

파이썬 시리즈 4
목차
재귀적 알고리즘 분석
버블 정렬 분석
-
데코레이터 분석
1. 재귀
1. 의 정의 recursion
수학과 컴퓨터 과학에서 재귀라고도 하는 재귀는 함수 정의에 함수 자체를 사용하는 방법을 말합니다. 재귀라는 용어는 자기 유사한 방식으로 사물을 반복하는 과정을 설명하기 위해 더 오랫동안 사용되기도 합니다.
F0 = 0F1 = 1
2. 재귀의 원리
(1) 예:
defth == 5= a1 += defth + 1== recursion(1, 0, 1(ret)
다음 그림은 전체 함수의 실행 과정을 보여줍니다. 녹색은 함수의 반환 값이 계층별로 반환됨을 나타냅니다. 실제로 재귀는 함수의 실행 흐름을 통해 다시 이 함수에 들어간 후, 조건을 통해 값을 반환한 후, 방금 실행 흐름에 따라 레이어별로 다시 반환을 하여 최종적으로 반환 값을 얻는 원리입니다. 하지만 반복할 때 주의할 점 두 가지:
1. 그의 조건은 그의 재귀가 특정 조건 내에서 값을 반환할 수 있어야 하며, 그렇지 않으면 컴퓨터 리소스가 고갈될 때까지 계속 반복됩니다(Python에는 개수에 제한이 있습니다). 재귀는 기본적으로)
2. 반환 값, 내부의 재귀 함수는 일반적으로 특정 반환 값을 제공해야 합니다. 그렇지 않으면 마지막 재귀가 반환될 때 원하는 값을 얻을 수 없습니다.

2. 버블 정렬
1. 버블 정렬 원리
버블 정렬은 간단한 정렬 알고리즘입니다. 그는 정렬할 순서를 반복적으로 살펴보며 한 번에 두 요소를 비교하고 순서가 잘못된 경우 교체합니다.
冒泡排序算法的运作如下: 1. 比较相邻的元素。如果第一个比第二个大,就交换他们两个。 2. 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。 3. 针对所有的元素重复以上的步骤,除了最后一个。 4. 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较
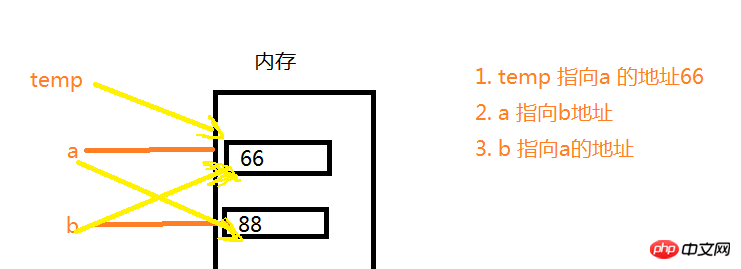
데이터 교환의 원리
주변변수를 이용하여 원래 값을 먼저 저장한 후 Point-to-Address 변환을 통해 데이터를 교환합니다. 참고: temp가 a를 가리키고, 이어서 a가 b를 가리킨다면 temp 자체의 시점은 변하지 않습니다. 아래 그림과 같이 a는 b를 가리키지만 temp는 여전히 a의 주소를 가리키므로 그대로입니다. 66
a = 66b = 88temp = a a = b b = temp
버블정렬의 원리
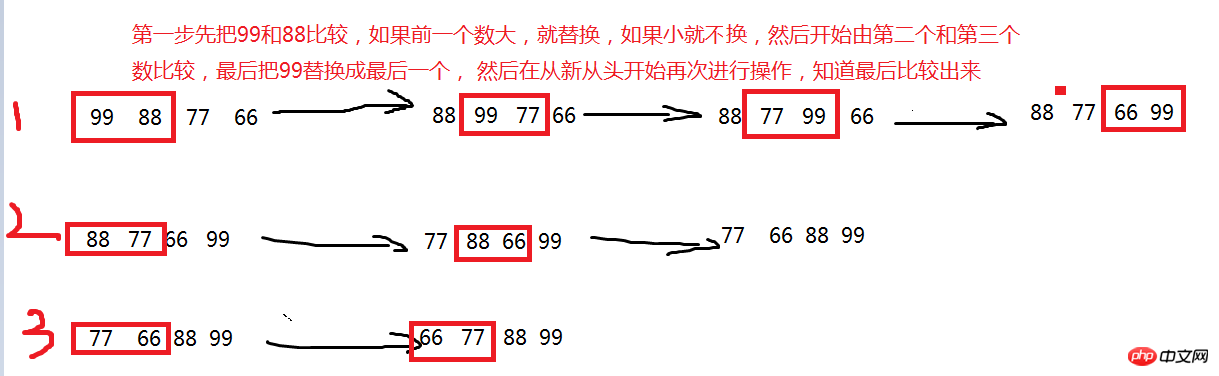
2. 버블정렬 예시
1 # -*- coding:utf-8 -*- 2 # zhou 3 # 2017/6/17 4 list = [0, 88, 99, 33, 22, 11, 1] 5 for j in range(1, len(list)): 6 for i in range(len(list) - j): 7 # 如果第一个数据大, 则交换数据, 否则, 不做改变 8 if list[i] > list[i + 1]: 9 temp = list[i]10 list[i] = list[i + 1]11 list[i + 1] = temp12 print(list)
3. 1. 데코레이터 정의
데코레이터란? 간단히 말해서 기능을 더욱 향상시키기 위해 소스 함수 코드를 변경하지 않고 코드를 미묘하게 확장한 것입니다. 데코레이터는 함수, 즉 다른 함수 위에 로드되는 함수입니다. 먼저 몇 가지 개념을 이해해 보겠습니다.
위에서 아래로, 즉 코드는 먼저 첫 번째 test1을 메모리에 로드한 다음 할당합니다. 두 번째 테스트를 저장할 새 메모리1.
이것이 첫 번째 test1이 890673481792로 변경된 지점이어야 합니다.
def test1():print('日本人.')print(id(test1))def test1():print('中国人.')print(id(test1))
test1()
执行结果:890673481656
890673481792中国人.로그인 후 복사
def test1():print('日本人.')print(id(test1))def test1():print('中国人.')print(id(test1))
test1()
执行结果:890673481656
890673481792中国人.<2>. 변수로서의 함수
다음 결과를 보면 함수명이 실제로 변수를 전달할 수 있는 변수임을 알 수 있습니다. functions
함수에 배정 됨 세 가지 함수가 여기에 정의되어 있습니다, test1, test2, test3, 3, 함수를 변수로 사용하면 괄호를 추가 할 수 없습니다. 함수 이름만 있으면 됩니다
(=<function test1 at 0x000000E2D403C7B8> <function test1 at 0x000000E2D403C7B8>
그 안에 1개가 중첩되어 있고, 1에 2개가 중첩되어 있습니다. 그 결과에서 함수의 실행 흐름도 볼 수 있어야 합니다.
rreee
2. 装饰器原理
(1). 装饰器的写法和使用
<1>. 装饰器也是一个函数
<2>. 使用装饰器的格式: 在一个函数前面加上:@装饰器的名字
(2). 装饰器的原理
<1>. 把test1函数当做一个变量传入outer中
func = test1
<2>. 把装饰器嵌套的一个函数inner赋值给test1
test1 = inner
<3>. 当执行test1函数的时候,就等于执行了inner函数,因此在最后的那个test1()命令其实执行的就是inner,因此先输出(你是哪国人)
<4>. 按照执行流执行到func函数的时候,其实执行的就是原来的test1函数,因此接着输出(我是中国人),并把它的返回值返回给了ret
<5>. 当原来的test1函数执行完了之后,继续执行inner里面的命令,因此输出了(Oh,hh, I love China.)
(3). 装饰器的总结
由上面的执行流可以看出来,其实装饰器把之前的函数当做参数传递进去,然后创建了另一个函数用来在原来的函数之前或者之后加上所需要的功能。
(=((
3. 带参数的装饰器
为了装饰器的高可用,一般都会采用下面的方式,也就是无论所用的函数是多少个参数,这个装饰器都可以使用
Python内部会自动的分配他的参数。
# -*- coding:utf-8 -*-# zhou# 2017/6/17def outer(func):def inner(a, *args, **kwargs):print('你是哪国人?')
ret = func(a, *args, **kwargs)print('Oh, hh, I love China.')return inner
@outerdef test1(a, *args, **kwargs):print('我是中国人.')
test1(1)3. 装饰器的嵌套
<1>. 第一层装饰器的简化(outer装饰器)
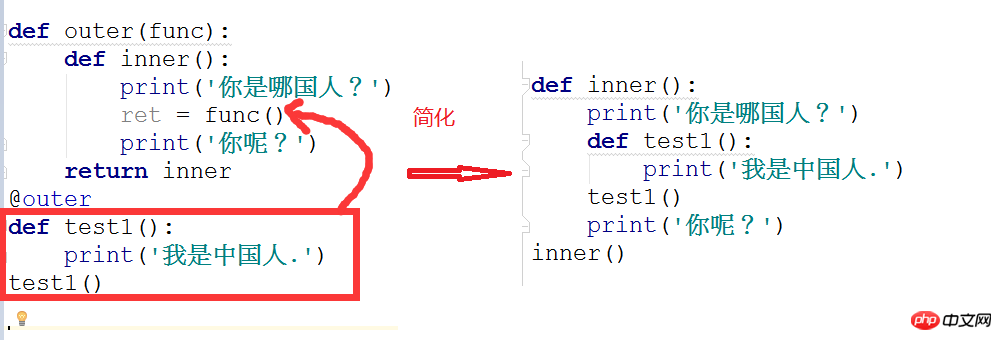
<2>. 第二层装饰器简化(outer0装饰器)

<3>. 装饰器嵌套攻击额,我们可以发现一层装饰器其实就是把原函数嵌套进另一个函数中间,因此我们只需要一层一层的剥开嵌套就可以了。
# -*- coding:utf-8 -*-# zhou# 2017/6/17def outer0(func):def inner():print('Hello, Kitty.')
ret = func()print('我是日本人.')return innerdef outer(func):def inner():print('你是哪国人?')
ret = func()print('你呢?')return inner
@outer0
@outerdef test1():print('我是中国人.')
test1()
结果Hello, Kitty.
你是哪国人?
我是中国人.
你呢?
我是日本人.
위 내용은 파이썬 시리즈 4의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7333
7333
 9
1627
14
1351
46
1262
25
1209
29
9
1627
14
1351
46
1262
25
1209
29

 한 데이터 프레임의 전체 열을 Python의 다른 구조를 가진 다른 데이터 프레임에 효율적으로 복사하는 방법은 무엇입니까?
Apr 01, 2025 pm 11:15 PM
한 데이터 프레임의 전체 열을 Python의 다른 구조를 가진 다른 데이터 프레임에 효율적으로 복사하는 방법은 무엇입니까?
Apr 01, 2025 pm 11:15 PM
Python의 Pandas 라이브러리를 사용할 때는 구조가 다른 두 데이터 프레임 사이에서 전체 열을 복사하는 방법이 일반적인 문제입니다. 두 개의 dats가 있다고 가정 해
 파이썬 매개 변수 주석이 문자열을 사용할 수 있습니까?
Apr 01, 2025 pm 08:39 PM
파이썬 매개 변수 주석이 문자열을 사용할 수 있습니까?
Apr 01, 2025 pm 08:39 PM
파이썬 프로그래밍에서 Python 매개 변수 주석의 대체 사용법, 매개 변수 주석은 개발자가 기능을 더 잘 이해하고 사용하는 데 도움이되는 매우 유용한 기능입니다 ...
 Python Cross-Platform 데스크탑 응용 프로그램 개발 : 어떤 GUI 라이브러리가 가장 적합합니까?
Apr 01, 2025 pm 05:24 PM
Python Cross-Platform 데스크탑 응용 프로그램 개발 : 어떤 GUI 라이브러리가 가장 적합합니까?
Apr 01, 2025 pm 05:24 PM
Python 크로스 플랫폼 데스크톱 응용 프로그램 개발 라이브러리 선택 많은 Python 개발자가 Windows 및 Linux 시스템 모두에서 실행할 수있는 데스크탑 응용 프로그램을 개발하고자합니다 ...
 Python 스크립트는 특정 위치에서 Cursor 위치로 출력을 어떻게 제거합니까?
Apr 01, 2025 pm 11:30 PM
Python 스크립트는 특정 위치에서 Cursor 위치로 출력을 어떻게 제거합니까?
Apr 01, 2025 pm 11:30 PM
Python 스크립트는 특정 위치에서 Cursor 위치로 출력을 어떻게 제거합니까? Python 스크립트를 작성할 때 이전 출력을 커서 위치로 지우는 것이 일반적입니다 ...
 내 코드가 API에 의해 데이터를 반환 할 수없는 이유는 무엇입니까? 이 문제를 해결하는 방법?
Apr 01, 2025 pm 08:09 PM
내 코드가 API에 의해 데이터를 반환 할 수없는 이유는 무엇입니까? 이 문제를 해결하는 방법?
Apr 01, 2025 pm 08:09 PM
내 코드가 API에 의해 데이터를 반환 할 수없는 이유는 무엇입니까? 프로그래밍에서 우리는 종종 API가 호출 될 때 NULL 값을 반환하는 문제를 겪는 경우가 종종 있습니다.
 Uvicorn은 Serving_forever ()없이 HTTP 요청을 어떻게 지속적으로 듣습니까?
Apr 01, 2025 pm 10:51 PM
Uvicorn은 Serving_forever ()없이 HTTP 요청을 어떻게 지속적으로 듣습니까?
Apr 01, 2025 pm 10:51 PM
Uvicorn은 HTTP 요청을 어떻게 지속적으로 듣습니까? Uvicorn은 ASGI를 기반으로 한 가벼운 웹 서버입니다. 핵심 기능 중 하나는 HTTP 요청을 듣고 진행하는 것입니다 ...
 문자열을 통해 객체를 동적으로 생성하고 방법을 파이썬으로 호출하는 방법은 무엇입니까?
Apr 01, 2025 pm 11:18 PM
문자열을 통해 객체를 동적으로 생성하고 방법을 파이썬으로 호출하는 방법은 무엇입니까?
Apr 01, 2025 pm 11:18 PM
파이썬에서 문자열을 통해 객체를 동적으로 생성하고 메소드를 호출하는 방법은 무엇입니까? 특히 구성 또는 실행 해야하는 경우 일반적인 프로그래밍 요구 사항입니다.
 파이썬 모래시 그래프 그리기 : 가변적 인 정의되지 않은 오류를 피하는 방법?
Apr 01, 2025 pm 06:27 PM
파이썬 모래시 그래프 그리기 : 가변적 인 정의되지 않은 오류를 피하는 방법?
Apr 01, 2025 pm 06:27 PM
Python : 모래 시계 그래픽 도면 및 입력 검증을 시작 하기이 기사는 모래 시계 그래픽 드로잉 프로그램에서 Python 초보자가 발생하는 변수 정의 문제를 해결합니다. 암호...
