

Python으로 qq 음악을 크롤링하는 프로세스의 예

1. 소개
가끔 좋은 음악을 다운받고 싶은데 웹페이지에서 다운받을 때마다 로그인이 필요하거나 뭔가 귀찮네요. . 여기 qqmusic 크롤러가 있습니다. 적어도 for 루프 크롤러에서 가장 중요한 것은 크롤링할 요소의 URL을 찾는 것이라고 생각합니다. 아래부터 살펴보겠습니다(틀렸다면 웃지 마세요)
<br>
2. Python은 QQ 음악 싱글을 크롤링합니다.
MOOC.com에서 본 동영상에서 아주 잘 설명했습니다. . 또한 일반적으로 크롤러를 작성하는 단계를 따릅니다. ㅋㅋㅋㅋㅋㅋㅋㅋㅋ 1. 목표를 정하라
우선 목표를 명확히 해야 한다. 이번에는 QQ뮤직 가수 앤디 라우(Andy Lau)의 싱글을 크롤링했다. 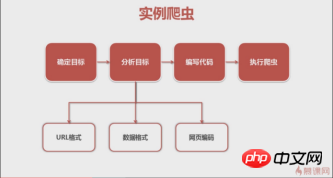 (바이두 백과사전) -> 분석 대상(전략: URL 형식(범위), 데이터 형식, 웹 페이지 인코딩) -> 코드 작성 -> 크롤러 실행
(바이두 백과사전) -> 분석 대상(전략: URL 형식(범위), 데이터 형식, 웹 페이지 인코딩) -> 코드 작성 -> 크롤러 실행
2. 분석 대상 link :
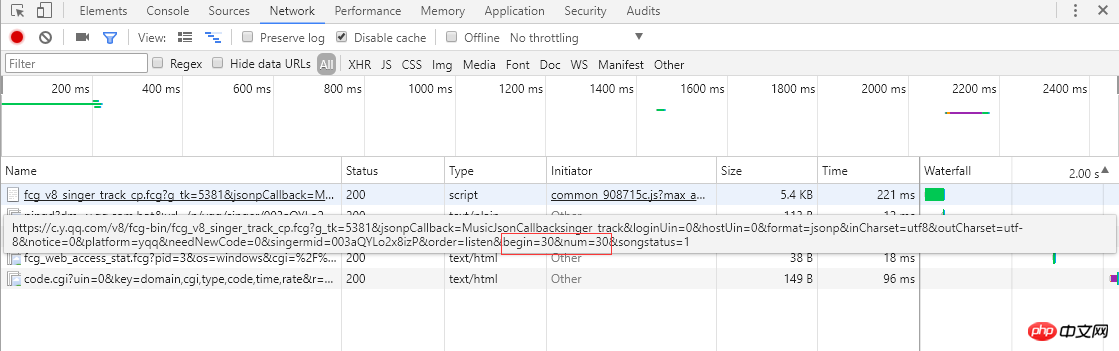
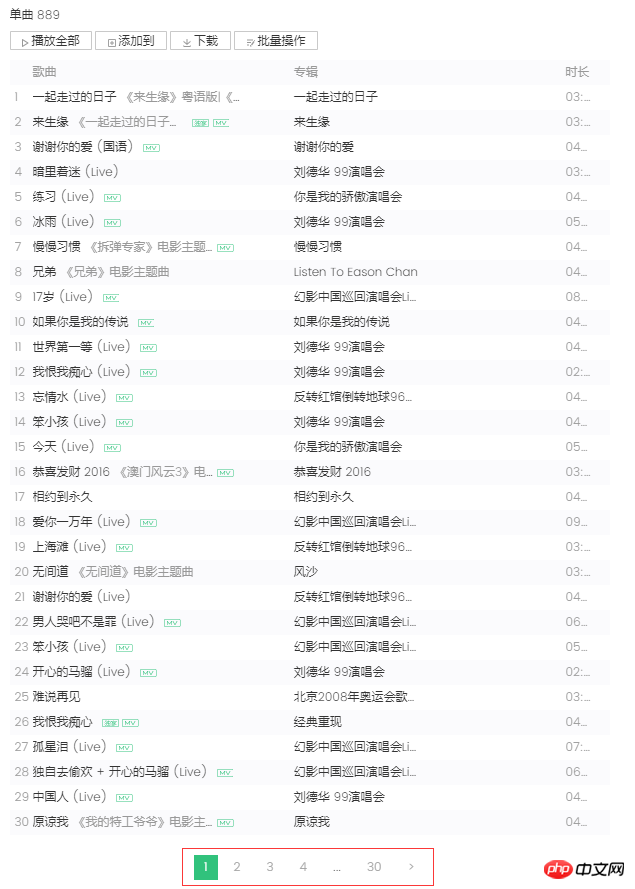
왼쪽 스크린샷을 보면 단일곡 정보가 페이징 방식으로 정리되어 있고, 각 페이지에 30개의 항목이 표시되어 총 30페이지에 걸쳐 표시되는 것을 볼 수 있습니다. 페이지 번호 또는 맨 오른쪽의 ">"를 클릭하면 브라우저가 서버에 비동기 Ajax 요청을 보냅니다. 각각 시작 노래 첨자(스크린샷은 두 번째 페이지, 시작 첨자는 30)와 한 페이지는 30개의 항목을 반환하며, 서버는 노래 정보를 json 형식(MusicJsonCallbacksinger_track({"code":0,"data": {"list":[{"Flisten_count1":.. .....]})), 노래 정보만 얻으려는 경우 링크 요청을 직접 연결하고 반환된 json 형식 데이터를 구문 분석할 수 있습니다. 여기서는 데이터 형식을 직접 구문 분석하는 방법을 사용하지 않습니다. 저는 Python Selenium 방법을 사용합니다. 단일 정보의 각 페이지를 가져와 구문 분석한 후 ">"를 클릭하여 모든 정보가 나올 때까지 구문 분석을 계속합니다. 단일 정보를 파싱하여 기록합니다. 마지막으로, 각 싱글의 링크를 요청하여 자세한 싱글 정보를 얻으세요.
오른쪽 스크린샷은 웹 페이지의 소스 코드입니다. 모든 노래 정보는 클래스 이름이 mod_songlist인 div 플로팅 레이어에 있습니다. 클래스 이름이 songlist_list인 순서가 지정되지 않은 목록 ul 아래에 있습니다. li 요소는 싱글을 표시합니다. songlist__album 클래스 이름 아래의 a 태그에는 싱글의 링크, 이름 및 기간이 포함됩니다.
3. 코드 작성
 1) 여기서는 Python의 Urllib 표준 라이브러리를 사용하고 다운로드 방법을 캡슐화합니다.
1) 여기서는 Python의 Urllib 표준 라이브러리를 사용하고 다운로드 방법을 캡슐화합니다. 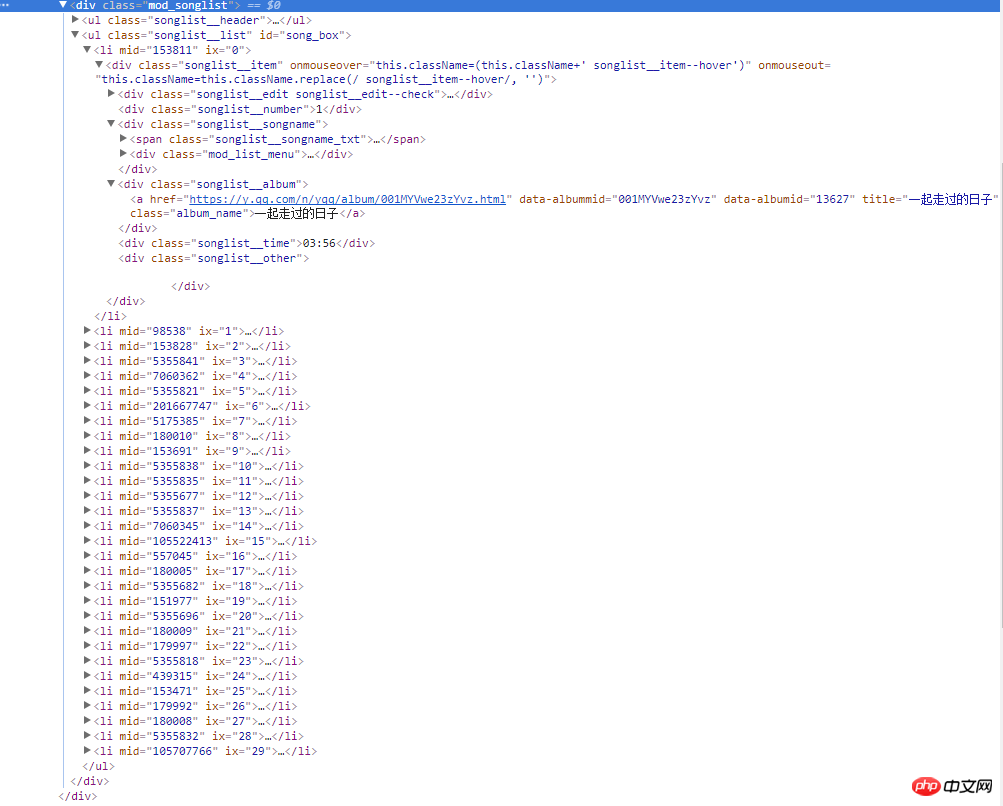
def download(url, user_agent='wswp', num_retries=2):
if url is None:
return None
print('Downloading:', url)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
request = urllib.request.Request(url, headers=headers) # 设置用户代理wswp(Web Scraping with Python)
try:
html = urllib.request.urlopen(request).read().decode('utf-8')
except urllib.error.URLError as e:
print('Downloading Error:', e.reason)
html = None
if num_retries > 0:
if hasattr(e, 'code') and 500 <= e.code < 600:
# retry when return code is 5xx HTTP erros
return download(url, num_retries-1) # 请求失败,默认重试2次,
return html2) Par 그래요 여기에서는 웹 페이지 콘텐츠, 타사 플러그인 BeautifulSoup이 사용됩니다. 자세한 내용은 BeautifulSoup API를 참조하세요. def music_scrapter(html, page_num=0):
try:
soup = BeautifulSoup(html, 'html.parser')
mod_songlist_div = soup.find_all('div', class_='mod_songlist')
songlist_ul = mod_songlist_div[1].find('ul', class_='songlist__list')
'''开始解析li歌曲信息'''
lis = songlist_ul.find_all('li')
for li in lis:
a = li.find('div', class_='songlist__album').find('a')
music_url = a['href'] # 单曲链接
urls.add_new_url(music_url) # 保存单曲链接
# print('music_url:{0} '.format(music_url))
print('total music link num:%s' % len(urls.new_urls))
next_page(page_num+1)
except TimeoutException as err:
print('解析网页出错:', err.args)
return next_page(page_num + 1)
return Nonedef get_music():
try:
while urls.has_new_url():
# print('urls count:%s' % len(urls.new_urls))
'''跳转到歌曲链接,获取歌曲详情'''
new_music_url = urls.get_new_url()
print('url leave count:%s' % str( len(urls.new_urls) - 1))
html_data_info = download(new_music_url)
# 下载网页失败,直接进入下一循环,避免程序中断
if html_data_info is None:
continue
soup_data_info = BeautifulSoup(html_data_info, 'html.parser')
if soup_data_info.find('div', class_='none_txt') is not None:
print(new_music_url, ' 对不起,由于版权原因,暂无法查看该专辑!')
continue
mod_songlist_div = soup_data_info.find('div', class_='mod_songlist')
songlist_ul = mod_songlist_div.find('ul', class_='songlist__list')
lis = songlist_ul.find_all('li')
del lis[0] # 删除第一个li
# print('len(lis):$s' % len(lis))
for li in lis:
a_songname_txt = li.find('div', class_='songlist__songname').find('span', class_='songlist__songname_txt').find('a')
if 'https' not in a_songname_txt['href']: #如果单曲链接不包含协议头,加上
song_url = 'https:' + a_songname_txt['href']
song_name = a_songname_txt['title']
singer_name = li.find('div', class_='songlist__artist').find('a').get_text()
song_time =li.find('div', class_='songlist__time').get_text()
music_info = {}
music_info['song_name'] = song_name
music_info['song_url'] = song_url
music_info['singer_name'] = singer_name
music_info['song_time'] = song_time
collect_data(music_info)
except Exception as err: # 如果解析异常,跳过
print('Downloading or parse music information error continue:', err.args)
<span style="font-size: 16px;">爬虫跑起来了,一页一页地去爬取专辑的链接,并保存到集合中,最后通过get_music()方法获取单曲的名称,链接,歌手名称和时长并保存到Excel文件中。</span><br><span style="font-size: 14px;"><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/001/a1138f33f00f8d95b52fbfe06e562d24-4.png" class="lazy" alt="" style="max-width:90%" style="max-width:90%"><strong><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/001/9282b5f7a1dc4a90cee186c16d036272-5.png" class="lazy" alt=""></strong></span>
<br>
3. Python 크롤링 QQ 음악 싱글 요약<br>
1. 싱글은 페이징을 사용하고, 다음 페이지로 전환하는 것은 비동기식 Ajax 요청을 통해 이루어집니다. 서버에서 json 형식의 데이터를 가져와 페이지에 렌더링합니다. 브라우저 주소 표시줄 링크는 변경되지 않으며 연결된 링크를 통해 요청할 수 없습니다. 처음에는 Python Urllib 라이브러리를 통해 ajax 요청을 시뮬레이션하려고 생각했지만 나중에 Selenium을 사용하려고 생각했습니다. Selenium은 브라우저의 실제 작동을 매우 잘 시뮬레이션할 수 있으며 페이지 요소의 위치 지정도 매우 편리합니다. 다음 페이지를 클릭하고 단일 페이지 매김을 지속적으로 전환한 다음 BeautifulSoup을 통해 웹 페이지 소스 코드를 구문 분석하여 단일 페이지를 얻는 것을 시뮬레이션합니다. 정보.
2.url 링크 관리자는 컬렉션 데이터 구조를 사용하여 단일 링크를 저장합니다. 동일한 앨범에서 여러 개의 싱글이 나올 수 있으므로(앨범 URL이 동일함) 이렇게 하면 요청 수가 줄어들 수 있습니다. class UrlManager(object):<br> def __init__(self):<br> self.new_urls = set() # 使用集合数据结构,过滤重复元素<br> self.old_urls = set() # 使用集合数据结构,过滤重复元素
로그인 후 복사
def add_new_url(self, url):<br> if url is None:<br> return<br> if url not in self.new_urls and url not in self.old_urls:<br> self.new_urls.add(url)<br><br> def add_new_urls(self, urls):<br> if urls is None or len(urls) == 0:<br> return<br> for url in urls:<br> self.add_new_url(url)<br><br> def has_new_url(self):<br> return len(self.new_urls) != 0<br><br> def get_new_url(self):<br> new_url = self.new_urls.pop()<br> self.old_urls.add(new_url)<br> return new_url<br><br>
로그인 후 복사
class UrlManager(object):<br> def __init__(self):<br> self.new_urls = set() # 使用集合数据结构,过滤重复元素<br> self.old_urls = set() # 使用集合数据结构,过滤重复元素
def add_new_url(self, url):<br> if url is None:<br> return<br> if url not in self.new_urls and url not in self.old_urls:<br> self.new_urls.add(url)<br><br> def add_new_urls(self, urls):<br> if urls is None or len(urls) == 0:<br> return<br> for url in urls:<br> self.add_new_url(url)<br><br> def has_new_url(self):<br> return len(self.new_urls) != 0<br><br> def get_new_url(self):<br> new_url = self.new_urls.pop()<br> self.old_urls.add(new_url)<br> return new_url<br><br>
3 Python 타사 플러그인
openpyxl을 통해 Excel을 읽고 쓰는 것이 매우 편리하며 단일 정보는 Excel 파일을 통해 잘 저장할 수 있습니다.
def write_to_excel(self, content):<br> try:<br> for row in content:<br> self.workSheet.append([row['song_name'], row['song_url'], row['singer_name'], row['song_time']])<br> self.workBook.save(self.excelName) # 保存单曲信息到Excel文件<br> except Exception as arr:<br> print('write to excel error', arr.args)<br><br>
드디어 축하해야 할 일이 있는데요, 결국 QQ뮤직 싱글 정보 크롤링에 성공했네요. 이번에는 싱글 크롤링에 성공했는데, Selenium은 꼭 필요했습니다. 이번에는 Selenium의 몇 가지 간단한 기능만 사용했습니다. 앞으로는 크롤러 측면뿐만 아니라 UI 자동화 측면에서도 Selenium에 대해 자세히 알아볼 예정입니다. 향후 최적화가 필요한 점: 1. 다운로드 링크가 많아 하나씩 다운로드가 느릴 예정입니다. 2. 서버가 IP를 비활성화하고 동일한 도메인 이름에 너무 자주 액세스하는 문제를 피하기 위해 다운로드 속도가 너무 빠릅니다. 각 요청 사이에 대기 간격이 있습니다. 3. 정규식을 구문 분석하는 것은 BeautifulSoup 및 lxml을 사용할 수 있지만 효율성 측면에서는 BeautifulSoup을 사용하려고 합니다. lxml 나중에.
위 내용은 Python으로 qq 음악을 크롤링하는 프로세스의 예의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7513
7513
 15
1378
52
79
11
53
19
19
64
15
1378
52
79
11
53
19
19
64

 2 시간의 파이썬 계획 : 현실적인 접근
Apr 11, 2025 am 12:04 AM
2 시간의 파이썬 계획 : 현실적인 접근
Apr 11, 2025 am 12:04 AM
2 시간 이내에 Python의 기본 프로그래밍 개념과 기술을 배울 수 있습니다. 1. 변수 및 데이터 유형을 배우기, 2. 마스터 제어 흐름 (조건부 명세서 및 루프), 3. 기능의 정의 및 사용을 이해하십시오. 4. 간단한 예제 및 코드 스 니펫을 통해 Python 프로그래밍을 신속하게 시작하십시오.
 파이썬 : 기본 응용 프로그램 탐색
Apr 10, 2025 am 09:41 AM
파이썬 : 기본 응용 프로그램 탐색
Apr 10, 2025 am 09:41 AM
Python은 웹 개발, 데이터 과학, 기계 학습, 자동화 및 스크립팅 분야에서 널리 사용됩니다. 1) 웹 개발에서 Django 및 Flask 프레임 워크는 개발 프로세스를 단순화합니다. 2) 데이터 과학 및 기계 학습 분야에서 Numpy, Pandas, Scikit-Learn 및 Tensorflow 라이브러리는 강력한 지원을 제공합니다. 3) 자동화 및 스크립팅 측면에서 Python은 자동화 된 테스트 및 시스템 관리와 같은 작업에 적합합니다.
 MongoDB 데이터베이스 비밀번호를 보는 Navicat의 방법
Apr 08, 2025 pm 09:39 PM
MongoDB 데이터베이스 비밀번호를 보는 Navicat의 방법
Apr 08, 2025 pm 09:39 PM
해시 값으로 저장되기 때문에 MongoDB 비밀번호를 Navicat을 통해 직접 보는 것은 불가능합니다. 분실 된 비밀번호 검색 방법 : 1. 비밀번호 재설정; 2. 구성 파일 확인 (해시 값이 포함될 수 있음); 3. 코드를 점검하십시오 (암호 하드 코드 메일).
 Amazon Athena와 함께 AWS Glue Crawler를 사용하는 방법
Apr 09, 2025 pm 03:09 PM
Amazon Athena와 함께 AWS Glue Crawler를 사용하는 방법
Apr 09, 2025 pm 03:09 PM
데이터 전문가는 다양한 소스에서 많은 양의 데이터를 처리해야합니다. 이것은 데이터 관리 및 분석에 어려움을 겪을 수 있습니다. 다행히도 AWS Glue와 Amazon Athena의 두 가지 AWS 서비스가 도움이 될 수 있습니다.
 Redis 대기열을 읽는 방법
Apr 10, 2025 pm 10:12 PM
Redis 대기열을 읽는 방법
Apr 10, 2025 pm 10:12 PM
Redis의 대기열을 읽으려면 대기열 이름을 얻고 LPOP 명령을 사용하여 요소를 읽고 빈 큐를 처리해야합니다. 특정 단계는 다음과 같습니다. 대기열 이름 가져 오기 : "큐 :"와 같은 "대기열 : my-queue"의 접두사로 이름을 지정하십시오. LPOP 명령을 사용하십시오. 빈 대기열 처리 : 대기열이 비어 있으면 LPOP이 NIL을 반환하고 요소를 읽기 전에 대기열이 존재하는지 확인할 수 있습니다.
 Redis의 서버 버전을 보는 방법
Apr 10, 2025 pm 01:27 PM
Redis의 서버 버전을 보는 방법
Apr 10, 2025 pm 01:27 PM
질문 : Redis 서버 버전을 보는 방법은 무엇입니까? 명령 줄 도구 Redis-Cli를 사용하여 연결된 서버의 버전을보십시오. 정보 서버 명령을 사용하여 서버의 내부 버전을보고 정보를 구문 분석하고 반환해야합니다. 클러스터 환경에서 각 노드의 버전 일관성을 확인하고 스크립트를 사용하여 자동으로 확인할 수 있습니다. 스크립트를 사용하여 Python 스크립트와 연결 및 인쇄 버전 정보와 같은보기 버전을 자동화하십시오.
 Redis로 서버를 시작하는 방법
Apr 10, 2025 pm 08:12 PM
Redis로 서버를 시작하는 방법
Apr 10, 2025 pm 08:12 PM
Redis 서버를 시작하는 단계에는 다음이 포함됩니다. 운영 체제에 따라 Redis 설치. Redis-Server (Linux/MacOS) 또는 Redis-Server.exe (Windows)를 통해 Redis 서비스를 시작하십시오. Redis-Cli Ping (Linux/MacOS) 또는 Redis-Cli.exe Ping (Windows) 명령을 사용하여 서비스 상태를 확인하십시오. Redis-Cli, Python 또는 Node.js와 같은 Redis 클라이언트를 사용하여 서버에 액세스하십시오.
 Navicat의 비밀번호는 얼마나 안전합니까?
Apr 08, 2025 pm 09:24 PM
Navicat의 비밀번호는 얼마나 안전합니까?
Apr 08, 2025 pm 09:24 PM
Navicat의 비밀번호 보안은 대칭 암호화, 암호 강도 및 보안 측정의 조합에 의존합니다. 특정 측정에는 다음이 포함됩니다. SSL 연결 사용 (데이터베이스 서버가 인증서를 지원하고 올바르게 구성하는 경우), 정기적으로 Navicat을 업데이트하고보다 안전한 방법 (예 : SSH 터널), 액세스 권한 제한 및 가장 중요한 것은 암호를 기록하지 않습니다.
