
영어명: Decision Tree
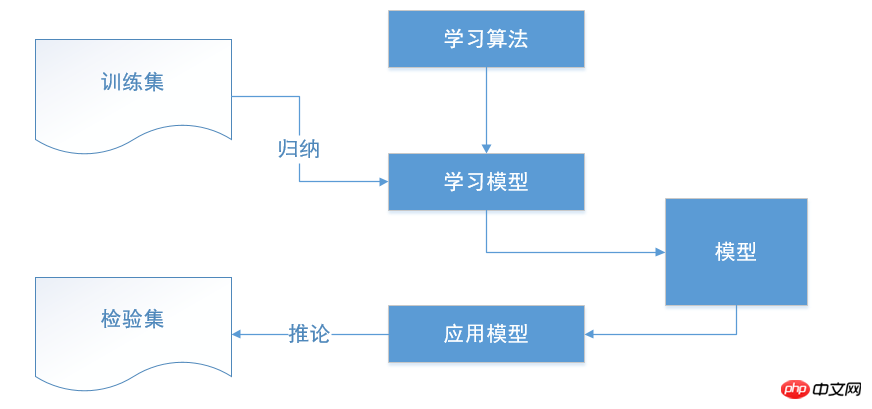
결정 트리는 먼저 데이터를 처리하고 귀납적 알고리즘을 사용하여 판독 가능한 규칙과 결정 트리를 생성한 다음 결정을 사용하여 새로운 데이터를 분석하는 일반적인 분류 방법입니다. 본질적으로 의사결정 트리는 일련의 규칙을 통해 데이터를 분류하는 프로세스입니다.
결정 트리는 지도 학습 방법으로 주로 분류 및 회귀에 사용됩니다. 알고리즘의 목표는 데이터 특징을 추론하고 의사결정 규칙을 학습하여 목표 변수를 예측하는 모델을 만드는 것입니다.
결정 트리는 if-else 구조와 유사합니다. 결과적으로 트리의 루트부터 리프 노드까지 지속적으로 판단하고 선택할 수 있는 트리를 생성해야 합니다. 하지만 여기서 if-else 판단 조건은 수동으로 설정하는 것이 아니라 우리가 제공하는 알고리즘을 기반으로 컴퓨터에 의해 자동으로 생성됩니다.
결정 지점
은 여러 가지 가능한 옵션 중 선택, 즉 최종적으로 가장 좋은 옵션이 선택되는 것입니다. 결정이 다단계 결정인 경우 결정 트리 중간에 여러 결정 지점이 있을 수 있으며, 결정 트리 루트에 있는 결정 지점이 최종 결정 계획입니다.
상태 노드
는 대체 계획의 경제적 효과(기대 가치)를 나타냅니다. 각 상태 노드의 경제적 효과를 비교하여 특정 의사 결정 기준에 따라 최상의 계획을 선택할 수 있습니다. 상태 노드에서 파생된 분기를 확률 분기라고 합니다. 확률 분기의 수는 발생할 수 있는 가능한 자연 상태의 수를 나타냅니다. 각 분기에는 상태가 발생할 확률이 표시되어야 합니다.
결과 노드
결과 노드 오른쪽 끝에 다양한 자연 상태에서 각 계획의 손익 가치를 표시합니다.
Simple 원리가 명확하고, 의사결정나무를 시각화할 수 있습니다
추론 과정을 이해하기 쉽고, 의사결정 추론 과정을 if-else 형식으로 표현할 수 있습니다
추론 과정은 전적으로 속성 변수의 값 특성에 달려 있습니다
대상은 자동으로 무시될 수 있습니다. 변수의 기여도가 없는 속성 변수는 속성 변수의 중요성을 판단하고 변수의 수를 줄이기 위한 참고 자료도 제공합니다. 의사결정 트리: 지나치게 복잡한 규칙이 설정될 수 있습니다. 즉, 과적합이 발생할 수 있습니다.
최적 의사결정 트리를 배우는 것은 NP-완전 문제입니다. 따라서 실제 의사결정나무 학습 알고리즘은 각 노드에서 국소 최적값을 달성하는 그리디 알고리즘 등 휴리스틱 알고리즘을 기반으로 한다. 이러한 알고리즘은 전체적으로 최적의 의사결정 트리를 반환한다고 보장할 수 없습니다. 이 문제는 기능과 샘플을 무작위로 선택하여 여러 의사결정 트리를 훈련함으로써 완화될 수 있습니다.
일부 문제는 의사결정 트리를 표현하기 어렵기 때문에 학습하기가 매우 어렵습니다. 예: XOR 문제, 패리티 검사 또는 멀티플렉서 문제
일부 요인이 지배적인 경우 의사결정 트리는 편향됩니다. 따라서 의사결정나무를 맞추기 전에 데이터의 영향 요인의 균형을 맞추는 것이 좋습니다.
의사결정 트리에 대한 일반적인 알고리즘
엔트로피: 시스템이 얼마나 지저분한지
ID3 알고리즘은 Quinlan이 제안한 고전적인 의사 결정 트리 학습 알고리즘입니다. ID3 알고리즘의 기본 아이디어는 의사결정 트리 노드의 속성 선택을 위한 척도로 정보 엔트로피를 사용하는 것입니다. 매번 가장 많은 정보를 가진 속성, 즉 엔트로피 값을 최소화할 수 있는 속성을 선택합니다. 엔트로피 값을 구성합니다. 가장 빠른 내림차순 결정 트리는 리프 노드에 대한 엔트로피 값이 0입니다. 이때 각 리프 노드에 해당하는 인스턴스 세트의 인스턴스는 동일한 클래스에 속합니다.
ID3 알고리즘을 사용하여 고객 이탈에 대한 조기 경고 분석을 실현하고 고객 이탈의 특성을 파악하여 통신 회사가 타겟 방식으로 고객 관계를 개선하고 고객 이탈을 방지하도록 돕습니다.
C4.5 알고리즘
C4.5는 ID3의 추가 확장으로 연속 속성을 구분하여 기능의 한계를 제거합니다. C4.5는 훈련 트리를 일련의 if-then 문법 규칙으로 변환합니다. 이러한 규칙의 정확성을 확인하여 어떤 규칙을 채택해야 하는지 결정할 수 있습니다. 규칙을 제거하여 정확도를 향상할 수 있다면 가지치기를 구현해야 합니다.
C4.5와 ID3의 핵심 알고리즘은 동일하지만 사용되는 방법이 다릅니다. C4.5는 정보 이득 분할의 기초로 ID3의 정보 이득 분할로 인한 속성 문제를 극복합니다. 알고리즘. 더 많은 값을 가진 속성을 선택하세요.
C5.0 알고리즘
분류 및 회귀 트리(CART - Classification And Regression Tree))는 매우 흥미롭고 효과적인 비모수적 분류 및 회귀 방법입니다. 이진 트리를 구축하여 예측 목적을 달성합니다. 분류 및 회귀 트리 CART 모델은 Breiman et al.에 의해 처음 제안되었으며 통계 및 데이터 마이닝 기술 분야에서 일반적으로 사용되었습니다. 기존 통계와는 완전히 다른 방식으로 예측 기준을 구성하므로 이해하고 사용하고 해석하기 쉽습니다. CART 모델에 의해 구축된 예측 트리는 일반적으로 사용되는 통계적 방법으로 구축된 대수적 예측 기준보다 더 정확한 경우가 많으며, 데이터가 복잡하고 변수가 많을수록 알고리즘의 우월성은 더욱 커집니다. 모델의 핵심은 예측 기준을 정확하게 구축하는 것입니다. 정의: 분류 및 회귀는 먼저 알려진 다변량 데이터를 사용하여 예측 기준을 구성한 다음 다른 변수의 값을 기반으로 하나의 변수를 예측합니다. 분류에서 사람들은 먼저 물체에 대해 다양한 측정을 수행한 다음 특정 분류 기준을 사용하여 물체가 속하는 범주를 결정하는 경우가 많습니다. 예를 들어, 특정 화석의 식별 특성을 고려하여 해당 화석이 어느 과, 어느 속, 심지어 어느 종에 속하는지 예측할 수 있습니다. 또 다른 예로는 특정 지역의 지질학적, 지구물리학적 정보를 바탕으로 해당 지역에 광물이 있는지 예측하는 것이다. 회귀는 객체를 분류하는 것이 아니라 객체의 특정 값을 예측하는 데 사용된다는 점에서 분류와 다릅니다. 예를 들어, 특정 지역의 광물 자원의 특성을 고려하여 해당 지역의 자원 양을 예측합니다.
CART는 C4.5와 매우 유사하지만 수치적 목표 변수(회귀)를 지원하고 의사결정 규칙을 생성하지 않습니다. CART는 기능과 임계값을 사용하여 각 노드에서 최대 정보 이득을 얻어 의사결정 트리를 구축합니다.
scikit-learn은 CART 알고리즘을 사용합니다.
샘플 코드:
#! /usr/bin/env python#-*- coding:utf-8 -*-from sklearn import treeimport numpy as np# scikit-learn使用的决策树算法是CARTX = [[0,0],[1,1]] Y = ["A","B"] clf = tree.DecisionTreeClassifier() clf = clf.fit(X,Y) data1 = np.array([2.,2.]).reshape(1,-1)print clf.predict(data1) # 预测类别 print clf.predict_proba(data1) # 预测属于各个类的概率
좋아, 그게 다입니다. 도움이 되었기를 바랍니다.
이 기사의 github 주소:
20170619_Decision Tree Algorithm.md
추가를 환영합니다
위 내용은 의사결정 트리 알고리즘이란 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



