

최근에 우연히 MySQL 페이징 최적화에 대한 테스트 케이스를 봤습니다. 테스트 시나리오를 아주 구체적으로 설명하지 않고 고전적인 솔루션이 제시되었습니다.
현실의 많은 상황이 수정되지 않기 때문에 일반적인 관행이나 규칙을 요약할 수는 없습니다.
동시에 최적화를 달성할 수 있는 방법에 직면했을 때 동일한 접근 방식으로 시나리오를 변경하면 최적화 효과를 얻을 수 없습니다. 여전히 이유를 조사해야 합니다.
저는 개인적으로 이 시나리오의 활용에 대해 의구심을 표명하고 직접 테스트해 본 결과 몇 가지 문제점을 발견했고 예상되는 아이디어도 몇 가지 확인했습니다.
이 기사에서는 가장 간단한 상황부터 시작하여 MySQL 페이징 최적화에 대한 간단한 분석을 수행합니다.
또 다른: 이 글의 테스트 환경은 가장 낮은 구성의 클라우드 서버입니다. 상대적으로 말하면 서버 하드웨어 환경은 제한되어 있지만 서로 다른 진술(작성 방법)은 "동일"해야 합니다
MySQL의 고전적인 페이징 "최적화" 방법
MySQL 페이징 최적화에는 더 많은 "뒤" 데이터를 쿼리할수록 속도가 느려지는 전형적인 문제가 있습니다. 테이블의 인덱스 유형에 따라 B-트리 구조 인덱스의 경우에도 마찬가지입니다. SQL Server)
id 제한 m,n에 따라 t order에서 *를 선택합니다.
즉, M이 증가할수록 동일한 양의 데이터를 쿼리하는 속도가 점점 느려집니다.
이 문제에 직면하여 다음 쓰기와 유사한(또는 변형) 고전적인 접근 방식이 탄생했습니다
먼저 페이징 범위 내에서 별도로 id를 지정한 다음 이를 기본 테이블과 연결하고 마지막으로 필요한 데이터를 쿼리합니다. t.id
이 접근 방식은 항상 효과적인가요, 아니면 어떤 상황에서 후자가 최적화 목적을 달성할 수 있나요? 다시 작성한 후에 효과가 없거나 느려지는 상황이 있나요?
동시에 대부분의 쿼리에는 필터링 조건이 있습니다.
필터링 조건이 있는 경우sql 문은 select * from t where *** order by idlimit m, n
같은 방법을 따르면 됩니다. ,select * from t
inner Join (select id from t where *** order by idlimit m,n )t1 on t1.id = t.id
이 경우 최종 SQL을 다시 작성할 수 있습니다. 문이 여전히 최적화 목적을 달성합니까?
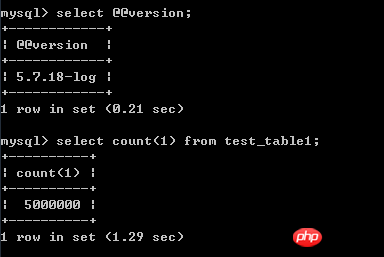
테스트 데이터는 저장 프로시저 루프와 테스트 테이블의 InnoDB 엔진 테이블을 통해 비교적 간단하게 작성됩니다.

먼저 이 고전적인 문제를 살펴보겠습니다. 페이징할 때 쿼리가 더 "뒤로" 이동합니다. 테스트 1: 1~20행의 데이터 쿼리 0.01초
동일한 쿼리는 20행의 데이터에 대한 쿼리이고, 다음과 같이 상대적으로 "나중에" 있는 데이터에 대한 쿼리입니다. 여기서 4900001-4900020개의 데이터 행에는 1.97초가 걸립니다.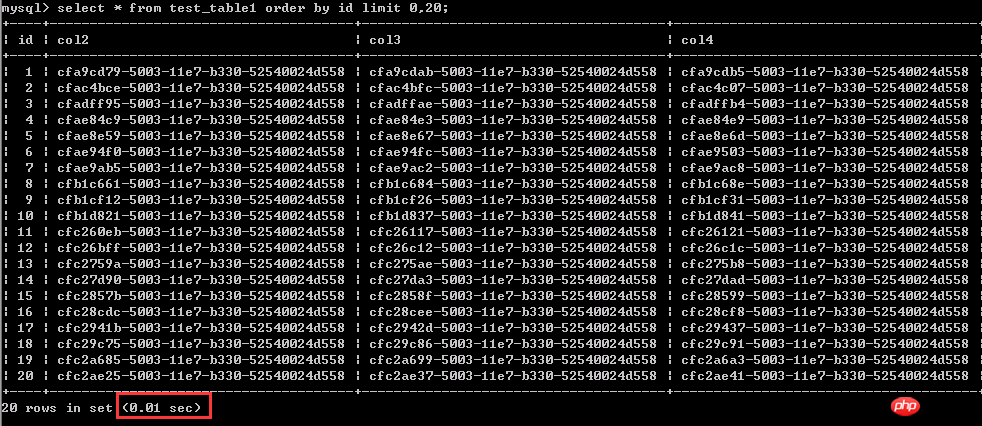
후자의 효율성이 떨어지는 이유에 대해서는 나중에 분석해 보겠습니다.

t order by id 제한 m,n에서 *를 선택하세요. select * from tinner Join (id 제한 m,n에 따라 t order에서 id 선택)t1 on t1.id = t.id
 첫 번째 작성 방법:
첫 번째 작성 방법:
select * from test_table1 order by id asclimit 4900000,20; 테스트 결과는 스크린샷에 표시됩니다. 실행 시간은 8.31초입니다
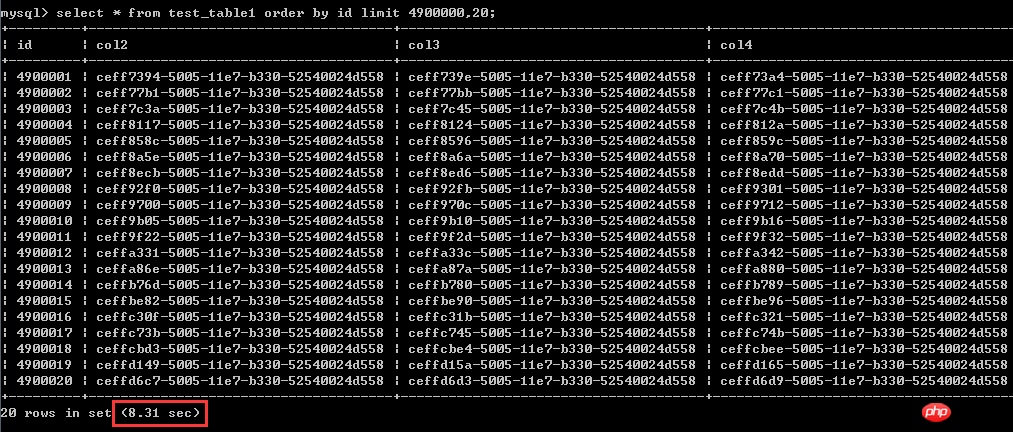
두 번째로 다시 작성된 작성 방법:
select t1.* from test_table1 t1
inner Join (test_table1에서 ID 선택 ID 제한 4900000,20으로 주문)t2 on t1.id = t2.id;실행 시간은 8.43초입니다
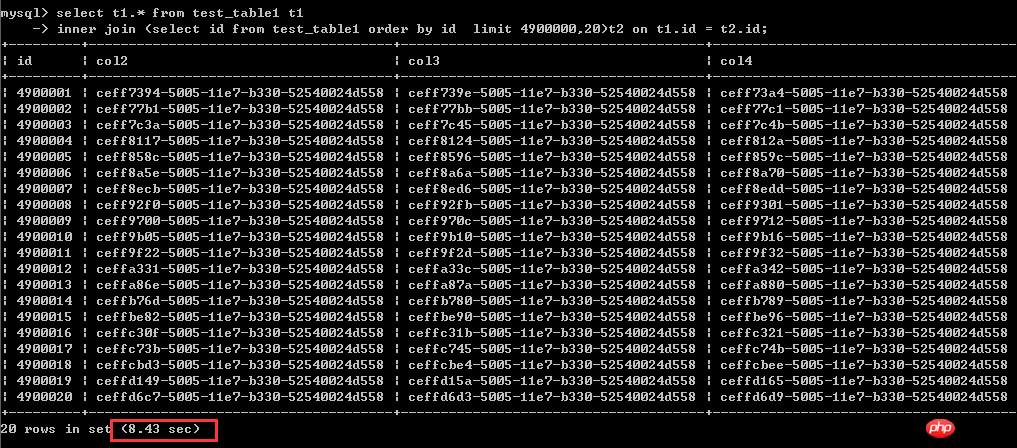
여기서는 다음을 통해 다시 작성한 후 매우 분명합니다.
실제 테스트에서는 둘 사이에 뚜렷한 선형적 차이가 없는 것으로 나타났습니다. 둘의 원본 포스터는 여러 테스트를 거쳤습니다. .
개인적으로 비슷한 결론을 보면 테스트를 해봐야 하는데 이건 믿을 수 없는 일이고, 아니면 왜 효율성이 향상될 수 없는 걸까요?
그렇다면 왜 다시 쓴 글쓰기 방식이 전설처럼 성능을 향상시키지 못한 걸까요?
현재 재작성이 성능 향상 목적을 달성하지 못하는 원인은 무엇입니까?
후자가 성능을 향상시킬 수 있는 원리는 무엇인가요?
먼저 테스트 테이블의 테이블 구조를 살펴보세요. 정렬 열에 인덱스가 있습니다. 핵심은 정렬 열의 인덱스가 기본 키(클러스터형 인덱스)라는 것입니다.
정렬 열이 클러스터형 인덱스인 경우 상대적으로 "최적화된" 다시 작성된 SQL이 "최적화" 목적을 달성할 수 없는 이유는 무엇입니까?
정렬 열이 클러스터형 인덱스 열인 경우 둘 다 순차 스캔입니다. 정규화된 데이터를 쿼리하는 테이블
후자는 먼저 하위 쿼리를 구동한 다음 하위 쿼리의 결과를 사용하여 메인 테이블을 구동하지만
그러나 하위 쿼리는 "한정된 데이터를 쿼리하기 위해 테이블의 순차적 스캔"을 변경하지 않습니다. " 접근 방식, 현재 상황에서는 재작성된 접근 방식조차 불필요한 것 같습니다
다음 두 가지 실행 계획, 첫 번째 스크린샷의 실행 계획 한 줄과 재작성된 SQL 실행 계획의 세 번째 줄(id = 2줄)을 참조하세요. ) 기본적으로 동일합니다.


필터 조건이 없고 정렬이 클러스터형 인덱스인 경우 소위 페이징 쿼리 최적화는 불필요합니다
현재 위 데이터를 쿼리하는 방법에는 두 가지가 있습니다. .매우 느립니다. 그렇다면 위의 데이터를 쿼리하려면 어떻게 해야 합니까?
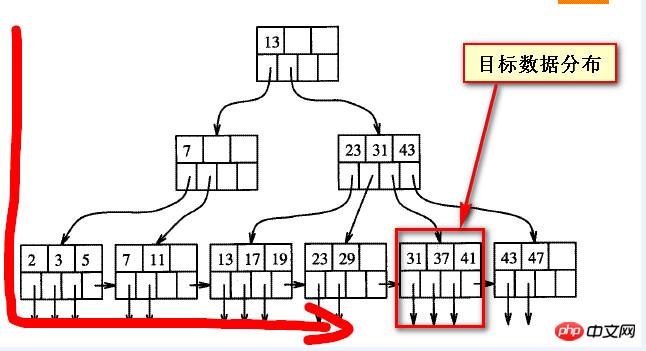
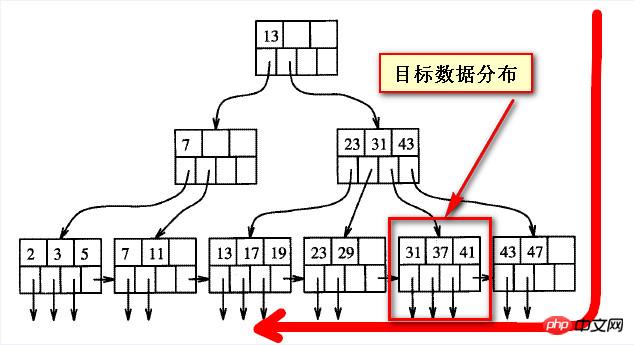
아직 왜 느린지 살펴봐야 합니다. 먼저 B 트리의 균형 잡힌 구조를 이해해야 합니다. 아래 그림과 같이 저의 대략적인 이해를 바탕으로
쿼리된 데이터가 "나중에"일 경우 실제로는 에서 벗어나게 됩니다. B 트리 인덱스. 한 방향, 아래 두 스크린샷에 표시된 대상 데이터
실제로 밸런스 트리의 데이터에는 소위 "앞"과 "뒤"가 없습니다. , 또는 스캔하는 방향에서 보면
한 방향에서 보면 "뒤" 데이터이고, 한 방향에서 보면 "앞" 데이터이고, 앞과 뒤는 절대적인 것은 아닙니다.
다음 두 스크린샷은 B-트리 인덱스 구조를 대략적으로 표현한 것입니다. 대상 데이터의 위치가 고정된 경우 소위 "뒤로"는 왼쪽에서 오른쪽으로 상대적입니다. 오른쪽에서 왼쪽으로 보면, 소위 나중 데이터는 실제로 "앞으로"입니다.
데이터가 맨 앞에 있는 한, 이 부분의 데이터를 효율적으로 찾는 것은 여전히 가능합니다. Mysql에는 sqlserver의 정방향 및 역방향 검색과 유사한 방법도 있어야 합니다.
 이후 데이터에 대해 역스캐닝을 사용하면 데이터의 이 부분을 빠르게 찾을 수 있고, 찾은 데이터를 다시 정렬(asc)해야 합니다.
이후 데이터에 대해 역스캐닝을 사용하면 데이터의 이 부분을 빠르게 찾을 수 있고, 찾은 데이터를 다시 정렬(asc)해야 합니다.
0.07초 밖에 걸리지 않습니다
. 앞선 두 가지 작성 방법 모두 8초 이상 걸렸으며 효율성에서는 수백 배의 차이가 있습니다. 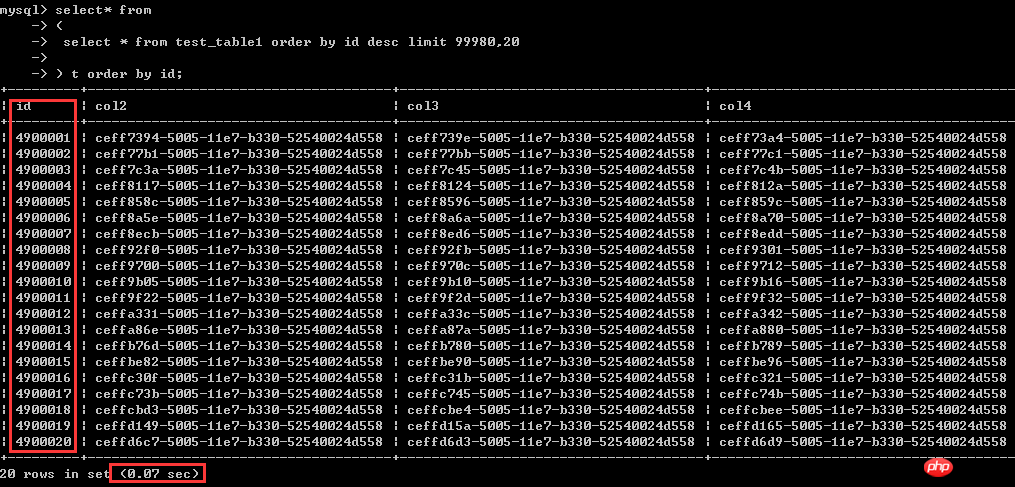
왜 그런지는 위의 설명을 토대로 이해하면 될 것 같습니다.
더 큰 ID를 가진 데이터나 시간 차원의 최신 데이터와 같은 소위 나중 데이터를 자주 쿼리하는 경우 역방향 스캔 인덱스 방법을 사용하여 효율적인 페이징 쿼리를 얻을 수 있습니다
(여기에서 데이터를 계산하십시오. 페이지 동일한 데이터라도 시작 "페이지 번호"가 정방향과 역순으로 다름)
select* from(select * from test_table1 order by id desc limit 99980,20) t order by id;
필터 조건이 없고 정렬 열이 비클러스터형 인덱스인 경우
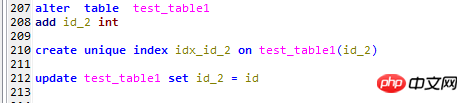
여기에서 test_table1 테스트 테이블에 다음과 같은 변경 사항이 적용되었습니다
1. id_2 열을 추가합니다.
2. 이 필드에 고유 인덱스를 생성합니다.
3. 이 필드를 해당 기본 키로 채웁니다. Id
테스트는 기본키 인덱스(클러스터드 인덱스)를 기준으로 정렬한 다음, 새로 추가된 id_2 컬럼인 비클러스터형 인덱스를 기준으로 정렬하고, 두 가지 페이징 방식을 테스트해 보겠습니다. 처음에 언급했습니다.
먼저 첫 번째 작성 방법을 살펴보겠습니다
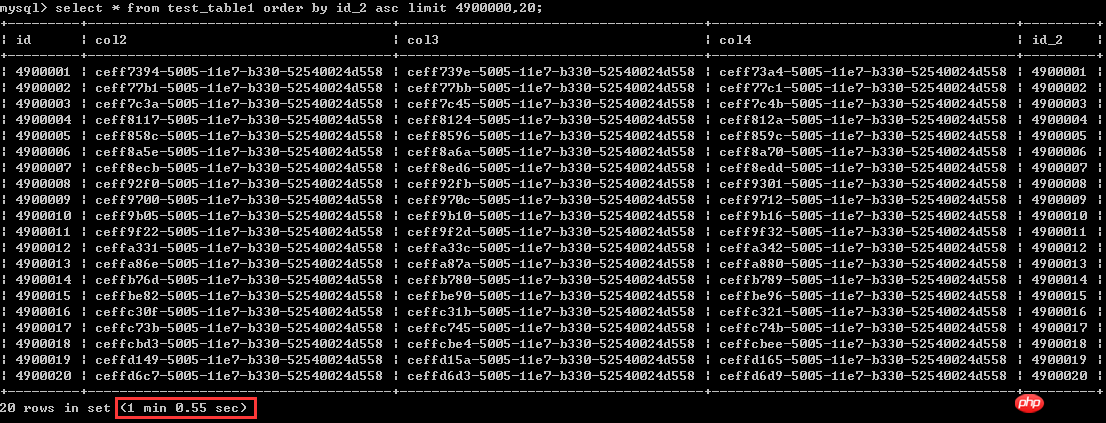
select * from test_table1 order by id_2 asclimit 4900000,20;실행 시간은 1분 남짓,60초로 생각하자
두 번째 쓰기 방법
select t1.* from test_table1 t1
inner Join (select id from test_table1 order by id_2 제한 4900000,20)t2 on t1.id = t2.id;실행 시간 1.67초
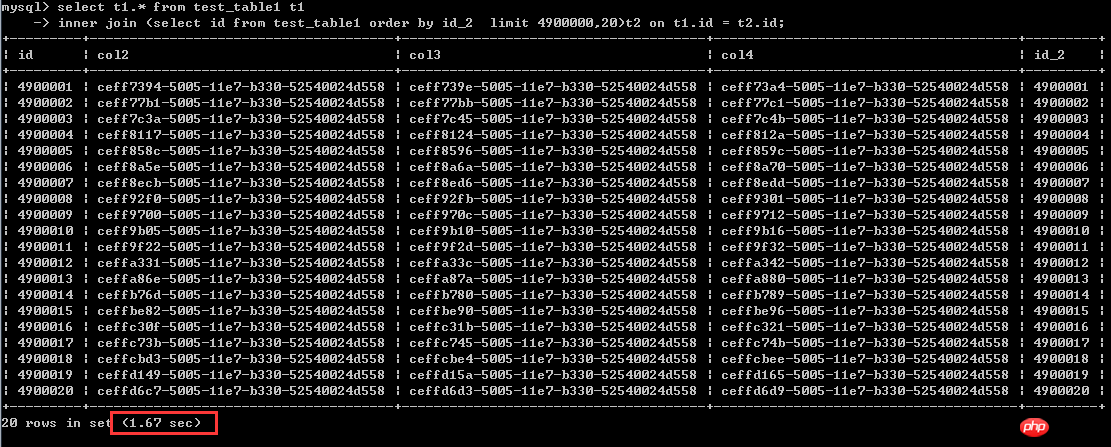
이러한 상황에서 보면, 즉 정렬 열이 비클러스터형 인덱스 열인 경우 후자의 작성 방법이 효율성을 크게 향상시킬 수 있다는 것을 알 수 있습니다. 거의 40배나 향상된 셈이다.
그럼 이유가 뭔가요?
먼저 첫 번째 작성 방법의 실행 계획을 살펴보면, 이 SQL을 실행하는 동안 테이블 전체를 스캔한 후 id_2에 따라 정렬하고 최종적으로 상위 20개의 데이터를 가져오는 것으로 간단히 이해할 수 있습니다. .
우선, 전체 테이블 스캐닝은 시간이 많이 걸리는 과정이고, 정렬도 비용이 많이 들기 때문에 성능이 매우 낮습니다.

후자의 실행 계획을 보면 먼저 id_2의 인덱스 순서에 따라 하위 쿼리를 스캔한 다음 정규화된 기본 키 ID를 사용하여 테이블의 데이터를 쿼리합니다
이렇게 하면 대규모 그런 다음 데이터를 재정렬합니다(filesort 사용)
sqlserver 실행 계획을 이해했다면 전자에 비해 후자는 빈번한 테이블 반환(sqlserver에서 키 조회 또는 북마크 조회라는 프로세스
)을 피해야 합니다. 20개의 정규화된 데이터를 쿼리하기 위해 외부 테이블을 하위 쿼리로 구동하는 프로세스는 실제로 정렬 열이 비클러스터형 인덱스 열인 현재 상황에서만 발생합니다. , 다시 작성된 SQL은 페이징 쿼리의 효율성을 향상시킬 수 있습니다.
위에서 볼 수 있듯이 동일한 데이터가 반환됩니다. 다음 쿼리는 0.07초로 여기의 1.67초보다 2배 더 높습니다
select* from(select * from test_table1 order by id desc limit 99980,20) t order by id;
제가 언급하고 싶은 또 다른 질문은 페이징 쿼리가 자주 수행되고 특정 순서로 수행된다면 이 열에 클러스터형 인덱스를 만드는 것이 어떨까요?
예를 들어 문이 자동으로 ID를 증가시키거나 시간 + 기타 필드가 고유성을 보장하는 경우 mysql은 자동으로 기본 키에 클러스터형 인덱스를 생성합니다.
그러면 클러스터형 인덱스의 경우 "앞"과 "뒤"는 상대적인 논리적 개념일 뿐입니다. 대부분의 경우 "뒤" 또는 최신 데이터를 얻으려면 위의 작성 방법인
최적화를 사용할 수 있습니다. 필터 조건이 있는 경우 페이징 쿼리
이 부분에 대해 잠시 생각해 보았습니다. 상황이 너무 복잡하고 매우 대표적인 사례를 요약하기가 어렵기 때문에 많은 테스트를 수행하지 않겠습니다.
select * from t where *** order by idlimit m,n
1. 예를 들어 브러시 선택 조건 자체는 일단 필터링되면 데이터의 작은 부분만 남으므로 생성되지 않습니다. 필터링 조건 자체가 매우 효율적인 필터링을 달성할 수 있기 때문에 SQL을 다시 작성해야 하는지에 대한 의미가 큽니다
2. 예를 들어 브러시 선택 조건 자체는 거의 영향을 미치지 않습니다(필터링 후에도 데이터의 양이 여전히 엄청납니다). 필터링 조건이 없는 상황이며 정렬 방법, 정방향 또는 역순 등에 따라 다릅니다.
3. 예를 들어 필터링 조건 자체는 거의 영향을 미치지 않습니다(필터링 후에도 데이터의 양이 여전히 엄청납니다). 고려해야 할 문제는 데이터 분포입니다.
데이터의 분포는 SQL 효율성의 실행에도 영향을 미칩니다. (sqlserver, mysql에서의 경험은 크게 다르지 않을 것입니다.)
4. 쿼리 자체가 상대적으로 복잡한 경우에는 그렇다고 말하기는 어렵습니다. 어떤 방법은 효율적인 목적을 달성할 수 있다
상황이 복잡할수록 총체적으로 요약하기는 어렵다. 성의 법칙이나 방법에 관해서는 모든 것을 구체적인 상황에 따라 보아야 하고 최종적인 결론을 내리기는 어렵다.
여기서는 쿼리에 필터링 조건을 하나씩 추가하는 상황을 분석하지는 않겠지만, 확실한 것은 실제 시나리오 없이는 절대 확실한 해결책이 없다는 점입니다.
또한, 현재 페이지의 데이터를 쿼리할 때 이전 페이지의 쿼리의 최대값을 필터 조건으로 활용하면 현재 페이지의 데이터를 빠르게 찾을 수 있음은 물론입니다. 문제 없습니다. 그러나 이는 또 다른 접근 방식이므로 이 문서에서는 다루지 않습니다.
요약
페이징 쿼리, 뒤로 갈수록 속도가 느려집니다. 사실 B-tree 인덱스의 경우 앞과 뒤는 논리적으로 상대적인 개념이고, 성능의 차이는 B-tree를 기준으로 합니다.
필터 조건을 추가하면 상황이 더 복잡해집니다. 이 문제의 원리는 SQL Server에서도 동일하므로 반복하지 않겠습니다. 여기요.
현재 상황에서는 정렬 열, 쿼리 조건 및 데이터 분포가 반드시 확실하지 않으므로 "최적화"를 달성하기 위해 특정 방법을 사용하기가 어렵습니다. 그렇지 않으면 불필요한 부작용이 발생합니다.
따라서 페이징 최적화를 수행할 때는 반드시 특정 시나리오를 기반으로 분석을 수행해야 합니다. 실제 시나리오와 동떨어진 결론은 반드시 한 가지만 있는 것은 아닙니다.
이 문제의 내용을 자세히 이해해야만 문제를 쉽게 처리할 수 있습니다.
따라서 데이터 "최적화"에 대한 나의 개인적인 결론은 특정 문제에 대한 구체적인 분석을 기반으로 해야 하며 다른 사람들이 "적용"할 수 있도록 일련의 규칙(규칙 1, 2, 3, 4, 5)을 요약하는 것은 매우 금기시됩니다. 나도 매우 훌륭하기 때문에 일부 교리를 감히 요약하는 것은 더욱 어렵습니다.
위 내용은 MySQL 페이징 최적화 테스트 사례의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



