

Python을 사용하여 Huaban.com에서 아름다운 사진을 캡처하세요.

一:前言
嘀嘀嘀,上车请刷卡。昨天看到了不错的图片分享网——花瓣,里面的图片质量还不错,所以利用selenium+xpath我把它的妹子的栏目下爬取了下来,以图片栏目名称给文件夹命名分类保存到电脑中。这个妹子主页 是动态加载的,如果想获取更多内容可以模拟下拉,这样就可以更多的图片资源。这种之前爬虫中也做过,但是因为网速不够快所以我就抓了19个栏目,一共500多张美图,也已经很满意了。
先看看效果:

二:运行环境
IDE:Pycharm
Python3.6
lxml 3.7.2
Selenium 3.4.0
requests 2.12.4
三:实例分析
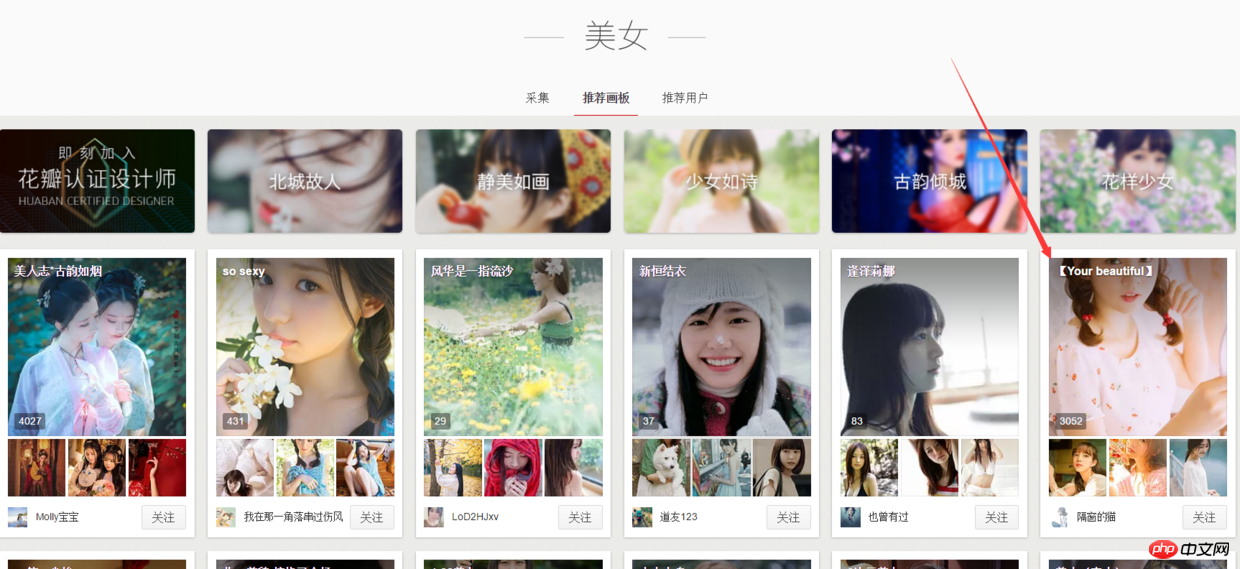
1.这次爬虫我开始做的思路是:进入这个网页然后来获取所有的图片栏目对应网址,然后进入每一个网页中去获取全部图片。(如下图所示)
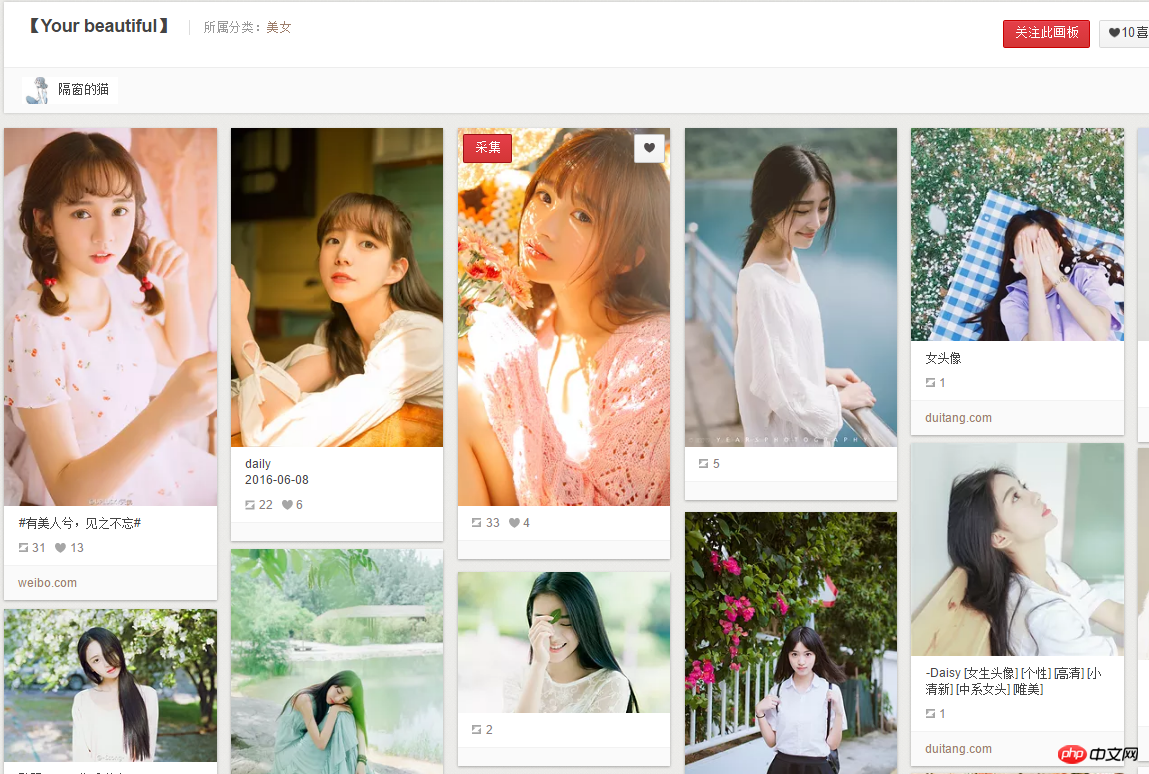
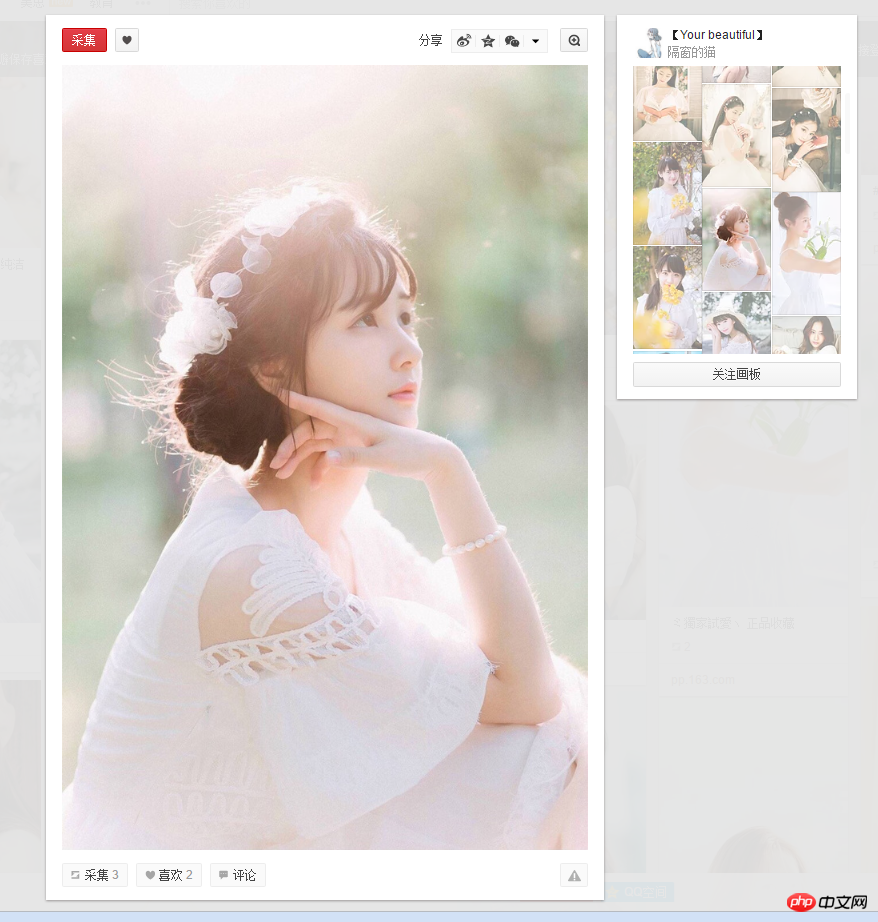
2.但是爬取获取的图片分辨率是236x354,图片质量不够高,但是那个时候已经是晚上1点30之后了,所以第二天做了另一个版本:在这个基础上再进入每个缩略图对应的网页,再抓取像下面这样高清的图片。
四:实战代码
1.第一步导入本次爬虫需要的模块
__author__ = '布咯咯_rieuse' from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.ui import WebDriverWait from selenium import webdriverimport requestsimport lxml.htmlimport os
2.下面是设置webdriver的种类,就是使用什么浏览器进行模拟,可以使用火狐来看它模拟的过程,也可以是无头浏览器PhantomJS来快速获取资源,['--load-images=false', '--disk-cache=true']这个意思是模拟浏览的时候不加载图片和缓存,这样运行速度会加快一些。WebDriverWait标明最大等待浏览器加载为10秒,set_window_size可以设置一下模拟浏览网页的大小。有些网站如果大小不到位,那么一些资源就不加载出来。
# SERVICE_ARGS = ['--load-images=false', '--disk-cache=true']# browser = webdriver.PhantomJS(service_args=SERVICE_ARGS)browser = webdriver.Firefox()wait = WebDriverWait(browser, 10)browser.set_window_size(1400, 900)
3.parser(url, param)这个函数用来解析网页,后面有几次都用用到这些代码,所以直接写一个函数会让代码看起来更整洁有序。函数有两个参数:一个是网址,另一个是显性等待代表的部分,这个可以是网页中的某些板块,按钮,图片等等...
def parser(url, param):
browser.get(url)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, param)))
html = browser.page_source
doc = lxml.html.fromstring(html)return doc4.下面的代码就是解析本次主页面 然后获取到每个栏目的网址和栏目的名称,使用xpath来获取栏目的网页时,进入网页开发者模式后,如图所示进行操作。之后需要用栏目名称在电脑中建立文件夹,所以在这个网页中要获取到栏目的名称,这里遇到一个问题,一些名称不符合文件命名规则要剔除,我这里就是一个 * 影响了。
def get_main_url():
print('打开主页搜寻链接中...')try:
doc = parser('http://huaban.com/boards/favorite/beauty/', '#waterfall')
name = doc.xpath('//*[@id="waterfall"]/div/a[1]/div[2]/h3/text()')
u = doc.xpath('//*[@id="waterfall"]/div/a[1]/@href')for item, fileName in zip(u, name):
main_url = 'http://huaban.com' + item
print('主链接已找到' + main_url)if '*' in fileName:
fileName = fileName.replace('*', '')
download(main_url, fileName)except Exception as e:
print(e)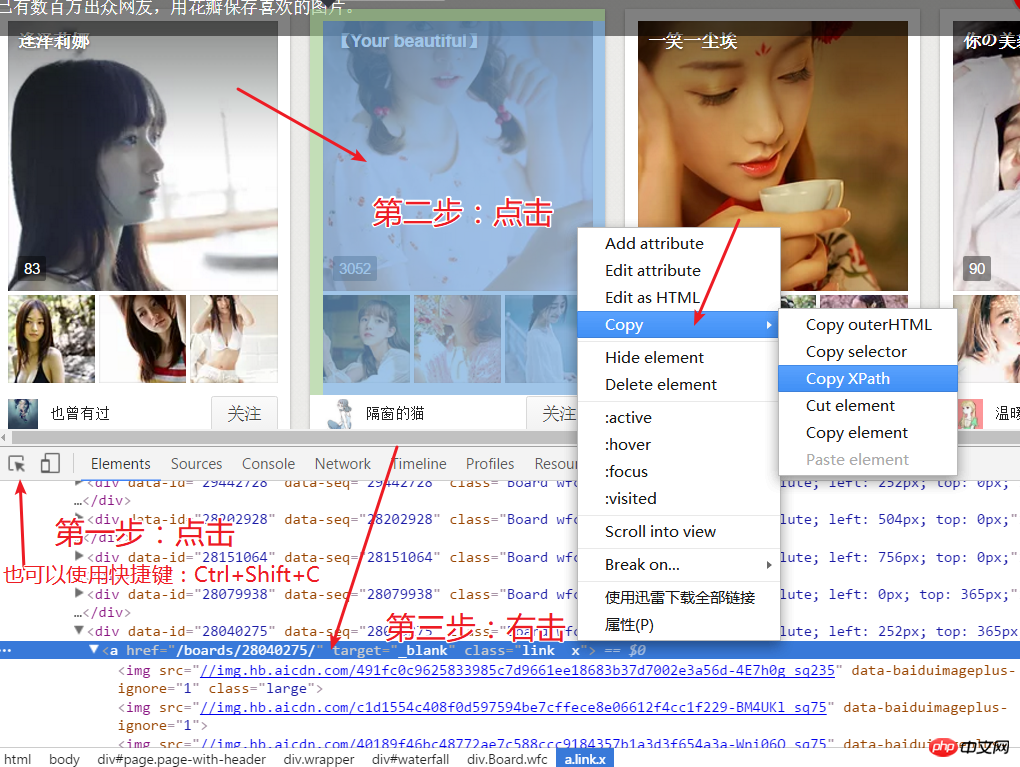
5.前面已经获取到栏目的网页和栏目的名称,这里就需要对栏目的网页分析,进入栏目网页后,只是一些缩略图,我们不想要这些低分辨率的图片,所以要再进入每个缩略图中,解析网页获取到真正的高清图片网址。这里也有一个地方比较坑人,就是一个栏目中,不同的图片存放dom格式不一样,所以我这样做
img_url = doc.xpath('//*[@id="baidu_image_holder"]/a/img/@src') img_url2 = doc.xpath('//*[@id="baidu_image_holder"]/img/@src')
这就把两种dom格式中的图片地址都获取了,然后把两个地址list合并一下。img_url +=img_url2
在本地创建文件夹使用filename = 'image\{}\'.format(fileName) + str(i) + '.jpg'表示文件保存在与这个爬虫代码同级目录image下,然后获取的图片保存在image中按照之前获取的栏目名称的文件夹中。
def download(main_url, fileName):
print('-------准备下载中-------')try:
doc = parser(main_url, '#waterfall')if not os.path.exists('image\\' + fileName):
print('创建文件夹...')
os.makedirs('image\\' + fileName)
link = doc.xpath('//*[@id="waterfall"]/div/a/@href')# print(link)
i = 0for item in link:
i += 1
minor_url = 'http://huaban.com' + item
doc = parser(minor_url, '#pin_view_page')
img_url = doc.xpath('//*[@id="baidu_image_holder"]/a/img/@src')
img_url2 = doc.xpath('//*[@id="baidu_image_holder"]/img/@src')
img_url +=img_url2try:
url = 'http:' + str(img_url[0])
print('正在下载第' + str(i) + '张图片,地址:' + url)
r = requests.get(url)
filename = 'image\\{}\\'.format(fileName) + str(i) + '.jpg'with open(filename, 'wb') as fo:
fo.write(r.content)except Exception:
print('出错了!')except Exception:
print('出错啦!')if __name__ == '__main__':
get_main_url()五:总结
这次爬虫继续练习了Selenium和xpath的使用,在网页分析的时候也遇到很多问题,只有不断练习才能把自己不会部分减少,当然这次爬取了500多张妹纸还是挺养眼的。
위 내용은 Python을 사용하여 Huaban.com에서 아름다운 사진을 캡처하세요.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7681
7681
 15
1639
14
1393
52
1286
25
1229
29
15
1639
14
1393
52
1286
25
1229
29

 PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP는 주로 절차 적 프로그래밍이지만 객체 지향 프로그래밍 (OOP)도 지원합니다. Python은 OOP, 기능 및 절차 프로그래밍을 포함한 다양한 패러다임을 지원합니다. PHP는 웹 개발에 적합하며 Python은 데이터 분석 및 기계 학습과 같은 다양한 응용 프로그램에 적합합니다.
 PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP는 웹 개발 및 빠른 프로토 타이핑에 적합하며 Python은 데이터 과학 및 기계 학습에 적합합니다. 1.PHP는 간단한 구문과 함께 동적 웹 개발에 사용되며 빠른 개발에 적합합니다. 2. Python은 간결한 구문을 가지고 있으며 여러 분야에 적합하며 강력한 라이브러리 생태계가 있습니다.
 Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python은 부드러운 학습 곡선과 간결한 구문으로 초보자에게 더 적합합니다. JavaScript는 가파른 학습 곡선과 유연한 구문으로 프론트 엔드 개발에 적합합니다. 1. Python Syntax는 직관적이며 데이터 과학 및 백엔드 개발에 적합합니다. 2. JavaScript는 유연하며 프론트 엔드 및 서버 측 프로그래밍에서 널리 사용됩니다.
 VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VS 코드 확장은 악의적 인 코드 숨기기, 취약성 악용 및 합법적 인 확장으로 자위하는 등 악성 위험을 초래합니다. 악의적 인 확장을 식별하는 방법에는 게시자 확인, 주석 읽기, 코드 확인 및주의해서 설치가 포함됩니다. 보안 조치에는 보안 인식, 좋은 습관, 정기적 인 업데이트 및 바이러스 백신 소프트웨어도 포함됩니다.
 Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
VS 코드는 파이썬을 작성하는 데 사용될 수 있으며 파이썬 애플리케이션을 개발하기에 이상적인 도구가되는 많은 기능을 제공합니다. 사용자는 다음을 수행 할 수 있습니다. Python 확장 기능을 설치하여 코드 완료, 구문 강조 및 디버깅과 같은 기능을 얻습니다. 디버거를 사용하여 코드를 단계별로 추적하고 오류를 찾아 수정하십시오. 버전 제어를 위해 git을 통합합니다. 코드 서식 도구를 사용하여 코드 일관성을 유지하십시오. 라인 도구를 사용하여 잠재적 인 문제를 미리 발견하십시오.
 Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
VS 코드는 Windows 8에서 실행될 수 있지만 경험은 크지 않을 수 있습니다. 먼저 시스템이 최신 패치로 업데이트되었는지 확인한 다음 시스템 아키텍처와 일치하는 VS 코드 설치 패키지를 다운로드하여 프롬프트대로 설치하십시오. 설치 후 일부 확장은 Windows 8과 호환되지 않을 수 있으며 대체 확장을 찾거나 가상 시스템에서 새로운 Windows 시스템을 사용해야합니다. 필요한 연장을 설치하여 제대로 작동하는지 확인하십시오. Windows 8에서는 VS 코드가 가능하지만 더 나은 개발 경험과 보안을 위해 새로운 Windows 시스템으로 업그레이드하는 것이 좋습니다.
 터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
vs 코드에서는 다음 단계를 통해 터미널에서 프로그램을 실행할 수 있습니다. 코드를 준비하고 통합 터미널을 열어 코드 디렉토리가 터미널 작업 디렉토리와 일치하는지 확인하십시오. 프로그래밍 언어 (예 : Python의 Python Your_file_name.py)에 따라 실행 명령을 선택하여 성공적으로 실행되는지 여부를 확인하고 오류를 해결하십시오. 디버거를 사용하여 디버깅 효율을 향상시킵니다.
 PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP는 1994 년에 시작되었으며 Rasmuslerdorf에 의해 개발되었습니다. 원래 웹 사이트 방문자를 추적하는 데 사용되었으며 점차 서버 측 스크립팅 언어로 진화했으며 웹 개발에 널리 사용되었습니다. Python은 1980 년대 후반 Guidovan Rossum에 의해 개발되었으며 1991 년에 처음 출시되었습니다. 코드 가독성과 단순성을 강조하며 과학 컴퓨팅, 데이터 분석 및 기타 분야에 적합합니다.
