
KNN 알고리즘의 전체 이름은 k-Nearest Neighbor이며, 이는 K 최근접 이웃을 의미합니다.
KNN은 서로 다른 특징값 간의 거리를 측정하여 분류하는 것이 기본 아이디어입니다.
알고리즘 프로세스는 다음과 같습니다.
1. 샘플 데이터 세트를 준비합니다(샘플의 각 데이터는 분류되었으며 분류 라벨이 있음).
2. 테스트 데이터를 입력합니다.
4. A와 샘플 세트의 각 데이터 사이의 거리를 계산합니다.
6. A에서 가장 작은 점을 선택합니다. 첫 번째 k 포인트의 빈도
8. 첫 번째 k 포인트의 빈도가 가장 높은 카테고리를 A의 예측 분류로 반환합니다.
주요 요인
사진의 빨간색 선은 맨해튼 거리를 나타내고, 녹색은 직선 거리인 유클리드 거리를 나타내며, 파란색과 노란색은 등가 맨해튼 거리를 나타냅니다. 맨해튼 거리 - 남북 방향의 두 지점 사이의 거리에 동서 방향의 거리를 더한 것입니다. 즉, d(i, j) = |xi-xj|+|yi-yj|입니다. 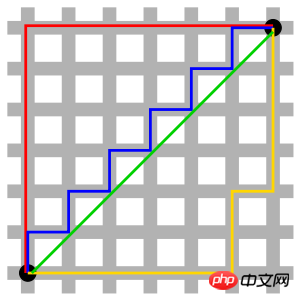
그리드의 거리 문제를 계산하는 데 사용됩니다. 
p=1이면 맨해튼 거리이고,
p=2이면 유클리드 거리입니다.
5. 표준화된 유클리드 거리(Standardized Euclidean distance)
표준화된 유클리드 거리(Standardized Euclidean distance)는 단순 유클리드 거리의 단점을 보완하기 위해 만들어진 개선 방안으로, 가중 유클리드 거리라고 볼 수 있습니다.
표준 유클리드 거리의 개념: 데이터의 각 차원 구성요소의 분포가 다르기 때문에 먼저 각 구성요소가 동일한 평균과 분산을 갖도록 "표준화"합니다.
6. Mahalanobis Distance
는 데이터의 공분산 거리를 나타냅니다.
알 수 없는 두 샘플 세트의 유사성을 계산하는 효과적인 방법입니다.
차원적으로 독립적이므로 변수 간 상관 관계로 인한 간섭을 제거할 수 있습니다.
7. 바타차리야 거리 통계에서 바타차리야 거리는 두 개의 이산 확률 분포를 측정하는 데 사용됩니다. 클래스 간 분리성을 측정하기 위해 분류에 자주 사용됩니다.
8. 해밍 거리
두 개의 동일한 길이 문자열 s1과 s2 사이의 해밍 거리는 둘 중 하나를 다른 문자열로 변경하는 데 필요한 최소 대체 수로 정의됩니다.
예를 들어 문자열 "1111"과 "1001" 사이의 해밍 거리는 2입니다.
적용:
정보 코딩(내결함성을 높이기 위해 코드 간 최소 해밍 거리를 최대한 크게 만들어야 함). 9. 끼인각의 코사인(Cosine)
기하학에서는 두 벡터의 방향 차이를 측정하는 데 사용할 수 있고, 데이터 마이닝에서는 차이를 측정하는 데 사용할 수 있습니다. 샘플 벡터 사이.
10. Jaccard 유사성 계수(Jaccard 유사성 계수)
Jaccard 거리는 모든 요소에 대한 두 세트의 서로 다른 요소의 비율을 사용하여 두 세트 간의 구별을 측정합니다.
Jaccard 유사성 계수를 사용하여 샘플의 유사성을 측정할 수 있습니다. 11. 피어슨 상관계수Pearson 곱적률 상관 계수라고도 하는 Pearson 상관 계수는 선형 상관 계수입니다. 피어슨 상관 계수는 두 변수 간의 선형 상관 정도를 반영하는 데 사용되는 통계입니다.
고차원이 거리 측정에 미치는 영향:
변수가 많을수록 유클리드 거리의 식별 능력은 더욱 저하됩니다.
변수 값 범위가 거리에 미치는 영향:
값 범위가 더 큰 변수는 거리 계산에서 지배적인 역할을 하는 경우가 많으므로 먼저 변수를 표준화해야 합니다.
k의 크기가 너무 작으면 분류 결과가 노이즈 포인트의 영향을 받기 쉽고 오류가 증가합니다.
k가 너무 크며 가장 가까운 이웃에 다른 카테고리의 포인트가 너무 많이 포함될 수 있습니다. 거리는 k 값을 줄일 수 있음 설정의 영향)
k=N(샘플 수)은 전혀 바람직하지 않습니다. 왜냐하면 이때 입력 인스턴스가 무엇이든 단순히 가장 많은 클래스에 속한다고 예측하기 때문입니다. 모델이 너무 단순하고 훈련 예제에서 유용한 정보를 많이 무시합니다.
실제 응용 분야에서 K 값은 일반적으로 교차 검증 방법(간단히 말하면 일부 샘플은 훈련 세트로 사용되고 일부 샘플은 테스트 세트로 사용됨)을 사용하여 최적의 값을 선택하는 등 상대적으로 작은 값을 사용합니다. K 값.
경험 법칙: k는 일반적으로 훈련 샘플 수의 제곱근보다 낮습니다.
1. 장점
간단하고, 이해하기 쉽고, 구현하기 쉽고, 정확도가 높으며, 이상치에 민감하지 않습니다.
2. 단점
KNN은 모델 구성이 매우 간단하지만, 모든 훈련 샘플이 필요하기 때문에 테스트 데이터를 분류하는 시스템 오버헤드가 큽니다. 스캔하고 거리를 계산했습니다.
숫자형과 명목형(유한한 수의 서로 다른 값을 가지며 값이 무질서함).
고객 이탈 예측, 사기 탐지 등
여기에서는 유클리드 거리를 기반으로 하는 KNN 알고리즘의 구현을 설명하기 위해 Python을 예로 사용합니다.
유클리드 거리 공식:

유클리드 거리를 예로 사용한 샘플 코드:
#! /usr/bin/env python#-*- coding:utf-8 -*-# E-Mail : Mike_Zhang@live.comimport mathclass KNN: def __init__(self,trainData,trainLabel,k):
self.trainData = trainData
self.trainLabel = trainLabel
self.k = k def predict(self,inputPoint):
retLable = "None"arr=[]for vector,lable in zip(self.trainData,self.trainLabel):
s = 0for i,n in enumerate(vector) :
s += (n-inputPoint[i]) ** 2arr.append([math.sqrt(s),lable])
arr = sorted(arr,key=lambda x:x[0])[:self.k]
dtmp = {}for k,v in arr :if not v in dtmp : dtmp[v]=0
dtmp[v] += 1retLable,_ = sorted(dtmp.items(),key=lambda x:x[1],reverse=True)[0] return retLable
data = [
[1.0, 1.1],
[1.0, 1.0],
[0.0, 0.0],
[0.0, 0.1],
[1.3, 1.1],
]
labels = ['A','A','B','B','A']
knn = KNN(data,labels,3)print knn.predict([1.2, 1.1])
print knn.predict([0.2, 0.1])위 구현은 상대적으로 간단하며 개발 시 scikit-learn과 같은 이미 만들어진 라이브러리를 사용할 수 있습니다.
손으로 쓴 숫자 인식
위 내용은 KNN 알고리즘에 대한 자세한 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



