

JAVA의 ThreadPoolExecutor 스레드 풀 원리 및 실행 방법 예제에 대한 자세한 설명

아래 편집기에서는 ThreadPoolExecutor 스레드 풀 원리와 해당 실행 방법(자세한 설명)에 대한 기사를 제공합니다. 편집자님이 꽤 좋다고 생각하셔서 지금 공유하고 모두에게 참고용으로 드리고자 합니다. 편집자를 따라가서 살펴보겠습니다.
jdk1.7.0_79
대부분의 사람들은 스레드 풀을 사용할 수 있으며, 스레드 풀을 사용하는 이유도 알고 있습니다. 작업은 비동기적으로 실행되어야 하고 스레드는 균일하게 관리되어야 합니다. 스레드 풀에서 스레드를 얻는 것과 관련하여 대부분의 사람들은 작업을 수행하기 위해 스레드가 필요한 경우 해당 작업을 스레드 풀에 던질 것이라는 점만 알 수 있습니다. 스레드 풀에 유휴 스레드가 있으면 해당 스레드가 실행됩니다. . 유휴 스레드가 없으면 실행됩니다. 실제로 스레드 풀의 실행 원리는 그 이상으로 간단합니다.
스레드 풀 클래스 - ThreadPoolExecutor는 Java 동시성 패키지에서 제공됩니다. 실제로 우리 중 더 많은 사람들이 Executors 팩토리 클래스인 newFixedThreadPool, newSingleThreadPool, newCachedThreadPool에서 제공하는 스레드 풀을 사용할 수 있습니다. 이들 간의 관계에 대해 먼저 ThreadPoolExecutor를 살펴보겠습니다. 소스 코드를 살펴보면 총 4개의 구성 메소드가 있음을 알 수 있습니다.
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue)
먼저 스레드 풀 ThreadPoolExecutor의 실행 원리를 이해하기 위해 이러한 매개변수부터 시작해 보겠습니다.
corePoolSize: 코어 스레드 풀의 스레드 수
maximumPoolSize: 스레드 풀 스레드의 최대 수
keepAliveTime: 스레드 활동 유지 시간, 스레드 풀 작업 스레드가 유휴 상태가 된 후에도 활성 상태로 유지되는 시간입니다.
단위: 스레드 활동 유지 시간의 단위입니다.
workQueue: 작업 대기열에서 사용하는 차단 대기열을 지정합니다.
corePoolSize와 maximumPoolSize는 모두 스레드 풀의 스레드 수를 지정합니다. 스레드 풀을 사용할 때는 패스만 하면 되는 것 같습니다. 최대 하나의 스레드 풀을 만들 수 있습니다. Java는 위에서 언급한 newFixedThreadPool, newSingleThreadExecutor 및 newCachedThreadPool과 같은 일반적으로 사용되는 스레드 풀 클래스를 제공합니다. 스레드 풀을 직접 수행하려면 스레드 풀에 대한 일부 매개변수를 "구성"해야 합니다.
작업을 스레드 풀에 넘겨 처리할 때 스레드 풀의 실행 원리는 아래 그림과 같습니다. "Java 동시 프로그래밍 기술"을 참조하세요.
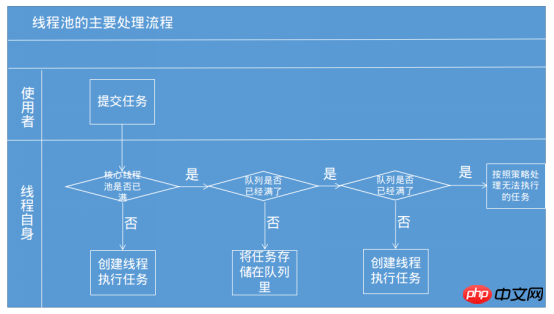
① 먼저 결정됩니다. 코어 스레드 풀에 스레드가 있는지 여부, 유휴 스레드가 있으면 스레드를 생성하여 작업을 수행합니다.
②코어 스레드 풀에 실행 가능한 스레드가 없으면 해당 작업은 작업 큐에 던져집니다.
3 작업 대기열(제한됨)도 가득 차 있지만 실행 중인 스레드 수가 최대 스레드 풀 수보다 적은 경우 작업을 실행하기 위해 새 스레드가 생성되지만 실행 중인 스레드 수에 도달한 경우 최대 스레드 풀 수에 도달하면 현재 작업을 수행하기 위한 스레드가 생성되지 않습니다.
사실 스레드 풀은 단순히 스레드 풀에 작업을 넣는 것이 아닙니다. 스레드 풀에 스레드가 있으면 작업이 실행되고, 스레드가 없으면 대기합니다.
스레드 풀의 원리를 통합하기 위해 위에서 언급한 일반적으로 사용되는 세 가지 스레드 풀에 대해 알아 보겠습니다.
Executors.newFixedThreadPool: 고정된 수의 스레드로 스레드 풀을 만듭니다.
// Executors#newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
}newFixedThreadPool에서 ThreadPoolExecutor 클래스가 호출되고 전달된 매개변수 corePoolSize= maximumPoolSize=nThread인 것을 확인할 수 있습니다. 스레드 풀의 실행 원리를 살펴보면, 작업이 스레드 풀에 제출되면 먼저 코어 스레드 풀에 유휴 스레드가 있는지 확인하고, 그렇지 않으면 스레드를 생성합니다. , 작업은 작업 대기열에 배치됩니다(여기서는 제한된 차단 대기열 LinkedBlockingQueue입니다). 작업 대기열이 가득 찬 경우 newFixedThreadPool의 경우 최대 스레드 풀 수 = 코어 스레드 풀 수입니다. 큐도 꽉 차서 작업을 실행하기 위해 새 스레드를 확장할 수 없습니다.
Executors.newSingleThreadExecutor: 하나의 스레드만 포함하는 스레드 풀을 만듭니다.
//Executors# newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegateExecutorService(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()));
}只有一个线程的线程池好像有点奇怪,并且并没有直接将返回ThreadPoolExecutor,甚至也没有直接将线程池数量1传递给newFixedThreadPool返回。那就说明这个只含有一个线程的线程池,或许并没有只包含一个线程那么简单。在其源码注释中这么写到:创建只有一个工作线程的线程池用于操作一个无界队列(如果由于前驱节点的执行被终止结束了,一个新的线程将会继续执行后继节点线程)任务得以继续执行,不同于newFixedThreadPool(1)不会有额外的线程来重新继续执行后继节点。也就是说newSingleThreadExecutor自始至终都只有一个线程在执行,这和newFixedThreadPool一样,但如果线程终止结束过后newSingleThreadExecutor则会重新创建一个新的线程来继续执行任务队列中的线程,而newFixedThreaPool则不会。
Executors.newCachedThreadPool:根据需要创建新线程的线程池。
//Executors#newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPooExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
}可以看到newCachedThread返回的是ThreadPoolExecutor,其参数核心线程池corePoolSize = 0, maximumPoolSize = Integer.MAX_VALUE,这也就是说当任务被提交到newCachedThread线程池时,将会直接把任务放到SynchronousQueue任务队列中,maximumPool从任务队列中获取任务。注意SynchronousQueue是一个没有容量的队列,也就是说每个入队操作必须等待另一个线程的对应出队操作,如果主线程提交任务的速度高于maximumPool中线程处理任务的速度时,newCachedThreadPool会不断创建线程,线程多并不是一件好事,严重会耗尽CPU和内存资源。
题外话:newFixedThreadPool、newSingleThreadExecutor、newCachedThreadPool,这三者都直接或间接调用了ThreadPoolExecutor,为什么它们三者没有直接是其子类,而是通过Executors来实例化呢?这是所采用的静态工厂方法,在java.util.Connections接口中同样也是采用的静态工厂方法来创建相关的类。这样有很多好处,静态工厂方法是用来产生对象的,产生什么对象没关系,只要返回原返回类型或原返回类型的子类型都可以,降低API数目和使用难度,在《Effective Java》中的第1条就是静态工厂方法。
回到ThreadPoolExecutor,首先来看它的继承关系:
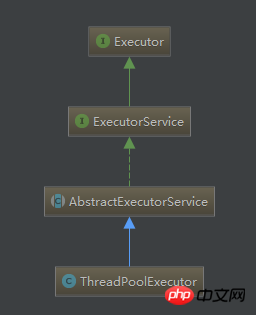
ThreadPoolExecutor它的顶级父类是Executor接口,只包含了一个方法——execute,这个方法也就是线程池的“执行”。
//Executor#execute
public interface Executor {
void execute(Runnable command);
}Executor#execute的实现则是在ThreadPoolExecutor中实现的:
//ThreadPoolExecutor#execute
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
…
}一来就碰到个不知所云的ctl变量它的定义:
private final AtomicInteger ctl = new AtlmicInteger(ctlOf(RUNNING, 0));
这个变量使用来干嘛的呢?它的作用有点类似我们在《ReadWriteLock接口及其实现ReentrantReadWriteLock》中提到的读写锁有读、写两个同步状态,而AQS则只提供了state一个int型变量,此时将state高16位表示为读状态,低16位表示为写状态。这里的clt同样也是,它表示了两个概念:
workerCount:当前有效的线程数
runState:当前线程池的五种状态,Running、Shutdown、Stop、Tidying、Terminate。
int型变量一共有32位,线程池的五种状态runState至少需要3位来表示,故workCount只能有29位,所以代码中规定线程池的有效线程数最多为229-1。
//ThreadPoolExecutor private static final int COUNT_BITS = Integer.SIZE – 3; //32-3=29,线程数量所占位数 private static final int CAPACITY = (1 << COUNT_BITS) – 1; //低29位表示最大线程数,229-1 //五种线程池状态 private static final int RUNNING = -1 << COUNT_BITS; /int型变量高3位(含符号位)101表RUNING private static final int SHUTDOWN = 0 << COUNT_BITS; //高3位000 private static final int STOP = 1 << COUNT_BITS; //高3位001 private static final int TIDYING = 2 << COUNT_BITS; //高3位010 private static final int TERMINATED = 3 << COUNT_BITS; //高3位011
再次回到ThreadPoolExecutor#execute方法:
//ThreadPoolExecutor#execute
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get(); //由它可以获取到当前有效的线程数和线程池的状态
/*1.获取当前正在运行线程数是否小于核心线程池,是则新创建一个线程执行任务,否则将任务放到任务队列中*/
if (workerCountOf(c) < corePoolSize){
if (addWorker(command, tre)) //在addWorker中创建工作线程执行任务
return ;
c = ctl.get();
}
/*2.当前核心线程池中全部线程都在运行workerCountOf(c) >= corePoolSize,所以此时将线程放到任务队列中*/
if (isRunning(c) && workQueue.offer(command)) { //线程池是否处于运行状态,且是否任务插入任务队列成功
int recheck = ctl.get();
if (!isRunning(recheck) && remove(command)) //线程池是否处于运行状态,如果不是则使刚刚的任务出队
reject(command); //抛出RejectedExceptionException异常
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
/*3.插入队列不成功,且当前线程数数量小于最大线程池数量,此时则创建新线程执行任务,创建失败抛出异常*/
else if (!addWorker(command, false)){
reject(command); //抛出RejectedExceptionException异常
}
}上面代码注释第7行的即判断当前核心线程池里是否有空闲线程,有则通过addWorker方法创建工作线程执行任务。addWorker方法较长,筛选出重要的代码来解析。
//ThreadPoolExecutor#addWorker
private boolean addWorker(Runnable firstTask, boolean core) {
/*首先会再次检查线程池是否处于运行状态,核心线程池中是否还有空闲线程,都满足条件过后则会调用compareAndIncrementWorkerCount先将正在运行的线程数+1,数量自增成功则跳出循环,自增失败则继续从头继续循环*/
...
if (compareAndIncrementWorkerCount(c))
break retry;
...
/*正在运行的线程数自增成功后则将线程封装成工作线程Worker*/
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
final ReentrantLock mainLock = this.mainLock; //全局锁
w = new Woker(firstTask); //将线程封装为Worker工作线程
final Thread t = w.thread;
if (t != null) {
mainLock.lock(); //获取全局锁
/*当持有了全局锁的时候,还需要再次检查线程池的运行状态等*/
try {
int c = clt.get();
int rs = runStateOf(c); //线程池运行状态
if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)){ //线程池处于运行状态,或者线程池关闭且任务线程为空
if (t.isAlive()) //线程处于活跃状态,即线程已经开始执行或者还未死亡,正确的应线程在这里应该是还未开始执行的
throw new IllegalThreadStateException();
workers.add(w); //private final HashSet<Worker> wokers = new HashSet<Worker>();包含线程池中所有的工作线程,只有在获取了全局的时候才能访问它。将新构造的工作线程加入到工作线程集合中
int s = worker.size(); //工作线程数量
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true; //新构造的工作线程加入成功
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start(); //在被构造为Worker工作线程,且被加入到工作线程集合中后,执行线程任务,注意这里的start实际上执行Worker中run方法,所以接下来分析Worker的run方法
workerStarted = true;
}
}
} finally {
if (!workerStarted) //未能成功创建执行工作线程
addWorkerFailed(w); //在启动工作线程失败后,将工作线程从集合中移除
}
return workerStarted;
}在上面第35代码中,工作线程被成功添加到工作线程集合中后,则开始start执行,这里start执行的是Worker工作线程中的run方法。
//ThreadPoolExecutor$Worker,它继承了AQS,同时实现了Runnable,所以它具备了这两者的所有特性
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
final Thread thread;
Runnable firstTask;
public Worker(Runnable firstTask) {
setState(-1); //设置AQS的同步状态为-1,禁止中断,直到调用runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this); //通过线程工厂来创建一个线程,将自身作为Runnable传递传递
}
public void run() {
runWorker(this); //运行工作线程
}
}ThreadPoolExecutor#runWorker,在此方法中,Worker在执行完任务后,还会循环获取任务队列里的任务执行(其中的getTask方法),也就是说Worker不仅仅是在执行完给它的任务就释放或者结束,它不会闲着,而是继续从任务队列中获取任务,直到任务队列中没有任务可执行时,它才退出循环完成任务。理解了以上的源码过后,往后线程池执行原理的第二步、第三步的理解实则水到渠成。
위 내용은 JAVA의 ThreadPoolExecutor 스레드 풀 원리 및 실행 방법 예제에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7461
7461
 15
1376
52
77
11
44
19
17
17
15
1376
52
77
11
44
19
17
17



 Java의 난수 생성기
Aug 30, 2024 pm 04:27 PM
Java의 난수 생성기
Aug 30, 2024 pm 04:27 PM
Java의 난수 생성기 안내. 여기서는 예제를 통해 Java의 함수와 예제를 통해 두 가지 다른 생성기에 대해 설명합니다.
 자바의 웨카
Aug 30, 2024 pm 04:28 PM
자바의 웨카
Aug 30, 2024 pm 04:28 PM
Java의 Weka 가이드. 여기에서는 소개, weka java 사용 방법, 플랫폼 유형 및 장점을 예제와 함께 설명합니다.
 Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 스미스 번호
Aug 30, 2024 pm 04:28 PM
Java의 Smith Number 가이드. 여기서는 정의, Java에서 스미스 번호를 확인하는 방법에 대해 논의합니다. 코드 구현의 예.
 Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
Java Spring 인터뷰 질문
Aug 30, 2024 pm 04:29 PM
이 기사에서는 가장 많이 묻는 Java Spring 면접 질문과 자세한 답변을 보관했습니다. 그래야 면접에 합격할 수 있습니다.
 Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream foreach에서 나누거나 돌아 오시겠습니까?
Feb 07, 2025 pm 12:09 PM
Java 8은 스트림 API를 소개하여 데이터 컬렉션을 처리하는 강력하고 표현적인 방법을 제공합니다. 그러나 스트림을 사용할 때 일반적인 질문은 다음과 같은 것입니다. 기존 루프는 조기 중단 또는 반환을 허용하지만 스트림의 Foreach 메소드는이 방법을 직접 지원하지 않습니다. 이 기사는 이유를 설명하고 스트림 처리 시스템에서 조기 종료를 구현하기위한 대체 방법을 탐색합니다. 추가 읽기 : Java Stream API 개선 스트림 foreach를 이해하십시오 Foreach 메소드는 스트림의 각 요소에서 하나의 작업을 수행하는 터미널 작동입니다. 디자인 의도입니다
 Java의 날짜까지의 타임스탬프
Aug 30, 2024 pm 04:28 PM
Java의 날짜까지의 타임스탬프
Aug 30, 2024 pm 04:28 PM
Java의 TimeStamp to Date 안내. 여기서는 소개와 예제와 함께 Java에서 타임스탬프를 날짜로 변환하는 방법에 대해서도 설명합니다.
