

node.js require() 소스 코드 해석_node.js

2009년 Node.js 프로젝트가 탄생했으며, 모든 모듈은 CommonJS 형식입니다.
현재 Node.js 모듈 웨어하우스 npmjs.com에는 150,000개의 모듈이 저장되어 있으며, 그 중 대부분은 CommonJS 형식입니다.
이 형식의 핵심은 모듈을 로드하는 require 문입니다. Node.js를 배울 때 require 문을 사용하는 방법을 배워야 합니다. 이 글에서는 Node.js의 모듈 메커니즘을 이해하는 데 도움이 되도록 소스 코드 분석을 통해 require 문의 내부 작동 메커니즘을 자세히 소개합니다.
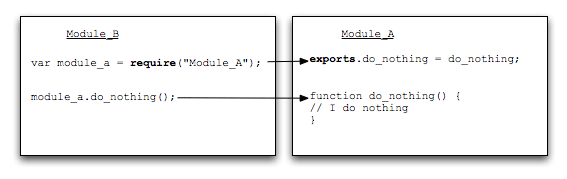
1. require()의 기본 사용법
소스코드를 분석하기 전에 먼저 require 문의 내부 로직을 소개하겠습니다. require 사용법만 알고 싶다면 이 문단을 읽어보세요.
다음 내용은 "노드 사용자 매뉴얼" 을 번역한 것입니다.
Node가 require(X)를 만나면 다음과 같은 순서로 처리됩니다.
(1) X가 내장 모듈인 경우(예: require('http'))
a. 모듈로 돌아갑니다.
b. 더 이상 실행되지 않습니다.
(2) X가 "./", "/" 또는 "../"로 시작하는 경우
a. X가 위치한 상위 모듈을 기반으로 X의 절대 경로를 결정합니다.
b.대접하다
엑스
X.js
X.json
X.노드
다.
X/package.json(메인 필드)
X/index.js
X/index.json
X/index.node
(3) X에 경로가 없는 경우
a. X가 위치한 상위 모듈을 기반으로 X의 가능한 설치 디렉터리를 결정합니다.
b. 각 디렉터리에서 X를 파일 이름이나 디렉터리 이름으로 차례로 로드합니다.
(4) "찾을 수 없음" 던지기
예시를 참고해주세요.
현재 스크립트 파일 /home/ry/projects/foo.js는 위의 세 번째 상황에 속하는 require('bar') 를 실행합니다. Node의 내부 동작 과정은 다음과 같습니다.
먼저 x의 절대 경로가 다음 위치일 수 있는지 확인하고 각 디렉터리를 차례로 검색합니다.
/home/ry/projects/node_modules/bar
/home/ry/node_modules/bar
/home/node_modules/bar
/node_modules/bar
검색 시 Node는 먼저 bar를 파일 이름으로 처리하고 다음 파일을 순서대로 로드하려고 시도한 후 성공하면 반환합니다.
bar bar.js bar.json bar.node
둘 다 성공하지 못하면 bar가 디렉터리 이름일 수 있으므로 다음 파일을 순서대로 로드해 보세요.
bar/package.json (메인 필드)
바/index.js
바/index.json
바/index.node
bar에 해당하는 파일이나 디렉터리를 어떤 디렉터리에서도 찾을 수 없으면 오류가 발생합니다.
2. 모듈 생성자
내부 로직을 이해한 후 소스코드를 살펴보겠습니다.
require의 소스 코드는 Node의 lib/module.js 파일에 있습니다. 이해의 편의를 위해 본 글에 인용된 소스코드는 단순화되었으며, 원저작자의 코멘트는 삭제되었습니다.
function Module(id, parent) {
this.id = id;
this.exports = {};
this.parent = parent;
this.filename = null;
this.loaded = false;
this.children = [];
}
module.exports = Module;
var module = new Module(filename, parent);
위 코드에서 Node는 생성자 Module을 정의하며, 모든 모듈은 Module의 인스턴스입니다. 보시다시피 현재 모듈(module.js)도 Module의 인스턴스입니다.
각 인스턴스에는 고유한 속성이 있습니다. 이러한 속성의 값이 무엇인지 예를 들어 보겠습니다. 새 스크립트 파일 a.js를 만듭니다.
// a.js
console.log('module.id: ', module.id);
console.log('module.exports: ', module.exports);
console.log('module.parent: ', module.parent);
console.log('module.filename: ', module.filename);
console.log('module.loaded: ', module.loaded);
console.log('module.children: ', module.children);
console.log('module.paths: ', module.paths);이 스크립트를 실행하세요.
$ node a.js
module.id: .
module.exports: {}
module.parent: null
module.filename: /home/ruanyf/tmp/a.js
module.loaded: false
module.children: []
module.paths: [ '/home/ruanyf/tmp/node_modules',
'/home/ruanyf/node_modules',
'/home/node_modules',
'/node_modules' ]
可以看到,如果没有父模块,直接调用当前模块,parent 属性就是 null,id 属性就是一个点。filename 属性是模块的绝对路径,path 属性是一个数组,包含了模块可能的位置。另外,输出这些内容时,模块还没有全部加载,所以 loaded 属性为 false 。
新建另一个脚本文件 b.js,让其调用 a.js 。
// b.js
var a = require('./a.js');运行 b.js 。
$ node b.js
module.id: /home/ruanyf/tmp/a.js
module.exports: {}
module.parent: { object }
module.filename: /home/ruanyf/tmp/a.js
module.loaded: false
module.children: []
module.paths: [ '/home/ruanyf/tmp/node_modules',
'/home/ruanyf/node_modules',
'/home/node_modules',
'/node_modules' ]
上面代码中,由于 a.js 被 b.js 调用,所以 parent 属性指向 b.js 模块,id 属性和 filename 属性一致,都是模块的绝对路径。
三、模块实例的 require 方法
每个模块实例都有一个 require 方法。
Module.prototype.require = function(path) {
return Module._load(path, this);
};由此可知,require 并不是全局性命令,而是每个模块提供的一个内部方法,也就是说,只有在模块内部才能使用 require 命令(唯一的例外是 REPL 环境)。另外,require 其实内部调用 Module._load 方法。
下面来看 Module._load 的源码。
Module._load = function(request, parent, isMain) {
// 计算绝对路径
var filename = Module._resolveFilename(request, parent);
// 第一步:如果有缓存,取出缓存
var cachedModule = Module._cache[filename];
if (cachedModule) {
return cachedModule.exports;
// 第二步:是否为内置模块
if (NativeModule.exists(filename)) {
return NativeModule.require(filename);
}
// 第三步:生成模块实例,存入缓存
var module = new Module(filename, parent);
Module._cache[filename] = module;
// 第四步:加载模块
try {
module.load(filename);
hadException = false;
} finally {
if (hadException) {
delete Module._cache[filename];
}
}
// 第五步:输出模块的exports属性
return module.exports;
};
上面代码中,首先解析出模块的绝对路径(filename),以它作为模块的识别符。然后,如果模块已经在缓存中,就从缓存取出;如果不在缓存中,就加载模块。
因此,Module._load 的关键步骤是两个。
◾Module._resolveFilename() :确定模块的绝对路径
◾module.load():加载模块
四、模块的绝对路径
下面是 Module._resolveFilename 方法的源码。
Module._resolveFilename = function(request, parent) {
// 第一步:如果是内置模块,不含路径返回
if (NativeModule.exists(request)) {
return request;
}
// 第二步:确定所有可能的路径
var resolvedModule = Module._resolveLookupPaths(request, parent);
var id = resolvedModule[0];
var paths = resolvedModule[1];
// 第三步:确定哪一个路径为真
var filename = Module._findPath(request, paths);
if (!filename) {
var err = new Error("Cannot find module '" + request + "'");
err.code = 'MODULE_NOT_FOUND';
throw err;
}
return filename;
};
上面代码中,在 Module.resolveFilename 方法内部,又调用了两个方法 Module.resolveLookupPaths() 和 Module._findPath() ,前者用来列出可能的路径,后者用来确认哪一个路径为真。
为了简洁起见,这里只给出 Module._resolveLookupPaths() 的运行结果。
[ '/home/ruanyf/tmp/node_modules',
'/home/ruanyf/node_modules',
'/home/node_modules',
'/node_modules'
'/home/ruanyf/.node_modules',
'/home/ruanyf/.node_libraries',
'$Prefix/lib/node' ]
上面的数组,就是模块所有可能的路径。基本上是,从当前路径开始一级级向上寻找 node_modules 子目录。最后那三个路径,主要是为了历史原因保持兼容,实际上已经很少用了。
有了可能的路径以后,下面就是 Module._findPath() 的源码,用来确定到底哪一个是正确路径。
Module._findPath = function(request, paths) {
// 列出所有可能的后缀名:.js,.json, .node
var exts = Object.keys(Module._extensions);
// 如果是绝对路径,就不再搜索
if (request.charAt(0) === '/') {
paths = [''];
}
// 是否有后缀的目录斜杠
var trailingSlash = (request.slice(-1) === '/');
// 第一步:如果当前路径已在缓存中,就直接返回缓存
var cacheKey = JSON.stringify({request: request, paths: paths});
if (Module._pathCache[cacheKey]) {
return Module._pathCache[cacheKey];
}
// 第二步:依次遍历所有路径
for (var i = 0, PL = paths.length; i < PL; i++) {
var basePath = path.resolve(paths[i], request);
var filename;
if (!trailingSlash) {
// 第三步:是否存在该模块文件
filename = tryFile(basePath);
if (!filename && !trailingSlash) {
// 第四步:该模块文件加上后缀名,是否存在
filename = tryExtensions(basePath, exts);
}
}
// 第五步:目录中是否存在 package.json
if (!filename) {
filename = tryPackage(basePath, exts);
}
if (!filename) {
// 第六步:是否存在目录名 + index + 后缀名
filename = tryExtensions(path.resolve(basePath, 'index'), exts);
}
// 第七步:将找到的文件路径存入返回缓存,然后返回
if (filename) {
Module._pathCache[cacheKey] = filename;
return filename;
}
}
// 第八步:没有找到文件,返回false
return false;
};
经过上面代码,就可以找到模块的绝对路径了。
有时在项目代码中,需要调用模块的绝对路径,那么除了 module.filename ,Node 还提供一个 require.resolve 方法,供外部调用,用于从模块名取到绝对路径。
require.resolve = function(request) {
return Module._resolveFilename(request, self);
};
// 用法
require.resolve('a.js')
// 返回 /home/ruanyf/tmp/a.js
五、加载模块
有了模块的绝对路径,就可以加载该模块了。下面是 module.load 方法的源码。
Module.prototype.load = function(filename) {
var extension = path.extname(filename) || '.js';
if (!Module._extensions[extension]) extension = '.js';
Module._extensions[extension](this, filename);
this.loaded = true;
};上面代码中,首先确定模块的后缀名,不同的后缀名对应不同的加载方法。下面是 .js 和 .json 后缀名对应的处理方法。
Module._extensions['.js'] = function(module, filename) {
var content = fs.readFileSync(filename, 'utf8');
module._compile(stripBOM(content), filename);
};
Module._extensions['.json'] = function(module, filename) {
var content = fs.readFileSync(filename, 'utf8');
try {
module.exports = JSON.parse(stripBOM(content));
} catch (err) {
err.message = filename + ': ' + err.message;
throw err;
}
};
这里只讨论 js 文件的加载。首先,将模块文件读取成字符串,然后剥离 utf8 编码特有的BOM文件头,最后编译该模块。
module._compile 方法用于模块的编译。
Module.prototype._compile = function(content, filename) {
var self = this;
var args = [self.exports, require, self, filename, dirname];
return compiledWrapper.apply(self.exports, args);
};
上面的代码基本等同于下面的形式。
(function (exports, require, module, __filename, __dirname) {
// 模块源码
});也就是说,模块的加载实质上就是,注入exports、require、module三个全局变量,然后执行模块的源码,然后将模块的 exports 变量的值输出。
(完)

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7615
7615
 15
1387
52
88
11
68
19
29
136
15
1387
52
88
11
68
19
29
136

 require의 용도는 무엇인가요?
Nov 27, 2023 am 10:03 AM
require의 용도는 무엇인가요?
Nov 27, 2023 am 10:03 AM
require 사용법: 1. 모듈 소개: 많은 프로그래밍 언어에서 require는 외부 모듈이나 라이브러리를 소개하여 이들이 제공하는 기능을 프로그램에서 사용할 수 있도록 하는 데 사용됩니다. 예를 들어 Ruby에서는 require를 사용하여 타사 라이브러리나 모듈을 로드할 수 있습니다. 2. 클래스 또는 메서드 가져오기: 일부 프로그래밍 언어에서는 require를 사용하여 특정 클래스나 메서드를 현재 파일에서 사용할 수 있도록 가져옵니다. 3. 특정 작업 수행: 일부 프로그래밍 언어나 프레임워크에서는 특정 작업이나 기능을 수행하는 데 require가 사용됩니다.
 PHP 헤더의 치명적인 오류를 해결하는 팁: require(): 필수 'data/tdk.php'를 열지 못했습니다.
Nov 27, 2023 pm 01:06 PM
PHP 헤더의 치명적인 오류를 해결하는 팁: require(): 필수 'data/tdk.php'를 열지 못했습니다.
Nov 27, 2023 pm 01:06 PM
PHP 개발에서 우리는 종종 fatalerror:require(): Failedopeningrequired'data/tdk.php'와 같은 오류 메시지를 접하게 됩니다. 이 오류는 일반적으로 PHP 애플리케이션의 파일 처리와 관련이 있습니다. 구체적인 이유는 잘못된 파일 경로, 존재하지 않는 파일 또는 불충분한 파일 권한 때문일 수 있습니다. 이 기사에서는 이러한 오류 메시지를 해결하기 위한 몇 가지 팁을 소개합니다. "치명적"인 경우 파일 경로를 확인하십시오.
 치명적인 오류: require(): 필수 'data/tdk.php' 열기 실패 오류 수정
Nov 27, 2023 am 11:40 AM
치명적인 오류: require(): 필수 'data/tdk.php' 열기 실패 오류 수정
Nov 27, 2023 am 11:40 AM
Fatalerror:require():Failedopeningrequired'data/tdk.php' 오류 수정 방법 웹사이트를 개발하거나 유지 관리하는 과정에서 우리는 종종 다양한 오류에 직면하게 됩니다. 일반적인 오류 중 하나는 "Fatalerror:require():Failedopeningrequired'data/tdk.php'"입니다. 이 실수는 하나
 PHP 헤더의 치명적인 오류를 해결하는 방법: require(): Failed opening require 'data/tdk.php' (include_path='.;C:\php\pear')
Nov 27, 2023 am 11:03 AM
PHP 헤더의 치명적인 오류를 해결하는 방법: require(): Failed opening require 'data/tdk.php' (include_path='.;C:\php\pear')
Nov 27, 2023 am 11:03 AM
PHP 헤더의 FatalError를 해결하는 방법 개요: require():Failedopeningrequired'data/tdk.php'(include_path='.;C:phppear'): PHP를 사용하여 웹 사이트를 개발하는 과정에서 다양한 문제를 자주 접하게 됩니다. 이런 오류가 발생합니다. 그 중 "FatalError:require():Failedopeningrequ
 반응 사용이 필요할 수 있나요?
Dec 27, 2022 am 09:47 AM
반응 사용이 필요할 수 있나요?
Dec 27, 2022 am 09:47 AM
React는 require를 사용할 수 있으며 올바른 사용 방법은 다음과 같습니다. 1. "<img src={require('../img/icon1.png')} alt="" />"를 통해 이미지를 읽습니다. "require('~/images/2.png').default" 방법을 사용하여 이미지를 읽습니다. 3. img 필드를 파일 이름과 이미지 이름의 두 부분으로 나눈 다음 "require('@/assets)를 사용합니다. " 읽는 방법 그냥 가져가세요.
 노드가 필요하다는 것은 무엇을 의미합니까?
Oct 18, 2022 pm 05:51 PM
노드가 필요하다는 것은 무엇을 의미합니까?
Oct 18, 2022 pm 05:51 PM
node의 require는 매개변수를 허용하는 함수이며, 형식 매개변수의 이름은 id이고 유형은 String입니다. require 함수는 "node_modules"의 상대 경로를 통해 모듈, JSON 파일 및 로컬 파일에 액세스할 수 있습니다. ", "로컬 모듈" 또는 "JSON 파일"인 경우 경로는 "__dirname" 변수 또는 현재 작업 디렉터리입니다.
 세 가지 다른 Java 팩토리 패턴 구현 방법 공개 - 소스 코드 분석을 시작점으로 삼음
Dec 28, 2023 am 09:29 AM
세 가지 다른 Java 팩토리 패턴 구현 방법 공개 - 소스 코드 분석을 시작점으로 삼음
Dec 28, 2023 am 09:29 AM
팩토리 패턴은 소프트웨어 개발에 널리 사용되며 객체를 생성하기 위한 디자인 패턴입니다. Java는 업계에서 널리 사용되는 인기 있는 프로그래밍 언어입니다. Java에는 팩토리 패턴의 다양한 구현이 있습니다. 이 기사에서는 소스 코드 관점에서 Java 팩토리 패턴을 해석하고 세 가지 구현 방법을 살펴보겠습니다. Java의 팩토리 패턴은 객체를 생성하고 관리하는 데 도움이 될 수 있습니다. 팩토리 클래스에서 객체의 인스턴스화 프로세스를 중앙 집중화하여 클래스 간의 결합을 줄이고 개선합니다.
 관련 PHP 헤더의 치명적인 오류를 해결하는 방법: require(): Failed opening require 'data/tdk.php' 오류
Nov 27, 2023 am 10:26 AM
관련 PHP 헤더의 치명적인 오류를 해결하는 방법: require(): Failed opening require 'data/tdk.php' 오류
Nov 27, 2023 am 10:26 AM
관련 PHP 헤더의 FatalError:require():Failedopeningrequired'data/tdk.php' 오류를 해결하는 방법 PHP 애플리케이션을 개발하는 동안 다양한 오류가 발생할 수 있습니다. 일반적인 오류 중 하나는 "FatalError:require():Failedopeningrequired'data/tdk.php'"입니다. 이건 틀렸어
