

MySQL 테스트 환경
테스트 테이블은 다음과 같습니다
create table test_table2 ( id int auto_increment primary key, pay_id int, pay_time datetime, other_col varchar(100) )
테스트 데이터를 삽입하기 위한 저장 프로시저를 구축합니다. 여기서는 pay_id가 반복 가능하다는 점입니다. 처리되고 300W의 데이터가 루프에 삽입됩니다. 이 과정에서 반복되는 pay_id는 데이터 100개마다 삽입되며 시간 필드는 일정 범위 내에서 무작위입니다
CREATE DEFINER=`root`@`%` PROCEDURE `test_insert`(IN `loopcount` INT) LANGUAGE SQLNOT DETERMINISTICCONTAINS SQL SQL SECURITY DEFINER COMMENT ''BEGINdeclare cnt int;set cnt = 0;while cnt< loopcount doinsert into test_table2 (pay_id,pay_time,other_col) values (cnt,date_add(now(), interval floor(300*rand()) day),uuid());if (cnt mod 100 = 0) theninsert into test_table2 (pay_id,pay_time,other_col) values (cnt,date_add(now(), interval floor(300*rand()) day),uuid());end if;set cnt = cnt + 1; end while;END
Execute call test_insert(3000000) Insert 303000; 행의 데이터
서브 쿼리를 작성하는 두 가지 방법
쿼리의 일반적인 의미는 특정 기간 내에 비즈니스 ID가 1보다 큰 데이터를 쿼리하는 것이므로 작성하는 방법에는 두 가지가 있습니다.
첫 번째 작성 방법은 다음과 같습니다. IN 하위 쿼리는 IN 하위 쿼리의 결과에 따라 외부 레이어에 쿼리되는 비즈니스 통계 행이 있습니다. 업체 ID의 pay_id 컬럼에 인덱스를 추가하고 로직도 상대적으로 간단합니다.
데이터의 양이 많고 인덱스가 필요하지 않은 경우에는 실제로 이 방법이 상대적으로 비효율적입니다
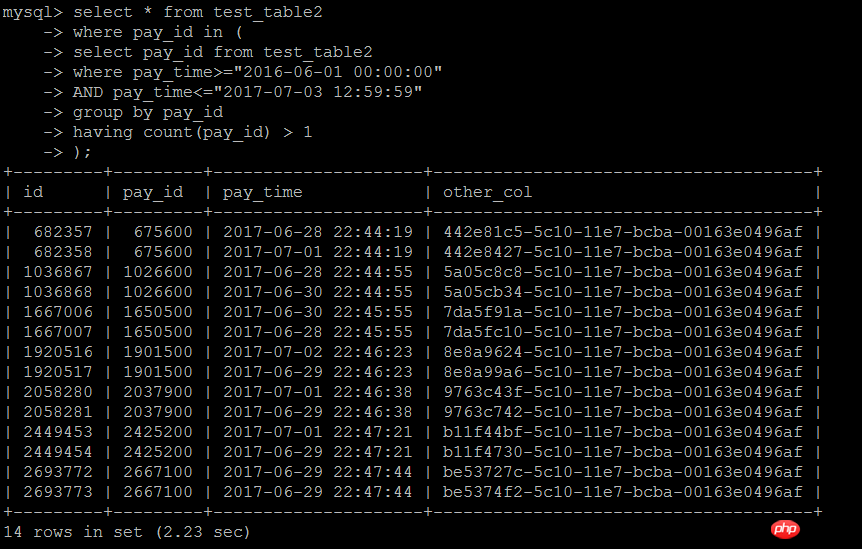
select * from test_table2 force index(idx_pay_id)where pay_id in ( select pay_id from test_table2 where pay_time>="2016-06-01 00:00:00" AND pay_time<="2017-07-03 12:59:59" group by pay_id having count(pay_id) > 1);
실행 결과: 2.23초
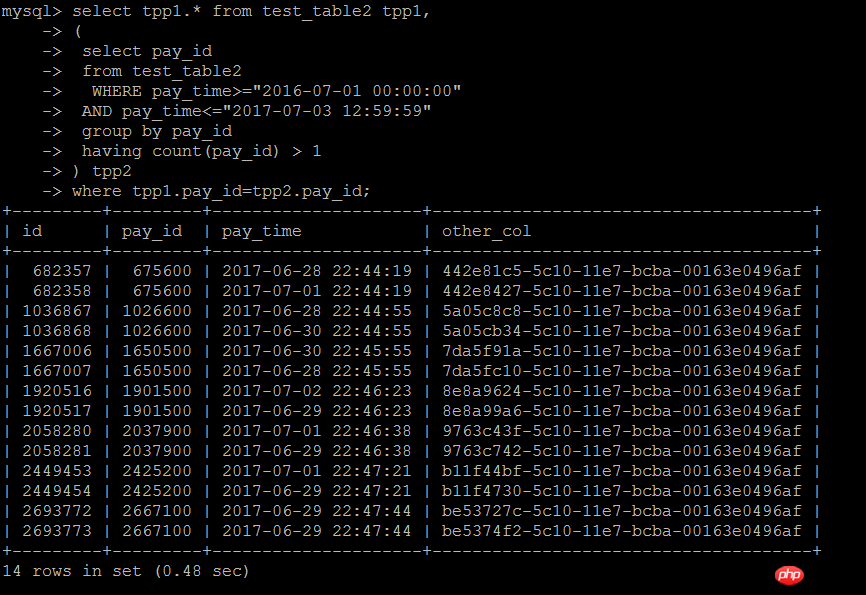
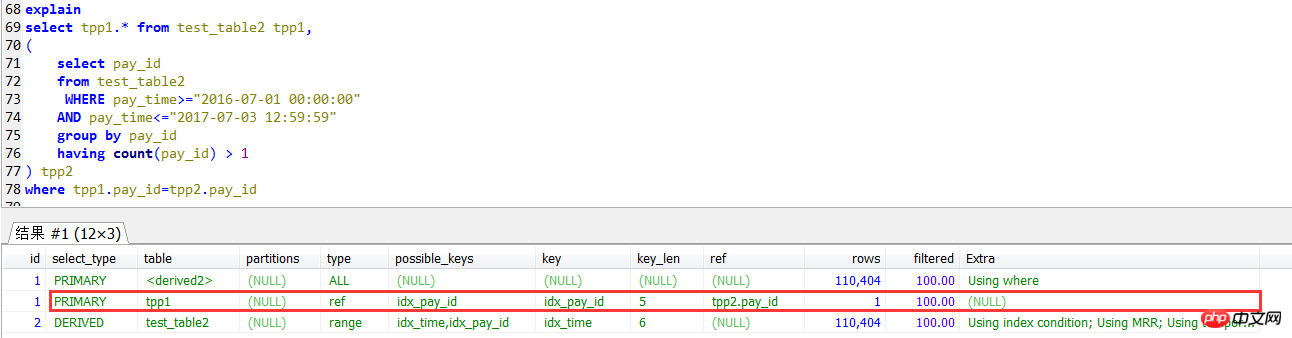
두 번째 작성 방법은 하위 쿼리로 조인하는 것인데, 이 작성 방법은 위의 IN 하위 쿼리 작성 방법과 동일합니다. 다음 테스트에서는 효율성이 실제로 많이 향상되었음을 확인했습니다
select tpp1.* from test_table2 tpp1,
( select pay_id
from test_table2
WHERE pay_time>="2016-07-01 00:00:00"
AND pay_time<="2017-07-03 12:59:59"
group by pay_id
having count(pay_id) > 1) tpp2
where tpp1.pay_id=tpp2.pay_id실행. 결과: 0.48초
서브 쿼리 실행 계획에서 외부 쿼리를 찾습니다. pay_id에 대한 인덱스를 사용하지 않는 전체 테이블 스캔 방식입니다.
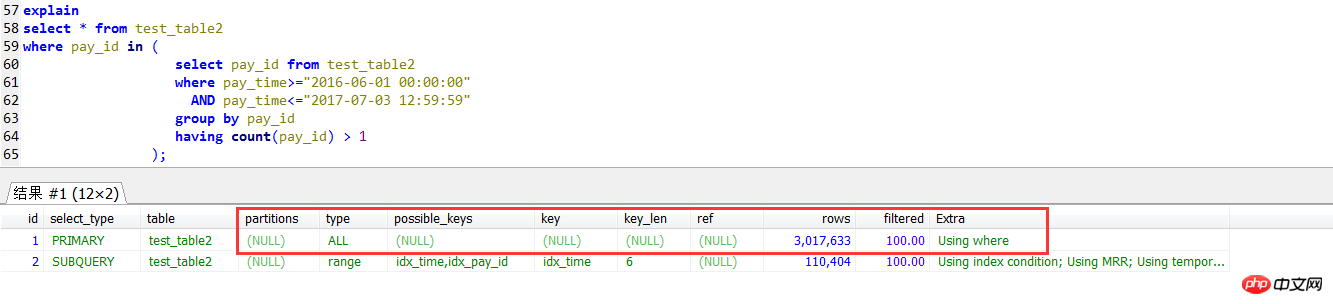
조인 셀프 체크 실행 계획, 외부 쿼리 레이어(tpp1 별칭 쿼리)는 pay_id의 인덱스를 사용합니다.
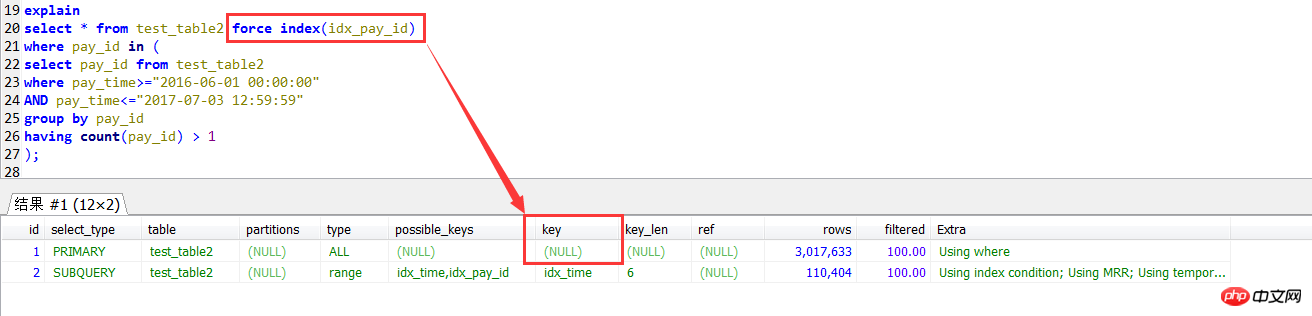
나중에 첫 번째 쿼리 방법으로 강제 인덱싱을 사용하고 싶었지만 오류를보고하지는 않았지만 전혀 쓸모가 없었습니다
ry는 직설적이야 값을 사용하면 정상적으로 사용할 수 있습니다.

IN 하위 쿼리에 대한 MySQL의 지원은 실제로 그다지 좋지 않다는 것을 알 수 있습니다.
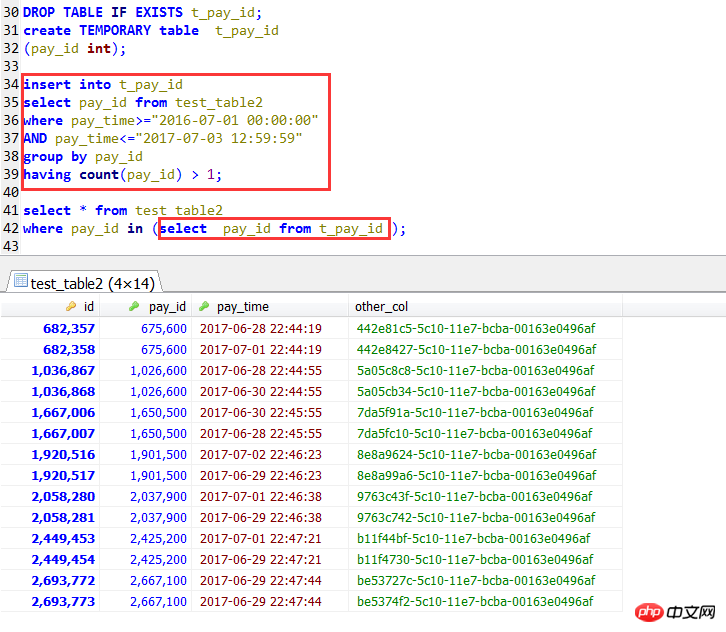
추가: 임시 테이블을 사용하는 경우를 추가합니다. 많은 조인 방법보다 효율적이지만 IN 하위 쿼리를 직접 사용하는 것보다 효율적이지만 이 경우 인덱스를 사용할 수도 있습니다. 이 경우 간단한 경우에는 임시 테이블을 사용할 필요가 없습니다.
다음은 sqlserver 2014에서 비슷한 경우를 테스트한 것으로, 수만 개의 동일한 테스트 테이블 구조와 수량을 가지고 있는 것을 알 수 있다. SQL Server에서 사용할 수 있습니다. (실행 계획 + 효율성) 이 점에서는 SQL Server가 MySQL보다 훨씬 좋습니다
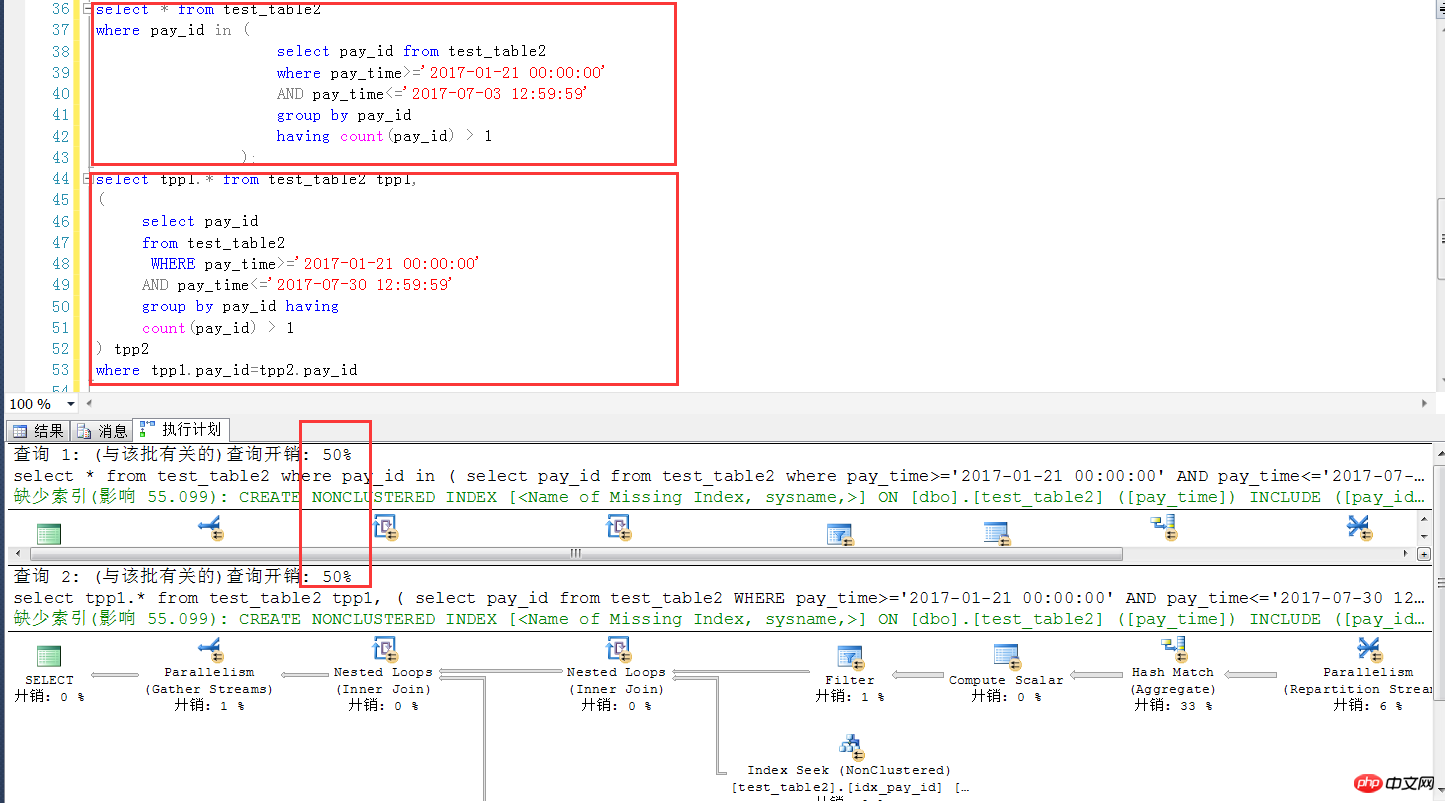
다음은 sqlserver의 테스트 환경 스크립트입니다.
create table test_table2
(
id int identity(1,1) primary key,
pay_id int,
pay_time datetime,
other_col varchar(100)
)begin trandeclare @i int = 0while @i<300000begininsert into test_table2 values (@i,getdate()-rand()*300,newid());
if(@i%1000=0)begininsert into test_table2 values (@i,getdate()-rand()*300,newid());endset @i = @i + 1endCOMMITGOcreate index idx_pay_id on test_table2(pay_id);
create index idx_time on test_table2(pay_time);GOselect * from test_table2
where pay_id in (select pay_id from test_table2 where pay_time>='2017-01-21 00:00:00' AND pay_time<='2017-07-03 12:59:59' group by pay_id having count(pay_id) > 1);
select tpp1.* from test_table2 tpp1,
( select pay_id
from test_table2
WHERE pay_time>='2017-01-21 00:00:00' AND pay_time<='2017-07-30 12:59:59'
group by pay_id having
count(pay_id) > 1) tpp2
where tpp1.pay_id=tpp2.pay_id요약: MySQL 데이터 버전 5.7.18부터 IN 하위 쿼리는 여전히 주의해서 사용해야 합니다
위 내용은 MySQL에서 두 개의 하위 쿼리를 작성하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



