객체는 몇 바이트를 차지하나요?
객체의 크기에 관해서 C/C++의 경우 직접 구할 수 있는 sizeof 함수가 있는데, Java에는 그런 방법이 없는 것 같습니다. 다행스럽게도 JDK 1.5 이후에 Instrumentation 클래스가 도입되었습니다. 이 클래스는 객체의 메모리 공간을 계산하는 방법을 제공합니다. 구체적인 Instrumentation 클래스의 사용법에 대해서는 자세히 설명하지 않겠습니다. Java 객체의 크기를 정확하게 측정하는 방법은 이 기사를 참조하세요.
하지만 한 가지 차이점은 이 문서에서는 명령줄을 사용하여 에이전트를 지정하기 위해 JVM 매개 변수를 전달한다는 것입니다. 여기서는 Eclipse를 통해 JVM 매개 변수를 설정했습니다.

다음은 내가 입력한 에이전트입니다. . 항아리의 특정 경로입니다. 나머지에 대해서는 이야기하지 않고 테스트 코드를 살펴보겠습니다.
1 public class JVMSizeofTest { 2 3 @Test 4 public void testSize() { 5 System.out.println("Object对象的大小:" + JVMSizeof.sizeOf(new Object()) + "字节"); 6 System.out.println("字符a的大小:" + JVMSizeof.sizeOf('a') + "字节"); 7 System.out.println("整型1的大小:" + JVMSizeof.sizeOf(new Integer(1)) + "字节"); 8 System.out.println("字符串aaaaa的大小:" + JVMSizeof.sizeOf(new String("aaaaa")) + "字节"); 9 System.out.println("char型数组(长度为1)的大小:" + JVMSizeof.sizeOf(new char[1]) + "字节");10 }11 12 }실행 결과는 다음과 같습니다.
Object对象的大小:16字节 字符a的大小:16字节 整型1的大小:16字节 字符串aaaaa的大小:24字节 char型数组(长度为1)的大小:24字节
그런 다음 코드는 변경되지 않고 가상 머신 매개변수 "- XX:-UseCompressedOops"가 추가되었습니다. 테스트 클래스를 다시 실행하면 결과는 다음과 같습니다.
Object对象的大小:16字节 字符a的大小:24字节 整型1的大小:24字节 字符串aaaaa的大小:32字节 char型数组(长度为1)的大小:32字节
이유는 나중에 자세히 설명하겠습니다.
Java 객체 크기 계산 방법
JVM은 일반 객체와 배열 객체의 크기를 다르게 계산합니다. 설명을 위해 그림을 그렸습니다.
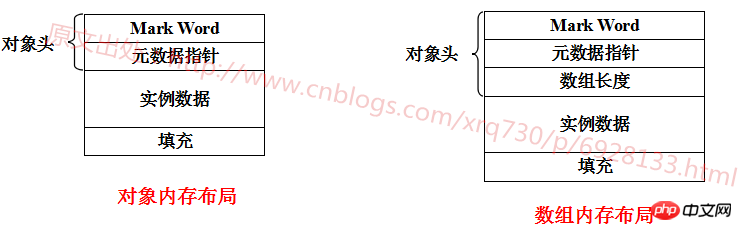
설명을 살펴보겠습니다. 각 부분에서 :
Mark Word : 객체가 저장될 때 정보를 기록하며, 차지하는 메모리 크기는 기계 자릿수와 동일합니다. 즉, 32비트 기계는 4바이트, 64를 차지합니다. -비트 머신은 8바이트를 차지합니다.
메타데이터 포인터: 유형을 설명하는 Klass 객체(Java 클래스의 C++ 대응)에 대한 포인터입니다. Klass 객체에는 인스턴스가 있는 유형의 메타데이터가 포함되어 있습니다. 객체가 속하므로 이 필드를 메타데이터 포인터라고 합니다. JVM은 런타임 중에 메서드 영역에 있는 유형 정보를 찾기 위해 이 포인터를 자주 사용합니다. 이 데이터의 크기는 나중에 논의하겠습니다
배열 길이: 배열 객체에 고유하며 int 유형을 가리키는 참조 유형으로 배열의 길이를 설명하는 데 사용됩니다. 나중에 논의할 메타데이터 포인터의 크기
인스턴스 데이터: 인스턴스 데이터는 8가지 기본 데이터 유형 byte, short, int, long, float, double, char, boolean ( 객체 유형도 이 8가지 기본 데이터 유형으로 구성됩니다.), 각 데이터 유형이 차지하는 바이트 수는 하나씩 나열되지 않습니다
Padding: 변수, HotSpot의 정렬은 8바이트 정렬입니다. 객체는 8바이트의 정수 배수여야 합니다. 따라서 마지막 데이터 크기가 17이면 7로 채우고, 이전 데이터 크기가 18이면 6으로 채우는 식으로
마지막으로 메타데이터 포인터의 크기에 대해 이야기해 보겠습니다. 메타데이터 포인터는 참조 유형이므로 일반적으로 64비트 머신 메타데이터 포인터는 8바이트, 32비트 머신 메타데이터 포인터는 4바이트여야 하지만 HotSpot에는 메타데이터 유형 포인터를 압축하는 최적화가 있습니다. , JVM 매개변수 사용:
-XX:+UseCompressedOops를 사용하여 압축을 설정합니다
-XX:-UseCompressedOops를 사용하여 압축을 해제합니다.
HotSpot의 기본값은 전자입니다. 메타데이터 포인터 압축에 대해 압축이 활성화되면 메타데이터 포인터는 64비트 시스템에서 4바이트를 차지합니다. 즉, 압축이 켜져 있으면 64비트 시스템의 참조는 4바이트를 차지하게 되고, 그렇지 않으면 일반 8바이트가 됩니다.
Java 객체 메모리 크기 계산
위의 이론적 근거를 바탕으로 JVMSizeofTest 클래스의 실행 결과와 "-XX:-UseCompressedOops" 뒤에 동일한 매개변수가 추가되는 이유를 분석할 수 있습니다. 물체의 크기는 다양합니다.
첫 번째는 Object 개체의 크기입니다.
포인터 압축이 켜져 있으면 8바이트 Mark Word + 4바이트 메타데이터 포인터 = 12바이트가 아니므로 12바이트는 배수가 아닙니다. 8, 4바이트가 패딩되고 개체 Object는 16바이트의 메모리를 차지합니다
포인터 압축이 꺼진 경우 8바이트 Mark Word + 8바이트 메타데이터 포인터 = 16바이트입니다. 16바이트는 정확히 다음의 배수이기 때문입니다. 8이므로 패딩 바이트가 필요하지 않으며 객체 Object는 16바이트의 메모리를 차지합니다
그러면 'a' 문자의 크기는 다음과 같습니다.
포인터 압축이 켜졌을 때 8바이트 Mark Word + 4바이트 메타데이터 포인터 + 1바이트 char = 13바이트, 13바이트는 8의 배수가 아니므로 3바이트가 채워지고 문자 'a'는 16바이트의 메모리를 차지합니다
포인터 압축을 끄면 8바이트 Mark Word + 8바이트 메타데이터 포인터 + 1바이트 문자 = 17바이트, 17바이트는 8의 배수가 아니므로 7바이트가 채워지고 문자 'a'는 24개를 차지합니다. 바이트의 메모리
그 다음 정수의 크기 1:
포인터 압축이 켜져 있으면 8바이트 Mark Word + 4바이트 메타데이터 포인터 + 4바이트 int = 16워드 섹션 , 16바이트는 정확히 8의 배수이므로 패딩 바이트가 필요하지 않습니다. 정수 1은 16바이트의 메모리를 차지합니다
포인터 압축이 꺼진 경우 8바이트 Mark Word + 8바이트 메타데이터 포인터 + 4바이트 int = 20바이트, 20바이트는 정확히 8의 배수이므로 4바이트가 채워지고 정수 1이 24바이트의 메모리를 차지합니다
그러면 문자열 "aaaaa"의 크기가 있습니다 , 모든 정적 필드는 관리할 필요가 없으며 인스턴스 필드에만 중점을 둡니다. 문자열 개체의 인스턴스 필드에는 "char value[]" 및 "int hash"가 포함됩니다.
포인터 압축이 켜져 있으면 8바이트 Mark Word + 4바이트 메타데이터 포인터 + 4바이트 참조 + 4바이트 int = 20바이트입니다. 20바이트는 8의 배수가 아니므로 4바이트가 채워지고 문자열 "aaaaa"는 24바이트의 메모리를 차지합니다.
포인터 압축이 꺼진 경우 8바이트 Mark Word + 8바이트 메타데이터 포인터 + 8바이트 참조 + 4바이트 int = 28바이트, 28바이트는 배수가 아니기 때문입니다. 8이므로 4바이트가 채워지는데, 문자열 "aaaaa"는 32바이트의 메모리를 차지합니다
마지막으로 길이가 1인 char 배열의 크기는
포인터 압축을 켜면 , Mark Word 8바이트 + 메타데이터 포인터 4바이트 + 배열 크기 참조 4바이트 + char 1바이트 = 17바이트, 17바이트는 8의 배수가 아니므로 7바이트가 채워지고 길이 1의 char 배열이 24바이트를 차지합니다. of memory
포인터 압축이 꺼지면 Mark Word 8바이트 + 메타데이터 포인터 8바이트 + 배열 크기 참조 8바이트 + char 1바이트 = 25바이트입니다. 25바이트는 배수가 아니기 때문입니다. 8, 따라서 7바이트를 채우면 길이 1의 char 배열은 32바이트의 메모리를 차지합니다
Mark Word
Mark Word는 이전에 본 적이 있는, 매우 큰 부분을 차지합니다. Java 객체 헤더 중요한 부분. Mark Word는 해시 코드(HashCode), GC 생성 기간, 잠금 상태 식별, 스레드가 보유한 잠금, 편향된 스레드 ID, 편향된 타임스탬프 등과 같은 객체 자체의 실행 데이터를 저장합니다.
객체는 런타임 데이터를 많이 저장해야 하기 때문에 실제로는 32비트와 64비트 비트맵 구조가 기록할 수 있는 한계를 초과합니다. 그러나 객체 헤더는 추가 저장 비용이 전혀 들지 않습니다. 이를 고려하여 Mark Word는 가상 머신의 공간 효율성으로 인해 최대한 많은 정보를 저장하기 위해 비고정 데이터 구조로 설계되었습니다. 작은 공간. 예를 들어 32비트 HotSpot 가상 머신의 개체가 잠겨 있지 않은 경우 Mark Word의 32비트 공간 중 25비트는 개체 해시 코드(HashCode)를 저장하는 데 사용되고, 4비트는 개체 생성 연령을 저장하는 데 사용됩니다. , 2비트는 객체 생성 연령을 저장하는 데 사용되며, 1비트는 고정 비트 0입니다. 그 외 상태(경량 잠금, 중량 잠금, GC 마크, 바이어스 가능)의 객체 저장 내용은 아래 그림과 같습니다.
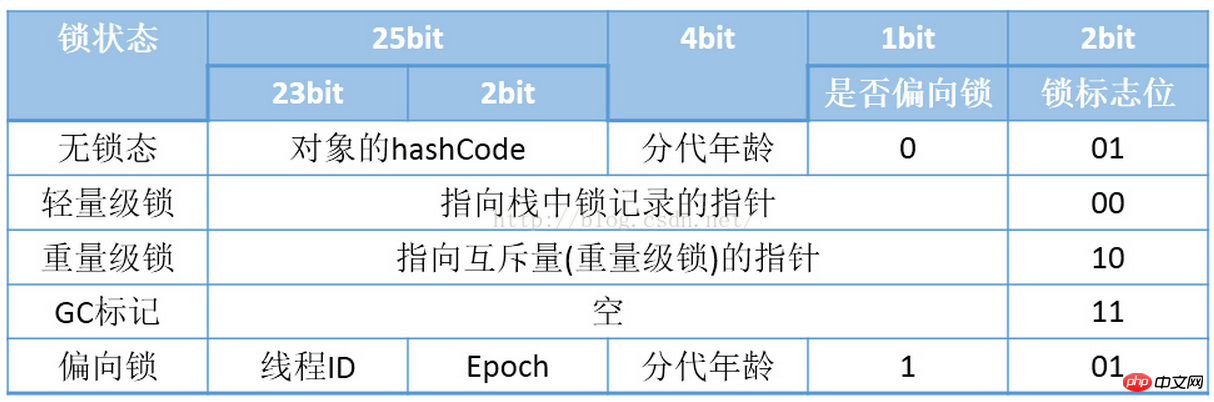
여기서 특별히 주의해야 할 것은 잠금 상태이며, 이에 대해서는 나중에 논의할 것입니다. 잠금 상태와 잠금 상태의 변경 사항을 연구합니다.
잠금 업그레이드
위 그림과 같이 잠금 상태에는 잠금 없음, 바이어스 잠금, 경량 잠금, 중량 잠금의 4가지 잠금 상태가 있으며, 그중 바이어스 잠금과 경량 잠금이 도입되었습니다. JDK 1.6은 잠금 획득 및 해제로 인한 성능 소비를 줄입니다.
4개 잠금 장치의 상태는 경쟁으로 인해 점차 확대됩니다. 잠금 장치는 업그레이드할 수 있지만 다운그레이드할 수는 없습니다. 즉, 편향형 잠금 장치는 경량 잠금 장치로 업그레이드할 수 있지만 경량 장치 잠금 장치는 편향 잠금 장치로 다운그레이드할 수 없다는 의미입니다. 잠금 획득 및 해제의 효율성을 향상시킵니다. 이 관계를 다이어그램으로 표현해보세요:

Biased lock
HotSpot 작성자는 이전 연구를 통해 대부분의 경우 잠금이 멀티 스레드 경쟁이 없을 뿐만 아니라 항상 동일한 스레드에 의해 여러 번 획득된다는 사실을 발견했습니다. 스레드가 획득할 수 있도록 잠금 코드가 낮으므로 편향된 잠금이 도입되었습니다. 바이어스 잠금을 얻는 프로세스는 다음과 같습니다.
바이어스 잠금 플래그가 1로 설정되어 있고 플래그 비트가 01인지 확인하려면 Mark Word에 액세스하세요.---바이어스 가능한 상태인지 확인하세요
가능하다면 바이어스된 상태에서 스레드 ID가 현재 스레드를 가리키는지 테스트합니다. 그렇다면 (5)를 실행하고, 그렇지 않으면 (3)을 실행합니다.
스레드 ID가 현재 스레드를 가리키지 않으면 현재 스레드에서 CAS 연산을 통해 잠금을 놓고 경쟁합니다. 경쟁이 성공하면 Mark Word의 스레드 ID를 현재 스레드 ID로 설정한 후 (5)를 실행하고, 경쟁이 실패하면 (4)를 실행합니다.
CAS가 바이어스 잠금 획득에 실패하면 경쟁이 있다는 뜻이다. 전역 안전점(safepoint)에 도달하면 편향된 잠금을 획득한 스레드가 일시 중단되고 편향된 잠금이 경량 잠금으로 업그레이드됩니다(편향된 잠금은 경쟁이 없다고 가정하지만 여기에는 경쟁이 있으므로 편향된 잠금에는 필요함) 업그레이드 예정), 안전 지점에서 차단된 스레드는 계속해서 동기화 코드
를 실행하고 동기화 코드
를 획득하면 릴리스가 발생합니다. 바이어스 잠금은 위의 (4) 단계에 있습니다. 다른 스레드가 바이어스 잠금을 놓고 경쟁하려고 할 때만 바이어스 잠금을 보유하고 있는 스레드가 잠금을 해제하고 스레드는 바이어스 잠금을 적극적으로 해제하지 않습니다. 편향된 잠금의 해제 프로세스는 다음과 같습니다.
전역 안전 지점을 기다려야 합니다(이 시점에서는 바이트 코드가 실행되지 않습니다)
먼저 잠금을 소유한 스레드를 일시 중지합니다. 바이어스 잠금 및 잠금 개체 결정 잠금 상태인지 여부
바이어스 잠금이 해제된 후 잠금 해제(식별 비트는 01) 또는 경량 잠금(식별 비트는 00) 상태로 돌아갑니다
경량 잠금
경량 잠금의 잠금 프로세스는 다음과 같습니다.
코드가 동기화 블록에 들어갈 때 동기화 객체 잠금 상태가 잠금 해제 상태이면 JVM은 먼저 현재 스레드의 스택 프레임에 설정합니다. Lock Record라는 공간은 잠금 개체의 현재 Mark Word의 복사본을 저장하는 데 사용됩니다. 이 때 공식적으로는 Displaced Mark Word라고 합니다. 객체 헤더는 그림과 같습니다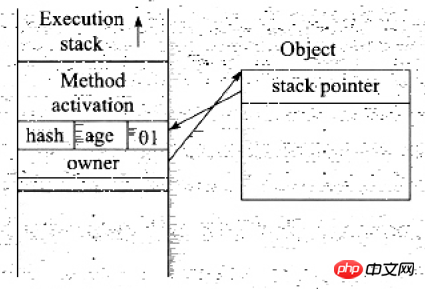
객체 헤더의 마크 워드를 잠금 레코드에 복사합니다
복사에 성공한 후 JVM은 CAS 작업을 사용하여 다음을 시도합니다. 개체의 표시 단어를 잠금 레코드에 대한 포인터로 업데이트하고 잠금 레코드의 소유자를 변경합니다. 포인터가 개체 표시 단어를 가리킵니다. 업데이트가 성공하면 단계(4)를 수행하고, 그렇지 않으면 단계(5)를 수행합니다.
업데이트 작업이 성공하면 현재 스레드가 객체의 잠금을 소유하고 객체 마크 워드 잠금 플래그 비트가 00으로 설정됩니다. 이는 객체가 경량 잠금 상태에 있음을 의미합니다. 이때 라인 스택과 객체 헤더의 상태는 그림과 같습니다. 업데이트 작업이 실패하면 JVM은 먼저 객체의 Mark를 확인합니다. 이는 현재 스레드가 이미 이 개체의 잠금을 소유하고 있으며 동기화 블록에 직접 들어가 실행을 계속할 수 있음을 의미합니다. 그렇지 않으면 여러 스레드가 잠금을 놓고 경쟁하여 경량 잠금이 중량 잠금으로 확장되고 잠금 식별자의 상태 값이 10이 됨을 의미합니다. Mark Word에 저장된 것은 중량 잠금에 대한 포인터이며, 잠금을 기다리는 스레드도 나중에 차단 상태로 들어갑니다. 현재 스레드는 잠금을 획득하기 위해 spin을 사용하려고 합니다. Spin은 스레드가 차단되는 것을 방지하고 루프를 사용하여 잠금을 획득합니다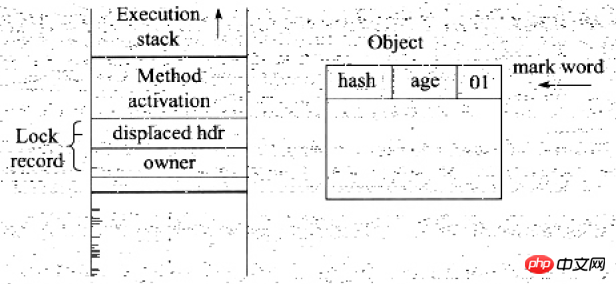
바이어스 잠금장치, 경량 잠금장치, 헤비웨이트 잠금장치 비교
다음은 바이어스 잠금장치, 경량 잠금장치, 헤비웨이트 잠금장치를 비교하는 표입니다. 온라인에서 보고 잘 쓴 것 같아요. 아주 좋습니다. 내 기억을 깊게 하기 위해 다시 손으로:
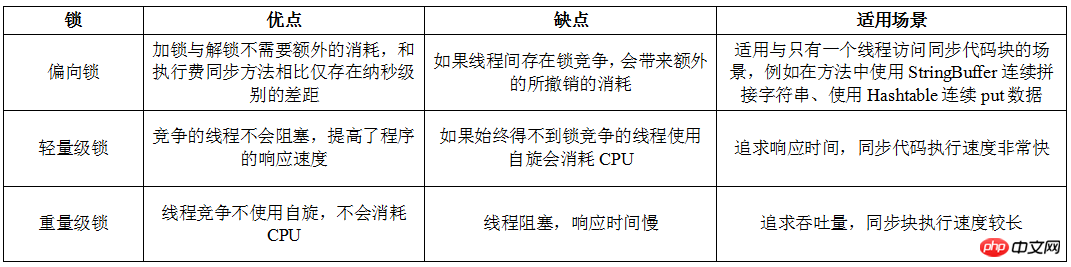
위 내용은 Java Virtual Machine 14: Java 객체 크기, 객체 메모리 레이아웃 및 잠금 상태 변경의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



