001이 발생하는 경우 대처 방법
Feb 23, 2024 am 08:09 AM
블루 스크린 코드 0x0000001로 수행할 작업 블루 스크린 오류는 컴퓨터 시스템이나 하드웨어에 문제가 있을 때 나타나는 경고 메커니즘입니다. 코드 0x0000001은 일반적으로 하드웨어 또는 드라이버 오류를 나타냅니다. 사용자가 컴퓨터를 사용하는 동안 갑자기 블루 스크린 오류가 발생하면 당황하고 당황할 수 있습니다. 다행히도 대부분의 블루 스크린 오류는 몇 가지 간단한 단계를 통해 문제를 해결하고 처리할 수 있습니다. 이 기사에서는 독자들에게 블루 스크린 오류 코드 0x0000001을 해결하는 몇 가지 방법을 소개합니다. 먼저, 블루 스크린 오류가 발생하면 다시 시작해 보세요.
 컴퓨터에 블루 스크린이 자주 발생하고 코드가 매번 다릅니다.
Jan 06, 2024 pm 10:53 PM
컴퓨터에 블루 스크린이 자주 발생하고 코드가 매번 다릅니다.
Jan 06, 2024 pm 10:53 PM
win10 시스템은 매우 뛰어난 지능 시스템으로 사용자에게 최고의 사용자 경험을 제공할 수 있습니다. 정상적인 상황에서는 사용자의 win10 시스템 컴퓨터에 아무런 문제가 없습니다! 그러나 우수한 컴퓨터에서는 다양한 오류가 발생하는 것은 불가피합니다. 최근 친구들은 win10 시스템에서 블루 스크린이 자주 발생한다고 보고했습니다. 오늘 편집자는 Windows 10 컴퓨터에서 자주 블루 스크린을 발생시키는 다양한 코드에 대한 솔루션을 제공합니다. 매번 다른 코드로 자주 나타나는 컴퓨터 블루 스크린에 대한 해결 방법: 다양한 오류 코드의 원인 및 해결 방법 제안 1. 0×000000116 오류의 원인: 그래픽 카드 드라이버가 호환되지 않는 것이어야 합니다. 해결책: 원래 제조업체의 드라이버를 교체하는 것이 좋습니다. 2,
 코드 0xc000007b 오류 해결
Feb 18, 2024 pm 07:34 PM
코드 0xc000007b 오류 해결
Feb 18, 2024 pm 07:34 PM
종료 코드 0xc000007b 컴퓨터를 사용하는 동안 때때로 다양한 문제와 오류 코드가 발생할 수 있습니다. 그 중 종료코드가 가장 충격적이며, 특히 종료코드 0xc000007b가 가장 충격적이다. 이 코드는 애플리케이션이 제대로 시작되지 않아 사용자에게 불편을 초래함을 나타냅니다. 먼저 종료코드 0xc000007b의 의미를 알아보겠습니다. 이 코드는 32비트 응용 프로그램이 64비트 운영 체제에서 실행을 시도할 때 일반적으로 발생하는 Windows 운영 체제 오류 코드입니다. 그래야 한다는 뜻이다
 모든 장치에서 GE 범용 원격 코드 프로그램
Mar 02, 2024 pm 01:58 PM
모든 장치에서 GE 범용 원격 코드 프로그램
Mar 02, 2024 pm 01:58 PM
장치를 원격으로 프로그래밍해야 하는 경우 이 문서가 도움이 될 것입니다. 우리는 모든 장치 프로그래밍을 위한 최고의 GE 범용 원격 코드를 공유할 것입니다. GE 리모콘이란 무엇입니까? GEUniversalRemote는 스마트 TV, LG, Vizio, Sony, Blu-ray, DVD, DVR, Roku, AppleTV, 스트리밍 미디어 플레이어 등과 같은 여러 장치를 제어하는 데 사용할 수 있는 리모컨입니다. GEUniversal 리모컨은 다양한 기능과 기능을 갖춘 다양한 모델로 제공됩니다. GEUniversalRemote는 최대 4개의 장치를 제어할 수 있습니다. 모든 장치에서 프로그래밍할 수 있는 최고의 범용 원격 코드 GE 리모컨에는 다양한 장치에서 작동할 수 있는 코드 세트가 함께 제공됩니다. 당신은 할 수있다
 블루 스크린 코드 0x000000d1은 무엇을 나타냅니까?
Feb 18, 2024 pm 01:35 PM
블루 스크린 코드 0x000000d1은 무엇을 나타냅니까?
Feb 18, 2024 pm 01:35 PM
0x000000d1 블루 스크린 코드는 무엇을 의미합니까? 최근 몇 년 동안 컴퓨터의 대중화와 인터넷의 급속한 발전으로 인해 운영 체제의 안정성 및 보안 문제가 점점 더 부각되고 있습니다. 일반적인 문제는 블루 스크린 오류이며, 코드 0x000000d1이 그 중 하나입니다. 블루 스크린 오류 또는 "죽음의 블루 스크린"은 컴퓨터에 심각한 시스템 오류가 발생할 때 발생하는 상태입니다. 시스템이 오류로부터 복구할 수 없는 경우 Windows 운영 체제는 화면에 오류 코드와 함께 블루 스크린을 표시합니다. 이러한 오류 코드
 0x0000007f 블루 스크린 코드의 원인과 해결 방법에 대한 자세한 설명
Dec 25, 2023 pm 02:19 PM
0x0000007f 블루 스크린 코드의 원인과 해결 방법에 대한 자세한 설명
Dec 25, 2023 pm 02:19 PM
블루 스크린은 시스템을 사용할 때 자주 발생하는 문제입니다. 오류 코드에 따라 다양한 원인과 해결 방법이 있습니다. 예를 들어 stop: 0x0000007f 문제가 발생하면 하드웨어 또는 소프트웨어 오류일 수 있습니다. 편집기를 따라 해결책을 찾아보겠습니다. 0x000000c5 블루 스크린 코드 이유: 답변: 메모리, CPU 및 그래픽 카드가 갑자기 오버클럭되었거나 소프트웨어가 잘못 실행되고 있습니다. 해결 방법 1: 1. 부팅할 때 F8을 계속 눌러 들어가고 안전 모드를 선택한 다음 Enter를 눌러 들어갑니다. 2. 안전모드 진입 후 win+r을 눌러 실행창을 열고 cmd를 입력한 후 Enter를 누릅니다. 3. 명령 프롬프트 창에서 "chkdsk /f /r"을 입력하고 Enter를 누른 다음 y 키를 누릅니다. 4.
 Python 그림 학습을 위한 빠른 가이드: 얼음 조각 그리기를 위한 코드 예제
Jan 13, 2024 pm 02:00 PM
Python 그림 학습을 위한 빠른 가이드: 얼음 조각 그리기를 위한 코드 예제
Jan 13, 2024 pm 02:00 PM
Python 그리기를 빠르게 시작하세요: 그리기를 위한 코드 예제 Bingdundun Python은 배우기 쉽고 강력한 프로그래밍 언어입니다. Python의 그리기 라이브러리를 사용하면 다양한 그리기 요구 사항을 쉽게 실현할 수 있습니다. 이 기사에서는 Python의 그리기 라이브러리 matplotlib를 사용하여 간단한 얼음 그래프를 그릴 것입니다. 빙둔둔은 귀여운 이미지를 지닌 판다로 어린이들에게 인기가 매우 높습니다. 먼저 matplotlib 라이브러리를 설치해야 합니다. 터미널에서 실행하면 됩니다.
