
python 2.7 구성
bs4
requestspip를 사용하여 설치 sudo pip install bs4 설치
sudo pip 설치 요청
bs4는 웹 페이지를 크롤링하기 때문에 사용법을 간략하게 설명합니다. find_all
find와 find_all의 차이점은 반환되는 내용이 다르다는 것입니다. find는 일치하는 첫 번째 태그를 반환하고 태그의 내용은
find_all이 목록을 반환합니다
예를 들어, 우리는 test.html을 작성합니다. 테스트 find와 find_all의 차이점. 내용은
<html> <head> </head> <body> <div id="one"><a></a></div> <div id="two"><a href="#">abc</a></div> <div id="three"><a href="#">three a</a><a href="#">three a</a><a href="#">three a</a></div> <div id="four"><a href="#">four<p>four p</p><p>four p</p><p>four p</p> a</a></div> </body> </html>
<br/>
test.py의 코드는
from bs4 import BeautifulSoup import lxml if __name__=='__main__': s = BeautifulSoup(open('test.html'),'lxml') print s.prettify() print "------------------------------" print s.find('div') print s.find_all('div') print "------------------------------" print s.find('div',id='one') print s.find_all('div',id='one') print "------------------------------" print s.find('div',id="two") print s.find_all('div',id="two") print "------------------------------" print s.find('div',id="three") print s.find_all('div',id="three") print "------------------------------" print s.find('div',id="four") print s.find_all('div',id="four") print "------------------------------"
<br/>
실행 후 지정된 태그를 가져오면 결과를 볼 수 있습니다. 두 개의 태그 세트를 얻을 때

할 때 둘의 차이점이 표시됩니다. 따라서 사용할 때 원하는 것에 주의해야 합니다. 그렇지 않으면 오류가 나타납니다. <br/>다음 단계는 요청을 통해 웹페이지 정보를 얻는 것입니다. 왜 다른 사람들이 들은 것과 다른 것에 대해 글을 쓰는지 잘 모르겠습니다. <br/>웹페이지에 직접 액세스하고 get을 통해 prose.com에서 여러 카테고리의 여러 보조 웹페이지를 얻습니다. 그런 다음 그룹 테스트를 통과하여 모든 웹페이지를 크롤링합니다
def get_html():
url = ""
two_html = ['sanwen','shige','zawen','suibi','rizhi','novel'] for doc in two_html:
i=1 if doc=='sanwen':print "running sanwen -----------------------------" if doc=='shige':print "running shige ------------------------------" if doc=='zawen':print 'running zawen -------------------------------' if doc=='suibi':print 'running suibi -------------------------------' if doc=='rizhi':print 'running ruzhi -------------------------------' if doc=='nove':print 'running xiaoxiaoshuo -------------------------' while(i<10):
par = {'p':i}
res = requests.get(url+doc+'/',params=par)if res.status_code==200:
soup(res.text)
i+=i
<br/>
코드의 이 부분에서는 200이 아닌 res.status_code를 처리하지 않았습니다. 결과적으로 문제는 오류가 발생하지 않는다는 것입니다. 표시되고 크롤링된 콘텐츠는 손실됩니다. 그러다가 Sanwen.net 웹페이지를 분석해 보니 www.sanwen.net/rizhi/&p=1
p의 최대값은 10입니다. 지난번에 디스크를 크롤링했을 때는 였네요. 100페이지는 나중에 분석하겠습니다. 그런 다음 get 메소드를 통해 각 페이지의 내용을 가져옵니다. <br/>각 페이지의 내용을 가져온 후 작성자와 제목을 분석합니다.
def soup(html_text):
s = BeautifulSoup(html_text,'lxml')
link = s.find('div',class_='categorylist').find_all('li') for i in link:if i!=s.find('li',class_='page'):
title = i.find_all('a')[1]
author = i.find_all('a')[2].text
url = title.attrs['href']
sign = re.compile(r'(//)|/')
match = sign.search(title.text)
file_name = title.text if match:
file_name = sign.sub('a',str(title.text))
<br/>
제목을 가져올 때 문제가 발생했습니다. 글을 쓸 때 제목에 슬래시를 추가하는 이유는 무엇입니까? 한개도 아니고 2개가 더 있습니다. 나중에 파일을 작성할 때 이 문제로 인해 파일명이 틀리게 되어 정규식을 작성해 드렸습니다. <br/>마지막 단계는 각 페이지의 분석을 통해 기사 주소를 얻은 다음, 원래는 웹 페이지 주소를 변경하여 하나씩 내용을 가져오고 싶었습니다. 문제.
def get_content(url):
res = requests.get(''+url) if res.status_code==200:
soup = BeautifulSoup(res.text,'lxml')
contents = soup.find('div',class_='content').find_all('p')
content = ''for i in contents:
content+=i.text+'\n'return content
<br/>
마지막으로 파일을 작성하고 저장하면 ok
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n')
f.write(author+'\n')
content=get_content(url)
f.write(content)
f.close()
세 가지 기능이 산문 네트워크에서 산문을 가져오는데 문제가 있습니다. 일부 산문이 왜 손실되었는지 모르겠습니다. 대략적인 내용만 얻을 수 있습니다. 400개가 넘는 기사가 있습니다. 이것은 prose.com의 기사와 많이 다르지만 실제로는 페이지별로 얻은 것입니다. 이 문제. 물론 웹 페이지를 접근 불가능하게 만들어야 할 것 같아요
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n')
f.write(author+'\n')
content=get_content(url)
f.write(content)
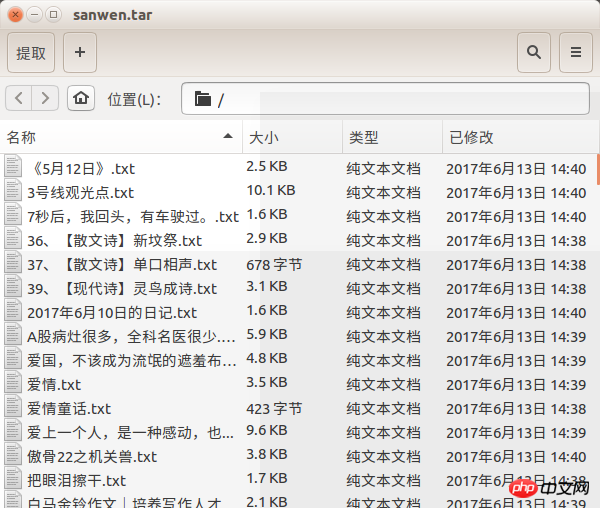
f.close()렌더링을 잊어버릴 뻔했어요

위 내용은 Python은 prose.com의 기사를 어떻게 크롤링합니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



