

Java의 Buffer 소스 코드에 대한 심층 분석

기본 환경: Linux 4.4.0-21-generic #37-Ubuntu SMP Mon Apr 18 18:33:37 UTC 2016 x86_64 x86_64 x86_64 GNU/LinuxLinux 4.4.0-21-generic #37-Ubuntu SMP Mon Apr 18 18:33:37 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
Buffer
Buffer的类图如下:
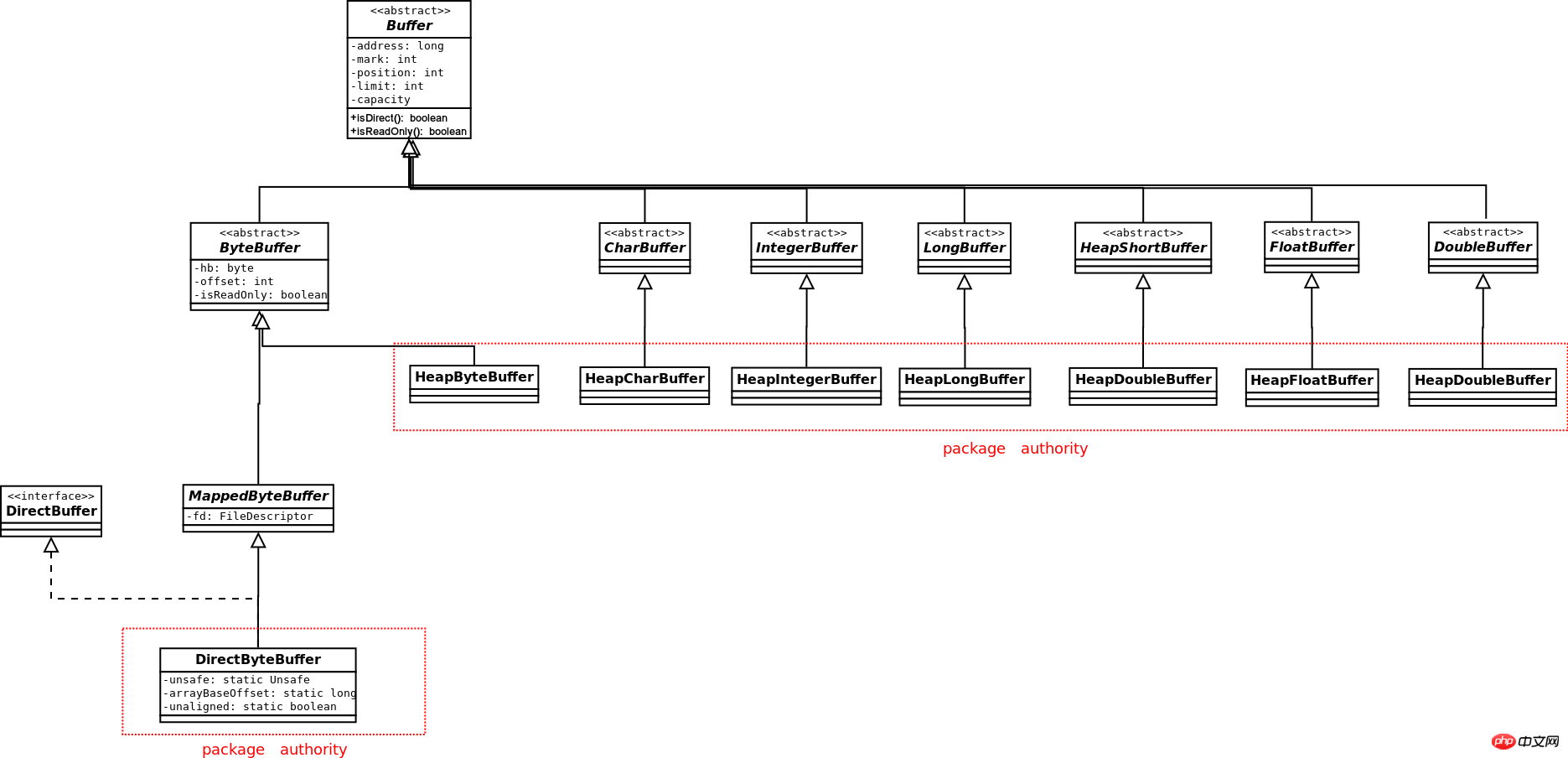
除了Boolean,其他基本数据类型都有对应的Buffer,但是只有ByteBuffer才能和Channel交互。只有ByteBuffer才能产生Direct的buffer,其他数据类型的Buffer只能产生Heap类型的Buffer。ByteBuffer可以产生其他数据类型的视图Buffer,如果ByteBuffer本身是Direct的,则产生的各视图Buffer也是Direct的。
Direct和Heap类型Buffer的本质
首选说说JVM是怎么进行IO操作的。
JVM在需要通过操作系统调用完成IO操作,比如可以通过read系统调用完成文件的读取。read的原型是:ssize_t read(int fd,void *buf,size_t nbytes),和其他的IO系统调用类似,一般需要缓冲区作为其中一个参数,该缓冲区要求是连续的。
Buffer分为Direct和Heap两类,下面分别说明这两类buffer。
Heap
Heap类型的Buffer存在于JVM的堆上,这部分内存的回收与整理和普通的对象一样。Heap类型的Buffer对象都包含一个对应基本数据类型的数组属性(比如:final **[] hb),数组才是Heap类型Buffer的底层缓冲区。
但是Heap类型的Buffer不能作为缓冲区参数直接进行系统调用,主要因为下面两个原因。
JVM在GC时可能会移动缓冲区(复制-整理),缓冲区的地址不固定。
系统调用时,缓冲区需要是连续的,但是数组可能不是连续的(JVM的实现没要求连续)。
所以使用Heap类型的Buffer进行IO时,JVM需要产生一个临时Direct类型的Buffer,然后进行数据复制,再使用临时Direct的Buffer作为参数进行操作系统调用。这造成很低的效率,主要是因为两个原因:
需要把数据从Heap类型的Buffer里面复制到临时创建的Direct的Buffer里面。
可能产生大量的Buffer对象,从而提高GC的频率。所以在IO操作时,可以通过重复利用Buffer进行优化。
Direct
Direct类型的buffer,不存在于堆上,而是JVM通过malloc直接分配的一段连续的内存,这部分内存成为直接内存,JVM进行IO系统调用时使用的是直接内存作为缓冲区。-XX:MaxDirectMemorySize,通过这个配置可以设置允许分配的最大直接内存的大小(MappedByteBuffer分配的内存不受此配置影响)。
直接内存的回收和堆内存的回收不同,如果直接内存使用不当,很容易造成OutOfMemoryError。JAVA没有提供显示的方法去主动释放直接内存,sun.misc.Unsafe类可以进行直接的底层内存操作,通过该类可以主动释放和管理直接内存。同理,也应该重复利用直接内存以提高效率。
MappedByteBuffer和DirectByteBuffer之间的关系
This is a little bit backwards: By rights MappedByteBuffer should be a subclass of DirectByteBuffer, but to keep the spec clear and simple, and for optimization purposes, it's easier to do it the other way around.This works because DirectByteBuffer is a package-private class.(本段话摘自MappedByteBuffer的源码)
实际上,MappedByteBuffer属于映射buffer(自己看看虚拟内存),但是DirectByteBuffer只是说明该部分内存是JVM在直接内存区分配的连续缓冲区,并不一是映射的。也就是说MappedByteBuffer应该是DirectByteBuffer的子类,但是为了方便和优化,把MappedByteBuffer作为了DirectByteBuffer的父类。另外,虽然MappedByteBuffer在逻辑上应该是DirectByteBuffer的子类,而且MappedByteBuffer的内存的GC和直接内存的GC类似(和堆GC不同),但是分配的MappedByteBuffer的大小不受-XX:MaxDirectMemorySize参数影响。
MappedByteBuffer封装的是内存映射文件操作,也就是只能进行文件IO操作。MappedByteBuffer是根据mmap产生的映射缓冲区,这部分缓冲区被映射到对应的文件页上,属于直接内存在用户态,通过MappedByteBuffer可以直接操作映射缓冲区,而这部分缓冲区又被映射到文件页上,操作系统通过对应内存页的调入和调出完成文件的写入和写出。
MappedByteBuffer
通过FileChannel.map(MapMode mode,long position, long size)得到MappedByteBuffer,下面结合源码说明MappedByteBuffer的产生过程。
FileChannel.map
버퍼
Buffer 클래스 다이어그램은 다음과 같습니다. 🎜🎜Boolean을 제외한 다른 기본 데이터 유형에는 해당 버퍼가 있지만 ByteBuffer만 채널과 상호 작용할 수 있습니다. ByteBuffer만 Direct 버퍼를 생성할 수 있습니다. 다른 데이터 유형의 버퍼는 Heap 유형 버퍼만 생성할 수 있습니다. ByteBuffer는 다른 데이터 유형의 뷰 버퍼를 생성할 수 있습니다. ByteBuffer 자체가 Direct이면 생성된 각 뷰 버퍼도 Direct입니다. 🎜직접 및 힙 유형 버퍼의 본질
🎜 첫 번째 선택은 JVM이 IO 작업을 수행하는 방법에 대해 이야기하는 것입니다. 🎜🎜JVM은 운영 체제 호출을 통해 IO 작업을 완료해야 합니다. 예를 들어 읽기 시스템 호출을 통해 파일 읽기를 완료할 수 있습니다. 읽기의 프로토타입은ssize_t read(int fd, void *buf, size_t nbytes)이며, 다른 IO 시스템 호출과 유사하며 일반적으로 매개변수 중 하나로 버퍼가 필요하며 버퍼는 다음을 수행하는 데 필요합니다. 지속적이어야 한다. 🎜🎜버퍼는 직접 및 힙의 두 가지 범주로 구분됩니다. 이 두 가지 유형의 버퍼는 아래에 설명되어 있습니다. 🎜힙
🎜힙 유형 버퍼는 JVM 힙에 존재합니다. 메모리의 이 부분을 재활용하고 정렬하는 방법은 일반 객체와 동일합니다. 힙 유형의 버퍼 객체에는 모두 기본 데이터 유형(예: final **[] hb)에 해당하는 배열 속성이 포함되어 있으며, 배열은 힙 유형 버퍼의 기본 버퍼입니다. 🎜그러나 Heap 유형의 Buffer는 주로 다음 두 가지 이유로 직접 시스템 호출의 버퍼 매개변수로 사용할 수 없습니다. 🎜- 🎜JVM은 GC 중에 버퍼를 이동(복사 구성)할 수 있으며 버퍼의 주소는 고정되어 있지 않습니다. 🎜
- 🎜시스템 호출을 할 때 버퍼는 연속적이어야 하지만 배열은 연속적이지 않을 수 있습니다(JVM 구현에서는 연속성이 필요하지 않습니다). 🎜
- 🎜 데이터를 힙 유형 버퍼에서 임시 생성된 직접 버퍼로 복사해야 합니다. 🎜
- 🎜많은 수의 Buffer 객체가 생성되어 GC 빈도가 높아질 수 있습니다. 따라서 IO 작업 중에 버퍼를 재사용하여 최적화할 수 있습니다. 🎜
Direct
🎜Direct형 버퍼는 힙에 존재하지 않고, JVM이 malloc을 통해 직접 할당한 연속 메모리이다. 직접 메모리가 되면 JVM은 IO 시스템 호출을 수행할 때 직접 메모리를 버퍼로 사용합니다. 🎜-XX:MaxDirectMemorySize, 이 구성을 통해 할당이 허용되는 최대 직접 메모리 크기를 설정할 수 있습니다(MappedByteBuffer에 의해 할당된 메모리는 이 구성의 영향을 받지 않습니다). 🎜직접 메모리 재활용은 힙 메모리 재활용과 다릅니다. 직접 메모리를 부적절하게 사용하면 OutOfMemoryError가 발생하기 쉽습니다. JAVA는 직접 메모리를 적극적으로 해제하는 명시적인 방법을 제공하지 않습니다. sun.misc.Unsafe 클래스는 기본 메모리 작업을 직접 수행할 수 있으며, 이 클래스를 통해 직접 메모리를 적극적으로 해제하고 관리할 수 있습니다. 마찬가지로 효율성을 높이려면 직접 메모리도 재사용해야 합니다. 🎜MappedByteBuffer와 DirectByteBuffer의 관계
🎜이것은 약간 거꾸로입니다. 권리에 따르면 MappedByteBuffer는 DirectByteBuffer의 하위 클래스여야 하지만 사양을 명확하고 단순하게 유지하려면 , 그리고 최적화 목적을 위해서는 반대 방향으로 수행하는 것이 더 쉽습니다. DirectByteBuffer는 패키지 전용 클래스이기 때문에 작동합니다.(이 단락은 MappedByteBuffer의 소스 코드에서 가져옴)🎜🎜In 실제로 MappedByteBuffer는 매핑된 버퍼이지만(가상 메모리를 직접 살펴보세요) DirectByteBuffer는 메모리의 이 부분이 JVM이 직접 메모리 영역에 할당한 연속 버퍼임을 나타낼 뿐 반드시 매핑되지는 않습니다. 즉, MappedByteBuffer는 DirectByteBuffer의 하위 클래스여야 하나, 편의성과 최적화를 위해 MappedByteBuffer를 DirectByteBuffer의 부모 클래스로 사용한다. 또한, MappedByteBuffer는 논리적으로 DirectByteBuffer의 서브클래스여야 하고, MappedByteBuffer 메모리의 GC는 직접 메모리의 GC와 유사하지만(힙 GC와 다름), 할당된 MappedByteBuffer의 크기는 -XX:MaxDirectMemorySize의 영향을 받지 않는다. 매개변수. 🎜MappedByteBuffer는 메모리 매핑된 파일 작업을 캡슐화합니다. 즉, 파일 IO 작업만 수행할 수 있습니다. MappedByteBuffer는 mmap을 기반으로 생성된 매핑 버퍼로, 이 부분은 해당 파일 페이지에 매핑되며, 사용자 모드에서는 직접 메모리에 속하며, 매핑된 버퍼는 MappedByteBuffer를 통해 직접 동작할 수 있다. 파일 페이지 시스템에서 운영 체제는 해당 메모리 페이지를 호출하여 파일 쓰기 및 쓰기를 완료합니다. 🎜
MappedByteBuffer
🎜FileChannel.map(MapMode 모드, 긴 위치, 긴 크기)를 통해 MappedByteBuffer를 가져옵니다. MappedByteBuffer 생성 과정은 소스 코드와 함께 아래에 설명되어 있습니다. 🎜🎜FileChannel.map 소스 코드: 🎜🎜public MappedByteBuffer map(MapMode mode, long position, long size)throws IOException
{ensureOpen();if (position < 0L)throw new IllegalArgumentException("Negative position");if (size < 0L)throw new IllegalArgumentException("Negative size");if (position + size < 0)throw new IllegalArgumentException("Position + size overflow");//最大2Gif (size > Integer.MAX_VALUE)throw new IllegalArgumentException("Size exceeds Integer.MAX_VALUE");int imode = -1;if (mode == MapMode.READ_ONLY)
imode = MAP_RO;else if (mode == MapMode.READ_WRITE)
imode = MAP_RW;else if (mode == MapMode.PRIVATE)
imode = MAP_PV;assert (imode >= 0);if ((mode != MapMode.READ_ONLY) && !writable)throw new NonWritableChannelException();if (!readable)throw new NonReadableChannelException();long addr = -1;int ti = -1;try {begin();
ti = threads.add();if (!isOpen())return null;//size()返回实际的文件大小//如果实际文件大小不符合,则增大文件的大小,文件的大小被改变,文件增大的部分默认设置为0。if (size() < position + size) { // Extend file sizeif (!writable) {throw new IOException("Channel not open for writing " +"- cannot extend file to required size");
}int rv;do { //增大文件的大小rv = nd.truncate(fd, position + size);
} while ((rv == IOStatus.INTERRUPTED) && isOpen());
}//如果要求映射的文件大小为0,则不调用操作系统的mmap调用,只是生成一个空间容量为0的DirectByteBuffer//并返回if (size == 0) {
addr = 0;// a valid file descriptor is not requiredFileDescriptor dummy = new FileDescriptor();if ((!writable) || (imode == MAP_RO))return Util.newMappedByteBufferR(0, 0, dummy, null);elsereturn Util.newMappedByteBuffer(0, 0, dummy, null);
}//allocationGranularity的大小在我的系统上是4K//页对齐,pagePosition为第多少页int pagePosition = (int)(position % allocationGranularity);//从页的最开始映射long mapPosition = position - pagePosition;//因为从页的最开始映射,增大映射空间long mapSize = size + pagePosition;try {// If no exception was thrown from map0, the address is valid//native方法,源代码在openjdk/jdk/src/solaris/native/sun/nio/ch/FileChannelImpl.c,//参见下面的说明addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError x) {// An OutOfMemoryError may indicate that we've exhausted memory// so force gc and re-attempt mapSystem.gc();try {
Thread.sleep(100);
} catch (InterruptedException y) {
Thread.currentThread().interrupt();
}try {
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError y) {// After a second OOME, failthrow new IOException("Map failed", y);
}
}// On Windows, and potentially other platforms, we need an open// file descriptor for some mapping operations.FileDescriptor mfd;try {
mfd = nd.duplicateForMapping(fd);
} catch (IOException ioe) {unmap0(addr, mapSize);throw ioe;
}assert (IOStatus.checkAll(addr));assert (addr % allocationGranularity == 0);int isize = (int)size;
Unmapper um = new Unmapper(addr, mapSize, isize, mfd);if ((!writable) || (imode == MAP_RO)) {return Util.newMappedByteBufferR(isize,
addr + pagePosition,
mfd,
um);
} else {return Util.newMappedByteBuffer(isize,
addr + pagePosition,
mfd,
um);
}
} finally {
threads.remove(ti);end(IOStatus.checkAll(addr));
}
}map0的源码实现:
JNIEXPORT jlong JNICALL
Java_sun_nio_ch_FileChannelImpl_map0(JNIEnv *env, jobject this,
jint prot, jlong off, jlong len)
{void *mapAddress = 0;
jobject fdo = (*env)->GetObjectField(env, this, chan_fd);//linux系统调用是通过整型的文件id引用文件的,这里得到文件idjint fd = fdval(env, fdo);int protections = 0;int flags = 0;if (prot == sun_nio_ch_FileChannelImpl_MAP_RO) {
protections = PROT_READ;
flags = MAP_SHARED;
} else if (prot == sun_nio_ch_FileChannelImpl_MAP_RW) {
protections = PROT_WRITE | PROT_READ;
flags = MAP_SHARED;
} else if (prot == sun_nio_ch_FileChannelImpl_MAP_PV) {
protections = PROT_WRITE | PROT_READ;
flags = MAP_PRIVATE;
}//这里就是操作系统调用了,mmap64是宏定义,实际最后调用的是mmapmapAddress = mmap64(0, /* Let OS decide location */len, /* Number of bytes to map */protections, /* File permissions */flags, /* Changes are shared */fd, /* File descriptor of mapped file */off); /* Offset into file */if (mapAddress == MAP_FAILED) {if (errno == ENOMEM) {//如果没有映射成功,直接抛出OutOfMemoryErrorJNU_ThrowOutOfMemoryError(env, "Map failed");return IOS_THROWN;
}return handle(env, -1, "Map failed");
}return ((jlong) (unsigned long) mapAddress);
}虽然FileChannel.map()的zise参数是long,但是size的大小最大为Integer.MAX_VALUE,也就是最大只能映射最大2G大小的空间。实际上操作系统提供的MMAP可以分配更大的空间,但是JAVA限制在2G,ByteBuffer等Buffer也最大只能分配2G大小的缓冲区。
MappedByteBuffer是通过mmap产生得到的缓冲区,这部分缓冲区是由操作系统直接创建和管理的,最后JVM通过unmmap让操作系统直接释放这部分内存。
Haep****Buffer
下面以ByteBuffer为例,说明Heap类型Buffer的细节。
该类型的Buffer可以通过下面方式产生:
ByteBuffer.allocate(int capacity)ByteBuffer.wrap(byte[] array)
使用传入的数组作为底层缓冲区,变更数组会影响缓冲区,变更缓冲区也会影响数组。ByteBuffer.wrap(byte[] array,int offset, int length)
使用传入的数组的一部分作为底层缓冲区,变更数组的对应部分会影响缓冲区,变更缓冲区也会影响数组。
DirectByteBuffer
DirectByteBuffer只能通过ByteBuffer.allocateDirect(int capacity) 产生。ByteBuffer.allocateDirect()源码如下:
public static ByteBuffer allocateDirect(int capacity) {return new DirectByteBuffer(capacity);
}DirectByteBuffer()源码如下:
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
//直接内存是否要页对齐,我本机测试的不用
boolean pa = VM.isDirectMemoryPageAligned();
//页的大小,本机测试的是4K
int ps = Bits.pageSize();
//如果页对齐,则size的大小是ps+cap,ps是一页,cap也是从新的一页开始,也就是页对齐了
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
//JVM维护所有直接内存的大小,如果已分配的直接内存加上本次要分配的大小超过允许分配的直接内存的最大值会
//引起GC,否则允许分配并把已分配的直接内存总量加上本次分配的大小。如果GC之后,还是超过所允许的最大值,
//则throw new OutOfMemoryError("Direct buffer memory");
Bits.reserveMemory(size, cap);
long base = 0;
try {
//是吧,unsafe可以直接操作底层内存
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {、
//没有分配成功,把刚刚加上的已分配的直接内存的大小减去。
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}unsafe.allocateMemory()的源码在openjdk/src/openjdk/hotspot/src/share/vm/prims/unsafe.cpp中。具体的源码如下:
UNSAFE_ENTRY(jlong, Unsafe_AllocateMemory(JNIEnv *env, jobject unsafe, jlong size))
UnsafeWrapper("Unsafe_AllocateMemory");
size_t sz = (size_t)size; if (sz != (julong)size || size < 0) {
THROW_0(vmSymbols::java_lang_IllegalArgumentException());
} if (sz == 0) {return 0;
}
sz = round_to(sz, HeapWordSize); //最后调用的是 u_char* ptr = (u_char*)::malloc(size + space_before + space_after),也就是malloc。
void* x = os::malloc(sz, mtInternal); if (x == NULL) {
THROW_0(vmSymbols::java_lang_OutOfMemoryError());
} //Copy::fill_to_words((HeapWord*)x, sz / HeapWordSize);
return addr_to_java(x);
UNSAFE_ENDJVM通过malloc分配得到连续的缓冲区,这部分缓冲区可以直接作为缓冲区参数进行操作系统调用。
위 내용은 Java의 Buffer 소스 코드에 대한 심층 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7476
7476
 15
1377
52
77
11
49
19
19
31
15
1377
52
77
11
49
19
19
31

 소프트웨어 소스코드 보호에 있어서 Python의 응용실습
Jun 29, 2023 am 11:20 AM
소프트웨어 소스코드 보호에 있어서 Python의 응용실습
Jun 29, 2023 am 11:20 AM
고급 프로그래밍 언어인 Python 언어는 배우기 쉽고 읽고 쓰기 쉬우며 소프트웨어 개발 분야에서 널리 사용되었습니다. 그러나 Python의 오픈 소스 특성으로 인해 소스 코드는 다른 사람이 쉽게 액세스할 수 있으므로 소프트웨어 소스 코드 보호에 몇 가지 문제가 발생합니다. 따라서 실제 응용 프로그램에서는 Python 소스 코드를 보호하고 보안을 보장하기 위해 몇 가지 방법을 사용해야 하는 경우가 많습니다. 소프트웨어 소스 코드 보호에는 Python에서 선택할 수 있는 다양한 응용 사례가 있습니다. 다음은 몇 가지 일반적인 사항입니다.
 PHP 코드의 소스 코드를 해석 및 실행하지 않고 브라우저에 표시하는 방법은 무엇입니까?
Mar 11, 2024 am 10:54 AM
PHP 코드의 소스 코드를 해석 및 실행하지 않고 브라우저에 표시하는 방법은 무엇입니까?
Mar 11, 2024 am 10:54 AM
PHP 코드의 소스 코드를 해석 및 실행하지 않고 브라우저에 표시하는 방법은 무엇입니까? PHP는 동적 웹 페이지를 개발하는 데 일반적으로 사용되는 서버 측 스크립팅 언어입니다. 서버에서 PHP 파일이 요청되면 서버는 그 안에 있는 PHP 코드를 해석하고 실행한 후 최종 HTML 콘텐츠를 브라우저에 보내 표시합니다. 그러나 때때로 PHP 파일의 소스 코드를 실행하는 대신 브라우저에 직접 표시하고 싶을 때가 있습니다. 이 기사에서는 PHP 코드의 소스 코드를 해석 및 실행하지 않고 브라우저에 표시하는 방법을 소개합니다. PHP에서는 다음을 사용할 수 있습니다.
 심층 분석: Go 언어의 실제 성능 수준은 무엇입니까?
Jan 30, 2024 am 10:02 AM
심층 분석: Go 언어의 실제 성능 수준은 무엇입니까?
Jan 30, 2024 am 10:02 AM
심층 분석: Go 언어의 성능은 어떤가요? 소개: 오늘날의 소프트웨어 개발 세계에서는 성능이 중요한 요소입니다. 개발자의 경우 성능이 뛰어난 프로그래밍 언어를 선택하면 소프트웨어 애플리케이션의 효율성과 품질을 향상시킬 수 있습니다. 현대 프로그래밍 언어로서 Go 언어는 많은 개발자들에 의해 고성능 언어로 간주됩니다. 이번 글에서는 Go 언어의 성능 특성을 살펴보고, 구체적인 코드 예시를 통해 분석해보겠습니다. 1. 동시성 기능: Go 언어는 동시성을 기반으로 한 프로그래밍 언어로서 뛰어난 동시성 기능을 가지고 있습니다.
 소스 코드를 온라인으로 볼 수 있는 웹사이트
Jan 10, 2024 pm 03:31 PM
소스 코드를 온라인으로 볼 수 있는 웹사이트
Jan 10, 2024 pm 03:31 PM
브라우저의 개발자 도구를 사용하여 웹사이트의 소스 코드를 볼 수 있습니다. Google Chrome 브라우저에서: 1. Chrome 브라우저를 열고 소스 코드를 보려는 웹사이트를 방문합니다. 2. 웹의 아무 곳이나 마우스 오른쪽 버튼으로 클릭합니다. 페이지에서 "검사"를 선택하거나 단축키 Ctrl + Shift + I를 눌러 개발자 도구를 엽니다. 3. 개발자 도구의 상단 메뉴 표시줄에서 "요소" 탭을 선택합니다. 4. HTML 및 CSS 코드를 확인합니다. 웹사이트의.
 아이디어에서 Tomcat의 소스 코드를 보는 방법
Jan 25, 2024 pm 02:01 PM
아이디어에서 Tomcat의 소스 코드를 보는 방법
Jan 25, 2024 pm 02:01 PM
IDEA에서 Tomcat 소스 코드를 보는 단계: 1. Tomcat 소스 코드를 다운로드합니다. 3. Tomcat 소스 코드를 봅니다. 4. Tomcat의 작동 원리를 이해합니다. 7. 도구 및 플러그인 사용 8. 커뮤니티에 참여하고 기여합니다. 자세한 소개: 1. Tomcat 소스 코드 다운로드 Apache Tomcat 공식 웹사이트에서 소스 코드 패키지를 다운로드할 수 있습니다. 일반적으로 이러한 소스 코드 패키지는 ZIP 또는 TAR 형식 등입니다.
 Vue가 소스 코드를 표시할 수 있나요?
Jan 05, 2023 pm 03:17 PM
Vue가 소스 코드를 표시할 수 있나요?
Jan 05, 2023 pm 03:17 PM
Vue에서 소스 코드를 표시할 수 있습니다. 1. "git clone https://github.com/vuejs/vue.git"을 통해 vue를 가져옵니다. 2. "npm i"를 통해 종속성을 설치합니다. 3. "npm i -g Rollup"을 통해 롤업을 설치합니다. 4. 개발 스크립트를 수정합니다. 5. 소스 코드를 디버그합니다.
 golang 프레임워크 소스 코드 학습 및 적용에 대한 종합 가이드
Jun 01, 2024 pm 10:31 PM
golang 프레임워크 소스 코드 학습 및 적용에 대한 종합 가이드
Jun 01, 2024 pm 10:31 PM
Golang 프레임워크 소스 코드를 이해함으로써 개발자는 언어의 본질을 마스터하고 프레임워크의 기능을 확장할 수 있습니다. 먼저, 소스 코드를 얻고 해당 디렉토리 구조에 익숙해지십시오. 둘째, 코드를 읽고, 실행 흐름을 추적하고, 종속성을 이해합니다. 실제 사례에서는 이러한 지식을 적용하는 방법, 즉 맞춤형 미들웨어를 생성하고 라우팅 시스템을 확장하는 방법을 보여줍니다. 모범 사례에는 단계별 학습, 무의미한 복사 붙여넣기 방지, 도구 활용 및 온라인 리소스 참조가 포함됩니다.
 PHP 소스 코드 오류: 인덱스 오류 문제 해결
Mar 10, 2024 am 11:12 AM
PHP 소스 코드 오류: 인덱스 오류 문제 해결
Mar 10, 2024 am 11:12 AM
PHP 소스 코드 오류: 인덱스 오류 문제를 해결하려면 특정 코드 예제가 필요합니다. 인터넷의 급속한 발전으로 인해 개발자는 웹사이트와 애플리케이션을 작성할 때 다양한 문제에 직면하게 됩니다. 그 중 PHP는 널리 사용되는 서버 측 스크립팅 언어이며 소스 코드 오류는 개발자가 자주 직면하는 문제 중 하나입니다. 가끔 웹사이트의 인덱스 페이지를 열려고 하면 "InternalServerError", "Unde" 등 다양한 오류 메시지가 나타나는 경우가 있습니다.
