

Python 크롤러를 처음부터 작성하는 전체 기록

처음 9개의 글은 기초부터 작성까지 자세하게 소개되어 있으니, 크롤러 프로그램 작성 방법을 단계별로 자세히 기록하겠습니다.
먼저 이야기해 보세요. 우리 학교 웹사이트 정보:
http://jwxt.sdu.edu.cn:7777/zhxt_bks/zhxt_bks.html
점수를 확인하려면 로그인해야 하며, 그러면 각 과목의 점수가 표시됩니다. 단, 가중평균점수인 성적은 없습니다.

물론 이렇게 수동으로 성적을 계산하는 것은 매우 번거로운 작업입니다. 따라서 우리는 Python을 사용하여 이 문제를 해결하는 크롤러를 만들 수 있습니다.
1. 결전을 앞두고
먼저 도구를 준비해보자: HttpFox 플러그인.
페이지 요청 및 응답의 시간과 내용은 물론 브라우저에서 사용하는 COOKIE를 분석하는 http 프로토콜 분석 플러그인입니다.
예를 들어 Firefox에 설치하면 아래와 같은 효과가 나타납니다. 
해당 정보를 매우 직관적으로 볼 수 있습니다.
탐지를 시작하려면 시작을 클릭하고, 감지를 일시 중지하려면 중지를 클릭하고, 콘텐츠를 지우려면 지우기를 클릭하세요.
일반적으로 사용하기 전에 중지를 클릭하여 일시 중지한 다음 지우기를 클릭하여 화면을 지워 현재 페이지에 액세스하여 얻은 데이터를 볼 수 있는지 확인하세요.
2. 적진 깊숙이 침투하기
로그인 시 어떤 정보가 전송되는지 산동대학교 점수조회 사이트에 접속해 보겠습니다.
먼저 로그인 페이지로 이동하여 httpfox를 열고 이를 지운 다음 시작을 클릭하여 감지를 시작합니다.

개인 정보를 입력한 후 httpfox가 켜져 있는지 확인한 다음 확인을 클릭하여 정보를 제출하고 로그를 남깁니다. 안에.
이때 httpfox가 세 가지 정보를 감지한 것을 볼 수 있습니다:

이때 중지 버튼을 클릭하여 페이지 방문 후 피드백된 데이터가 캡처되었는지 확인하여 로그인을 시뮬레이션할 수 있습니다. 크롤러를 할 때.
3.庖丁解牛
얼핏 보면 3개의 데이터가 있는데, 2개는 GET이고 하나는 POST이지만, 여전히 그 데이터가 무엇인지, 어떻게 사용하는지 모릅니다.
그래서 캡처한 내용을 하나씩 살펴봐야 합니다.
POST 정보를 먼저 살펴보겠습니다.
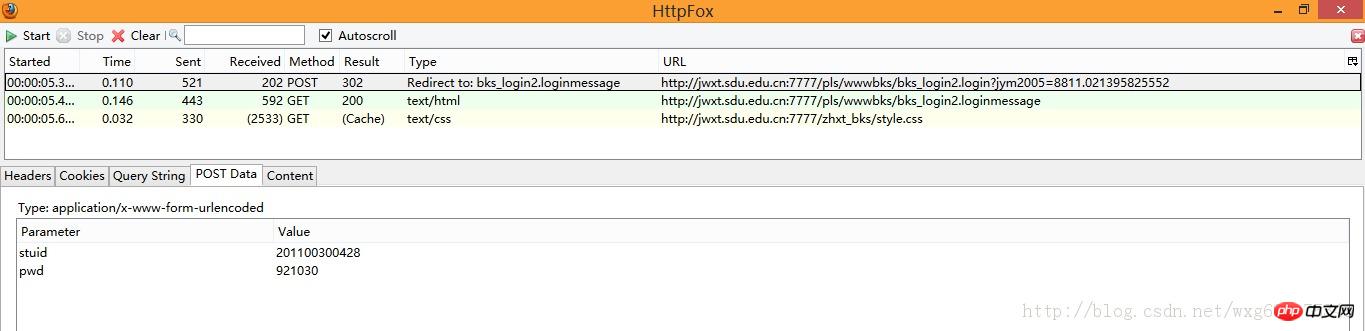
POST 정보이므로 PostData만 보면 됩니다.
POST 데이터에는 studid와 pwd라는 두 가지 데이터가 있는 것을 볼 수 있습니다.
그리고 Type의 Redirect to를 보면 POST가 완료된 후 bks_login2.loginmessage 페이지로 점프하는 것을 볼 수 있습니다.
이 데이터는 확인을 클릭한 후 제출한 양식 데이터임을 알 수 있습니다.
쿠키 정보를 보려면 쿠키 라벨을 클릭하세요.

예, 계정 쿠키가 수신되었으며 세션이 끝나면 자동으로 삭제됩니다.
그럼 제출 후 어떤 정보를 받으셨나요?
다음 두 개의 GET 데이터를 살펴보겠습니다.
먼저 첫 번째 내용을 살펴보겠습니다. 콘텐츠 태그를 클릭하면 받은 콘텐츠를 볼 수 있습니다. - 의심할 바 없이 HTML 소스 코드가 노출되어 있습니다:

이것은 단지 페이지의 HTML 소스 코드인 것 같습니다. 쿠키 관련 정보를 보려면 쿠키를 클릭하십시오:

아하, HTML 페이지의 원본 내용은 쿠키 정보가 전송된 후에 수신되었습니다.
마지막으로 수신된 메시지를 살펴보겠습니다.

대략 살펴보면 style.css라는 CSS 파일일 뿐이며 이는 우리에게 큰 영향을 주지 않습니다.
4. 침착하게 응답
이제 서버에 어떤 데이터를 보냈는지, 어떤 데이터를 받았는지 알았으니 기본 과정은 다음과 같습니다.
먼저 학생 ID와 비밀번호를 게시합니다--- > ;그런 다음 쿠키 값을 반환하고 쿠키를 서버로 보냅니다--->페이지 정보를 반환합니다. 성적 페이지에서 데이터를 얻고 정규식을 사용하여 성적과 학점을 별도로 추출하고 가중 평균을 계산합니다.
좋아요, 아주 간단한 샘플 종이처럼 보입니다. 그럼 한번 시험해 보겠습니다.
그런데 실험을 하기 전에 아직 해결되지 않은 문제가 있는데, POST 데이터는 어디로 전송되나요?
원본 페이지를 다시 보세요:

분명히 html 프레임워크를 사용하여 구현되었습니다. 즉, 주소 표시줄에 표시되는 주소는 오른쪽에 있는 양식을 제출하는 주소가 아닙니다.
실제 주소는 어떻게 알 수 있나요-. -페이지 소스 코드를 보려면 마우스 오른쪽 버튼을 클릭하세요.
예, 맞습니다. 이름이 "w_right"인 페이지가 우리가 원하는 로그인 페이지입니다.
웹사이트의 원래 주소는 다음과 같습니다:
http://jwxt.sdu.edu.cn:7777/zhxt_bks/zhxt_bks.html
따라서 실제 양식 제출 주소는 다음과 같습니다:
http://jwxt .sdu.edu.cn:7777/zhxt_bks/xk_login.html
입력한 결과 사실로 확인되었습니다.

청화대학교 수강신청 시스템으로 확인되었습니다. . . 내 생각엔 우리 학교가 페이지를 만드는 게 너무 게을러서 그냥 빌려온 것 같다. . 결과적으로 제목도 바뀌지 않았습니다. . .
하지만 이 페이지는 여전히 우리에게 필요한 페이지가 아닙니다. 왜냐하면 POST 데이터가 제출되는 페이지는 양식의 ACTION으로 제출된 페이지여야 하기 때문입니다.
즉, POST 데이터가 전송되는 위치를 알기 위해 소스 코드를 확인해야 합니다.

글쎄, 시각적으로 말하면 이것은 POST 데이터가 제출되는 주소입니다.
주소 표시줄에 정리하세요. 전체 주소는 다음과 같아야 합니다.
http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login
(얻는 방법은 다음과 같습니다. 아주 간단합니다. Firefox에서 찾아보세요. 링크 주소를 보려면 브라우저에서 직접 링크를 클릭하세요.)
5. 사용해 보세요
다음 작업은 Python을 사용하여 POST 데이터 전송을 시뮬레이션하고 반환된 쿠키 값 .
쿠키의 작동에 대해서는 다음 블로그 게시물을 읽어보실 수 있습니다:
http://www.jb51.net/article/57144.htm
먼저 POST 데이터를 준비한 후 쿠키 수신을 준비한 후 작성합니다. 소스 코드는 다음과 같습니다.
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:山东大学爬虫
# 版本:0.1
# 作者:why
# 日期:2013-07-12
# 语言:Python 2.7
# 操作:输入学号和密码
# 功能:输出成绩的加权平均值也就是绩点
#---------------------------------------
import urllib
import urllib2
import cookielib
cookie = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
#需要POST的数据#
postdata=urllib.urlencode({
'stuid':'201100300428',
'pwd':'921030'
})
#自定义一个请求#
req = urllib2.Request(
url = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login',
data = postdata
)
#访问该链接#
result = opener.open(req)
#打印返回的内容#
print result.read()이후 실행 효과를 살펴보세요.

이렇게 하면 시뮬레이션된 로그인이 성공한 것으로 계산됩니다.
6. 한 가지를 다른 것으로 대체하기
다음 작업은 크롤러를 사용하여 학생들의 점수를 얻는 것입니다.
출처 사이트를 다시 살펴보겠습니다.
HTTPFOX를 켠 후 클릭하여 결과를 보고 다음 데이터가 캡처된 것을 확인합니다.

첫 번째 GET 데이터를 클릭하고 내용을 보면 Content가 얻은 결과의 내용임을 알 수 있습니다.
얻은 페이지 링크는 마우스 오른쪽 버튼을 클릭하면 페이지 소스 코드에서 해당 요소를 볼 수 있고, 링크를 클릭하면 점프하는 페이지를 볼 수 있습니다(Firefox에서는 마우스 오른쪽 버튼을 클릭하고 "이 프레임 보기"만 하면 됩니다) ):

다음과 같이 결과를 볼 수 있는 링크를 얻을 수 있습니다:
http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bkscjcx.curscopre
7. 모든 것이 준비되었습니다
이제 모든 것이 준비되었으므로 크롤러에 링크를 적용하고 결과 페이지가 나타나는지 확인하십시오.
httpfox에서 볼 수 있듯이 점수 정보를 반환하려면 쿠키를 보내야 하므로 Python을 사용하여 점수 정보를 요청하는 쿠키 보내기를 시뮬레이션합니다.
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:山东大学爬虫
# 版本:0.1
# 作者:why
# 日期:2013-07-12
# 语言:Python 2.7
# 操作:输入学号和密码
# 功能:输出成绩的加权平均值也就是绩点
#---------------------------------------
import urllib
import urllib2
import cookielib
#初始化一个CookieJar来处理Cookie的信息#
cookie = cookielib.CookieJar()
#创建一个新的opener来使用我们的CookieJar#
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
#需要POST的数据#
postdata=urllib.urlencode({
'stuid':'201100300428',
'pwd':'921030'
})
#自定义一个请求#
req = urllib2.Request(
url = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login',
data = postdata
)
#访问该链接#
result = opener.open(req)
#打印返回的内容#
print result.read()
#打印cookie的值
for item in cookie:
print 'Cookie:Name = '+item.name
print 'Cookie:Value = '+item.value
#访问该链接#
result = opener.open('http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bkscjcx.curscopre')
#打印返回的内容#
print result.read()F5를 눌러 실행하고 살펴봅니다. 캡처된 데이터 :

이 방법으로는 문제가 없으므로 정규식을 사용하여 데이터를 약간 처리한 후 크레딧과 해당 점수를 추출합니다.
8. 손끝에서
이렇게 많은 양의 HTML 소스 코드는 확실히 처리에 도움이 되지 않습니다. 다음으로, 필요한 데이터를 추출하기 위해 정규식을 사용해야 합니다.
정규식에 대한 튜토리얼을 보려면 다음 블로그 게시물을 확인하세요.
http://www.jb51.net/article/57150.htm
결과의 소스 코드를 살펴보겠습니다.

이 경우 정규식을 사용하면 쉽습니다.
코드를 조금 정리한 다음 정규 표현식을 사용하여 데이터를 추출하겠습니다.
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:山东大学爬虫
# 版本:0.1
# 作者:why
# 日期:2013-07-12
# 语言:Python 2.7
# 操作:输入学号和密码
# 功能:输出成绩的加权平均值也就是绩点
#---------------------------------------
import urllib
import urllib2
import cookielib
import re
class SDU_Spider:
# 申明相关的属性
def __init__(self):
self.loginUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login' # 登录的url
self.resultUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bkscjcx.curscopre' # 显示成绩的url
self.cookieJar = cookielib.CookieJar() # 初始化一个CookieJar来处理Cookie的信息
self.postdata=urllib.urlencode({'stuid':'201100300428','pwd':'921030'}) # POST的数据
self.weights = [] #存储权重,也就是学分
self.points = [] #存储分数,也就是成绩
self.opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookieJar))
def sdu_init(self):
# 初始化链接并且获取cookie
myRequest = urllib2.Request(url = self.loginUrl,data = self.postdata) # 自定义一个请求
result = self.opener.open(myRequest) # 访问登录页面,获取到必须的cookie的值
result = self.opener.open(self.resultUrl) # 访问成绩页面,获得成绩的数据
# 打印返回的内容
# print result.read()
self.deal_data(result.read().decode('gbk'))
self.print_data(self.weights);
self.print_data(self.points);
# 将内容从页面代码中抠出来
def deal_data(self,myPage):
myItems = re.findall('<TR>.*?<p.*?<p.*?<p.*?<p.*?<p.*?>(.*?)</p>.*?<p.*?<p.*?>(.*?)</p>.*?</TR>',myPage,re.S) #获取到学分
for item in myItems:
self.weights.append(item[0].encode('gbk'))
self.points.append(item[1].encode('gbk'))
# 将内容从页面代码中抠出来
def print_data(self,items):
for item in items:
print item
#调用
mySpider = SDU_Spider()
mySpider.sdu_init()레벨이 제한되어 있고 정규 표현식이 약간 보기 흉합니다. 실행 효과는 그림에 표시된 것과 같습니다.

좋아, 다음은 데이터 처리입니다. .
9. 승리의 복귀
완성된 코드는 다음과 같습니다. 이 시점에서 완전한 크롤러 프로젝트가 완성됩니다.
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:山东大学爬虫
# 版本:0.1
# 作者:why
# 日期:2013-07-12
# 语言:Python 2.7
# 操作:输入学号和密码
# 功能:输出成绩的加权平均值也就是绩点
#---------------------------------------
import urllib
import urllib2
import cookielib
import re
import string
class SDU_Spider:
# 申明相关的属性
def __init__(self):
self.loginUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login' # 登录的url
self.resultUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bkscjcx.curscopre' # 显示成绩的url
self.cookieJar = cookielib.CookieJar() # 初始化一个CookieJar来处理Cookie的信息
self.postdata=urllib.urlencode({'stuid':'201100300428','pwd':'921030'}) # POST的数据
self.weights = [] #存储权重,也就是学分
self.points = [] #存储分数,也就是成绩
self.opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookieJar))
def sdu_init(self):
# 初始化链接并且获取cookie
myRequest = urllib2.Request(url = self.loginUrl,data = self.postdata) # 自定义一个请求
result = self.opener.open(myRequest) # 访问登录页面,获取到必须的cookie的值
result = self.opener.open(self.resultUrl) # 访问成绩页面,获得成绩的数据
# 打印返回的内容
# print result.read()
self.deal_data(result.read().decode('gbk'))
self.calculate_date();
# 将内容从页面代码中抠出来
def deal_data(self,myPage):
myItems = re.findall('<TR>.*?<p.*?<p.*?<p.*?<p.*?<p.*?>(.*?)</p>.*?<p.*?<p.*?>(.*?)</p>.*?</TR>',myPage,re.S) #获取到学分
for item in myItems:
self.weights.append(item[0].encode('gbk'))
self.points.append(item[1].encode('gbk'))
#计算绩点,如果成绩还没出来,或者成绩是优秀良好,就不运算该成绩
def calculate_date(self):
point = 0.0
weight = 0.0
for i in range(len(self.points)):
if(self.points[i].isdigit()):
point += string.atof(self.points[i])*string.atof(self.weights[i])
weight += string.atof(self.weights[i])
print point/weight
#调用
mySpider = SDU_Spider()
mySpider.sdu_init()위는 이 크롤러가 탄생하기까지의 전 과정을 자세하게 기록한 것입니다. 혹시 어떤 마술이라도 있는 걸까요? ? 하하, 농담이에요. 필요한 친구들이 참고해서 자유롭게 확장할 수 있어요
위 내용은 Python 크롤러를 처음부터 작성하는 전체 기록의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP는 주로 절차 적 프로그래밍이지만 객체 지향 프로그래밍 (OOP)도 지원합니다. Python은 OOP, 기능 및 절차 프로그래밍을 포함한 다양한 패러다임을 지원합니다. PHP는 웹 개발에 적합하며 Python은 데이터 분석 및 기계 학습과 같은 다양한 응용 프로그램에 적합합니다.
 PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP는 웹 개발 및 빠른 프로토 타이핑에 적합하며 Python은 데이터 과학 및 기계 학습에 적합합니다. 1.PHP는 간단한 구문과 함께 동적 웹 개발에 사용되며 빠른 개발에 적합합니다. 2. Python은 간결한 구문을 가지고 있으며 여러 분야에 적합하며 강력한 라이브러리 생태계가 있습니다.
 숭고한 코드 파이썬을 실행하는 방법
Apr 16, 2025 am 08:48 AM
숭고한 코드 파이썬을 실행하는 방법
Apr 16, 2025 am 08:48 AM
Sublime 텍스트로 Python 코드를 실행하려면 먼저 Python 플러그인을 설치 한 다음 .py 파일을 작성하고 코드를 작성한 다음 CTRL B를 눌러 코드를 실행하면 콘솔에 출력이 표시됩니다.
 PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP는 1994 년에 시작되었으며 Rasmuslerdorf에 의해 개발되었습니다. 원래 웹 사이트 방문자를 추적하는 데 사용되었으며 점차 서버 측 스크립팅 언어로 진화했으며 웹 개발에 널리 사용되었습니다. Python은 1980 년대 후반 Guidovan Rossum에 의해 개발되었으며 1991 년에 처음 출시되었습니다. 코드 가독성과 단순성을 강조하며 과학 컴퓨팅, 데이터 분석 및 기타 분야에 적합합니다.
 Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python은 부드러운 학습 곡선과 간결한 구문으로 초보자에게 더 적합합니다. JavaScript는 가파른 학습 곡선과 유연한 구문으로 프론트 엔드 개발에 적합합니다. 1. Python Syntax는 직관적이며 데이터 과학 및 백엔드 개발에 적합합니다. 2. JavaScript는 유연하며 프론트 엔드 및 서버 측 프로그래밍에서 널리 사용됩니다.
 Golang vs. Python : 성능 및 확장 성
Apr 19, 2025 am 12:18 AM
Golang vs. Python : 성능 및 확장 성
Apr 19, 2025 am 12:18 AM
Golang은 성능과 확장 성 측면에서 Python보다 낫습니다. 1) Golang의 컴파일 유형 특성과 효율적인 동시성 모델은 높은 동시성 시나리오에서 잘 수행합니다. 2) 해석 된 언어로서 파이썬은 천천히 실행되지만 Cython과 같은 도구를 통해 성능을 최적화 할 수 있습니다.
 vscode에서 코드를 작성하는 위치
Apr 15, 2025 pm 09:54 PM
vscode에서 코드를 작성하는 위치
Apr 15, 2025 pm 09:54 PM
Visual Studio Code (VSCODE)에서 코드를 작성하는 것은 간단하고 사용하기 쉽습니다. vscode를 설치하고, 프로젝트를 만들고, 언어를 선택하고, 파일을 만들고, 코드를 작성하고, 저장하고 실행합니다. VSCODE의 장점에는 크로스 플랫폼, 무료 및 오픈 소스, 강력한 기능, 풍부한 확장 및 경량 및 빠른가 포함됩니다.
 메모장으로 파이썬을 실행하는 방법
Apr 16, 2025 pm 07:33 PM
메모장으로 파이썬을 실행하는 방법
Apr 16, 2025 pm 07:33 PM
메모장에서 Python 코드를 실행하려면 Python 실행 파일 및 NPPEXEC 플러그인을 설치해야합니다. Python을 설치하고 경로를 추가 한 후 nppexec 플러그인의 명령 "Python"및 매개 변수 "{current_directory} {file_name}"을 구성하여 Notepad의 단축키 "F6"을 통해 Python 코드를 실행하십시오.
