

JVM 메모리 영역 분할 및 가비지 수집 메커니즘에 대한 자세한 설명
우리가 Java 코드를 작성할 때 대부분의 경우 New 객체가 릴리스되는지 여부와 시기를 신경 쓸 필요가 없습니다. JVM에는 자동 가비지 수집 메커니즘이 있기 때문입니다. 이전 블로그에서 Objective-C의 MRC(수동 참조 카운팅)과 ARC(자동 참조 카운팅)의 메모리 관리 방법에 대해 이야기했는데, 이에 대해서는 아래에서 검토하겠습니다. 현재 JVM 메모리 재활용 메커니즘은 참조 카운팅을 사용하지 않고 주로 "복사 재활용" 및 "적응 재활용"을 사용합니다.
물론 위의 두 가지 알고리즘 외에도 다른 알고리즘도 있는데, 이에 대해서도 아래에서 소개하겠습니다. 이번 블로그에서는 먼저 JVM의 지역 구분에 대해 간략하게 설명하고, 이를 바탕으로 JVM의 가비지 수집 메커니즘을 소개하겠습니다.
1. JVM 메모리 영역 분할에 대한 간략한 설명
물론 이 부분에서는 JVM 메모리 영역 분할에 대해 간략하게 설명하여 아래의 가비지 수집 메커니즘을 확장할 수 있는 길을 열어줍니다. 물론 인터넷에는 JVM 메모리 영역 분할에 대한 자세한 정보가 많이 있으므로 직접 Google에서 검색해 보세요.
JVM 메모리 영역 구분을 기준으로 간단히 아래와 같이 다이어그램을 그렸습니다. 영역은 크게 두 개의 블록으로 나뉘는데, 그 중 하나가 Heap입니다. 우리가 생성하는 객체는 힙 영역에 할당됩니다. C 언어의 malloc 할당 방법은 힙 영역에서 가져옵니다. 가비지 컬렉터는 주로 힙 영역의 메모리를 재활용합니다.
또 다른 부분은 비힙 영역입니다. 비힙 영역은 주로 로컬 코드를 컴파일하고 저장하는 데 사용되는 "코드 캐시 영역(Code Cache)"과 "영원한 생성()"을 포함합니다. Perm Gen)", "Java Virtual Machine Stack(JVM Stack)", "Local Method Stack(Local Method Stack)"은 JVM 자체의 정적 데이터를 저장하고, 이를 기록합니다. 메소드 호출 순서
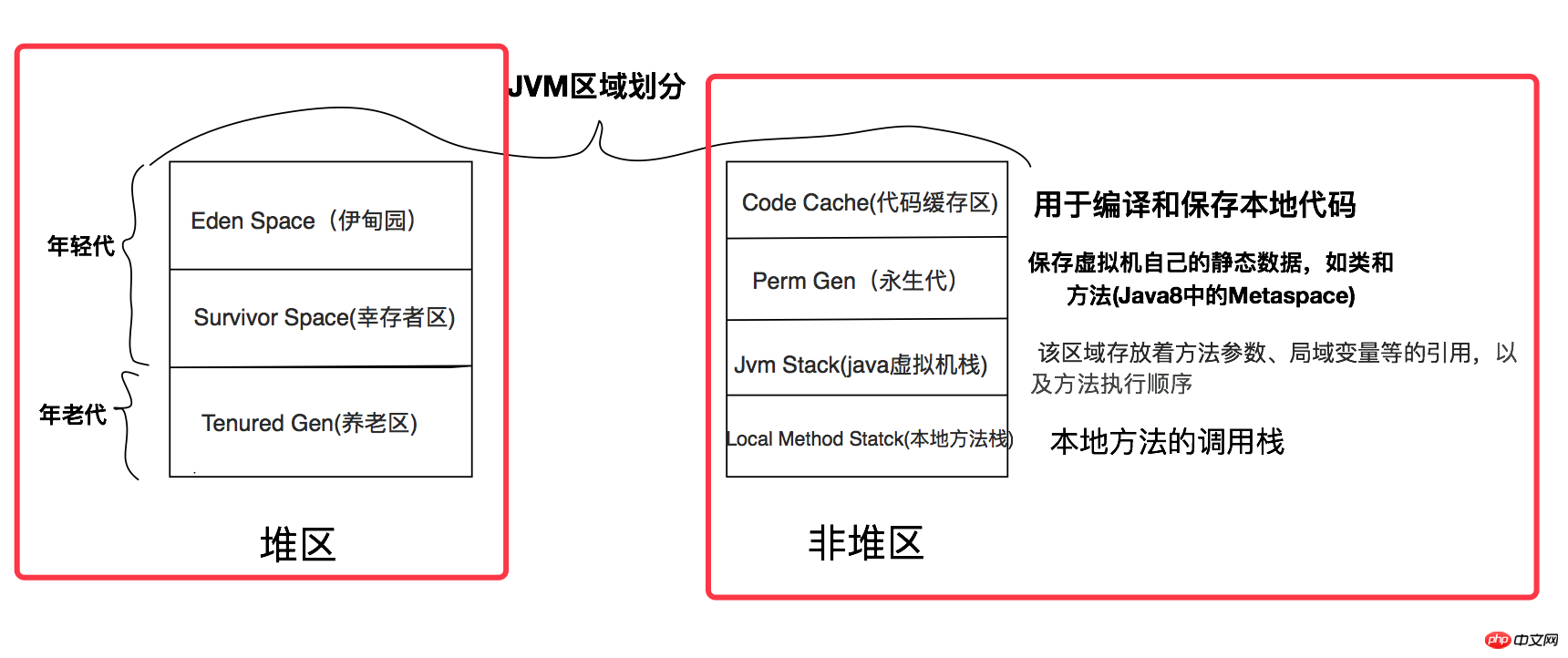
가비지 컬렉터는 주로 힙 영역에서 사용하지 않는 메모리 영역을 복구하고 해당 영역을 정리합니다. 힙 영역에서는 객체 메모리의 생존 시간이나 객체의 크기를 기준으로 "젊은 세대"와 "구세대"로 구분됩니다. "젊은 세대"의 객체는 불안정하고 쓰레기를 생성하기 쉬운 반면, "구세대"의 객체는 상대적으로 안정적이며 쓰레기를 생성할 가능성이 적습니다. 분리된 이유는 서로 다른 영역의 메모리 블록 특성에 따라 서로 다른 메모리 복구 알고리즘을 채택하여 힙 영역의 가비지 수집 효율성을 높이기 위한 것입니다. 자세한 소개는 아래에서 하겠습니다.
2. 일반적인 메모리 재활용 알고리즘 소개 위에서
JVM의 메모리 영역 구분에 대해 간략하게 이해했습니다. 다음으로 몇 가지 일반적인 메모리 재활용 알고리즘을 살펴보겠습니다. 물론, 아래에서 소개하는 메모리 재활용 알고리즘은 JVM에서만 사용되는 것이 아니라 OC에서도 메모리 재활용 방법을 검토해 보겠습니다. 다음은 주로 "참조 카운팅 재활용", "복사 재활용", "표시 분류 재활용", "세대 재활용"을 포함합니다.
1. 참조 카운팅(Reference Count) 메모리 재활용 메커니즘은 현재 Objective-C 및
Swift언어에서도 사용되는 메모리 재활용 메커니즘입니다. 우리 블로그에서 참조 계산 메모리 재활용에 대해 자세히 설명했습니다. 참조가 있는 한 참조 카운트는 1씩 증가합니다. 참조 횟수가 0에 도달하면 메모리 블록이 재활용됩니다. 물론 이 메모리 정리 방법은 "참조 사이클"을 쉽게 형성할 수 있습니다. Objective-C의 참조 횟수에서 순환 참조로 인해 발생하는 메모리 누수 문제에서 변수는 약한 유형 또는 강한 유형으로 선언될 수 있습니다. 즉, 참조를 "
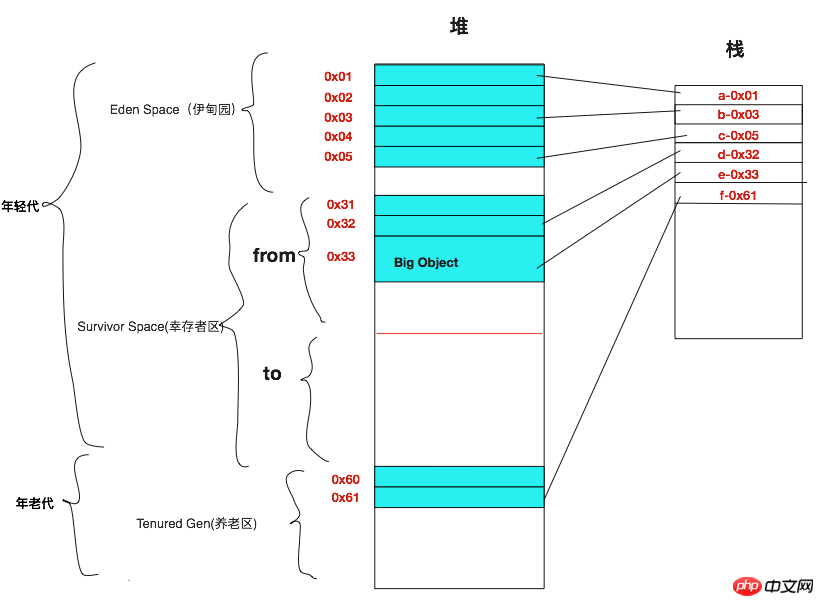
강한 참조" 또는 "약한 참조"로 정의할 수 있습니다. "강한 참조 순환"이 발생하면 참조 중 하나를 약한 유형으로 설정할 수 있습니다. 그러면 이 강력한 참조 순환이 깨지고 "메모리 누수" 문제가 발생하지 않습니다. "Reference Counted Memory Recycling"에 대한 보다 자세한 내용은 이전에 게시된 OC 콘텐츠 관련 블로그를 참조하시기 바랍니다. 참조 카운팅이 어떻게 작동하는지 더 명확하게 이해하기 위해 아래 그림을 간단히 그렸습니다. 왼쪽 스택의 세 참조 a, b, c는 힙의 서로 다른 영역 블록을 가리킵니다. 힙의 메모리 영역 블록에서 이 영역에 대한 강력한 참조가 있으면 해당 keepCount가 1씩 증가합니다. 약한 참조가 있는 경우, keepCount는 1씩 증가하지 않습니다. 먼저 a가 참조하는 첫 번째 메모리 영역을 살펴보겠습니다. 이 메모리 블록은 a에 의해서만 강력하게 참조되므로, a가 더 이상 이 메모리 영역을 참조하지 않으면 keepCount=0이 되고 메모리는 재활용. 이 경우 메모리 누수가 발생하지 않습니다. b가 가리키는 메모리 영역 2를 살펴보겠습니다. b와 메모리 블록 3은 모두 메모리 블록 2에 대한 강력한 참조를 가지므로 2의 retainCount=2입니다. 메모리 블록 2에도 메모리 블록 3에 대한 강력한 참조가 있으므로 3의 keepCount=1입니다. 따라서 b가 가리키는 메모리 영역에는 "강력한 참조 순환"이 있습니다. 왜냐하면 b가 더 이상 이 메모리 영역을 가리키지 않으면 rc=2는 rc=1이 되기 때문입니다. keepCount가 0이 아니기 때문에 이 두 메모리 영역은 해제되지 않고, 2개도 해제되지 않으므로 당연히 세 개의 메모리 영역은 해제되지 않지만 이 메모리 영역은 다시 사용되지 않으므로 " 메모리 누수' 상황. 이 두 메모리 영역이 특히 크다면 그 결과는 심각할 것이라고 상상할 수 있습니다. c 참조와 마찬가지로 참조 체인 중 하나가 약한 참조이기 때문에 "강한 참조 순환"이 발생하지 않습니다. c가 더 이상 네 번째 메모리 블록을 참조하지 않으면 rc는 1에서 0으로 변경되고 블록 영역은 즉시 해제됩니다. 메모리 블록 4가 해제된 후 메모리 블록 5의 rc는 1에서 0으로 변경되고 메모리 블록 5도 해제됩니다. 이 경우 메모리 누수는 발생하지 않습니다. Objective-C에서는 이 방법을 사용하여 메모리를 재활용합니다. 물론 OC에는 "강한 참조"와 "약한 참조" 외에 자동 해제 풀도 있습니다. 즉, Autorealease 유형 참조는 keepCount = 0일 때 즉시 해제되지 않지만, 자동 해제 풀에서 나올 때 해제됩니다. 여기서는 자세히 설명하지 않겠습니다. 2. 복사 메모리 재활용 참조 카운팅 재활용에 대해 이야기한 후, 우리는 ""으로 인한 메모리 누수 문제를 쉽게 해결할 수 있다는 것을 알았습니다. 순환 참조" 질문, "강한 참조"와 "약한 참조"라는 개념이 OC에 도입되었습니다. 다음으로 복사 메모리 재활용 메커니즘을 살펴보겠습니다. 이 메커니즘에서는 "순환 참조" 문제를 걱정할 필요가 없습니다. 간단히 말해서 복사 기반 재활용의 핵심은 "복사"이지만 전제는 조건부 복사입니다. 가비지 수집 중에 "라이브 개체"는 다른 빈 힙 영역에 복사된 다음 이전 영역이 함께 지워집니다. "라이브 객체"는 객체의 참조 체인을 따라 "스택"에서 도달할 수 있는 객체를 나타냅니다. 물론, 라이브 객체를 새로운 "힙 영역"에 복사한 후에는 스택 영역에 대한 참조도 수정해야 합니다. 아래는 우리가 그린 복사형 재활용의 단순화된 다이어그램입니다. 이는 주로 힙을 두 부분으로 나눕니다. 가비지 수집 중에 한 힙에 있는 활성 개체가 다른 힙에 복사됩니다. 아래의 힙 1 영역은 현재 사용 중인 블록이고, 힙 2 영역은 여유 영역입니다. 힙 영역 1의 표시되지 않은 메모리 블록, 즉 2와 3은 재활용할 가비지 개체입니다. 그리고 1, 4, 5는 복사할 '살아있는 객체'이다. 블록 1은 스택의 a를 따라 도달할 수 있고 블록 4와 5는 c를 따라 도달할 수 있기 때문입니다. 블록 2와 3에는 참조가 있지만 비힙 영역에서 온 것이 아닙니다. 즉, 2와 3의 참조는 모두 힙 영역의 참조이므로 재활용 대상입니다. 라이브 객체를 찾은 후 다음으로 할 일은 라이브 객체를 복사하여 힙 2 영역에 복사하는 것입니다. 물론, 힙 영역 2에 복사된 객체 간의 메모리 주소는 연속적입니다. 새로운 메모리 공간을 할당하려면 힙의 여유 공간에서 직접 할당하면 됩니다. 이는 메모리 공간을 할당할 때 더 효율적입니다. 객체를 복사한 후 "비힙 영역"의 참조 주소를 수정해야 합니다. 아래 그림과 같습니다. 복사 완료 후 힙 영역의 모든 메모리 공간을 직접 재활용할 수 있습니다. 2. 복사 및 재활용 후 최종 결과는 다음과 같습니다. 하위 힙 영역 1이 지워진 후 복사된 개체를 받을 수 있습니다. 힙 영역 2에서 가비지 수집이 수행되면 힙 영역 2의 활성 개체가 힙 영역 1로 복사됩니다. 이 예에서 메모리 가비지가 많을 때 복사된 객체 수가 상대적으로 적고 이전 힙 공간을 직접 정리할 수 있기 때문에 "복사" 가비지 수집의 효율성이 여전히 상대적으로 높다는 것을 알 수 있습니다. 청산. 그러나 상대적으로 쓰레기가 적은 경우 이 방법은 많은 수의 라이브 개체를 복사하므로 효율성은 여전히 상대적으로 낮습니다. 이 방법은 또한 힙 저장 공간을 절반으로 나눕니다. 즉, 절반은 항상 무료이며, 힙 공간의 활용률은 높지 않습니다. 3. 마크 압축 복구 알고리즘 위의 "복사" 가비지 수집 프로세스를 통해 우리는 쓰레기가 많을 때 효율성이 상대적으로 높다는 것을 알고 있습니다. 쓰레기가 거의 없으면 작업 방법 효율성이 상대적으로 낮습니다. 그럼 다음으로 또 다른 마크 압축 재활용 알고리즘을 소개하겠습니다. 이 알고리즘은 쓰레기가 적을 때 더 효율적이지만, 쓰레기가 많으면 효율성이 높지 않습니다. "Copying" 보완적. 아래에서는 마크 압축 재활용 알고리즘을 소개합니다. 마킹 - 압축의 첫 번째 단계는 마킹이며, 이를 위해서는 힙 영역에 "live object"을 표시해야 합니다. 위 내용에서 "살아있는 물체"가 무엇인지에 대해서는 이미 이야기했으므로 여기서는 자세히 설명하지 않겠습니다. "라이브 객체"의 특성을 보면 아래의 라이브 객체는 메모리 영역 1과 3이므로 표시해 두는 것을 알 수 있습니다. 마킹이 완료된 후 압축을 시작하고 라이브 개체를 "힙 영역"의 섹션으로 압축한 다음 나머지 부분을 지웁니다. 아래는 두 개의 생명체 1과 3을 압축한 것입니다. 압축 후 아래 공간을 깨끗이 청소해 주세요. 즉, Clean 부분에서는 새로운 객체를 할당할 수 있다. 아래 스크린샷은 마크 압축 및 클리닝 후의 상태입니다. 표시 압축된 가비지 수집은 힙 영역의 공간을 최대한 활용할 수 있습니다. 가비지가 상대적으로 적고 가비지가 너무 많고 조각화가 심각한 경우에는 더 많은 "살아있는 객체"가 이동되며 이 처리 방법이 상대적으로 효율적입니다. 효율성이 상대적으로 낮습니다. 이 방법을 "복사"와 함께 사용하여 현재 힙 영역의 가비지 상태를 기반으로 재활용 방법을 선택할 수 있습니다. "복사"의 장점을 정확하게 보완합니다. "복사"와 "표시-압축" 재활용 방법을 통합한 알고리즘은 "세대별" 가비지 수집 메커니즘이며, 이에 대해 아래에서 자세히 소개합니다. 4. 세대별 가비지 수집 "세대"는 개체의 쓰레기 발생 가능성이 높은 상태나 분할할 수 있는 개체의 크기에 따라 여러 세대로 나누는 것을 의미합니다. "젊은세대", "기성세대", "영구세대"로 나뉜다. "영구 세대"는 힙에 없으므로 다시 논의하지 않습니다. 세대별 가비지 컬렉션의 특성을 바탕으로 다음과 같은 단순화된 다이어그램이 그려집니다. 힙에서는 영역이 크게 '젊은 세대'와 '기존 세대'로 구분됩니다. "젊은 세대"에 위치한 객체의 메모리는 오랫동안 생성되지 않고 비교적 빠르게 업데이트되며 "메모리 쓰레기"를 생성하기 쉽습니다. 따라서 "젊은 세대"의 가비지 수집을 위한 "복사" 재활용 방법이 있습니다. "가 더 효율적입니다. "젊은 세대"는 두 가지 영역으로 나눌 수 있는데, 하나는 Eden Space와 Survivor Sprace입니다. Eden Space는 처음 생성된 객체를 주로 저장하는 반면, Survivor Sprace는 Eden Space에서 살아남은 "살아있는 객체"를 저장합니다. Survivor Sprace(생존자 영역)는 form과 to의 두 블록으로 나누어져 있으며, 가비지 청소를 위해 객체를 서로 복사하는 데 사용됩니다. "구세대"는 Survivor Sprace에서 살아남은 일부 "대형 개체"와 "개체"를 저장합니다. 일반적으로 "구세대"의 개체는 이 목적을 위해 더 안정적이고 쓰레기를 덜 생성합니다. , "마크 압축" 재활용 방법을 사용하는 것이 더 효율적입니다. "세대별 가비지 컬렉션"은 주로 분할 및 정복을 통해 다양한 객체를 특성에 따라 분류하고, 분류 특성에 따라 적절한 가비지 컬렉션 솔루션을 선택합니다. 3. 세대별 가비지 수집의 구체적인 작동 원리 물론 JVM의 구체적인 가비지 컬렉션에서는 스레드에 따라 재활용을 위해 단일 스레드를 사용하는 "직렬 가비지 컬렉션"과 재활용을 위해 여러 스레드를 사용하는 "병렬 가비지 컬렉션"으로 나눌 수 있습니다. . 프로그램 중단 상황에 따라 '전용 재활용'과 '동시 재활용'으로 구분됩니다. 물론, 이전에도 "병렬"과 "동시성"은 동일한 개념이 아니며 혼동해서는 안 된다는 점을 여러 차례 논의한 바 있습니다. 이 블로그에서는 위의 방법에 대해 자세히 설명하지 않습니다. 관심이 있으시면 Google에 문의하세요. 1. 가비지 수집 전 세대 가비지 수집"을 기다리는 모습을 간략하게 나타낸 것입니다. 아래 그림을 보면 할당된 객체 메모리 중 일부가 없는 것을 알 수 있습니다. 힙. 스택에서 참조되지 않으며 재활용할 개체입니다. 아래의 힙은 전체적으로 "젊은 세대"와 "올드 세대"로 나누어져 있고, 젊은 세대는 Eden Space, From and To 세 가지 영역으로 세분화할 수 있음을 알 수 있습니다. 각 영역의 역할에 대해서는 위에서 '세대별 가비지 컬렉션'을 소개할 때 이미 소개한 바 있으므로, 이번 편에서는 자세히 소개하지 않겠습니다. 2. 세대별 가비지 수집 Eden Space 및 From에 있는 "라이브 개체"를 To 영역으로 복사합니다. 복사하는 동안 복사된 메모리의 스택 참조 주소도 수정해야 합니다. From 또는 Eden 영역의 "대형 개체" 저장 공간은 "old Generation"에 직접 복사됩니다. From 및 To 영역에 있는 "대형 개체"의 여러 복사본의 효율성이 상대적으로 낮기 때문에 이를 "old Generation"에 직접 추가하여 재활용 효율성을 향상시킵니다. 3. 가비지 수집 후 결과 IV.Eclipse GC 로그 구성 및 분석 Eclipse에서 로그인하는 가비지 컬렉션 구성을 살펴보고 이러한 로그 기록을 분석합니다. 물론, 이 블로그에서는 Java8을 사용하고 있습니다. 다른 버전의 Java를 사용하면 출력되는 로그 정보가 약간씩 달라지므로 이 부분부터 살펴보겠습니다. 1. Eclipse 실행 설정을 구성합니다 Run Configurations… 옵션을 찾아 런타임 구성을 수행합니다. 아래는 위 옵션으로 열리는 대화 상자입니다. 그런 다음 (x)=Arguments 탭 표시줄을 찾아 VM 인수에 해당 가상 머신 매개변수를 추가하세요. 이 매개변수는 런타임 시 프로젝트의 매개변수로 사용됩니다. . 아래에는 -XX:+PrintGCTimeStamps 및 -XX:+PrintGCDetails라는 두 가지 매개변수가 추가되었습니다. 이 두 개의 매개변수 이름에서 해당 매개변수에 해당하는 함수를 보는 것은 어렵지 않습니다. 하나는 가비지 수집의 타임스탬프를 인쇄하는 것이고, 다른 하나는 가비지 수집의 세부 사항을 인쇄하는 것입니다. 물론 "가비지 수집"을 선택할 때 특정 알고리즘의 매개변수, "직렬" 또는 "병렬"을 선택할지 여부에 대한 매개변수, "배타적" 또는 "동시" 쓰레기의 일부 선택과 같은 다른 매개변수도 많이 있습니다. . 재활용된 매개변수. 여기서는 너무 자세히 설명하지 않겠습니다. Google에서 직접 검색해 보세요. 2. 재활용 로그 인쇄 및 분석 위 매개변수를 구성한 후 System.gc()를 사용하여 강제 가비지 수집을 수행하면 해당 매개변수가 인쇄됩니다. 정보. 먼저 테스트용 코드를 생성해야 합니다. 아래는 우리가 생성한 테스트 클래스입니다. 물론 테스트 클래스의 코드는 비교적 간단합니다. 가장 중요한 것은 문자열을 새로 만든 다음 참조를 null로 설정하고 마지막으로 재활용을 위해 System.gc()을 호출하는 것입니다. 구체적인 코드는 다음과 같습니다. 위 코드의 효과는 다음과 같습니다. 다음으로 로그 정보의 주요 내용을 소개하겠습니다. [PSYoungGen: 1997K->416K(38400K)] 1997K->424K(125952K), 0.0010277초] PSYoungGen은 "젊은 세대"가 재활용된다고 말했습니다. parallel 에서 1997K->416K는 Young Generation 해당 영역의 "재활용 전->재활용 후" 크기를 나타내고, (38400K)는 "Young Generation" 힙의 전체 크기를 나타냅니다. 뒤쪽의 1997K->424K(125952K) 데이터는 전체 힙 관점에서 볼 때 문제입니다. 1997K(힙 재활용 전 사용된 메모리) -> 424K(힙 재활용 후 사용된 메모리) (125952K - 힙의 전체 메모리 공간) [ParOldGen: 8K->328K(87552K)] ParOldGen은 "old Generation"을 병렬로 재활용하는 매개변수와 유사합니다. 위의 젊은 세대는 말할 것도 없습니다. [Metaspace: 2669K->2669K(1056768K)] 은 정적 데이터나 시스템을 저장하는 데 사용되는 "메타데이터 영역", 메타스페이스 및 "영구 생성" 영역의 재활용 상태를 나타냅니다. 메소드 영역. 위는 간단한 가비지 수집 로그입니다. 먼저 이 블로그의 내용은 JVM의 가비지 수집에 대한 더 많은 내용이 있습니다. 앞으로 차례로 소개됩니다. 오늘의 블로그는 여기까지입니다. 











package com.zeluli.gclog;public class GCLogTest {public static void main(String[] args) {
String s = new String("Value");
s = null;
System.gc();
}
}

위 내용은 JVM 메모리 영역 분할 및 가비지 수집 메커니즘에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7467
7467
 15
1376
52
77
11
46
19
18
20
15
1376
52
77
11
46
19
18
20

 프린터 메모리가 부족하여 페이지를 인쇄할 수 없습니다. Excel 또는 PowerPoint 오류
Feb 19, 2024 pm 05:45 PM
프린터 메모리가 부족하여 페이지를 인쇄할 수 없습니다. Excel 또는 PowerPoint 오류
Feb 19, 2024 pm 05:45 PM
Excel 워크시트나 PowerPoint 프레젠테이션을 인쇄할 때 프린터 메모리 부족 문제가 발생하는 경우 이 문서가 도움이 될 수 있습니다. 프린터에 페이지를 인쇄할 메모리가 부족하다는 유사한 오류 메시지가 나타날 수 있습니다. 그러나 이 문제를 해결하기 위해 따를 수 있는 몇 가지 제안 사항이 있습니다. 인쇄할 때 프린터 메모리를 사용할 수 없는 이유는 무엇입니까? 프린터 메모리가 부족하면 메모리를 사용할 수 없다는 오류가 발생할 수 있습니다. 프린터 드라이버 설정이 너무 낮아서 발생하는 경우도 있지만 다른 이유일 수도 있습니다. 큰 파일 크기 프린터 드라이버 오래되었거나 손상됨 설치된 추가 기능이 중단됨 프린터 설정이 잘못 구성됨 이 문제는 Microsoft Windows 프린터 드라이버의 메모리 부족 설정으로 인해 발생할 수도 있습니다. 인쇄 수리
 대용량 메모리 최적화, 컴퓨터가 16g/32g 메모리 속도로 업그레이드했는데 변화가 없다면 어떻게 해야 하나요?
Jun 18, 2024 pm 06:51 PM
대용량 메모리 최적화, 컴퓨터가 16g/32g 메모리 속도로 업그레이드했는데 변화가 없다면 어떻게 해야 하나요?
Jun 18, 2024 pm 06:51 PM
기계식 하드 드라이브나 SATA 솔리드 스테이트 드라이브의 경우 소프트웨어 실행 속도의 증가를 느낄 수 있지만 NVME 하드 드라이브라면 느끼지 못할 수도 있습니다. 1. 레지스트리를 데스크탑으로 가져와 새 텍스트 문서를 생성하고, 다음 내용을 복사하여 붙여넣은 후 1.reg로 저장한 후 마우스 오른쪽 버튼을 클릭하여 병합하고 컴퓨터를 다시 시작합니다. WindowsRegistryEditorVersion5.00[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\SessionManager\MemoryManagement]"DisablePagingExecutive"=d
 Xiaomi Mi 14Pro의 메모리 사용량을 확인하는 방법은 무엇입니까?
Mar 18, 2024 pm 02:19 PM
Xiaomi Mi 14Pro의 메모리 사용량을 확인하는 방법은 무엇입니까?
Mar 18, 2024 pm 02:19 PM
최근 샤오미는 스타일리시한 디자인은 물론 내부 및 외부 블랙 기술까지 갖춘 강력한 고급 스마트폰 샤오미 14Pro를 출시했다. 이 전화기는 최고의 성능과 뛰어난 멀티태스킹 기능을 갖추고 있어 사용자가 빠르고 원활한 휴대폰 경험을 즐길 수 있습니다. 하지만 성능은 메모리에 의해서도 영향을 받습니다. 많은 사용자들이 Xiaomi 14Pro의 메모리 사용량을 확인하는 방법을 알고 싶어하므로 한번 살펴보겠습니다. Xiaomi Mi 14Pro의 메모리 사용량을 확인하는 방법은 무엇입니까? Xiaomi 14Pro의 메모리 사용량을 확인하는 방법을 소개합니다. Xiaomi 14Pro 휴대폰의 [설정]에서 [애플리케이션 관리] 버튼을 엽니다. 설치된 모든 앱 목록을 보려면 목록을 탐색하고 보려는 앱을 찾은 다음 클릭하여 앱 세부 정보 페이지로 들어갑니다. 신청 세부정보 페이지에서
![Windows 입력 시 중단 또는 높은 메모리 사용량이 발생함 [수정]](https://img.php.cn/upload/article/000/887/227/170835409686241.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) Windows 입력 시 중단 또는 높은 메모리 사용량이 발생함 [수정]
Feb 19, 2024 pm 10:48 PM
Windows 입력 시 중단 또는 높은 메모리 사용량이 발생함 [수정]
Feb 19, 2024 pm 10:48 PM
Windows 입력 환경은 다양한 휴먼 인터페이스 장치의 사용자 입력 처리를 담당하는 핵심 시스템 서비스입니다. 시스템이 시작되고 백그라운드에서 실행될 때 자동으로 시작됩니다. 그러나 때때로 이 서비스가 자동으로 중단되거나 너무 많은 메모리를 차지하여 시스템 성능이 저하될 수 있습니다. 따라서 시스템 효율성과 안정성을 보장하려면 이 프로세스를 적시에 모니터링하고 관리하는 것이 중요합니다. 이 문서에서는 Windows 입력 환경이 중단되거나 메모리 사용량이 높아지는 문제를 해결하는 방법을 공유합니다. Windows 입력 경험 서비스에는 사용자 인터페이스가 없지만 입력 장치와 관련된 기본적인 시스템 작업 및 기능을 처리하는 것과 밀접한 관련이 있습니다. 그 역할은 Windows 시스템이 사용자가 입력한 모든 입력을 이해하도록 돕는 것입니다.
 컴퓨터에서 8g 메모리와 16g 메모리 사이에 큰 차이가 있나요? (컴퓨터 메모리 8g 또는 16g 선택)
Mar 13, 2024 pm 06:10 PM
컴퓨터에서 8g 메모리와 16g 메모리 사이에 큰 차이가 있나요? (컴퓨터 메모리 8g 또는 16g 선택)
Mar 13, 2024 pm 06:10 PM
초보 사용자가 컴퓨터를 구입할 때 8g과 16g 컴퓨터 메모리의 차이점이 궁금할 것입니다. 8g 또는 16g을 선택해야 합니까? 이 문제에 대해 오늘 편집자가 자세히 설명해 드리겠습니다. 컴퓨터 메모리 8g과 16g 사이에 큰 차이가 있나요? 1. 일반 가족이나 일반 업무의 경우 8G 런닝 메모리가 요구 사항을 충족할 수 있으므로 사용 중에는 8g와 16g 사이에 큰 차이가 없습니다. 2. 게임 매니아가 사용하는 경우 현재 대규모 게임은 기본적으로 6g부터 시작하며, 8g가 최소 기준입니다. 현재 화면이 2k인 경우 해상도가 높아진다고 프레임 속도 성능이 높아지는 것은 아니므로 8g와 16g 사이에는 큰 차이가 없습니다. 3. 오디오 및 비디오 편집 사용자의 경우 8g와 16g 사이에는 분명한 차이가 있습니다.
 소식통에 따르면 삼성전자와 SK하이닉스는 2026년 이후 적층형 모바일 메모리를 상용화할 것으로 보인다.
Sep 03, 2024 pm 02:15 PM
소식통에 따르면 삼성전자와 SK하이닉스는 2026년 이후 적층형 모바일 메모리를 상용화할 것으로 보인다.
Sep 03, 2024 pm 02:15 PM
3일 홈페이지 보도에 따르면 국내 언론 에트뉴스는 어제(현지시간) 삼성전자와 SK하이닉스의 'HBM형' 적층구조 모바일 메모리 제품이 2026년 이후 상용화될 것이라고 보도했다. 소식통에 따르면 두 한국 메모리 거대 기업은 적층형 모바일 메모리를 미래 수익의 중요한 원천으로 여기고 'HBM형 메모리'를 스마트폰, 태블릿, 노트북으로 확장해 엔드사이드 AI에 전력을 공급할 계획이라고 전했다. 이 사이트의 이전 보도에 따르면 삼성전자 제품은 LPWide I/O 메모리라고 하며 SK하이닉스는 이 기술을 VFO라고 부른다. 두 회사는 팬아웃 패키징과 수직 채널을 결합하는 것과 거의 동일한 기술 경로를 사용했습니다. 삼성전자 LPWide I/O 메모리의 비트폭은 512이다.
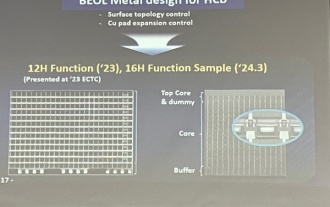 삼성전자가 HBM4 메모리에 널리 사용될 것으로 예상되는 16단 하이브리드 본딩 적층 공정 기술 검증을 완료했다고 밝혔다.
Apr 07, 2024 pm 09:19 PM
삼성전자가 HBM4 메모리에 널리 사용될 것으로 예상되는 16단 하이브리드 본딩 적층 공정 기술 검증을 완료했다고 밝혔다.
Apr 07, 2024 pm 09:19 PM
보고서에 따르면 삼성전자 김대우 상무는 2024년 한국마이크로전자패키징학회 연차총회에서 삼성전자가 16단 하이브리드 본딩 HBM 메모리 기술 검증을 완료할 것이라고 밝혔다. 해당 기술은 기술검증을 통과한 것으로 알려졌다. 보고서는 이번 기술 검증이 향후 몇 년간 메모리 시장 발전의 초석을 마련하게 될 것이라고 밝혔다. 김대우 사장은 삼성전자가 하이브리드 본딩 기술을 바탕으로 16단 적층 HBM3 메모리를 성공적으로 제조했다고 밝혔다. ▲이미지 출처 디일렉, 아래와 동일 하이브리드 본딩은 DRAM 메모리층 사이에 범프를 추가할 필요 없이 상하층 구리를 직접 연결하는 방식이다.
 마이크론 : HBM 메모리는 웨이퍼 용량의 3배 소비, 생산능력은 기본적으로 내년으로 예약
Mar 22, 2024 pm 08:16 PM
마이크론 : HBM 메모리는 웨이퍼 용량의 3배 소비, 생산능력은 기본적으로 내년으로 예약
Mar 22, 2024 pm 08:16 PM
21일 본 사이트의 소식에 따르면 마이크론은 분기별 재무보고서를 발표한 뒤 컨퍼런스콜을 가졌다. 컨퍼런스에서 Micron CEO Sanjay Mehrotra는 기존 메모리에 비해 HBM이 훨씬 더 많은 웨이퍼를 소비한다고 말했습니다. 마이크론은 동일한 노드에서 동일한 용량을 생산할 때 현재 가장 발전된 HBM3E 메모리는 표준 DDR5보다 3배 더 많은 웨이퍼를 소비하며 성능이 향상되고 패키징 복잡성이 심화됨에 따라 향후 HBM4 이 비율은 더욱 높아질 것으로 예상된다고 밝혔습니다. . 이 사이트의 이전 보고서를 참조하면 이러한 높은 비율은 부분적으로 HBM의 낮은 수율 때문입니다. HBM 메모리는 다층 DRAM 메모리 TSV 연결로 적층됩니다. 한 층에 문제가 있다는 것은 전체가 의미합니다.
