
런타임 Java 가상 머신 인스턴스의 의무는 다음과 같습니다. Java 프로그램 실행을 담당합니다. Java 프로그램이 시작되면 가상 머신 인스턴스가 생성됩니다. 프로그램을 닫고 종료하면 가상 머신 인스턴스도 종료됩니다. 세 개의 Java 프로그램이 동일한 컴퓨터에서 동시에 실행되면 세 개의 Java 가상 머신 인스턴스가 확보됩니다. 각 Java 프로그램은 자체 Java 가상 머신 인스턴스에서 실행됩니다.
Java Virtual Machine 인스턴스는 초기 클래스의 main() 메서드를 호출하여 Java 프로그램을 실행합니다. main() 메서드는 공개적이고 정적이어야 하며 void를 반환하고 문자열 배열을 매개 변수로 허용해야 합니다. 이러한 main() 메소드가 있는 모든 클래스는 Java 프로그램 실행을 위한 시작점으로 사용될 수 있습니다.
public class Test {public static void main(String[] args) {// TODO Auto-generated method stub
System.out.println("Hello World");
}
}위의 예에서 Java 프로그램의 초기 클래스에 있는 main() 메소드는 프로그램의 초기 스레드의 시작점으로 사용되며 다른 스레드는 이 초기 스레드에 의해 시작됩니다.
Java 가상 머신 내부에는 데몬 스레드와 비데몬 스레드라는 두 가지 유형의 스레드가 있습니다. 데몬 스레드는 일반적으로 가비지 수집 작업을 수행하는 스레드와 같이 가상 머신 자체에서 사용됩니다. 그러나 Java 프로그램은 자신이 생성하는 모든 스레드를 데몬 스레드로 표시할 수도 있습니다. Java 프로그램의 초기 스레드(main()에서 시작되는 스레드)는 비데몬 스레드입니다.
데몬이 아닌 스레드가 실행 중인 한 Java 프로그램은 계속 실행됩니다. 프로그램의 데몬이 아닌 스레드가 모두 종료되면 가상 머신 인스턴스가 자동으로 종료됩니다. 보안 관리자가 허용하는 경우 Runtime 클래스나 System 클래스의 exit() 메서드를 호출하여 프로그램 자체를 종료할 수도 있습니다.
다음 그림은 JAVA 가상 머신의 구조 다이어그램입니다. 각 Java 가상 머신에는 주어진 정규화된 이름을 기반으로 유형(클래스 또는 인터페이스)을 로드하는 클래스 로딩 하위 시스템이 있습니다. 마찬가지로, 각 JVM(Java Virtual Machine)에는 로드된 클래스의 메소드에 포함된 명령 실행을 담당하는 실행 엔진이 있습니다.
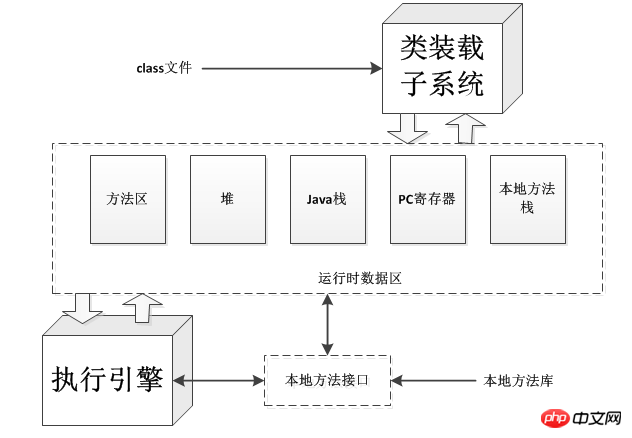
JAVA 가상 머신이 프로그램을 실행할 때 바이트 코드, 로드된 클래스 파일에서 얻은 기타 정보, 프로그램에서 생성된 개체, 메서드에 전달된 매개 변수, 반환 값과 같은 많은 항목을 저장하기 위해 메모리가 필요합니다. , 지역 변수 등 JVM(Java Virtual Machine)은 이러한 항목을 여러 "런타임 데이터 영역"으로 구성하여 쉽게 관리할 수 있습니다.
일부 런타임 데이터 영역은 프로그램의 모든 스레드에서 공유되는 반면, 일부 런타임 데이터 영역은 하나의 스레드만 소유할 수 있습니다. 각 JVM(Java Virtual Machine) 인스턴스에는 가상 머신 인스턴스의 모든 스레드가 공유하는 메소드 영역과 힙이 있습니다. 가상 머신은 클래스 파일을 로드할 때 클래스 파일에 포함된 이진 데이터에서 유형 정보를 구문 분석합니다. 그런 다음 이 유형 정보를 메소드 영역에 입력하십시오. 프로그램이 실행 중일 때 가상 머신은 프로그램이 실행되는 동안 생성된 모든 개체를 힙에 넣습니다.

각각의 새 스레드가 생성되면 자체 PC 레지스터(프로그램 카운터)와 Java 스택이 생성됩니다. 스레드가 Java 메서드(비네이티브 메서드)를 실행하는 경우 PC 레지스터의 값은 다음과 같습니다. 항상 실행될 다음 명령어를 가리키며, 해당 Java 스택은 로컬 변수, 호출 시 전달된 매개변수 및 작업의 중간 결과를 포함하여 항상 스레드의 Java 메서드 호출 상태를 저장합니다. 등. 로컬 메서드 호출의 상태는 특정 구현에 따라 달라지는 메서드의 로컬 메서드 스택에 저장되거나 특정 구현과 관련된 레지스터나 다른 메모리 영역에 저장될 수 있습니다.
Java 스택은 여러 스택 프레임으로 구성됩니다. 하나의 스택 프레임에는 Java 메서드 호출 상태가 포함됩니다. 스레드가 Java 메소드를 호출하면 가상 머신은 새 스택 프레임을 스레드의 Java 스택에 푸시합니다. 메소드가 반환되면 스택 프레임이 Java 스택에서 제거됩니다.
Java Virtual Machine에는 레지스터가 없으며 명령어 세트는 Java 스택을 사용하여 중간 데이터를 저장합니다. 이러한 설계의 이유는 Java 가상 머신의 명령어 세트를 가능한 한 컴팩트하게 유지하고 범용 레지스터가 거의 없는 플랫폼에서 Java 가상 머신의 구현을 용이하게 하기 위한 것입니다. 또한 Java 가상 머신의 스택 기반 아키텍처는 런타임 중에 일부 가상 머신에 의해 구현되는 동적 컴파일러 및 JIT(Just-In-Time) 컴파일러의 코드 최적화에도 도움이 됩니다.
다음 그림은 Java Virtual Machine이 각 스레드에 대해 생성한 메모리 영역을 보여줍니다. 이러한 메모리 영역은 전용이며 어떤 스레드도 다른 스레드의 PC 레지스터나 Java 스택에 액세스할 수 없습니다.

위 그림은 3개의 스레드가 실행되는 가상 머신 인스턴스의 스냅샷을 보여줍니다. 스레드 1과 스레드 2는 모두 Java 메서드를 실행하고 스레드 3은 기본 메서드를 실행합니다.
Java栈都是向下生长的,而栈顶都显示在图的底部。当前正在执行的方法的栈帧则以浅色表示,对于一个正在运行Java方法的线程而言,它的PC寄存器总是指向下一条将被执行的指令。比如线程1和线程2都是以浅色显示的,由于线程3当前正在执行一个本地方法,因此,它的PC寄存器——以深色显示的那个,其值是不确定的。
Java虚拟机是通过某些数据类型来执行计算的,数据类型可以分为两种:基本类型和引用类型,基本类型的变量持有原始值,而引用类型的变量持有引用值。

Java语言中的所有基本类型同样也都是Java虚拟机中的基本类型。但是boolean有点特别,虽然Java虚拟机也把boolean看做基本类型,但是指令集对boolean只有很有限的支持,当编译器把Java源代码编译为字节码时,它会用int或者byte来表示boolean。在Java虚拟机中,false是由整数零来表示的,所有非零整数都表示true,涉及boolean值的操作则会使用int。另外,boolean数组是当做byte数组来访问的,但是在“堆”区,它也可以被表示为位域。
Java虚拟机还有一个只在内部使用的基本类型:returnAddress,Java程序员不能使用这个类型,这个基本类型被用来实现Java程序中的finally子句。该类型是jsr, ret以及jsr_w指令需要使用到的,它的值是JVM指令的操作码的指针。returnAddress类型不是简单意义上的数值,不属于任何一种基本类型,并且它的值是不能被运行中的程序所修改的。
Java虚拟机的引用类型被统称为“引用(reference)”,有三种引用类型:类类型、接口类型、以及数组类型,它们的值都是对动态创建对象的引用。类类型的值是对类实例的引用;数组类型的值是对数组对象的引用,在Java虚拟机中,数组是个真正的对象;而接口类型的值,则是对实现了该接口的某个类实例的引用。还有一种特殊的引用值是null,它表示该引用变量没有引用任何对象。
java中参数的传递有两种,分别是按值传递和按引用传递。按值传递不必多说,下面就说一下按引用传递。
“当一个对象被当作参数传递到一个方法”,这就是所谓的按引用传递。
public class User { private String name;public String getName() {return name;
}public void setName(String name) {this.name = name;
}
}public class Test { public void set(User user){
user.setName("hello world");
} public static void main(String[] args) {
Test test = new Test();
User user = new User();
test.set(user);
System.out.println(user.getName());
}
}上面代码的输出结果是“hello world”,这不必多说,那如果将set方法改为如下,结果会是多少呢?
public void set(User user){
user.setName("hello world");
user = new User();
user.setName("change");
}答案依然是“hello world”,下面就让我们来分析一下如上代码。
首先
User user = new User();
是在堆中创建了一个对象,并在栈中创建了一个引用,此引用指向该对象,如下图:

test.set(user);
是将引用user作为参数传递到set方法,注意:这里传递的并不是引用本身,而是一个引用的拷贝。也就是说这时有两个引用(引用和引用的拷贝)同时指向堆中的对象,如下图:

user.setName("hello world");在set()方法中,“user引用的拷贝”操作堆中的User对象,给name属性设置字符串"hello world"。如下图:

user = new User();
在set()方法中,又创建了一个User对象,并将“user引用的拷贝”指向这个在堆中新创建的对象,如下图:

user.setName("change");在set()方法中,“user引用的拷贝”操作的是堆中新创建的User对象。

set()方法执行完毕,目光再回到mian()方法
System.out.println(user.getName());
因为之前,"user引用的拷贝"已经将堆中的User对象的name属性设置为了"hello world",所以当main()方法中的user调用getName()时,打印的结果就是"hello world"。如下图:

JAVA 가상 머신에서 유형을 찾고 로딩하는 부분을 클래스 로딩 서브시스템이라고 합니다.
JAVA 가상 머신에는 시작 클래스 로더와 사용자 정의 클래스 로더라는 두 가지 유형의 클래스 로더가 있습니다. 전자는 JAVA 가상 머신 구현의 일부이고 후자는 Java 프로그램의 일부입니다. 서로 다른 클래스 로더에 의해 로드된 클래스는 가상 머신 내의 서로 다른 네임스페이스에 배치됩니다.
클래스 로더 하위 시스템에는 Java 가상 머신의 여러 다른 구성 요소와 java.lang 라이브러리의 여러 클래스가 포함됩니다. 예를 들어, 사용자 정의 클래스 로더는 일반 Java 객체이고 해당 클래스는 java.lang.ClassLoader 클래스에서 파생되어야 합니다. ClassLoader에 정의된 메소드는 프로그램이 클래스 로더 메커니즘에 액세스할 수 있는 인터페이스를 제공합니다. 또한 로드된 각 유형에 대해 JAVA 가상 머신은 유형을 표시하기 위해 java.lang.Class 클래스의 인스턴스를 생성합니다. 다른 모든 객체와 마찬가지로 사용자 정의 클래스 로더와 Class 클래스의 인스턴스는 메모리의 힙 영역에 배치되고 로드된 유형 정보는 메소드 영역에 위치합니다.
바이너리 클래스 파일을 찾고 가져오는 것 외에도 클래스 로더 하위 시스템은 가져온 클래스의 정확성을 확인하고, 클래스 변수에 대한 메모리를 할당 및 초기화하고, 기호 참조를 해결하는 데 도움을 주는 역할도 담당해야 합니다. 이러한 작업은 다음 순서에 따라 엄격하게 수행되어야 합니다.
● Verification 가져온 유형이 올바른지 확인하세요.
● 준비 클래스 변수에 메모리를 할당하고 기본값으로 초기화합니다.
● Parsing 타입의 기호 참조를 직접 참조로 변환합니다.
모든 JAVA 가상 머신 구현에는 신뢰할 수 있는 클래스를 로드하는 방법을 아는 시작 클래스 로더가 있어야 합니다.
각 클래스 로더에는 로드된 유형을 유지하는 자체 네임스페이스가 있습니다. 따라서 Java 프로그램은 동일한 정규화된 이름을 가진 여러 유형을 여러 번 로드할 수 있습니다. 이러한 유형의 완전한 이름은 JVM(Java Virtual Machine) 내에서 고유성을 판별하는 데 충분하지 않습니다. 따라서 여러 클래스 로더가 동일한 이름의 유형을 로드하는 경우 유형을 고유하게 식별하려면 유형을 로드하는 클래스 로더 ID(해당 유형이 위치한 네임스페이스를 나타냄) 앞에 유형 이름이 와야 합니다.
Java Virtual Machine에서는 로드된 유형에 대한 정보가 논리적으로 메소드 영역이라는 메모리에 저장됩니다. 가상 머신이 특정 유형을 로드할 때 클래스 로더를 사용하여 해당 클래스 파일을 찾은 다음 선형 바이너리 데이터 스트림인 클래스 파일을 읽어 가상 머신으로 전송한 다음 가상 머신이 유형을 추출합니다. 정보를 저장하고 이 정보를 메소드 영역에 저장합니다. 이 형식의 클래스(정적) 변수도 메서드 영역에 저장됩니다.
JAVA 가상 머신이 내부적으로 유형 정보를 저장하는 방법은 특정 구현의 설계자에 의해 결정됩니다.
가상 머신은 자바 프로그램을 실행할 때 메소드 영역에 저장된 타입 정보를 찾아 사용합니다. 모든 스레드는 메소드 영역을 공유하므로 메소드 영역 데이터에 대한 액세스는 스레드로부터 안전하도록 설계되어야 합니다. 예를 들어, 두 스레드가 동시에 Lava라는 클래스에 액세스하려고 시도하고 이 클래스가 가상 머신에 로드되지 않았다고 가정하면 이때 한 스레드만 이를 로드해야 하고 다른 스레드는 대기만 할 수 있습니다. .
로드된 각 유형에 대해 가상 머신은 메소드 영역에 다음 유형 정보를 저장합니다.
● 이 유형의 정규화된 이름
● 이 유형의 직접 슈퍼클래스의 정규화된 이름(예외 이 유형은 java.lang.Object이며 슈퍼클래스가 없습니다.)
● 이 유형은 클래스 유형입니까, 아니면 인터페이스 유형입니까?
● 이 유형의 액세스 한정자(공용, 추상 또는 최종의 하위 집합)
● 직접 슈퍼인터페이스의 정규화된 이름 순서 목록
위에 나열된 기본 유형 정보 외에도 가상 머신은 로드된 각 유형에 대해 다음 정보도 저장해야 합니다.
● 상수 해당 유형 Pool
●필드 정보
●메서드 정보
●상수를 제외한 모든 클래스(정적) 변수
●ClassLoader 클래스에 대한 참조
수업에 class
의 참조 가상 머신은 로드된 각 유형에 대해 상수 풀을 유지해야 합니다. 상수 풀은 직접 상수와 다른 유형, 필드 및 메소드에 대한 기호 참조를 포함하여 해당 유형에서 사용되는 순서가 지정된 상수 모음입니다. 풀의 데이터 항목은 배열과 마찬가지로 인덱스를 통해 액세스됩니다. 상수 풀은 해당 유형이 사용하는 모든 유형, 필드 및 메소드에 대한 기호 참조를 저장하므로 Java 프로그램의 동적 연결에서 핵심 역할을 합니다.
对于类型中声明的每一个字段。方法区中必须保存下面的信息。除此之外,这些字段在类或者接口中的声明顺序也必须保存。
○ 字段名
○ 字段的类型
○ 字段的修饰符(public、private、protected、static、final、volatile、transient的某个子集)
对于类型中声明的每一个方法,方法区中必须保存下面的信息。和字段一样,这些方法在类或者接口中的声明顺序也必须保存。
○ 方法名
○ 方法的返回类型(或void)
○ 方法参数的数量和类型(按声明顺序)
○ 方法的修饰符(public、private、protected、static、final、synchronized、native、abstract的某个子集)
除了上面清单中列出的条目之外,如果某个方法不是抽象的和本地的,它还必须保存下列信息:
○ 方法的字节码(bytecodes)
○ 操作数栈和该方法的栈帧中的局部变量区的大小
○ 异常表
类变量是由所有类实例共享的,但是即使没有任何类实例,它也可以被访问。这些变量只与类有关——而非类的实例,因此它们总是作为类型信息的一部分而存储在方法区。除了在类中声明的编译时常量外,虚拟机在使用某个类之前,必须在方法区中为这些类变量分配空间。
而编译时常量(就是那些用final声明以及用编译时已知的值初始化的类变量)则和一般的类变量处理方式不同,每个使用编译时常量的类型都会复制它的所有常量到自己的常量池中,或嵌入到它的字节码流中。作为常量池或字节码流的一部分,编译时常量保存在方法区中——就和一般的类变量一样。但是当一般的类变量作为声明它们的类型的一部分数据面保存的时候,编译时常量作为使用它们的类型的一部分而保存。
每个类型被装载的时候,虚拟机必须跟踪它是由启动类装载器还是由用户自定义类装载器装载的。如果是用户自定义类装载器装载的,那么虚拟机必须在类型信息中存储对该装载器的引用。这是作为方法表中的类型数据的一部分保存的。
虚拟机会在动态连接期间使用这个信息。当某个类型引用另一个类型的时候,虚拟机会请求装载发起引用类型的类装载器来装载被引用的类型。这个动态连接的过程,对于虚拟机分离命名空间的方式也是至关重要的。为了能够正确地执行动态连接以及维护多个命名空间,虚拟机需要在方法表中得知每个类都是由哪个类装载器装载的。
对于每一个被装载的类型(不管是类还是接口),虚拟机都会相应地为它创建一个java.lang.Class类的实例,而且虚拟机还必须以某种方式把这个实例和存储在方法区中的类型数据关联起来。
在Java程序中,你可以得到并使用指向Class对象的引用。Class类中的一个静态方法可以让用户得到任何已装载的类的Class实例的引用。
public static Class<?> forName(String className)
比如,如果调用forName("java.lang.Object"),那么将得到一个代表java.lang.Object的Class对象的引用。可以使用forName()来得到代表任何包中任何类型的Class对象的引用,只要这个类型可以被(或者已经被)装载到当前命名空间中。如果虚拟机无法把请求的类型装载到当前命名空间,那么会抛出ClassNotFoundException异常。
另一个得到Class对象引用的方法是,可以调用任何对象引用的getClass()方法。这个方法被来自Object类本身的所有对象继承:
public final native Class<?> getClass();
比如,如果你有一个到java.lang.Integer类的对象的引用,那么你只需简单地调用Integer对象引用的getClass()方法,就可以得到表示java.lang.Integer类的Class对象。
为了展示虚拟机如何使用方法区中的信息,下面来举例说明:
class Lava {private int speed = 5;void flow(){
}
}public class Volcano { public static void main(String[] args){
Lava lava = new Lava();
lava.flow();
}
}不同的虚拟机实现可能会用完全不同的方法来操作,下面描述的只是其中一种可能——但并不是仅有的一种。
Volcano 프로그램을 실행하려면 먼저 "구현에 따른" 방식으로 가상 머신에 "Volcano"라는 이름을 알려주어야 합니다. 그런 다음 가상 머신은 해당 클래스 파일 "Volcano.class"를 찾아서 읽은 다음 가져온 클래스 파일의 바이너리 데이터에서 유형 정보를 추출하여 메소드 영역에 넣습니다. 메소드 영역에 저장된 바이트코드를 실행함으로써 가상 머신은 main() 메소드 실행을 시작하며, 실행 중에 항상 현재 클래스(Volcano 클래스)를 가리키는 상수 풀(메소드 영역의 데이터 구조)을 보유합니다. 바늘.
참고: 가상 머신이 Volcano 클래스에 있는 main() 메서드의 바이트코드 실행을 시작할 때 대부분의(아마도 모든) 가상 머신 구현과 마찬가지로 Lava 클래스가 아직 로드되지 않았지만 프로그램이 실행될 때까지 기다리지 않습니다. 사용된 모든 클래스는 실행 전에 로드됩니다. 반대로 필요할 때만 해당 클래스를 로드합니다.
main()의 첫 번째 명령은 가상 머신에 상수 풀의 첫 번째 항목에 나열된 클래스에 충분한 메모리를 할당하라고 지시합니다. 따라서 가상 머신은 Volcano 상수 풀에 대한 포인터를 사용하여 첫 번째 항목을 찾고, 그것이 Lava 클래스에 대한 상징적 참조임을 찾은 다음, Lava 클래스가 로드되었는지 확인하기 위해 메서드 영역을 확인합니다.
이 기호 참조는 단순히 Lava 클래스의 정규화된 이름 "Lava"를 제공하는 문자열입니다. 가상 머신이 가능한 한 빨리 이름에서 클래스를 찾으려면 가상 머신 설계자가 최상의 데이터 구조와 알고리즘을 선택해야 합니다.
가상 머신은 "Lava"라는 클래스가 로드되지 않은 것을 발견하면 "Lava.class" 파일을 찾아서 로드하기 시작하며, 읽은 바이너리 데이터에서 추출한 타입 정보를 메소드 영역에 넣습니다.
그 직후, 가상 머신은 상수 풀의 첫 번째 항목(즉, 문자열 "Lava")을 메서드 영역의 Lava 클래스 데이터를 직접 가리키는 포인터로 대체합니다. 이 포인터를 사용하면 해당 항목에 빠르게 액세스할 수 있습니다. 미래의 라바 수업. 이러한 대체 프로세스를 상수 풀 해결이라고 하며, 상수 풀의 기호 참조를 직접 참조로 대체합니다.
마지막으로 가상 머신은 새로운 Lava 객체에 메모리를 할당할 준비가 되었습니다. 이 시점에서 메소드 영역의 정보가 다시 필요합니다. 방금 Volcano 클래스 상수 풀의 첫 번째 항목에 넣은 포인터를 기억하시나요? 이제 가상 머신은 이를 사용하여 Lava 유형 정보에 액세스하고 여기에 기록된 정보, 즉 Lava 객체가 할당해야 하는 힙 공간의 양을 찾습니다.
JAVA 가상 머신은 스토리지 및 메소드 영역의 유형 정보를 통해 객체에 필요한 메모리 양을 항상 결정할 수 있습니다. JAVA 가상 머신은 Lava 객체의 크기를 결정할 때 이러한 큰 공간을 힙에 할당하고 저장합니다. this 객체 인스턴스의 가변 속도는 기본 초기값인 0으로 초기화됩니다.
새로 생성된 Lava 객체의 참조가 스택에 푸시되면 main() 메서드의 첫 번째 명령도 완료됩니다. 다음 지침에서는 이 참조를 통해 속도 변수를 올바른 초기 값 5로 초기화하는 Java 코드를 호출합니다. 또 다른 명령어는 이 참조를 사용하여 Lava 개체 참조의 flow() 메서드를 호출합니다.
런타임 중에 Java 프로그램에 의해 생성된 모든 클래스 인스턴스 또는 배열은 동일한 힙에 배치됩니다. JAVA 가상 머신 인스턴스에는 힙 공간이 하나만 있으므로 모든 스레드가 이 힙을 공유합니다. 그리고 Java 프로그램은 JAVA 가상 머신 인스턴스를 차지하므로 각 Java 프로그램은 고유한 힙 공간을 가지며 서로 간섭하지 않습니다. 그러나 동일한 Java 프로그램의 여러 스레드가 동일한 힙 공간을 공유하는 경우 개체(힙 데이터)에 대한 다중 스레드 액세스의 동기화 문제를 고려해야 합니다.
JAVA 가상머신에는 힙에 새 객체를 할당하라는 명령은 있지만, Java 코드 영역에서 객체를 명시적으로 해제할 수 없는 것처럼 메모리를 해제하라는 명령은 없습니다. 가상 머신 자체는 실행 중인 프로그램에서 더 이상 참조하지 않는 개체가 차지한 메모리를 해제하는 방법과 시기를 결정하는 역할을 담당합니다. 일반적으로 가상 머신은 이 작업을 가비지 수집기에 맡깁니다.
Java에서 배열은 실제 객체입니다. 다른 객체와 마찬가지로 배열은 항상 힙에 저장됩니다. 마찬가지로 배열에는 해당 클래스와 연관된 Class 인스턴스가 있으며, 동일한 차원과 유형을 가진 모든 배열은 배열 길이(다차원 배열의 각 차원 길이)에 관계없이 동일한 클래스의 인스턴스입니다. 예를 들어, 3개의 정수를 포함하는 배열과 300개의 정수를 포함하는 배열은 동일한 클래스를 갖습니다. 배열의 길이는 인스턴스 데이터에만 관련됩니다.
배열 클래스의 이름은 두 부분으로 구성됩니다. 각 차원은 대괄호 "["로 표시되며 문자 또는 문자열은 요소 유형을 나타내는 데 사용됩니다. 예를 들어 요소 유형이 정수인 1차원 배열의 클래스 이름은 "[I"이고 요소 유형이 바이트인 3차원 배열의 클래스 이름은 "[[[B""이며 클래스 이름은 "[[B"입니다. 요소 유형이 Object인 2차원 배열은 "[[Ljava/lang/Object"입니다.
다차원 배열은 배열의 배열로 표현됩니다. 예를 들어, int 유형의 2차원 배열은 1차원 배열로 표시되며, 여기서 각 요소는 아래와 같이 1차원 int 배열에 대한 참조입니다.
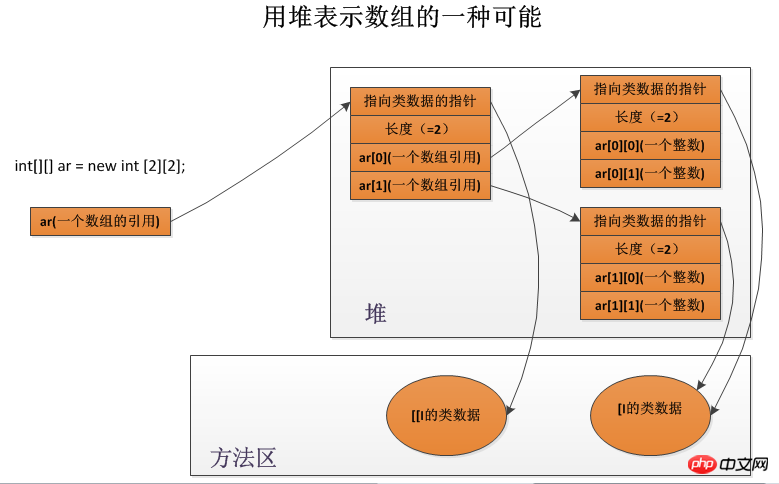
힙의 각 배열 객체는 배열 길이, 배열 데이터 및 배열 유사 데이터에 대한 일부 참조도 저장해야 합니다. 가상 머신은 배열 객체에 대한 참조를 통해 배열의 길이를 얻을 수 있어야 하고, 인덱스를 통해 해당 요소에 액세스하고(배열 경계가 범위를 벗어났는지 확인해야 하는 동안), 선언된 메서드를 호출할 수 있어야 합니다. 모든 배열의 직접 슈퍼클래스 객체 등.
실행 중인 Java 프로그램의 경우 각 스레드에는 스레드가 시작될 때 생성되는 자체 PC(프로그램 카운터) 레지스터가 있으므로 PC 레지스터의 크기는 1워드입니다. 로컬 포인터와 returnAddress 모두. 스레드가 Java 메서드를 실행할 때 PC 레지스터의 내용은 항상 실행될 다음 명령어의 "주소"입니다. 여기서 "주소"는 로컬 포인터일 수도 있고 메서드의 메서드에 상대적일 수도 있습니다. 바이트코드. 시작 명령어의 오프셋입니다. 스레드가 기본 메서드를 실행 중인 경우 이 시점의 PC 레지스터 값은 "정의되지 않음"입니다.
새로운 스레드가 시작될 때마다 Java 가상 머신은 이에 대해 Java 스택을 할당합니다. Java 스택은 스레드의 실행 상태를 프레임에 저장합니다. 가상 머신은 Java 스택에서 프레임 푸시와 팝이라는 두 가지 작업만 직접 수행합니다.
스레드에 의해 실행되는 메서드를 스레드의 현재 메서드라고 합니다. 현재 메서드가 사용하는 스택 프레임을 현재 클래스라고 합니다. 현재 클래스를 현재 상수 풀이라고 합니다. 스레드가 메서드를 실행할 때 현재 클래스와 현재 상수 풀을 추적합니다. 또한 가상 머신은 스택 내 작업 명령을 만나면 현재 프레임의 데이터에 대한 작업을 수행합니다.
스레드가 Java 메소드를 호출할 때마다 가상 머신은 스레드의 Java 스택에 새 프레임을 푸시합니다. 그리고 이 새로운 프레임은 자연스럽게 현재 프레임이 됩니다. 이 메서드를 실행할 때 이 프레임을 사용하여 매개변수, 지역 변수, 중간 작업 결과 및 기타 데이터를 저장합니다.
Java 메서드는 두 가지 방법으로 수행할 수 있습니다. 하나는 return에 의해 반환되는데, 이를 일반 반환이라고 하고, 다른 하나는 예외를 발생시켜 비정상적으로 종료됩니다. 어떤 메소드가 반환되든 가상 머신은 현재 프레임을 Java 스택에서 꺼내어 해제하므로 이전 메소드의 프레임이 현재 프레임이 됩니다.
Java 프레임의 모든 데이터는 이 스레드에 비공개입니다. 어떤 스레드도 다른 스레드의 스택 데이터에 액세스할 수 없으므로 멀티 스레드 상황에서 스택 데이터의 액세스 동기화 문제를 고려할 필요가 없습니다. 스레드가 메소드를 호출하면 메소드의 지역 변수가 호출 스레드의 Java 스택 프레임에 저장됩니다. 항상 하나의 스레드, 즉 메서드를 호출하는 스레드만이 해당 지역 변수에 액세스할 수 있습니다.
앞서 언급한 모든 런타임 데이터 영역은 Java 가상 머신 사양에 명확하게 정의되어 있습니다. 또한 실행 중인 Java 프로그램의 경우 로컬 메소드와 관련된 일부 데이터 영역을 사용할 수도 있습니다. 스레드가 기본 메서드를 호출하면 더 이상 가상 머신의 제한을 받지 않는 새로운 세계로 들어갑니다. 네이티브 메서드는 네이티브 메서드 인터페이스를 통해 가상 머신의 런타임 데이터 영역에 액세스할 수 있지만 그 이상으로 원하는 모든 작업을 수행할 수 있습니다.
네이티브 메소드는 기본적으로 구현에 따라 다릅니다. 가상 머신 구현 설계자는 Java 프로그램이 로컬 메소드를 호출할 수 있도록 어떤 메커니즘을 사용할지 자유롭게 결정할 수 있습니다.
모든 기본 메서드 인터페이스는 일종의 기본 메서드 스택을 사용합니다. 스레드가 Java 메소드를 호출하면 가상 머신은 새 스택 프레임을 생성하고 이를 Java 스택에 푸시합니다. 그러나 로컬 메소드를 호출하면 가상 머신은 Java 스택을 변경하지 않고 더 이상 스레드의 Java 스택에 새 프레임을 푸시하지 않습니다. 가상 머신은 지정된 로컬 메소드를 동적으로 연결하고 직접 호출합니다.
가상 머신에 의해 구현된 로컬 메소드 인터페이스가 C 연결 모델을 사용하는 경우 해당 로컬 메소드 스택은 C 스택입니다. C 프로그램이 C 함수를 호출하면 스택 작업이 결정됩니다. 함수에 전달된 매개변수는 특정 순서로 스택에 푸시되고, 반환 값도 특정 방식으로 호출자에게 다시 전달됩니다. 다시 말하지만, 이는 가상 머신 구현에서 기본 메서드 스택이 작동하는 방식입니다.
네이티브 메소드 인터페이스가 Java 가상 머신에서 Java 메소드를 콜백해야 할 가능성이 매우 높습니다. 이 경우 스레드는 로컬 메소드 스택의 상태를 저장하고 다른 Java 스택에 들어갑니다.
다음 그림은 스레드가 로컬 메서드를 호출할 때 로컬 메서드가 가상 머신에서 다른 Java 메서드를 다시 호출하는 시나리오를 보여줍니다. 이 그림은 JAVA 가상 머신 내부에서 실행되는 스레드의 전경을 보여줍니다. 스레드는 Java 메소드를 실행하고 수명 주기 내내 Java 스택을 작동할 수 있습니다. 또는 아무런 방해 없이 Java 스택과 기본 메소드 스택 사이를 이동할 수도 있습니다. 
스레드는 먼저 두 개의 Java 메소드를 호출하고 두 번째 Java 메소드는 로컬 메소드를 호출하여 가상 머신이 로컬 메소드 스택을 사용하게 했습니다. 두 개의 C 함수가 사이에 있는 C 언어 스택이라고 가정해 보겠습니다. 첫 번째 C 함수는 두 번째 Java 메서드에 의해 기본 메서드로 호출되고 이 C 함수는 두 번째 C 함수를 호출합니다. 그런 다음 두 번째 C 함수는 로컬 메서드 인터페이스를 통해 Java 메서드(세 번째 Java 메서드)를 다시 호출하고, 마지막으로 이 Java 메서드는 Java 메서드를 호출합니다(다이어그램에서 현재 메서드가 됨).
Java를 배우는 학생들 주목! ! !
학습 과정에서 문제가 발생하거나 학습 리소스를 얻고 싶다면 Java 학습 교류 그룹인 299541275에 가입하세요. 함께 Java를 배우자!
위 내용은 Java Virtual Machine 아키텍처에 대한 자세한 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



