
문서, 문서 수업. Pylucene에서 색인 생성의 기본 단위는 "문서"입니다. 문서는 웹페이지, 기사 또는 이메일일 수 있습니다. 문서는 인덱스를 구성하는 단위이자 검색 결과의 단위이기도 합니다. 이를 적절히 설계하면 개인화된 검색 서비스를 제공할 수 있습니다.
파일링, 도메인 클래스입니다. 문서에는 여러 필드(필드)가 포함될 수 있습니다. 기사가 기사 제목, 기사 본문, 저자, 출판 날짜 등과 같은 여러 파일로 구성될 수 있는 것처럼 Filed는 문서의 구성 요소입니다.
페이지를 문서로 처리합니다. 여기에는 페이지의 URL 주소(url), 페이지 제목(title), 페이지의 기본 텍스트 내용(content)이라는 세 가지 필드가 포함됩니다. 인덱스 저장 방법으로 SimpleFSDirectory 클래스를 사용하고 인덱스를 파일에 저장하도록 선택합니다. 분석기는 Pylucene과 함께 제공되는 CJKAnalyzer를 선택합니다. 이 분석기는 중국어를 잘 지원하며 중국어 콘텐츠의 텍스트 처리에 적합합니다.
검색 엔진이란 무엇인가요?
검색 엔진은 "네트워크 정보 자원을 수집 및 정리하고 정보 수집, 정보 정렬 및 사용자 쿼리의 세 부분으로 구성된 정보 쿼리 서비스를 제공하는 시스템"입니다. 그림 1은 검색 엔진의 일반적인 구조입니다. 정보 수집 모듈은 일반적으로 크롤러를 사용하여 인터넷에서 정보를 수집한 다음 정보 정렬 모듈에서 단어 분할, 중지 단어 제거, 가중치 부여 및 기타 작업을 수행합니다. 수집된 정보. 인덱스 테이블(보통 반전 인덱스)을 구축하여 인덱스 데이터베이스를 형성합니다. 최종적으로 사용자 쿼리 모듈은 사용자의 검색 요구 사항을 식별하고 검색 서비스를 제공할 수 있습니다.
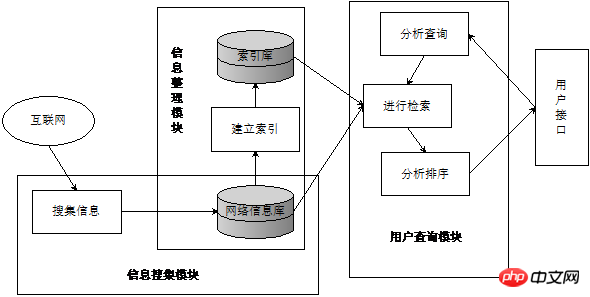
그림 1 검색 엔진의 일반적인 구조
2. Python을 사용하여 간단한 검색 엔진 구현
2.1 문제 분석
그림 1에서 전체 검색 엔진 아키텍처는 인터넷. Python의 장점인 크롤러를 작성하려면 Python을 사용하세요.
다음은 정보처리 모듈입니다. 분사? 말을 멈추시겠습니까? 거꾸로 된 테이블? 무엇? 이 혼란은 무엇입니까? 걱정하지 마십시오. 우리는 전임자가 만든 바퀴를 가지고 있습니다.---Pylucene(lucene의 Python 패키지 버전입니다. Lucene은 개발자가 소프트웨어 및 시스템에 검색 기능을 추가하는 데 도움을 줄 수 있습니다. Lucene은 전체 기능을 위한 오픈 소스 라이브러리 세트입니다. 텍스트 검색 및 검색). Pylucene을 사용하면 색인 생성 및 검색을 포함하여 수집된 정보를 처리하는 데 도움이 될 수 있습니다.
마지막으로 웹 페이지에서 검색 엔진을 사용하기 위해 경량 웹 애플리케이션 프레임워크인 플라스크를 사용하여 작은 웹 페이지를 만들어 검색문과 피드백 검색 결과를 얻습니다.
2.2 크롤러 디자인
주로 대상 웹페이지의 제목, 대상 웹페이지의 본문 내용, 대상 웹페이지가 가리키는 다른 페이지의 URL 주소 등의 내용을 수집합니다. 웹 크롤러의 작업 흐름은 그림 2에 나와 있습니다. 크롤러의 주요 데이터 구조는 대기열입니다. 먼저 초기 시드 노드가 대기열에 들어간 다음 대기열에서 노드를 꺼내 액세스하고 노드 페이지에서 대상 정보를 가져온 다음 다른 페이지를 가리키는 노드 페이지의 URL 링크를 대기열에 넣은 다음 가져옵니다. 대기열에서 새 노드를 꺼내면 대기열이 빌 때까지 노드에 액세스됩니다. 대기열의 "선입선출" 기능을 통해 너비 우선 순회 알고리즘이 구현되어 사이트의 각 페이지에 하나씩 액세스합니다. ㅋㅋ |
Directory는 파일 작업을 위한 Pylucene의 클래스입니다. SimpleFSDirectory, RAMDirectory, FileSwitchDirectory와 같은 11개의 하위 클래스가 있습니다. 나열된 4개는 인덱스 디렉터리 저장과 관련된 하위 클래스입니다. SimpleFSDirectory는 인덱스를 RAM 메모리에 저장합니다. 복합 인덱스 저장 방법과 FileSwitchDirectory를 사용하면 인덱스 저장 방법을 임시로 전환하여 다양한 인덱스 저장 방법을 활용할 수 있습니다. 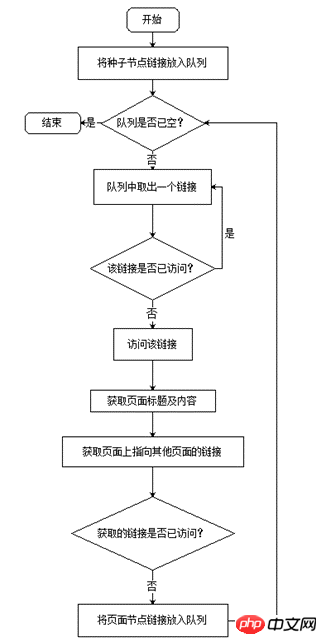
문서, 문서 수업. Pylucene에서 색인 생성의 기본 단위는 "문서"입니다. 문서는 웹페이지, 기사 또는 이메일일 수 있습니다. 문서는 인덱스를 구성하는 단위이자 검색 결과의 단위이기도 합니다. 이를 적절히 설계하면 개인화된 검색 서비스를 제공할 수 있습니다.
파일링, 도메인 클래스입니다. 문서에는 여러 필드(필드)가 포함될 수 있습니다. 기사가 기사 제목, 기사 본문, 저자, 출판 날짜 등과 같은 여러 파일로 구성될 수 있는 것처럼 Filed는 문서의 구성 요소입니다.
페이지의 URL 주소(url), 페이지 제목(title), 페이지의 기본 텍스트 내용(content)의 세 가지 필드가 포함된 문서로 페이지를 처리합니다. 인덱스 저장 방법으로 SimpleFSDirectory 클래스를 사용하고 인덱스를 파일에 저장하도록 선택합니다. 분석기는 Pylucene과 함께 제공되는 CJKAnalyzer를 선택합니다. 이 분석기는 중국어를 잘 지원하며 중국어 콘텐츠의 텍스트 처리에 적합합니다.
Pylucene을 사용하여 인덱스를 구축하는 구체적인 단계는 다음과 같습니다:
lucene.initVM()
INDEXIDR = self.__index_dir
indexdir = SimpleFSDirectory(File(INDEXIDR))①
analyzer = CJKAnalyzer(Version.LUCENE_30)②
index_writer = IndexWriter(indexdir, analyzer, True, IndexWriter.MaxFieldLength(512))③
document = Document()④
document.add(Field("content", str(page_info["content"]), Field.Store.NOT, Field.Index.ANALYZED))⑤
document.add(Field("url", visiting, Field.Store.YES, Field.Index.NOT_ANALYZED))⑥
document.add(Field("title", str(page_info["title"]), Field.Store.YES, Field.Index.ANALYZED))⑦
index_writer.addDocument(document)⑧
index_writer.optimize()⑨
index_writer.close()⑩
인덱스를 구축하는 10가지 주요 단계는 다음과 같습니다.
①SimpleFSDirectory 객체를 인스턴스화하고 인덱스를 로컬 파일에 저장한 후 경로 사용자 정의된 경로 "INDEXIDR"의 경우.
② CJKAnalyzer 분석기를 인스턴스화합니다. 인스턴스화 중 매개변수 Version.LUCENE_30은 Pylucene의 버전 번호입니다.
3 IndexWriter 개체를 인스턴스화합니다. 전달되는 4개의 매개 변수는 이전에 인스턴스화된 SimpleFSDirectory 개체와 CJKAnalyzer 분석기입니다. IndexWriter.MaxFieldLength는 가장 큰 인덱스 수(Filed)를 갖는 인덱스를 지정합니다. .
4Document 개체를 인스턴스화하고 이름을 document로 지정합니다.
⑤문서에 "content"라는 도메인을 추가합니다. 이 필드의 내용은 크롤러가 얻은 웹페이지의 주요 텍스트 내용입니다. 이 작업의 매개변수는 인스턴스화되어 즉시 사용되는 Field 개체입니다. Field 개체의 네 가지 매개변수는 다음과 같습니다.
(1) "content", 도메인 이름.
(2) page_info["content"], 크롤러가 수집한 웹페이지의 주요 텍스트 내용입니다.
(3) Field.Store는 이 필드의 값을 원래 문자로 복원할 수 있는지 여부를 나타내는 데 사용되는 변수입니다. Field.Store.YES는 이 필드에 저장된 내용을 원본 텍스트 콘텐츠로 복원할 수 있음을 의미합니다. Field.Store.NOT은 복구할 수 없음을 의미합니다.
(4) Field.Index 변수는 필드의 내용이 분석기에서 처리되어야 하는지 여부를 나타냅니다. Index.ANALYZED는 분석기가 이 필드의 문자를 처리하는 데 사용됨을 나타냅니다. 이 필드의 문자를 처리하는 데 사용되지 않습니다.
⑥페이지 주소를 저장하려면 "url"이라는 도메인을 추가하세요.
7페이지 제목을 저장하려면 "제목"이라는 필드를 추가하세요.
⑧문서 문서를 인덱스 파일에 쓰려면 IndexWriter 개체를 인스턴스화합니다.
9 인덱스 라이브러리 파일을 최적화하고 인덱스 라이브러리에 있는 작은 파일을 큰 파일로 병합합니다.
⑩한 번의 주기로 인덱스 구축 작업이 완료된 후 IndexWriter 개체를 닫습니다.
Pylucene의 색인 검색을 위한 주요 클래스로는 IndexSearcher, Query 및 QueryParser[16]가 있습니다.
IndexSearcher, 인덱스 검색 클래스입니다. IndexWriter가 구축한 인덱스 라이브러리에서 검색 작업을 수행하는 데 사용됩니다.
Query, 쿼리 요청을 설명하는 클래스입니다. 검색 작업을 완료하기 위해 IndexSearcher에 쿼리 요청을 제출합니다. 쿼리에는 다양한 쿼리 요청을 완료하기 위한 많은 하위 클래스가 있습니다. 예를 들어, 가장 기본적이고 간단한 쿼리 유형으로 특정 도메인의 특정 항목과 문서를 일치시키는 데 사용되는 용어별 검색인 TermQuery와 지정된 범위 내의 문서를 일치시키는 데 사용되는 RangeQuery가 있습니다. 퍼지 쿼리인 FuzzyQuery는 쿼리 키워드와 의미상 유사한 동의어 일치를 간단히 식별할 수 있습니다.
QueryParser, 쿼리 파서. 다양한 쿼리 요구 사항을 구현해야 하는 경우 Query에서 제공하는 다양한 하위 클래스를 사용해야 합니다. 이는 Query를 사용할 때 혼동을 일으키기 쉽습니다. 따라서 Pylucene은 쿼리 파서인 QueryParser도 제공합니다. QueryParser는 제출된 Query 문을 구문 분석하고 Query 구문에 따라 적절한 Query 하위 클래스를 선택하여 해당 쿼리를 완료할 수 있습니다. 개발자는 하단에 어떤 Query 구현 클래스가 사용되는지 신경 쓸 필요가 없습니다. 예를 들어, 쿼리 문 "키워드 1 및 키워드 2" QueryParser는 키워드 1과 키워드 2 모두와 일치하는 쿼리 문서로 구문 분석합니다. QueryParser는 이름이 "id"인 도메인을 쿼리하기 위해 구문 분석합니다. 값이 지정된 범위 "123"에서 "456" 내에 있는 문서; 쿼리 문 "keyword site:www.web.com" QueryParser는 "site"라는 도메인에서 "www.web" 값도 충족하는 쿼리로 구문 분석합니다. ".com" 및 "키워드"의 두 가지 쿼리 조건과 일치하는 문서입니다.
인덱스 검색은 Pylucene이 중점을 두고 있는 영역 중 하나입니다. 인덱스 검색을 구현하기 위해 쿼리라는 클래스가 작성되었습니다. 쿼리는 인덱스 검색을 구현하는 주요 단계가 있습니다.
lucene.initVM()
if query_str.find(":") ==-1 and query_str.find(":") ==-1:
query_str="title:"+query_str+" OR content:"+query_str①
indir= SimpleFSDirectory(File(self.__indexDir))②
lucene_analyzer= CJKAnalyzer(Version.LUCENE_CURRENT)③
lucene_searcher= IndexSearcher(indir)④
my_query = QueryParser(Version.LUCENE_CURRENT,"title",lucene_analyzer).parse(query_str)⑤
total_hits = lucene_searcher.search(my_query, MAX)⑥
for hit in total_hits.scoreDocs:⑦
print"Hit Score: ", hit.score
doc = lucene_searcher.doc(hit.doc)
result_urls.append(doc.get("url").encode("utf-8"))
result_titles.append(doc.get("title").encode("utf-8"))
print doc.get("title").encode("utf-8")
result = {"Hits": total_hits.totalHits, "url":tuple(result_urls), "title":tuple(result_titles)}
return result
인덱스 검색에는 7가지 주요 단계가 있습니다. :
① 먼저 검색문을 판단합니다. 해당 문이 제목이나 기사 내용에 대한 단일 도메인 쿼리가 아닌 경우, 즉 키워드 "title:" 또는 "content:"가 포함되어 있지 않은 경우 두 도메인입니다. 제목과 내용이 기본적으로 검색됩니다.
②SimpleFSDirectory 개체를 인스턴스화하고 작업 경로를 이전에 인덱스가 생성된 경로로 지정합니다.
③实例化一个CJKAnalyzer分析器,搜索时使用的分析器应与索引构建时使用的分析器在类型版本上均一致。
④实例化一个IndexSearcher对象lucene_searcher,它的参数为第○2步的SimpleFSDirectory对象。
⑤实例化一个QueryParser对象my_query,它描述查询请求,解析Query查询语句。参数Version.LUCENE_CURRENT为pylucene的版本号,“title”指默认的搜索域,lucene_analyzer指定了使用的分析器,query_str是Query查询语句。在实例化QueryParser前会对用户搜索请求作简单处理,若用户指定了搜索某个域就搜索该域,若用户未指定则同时搜索“title”和“content”两个域。
⑥lucene_searcher进行搜索操作,返回结果集total_hits。total_hits中包含结果总数totalHits,搜索结果的文档集scoreDocs,scoreDocs中包括搜索出的文档以及每篇文档与搜索语句相关度的得分。
⑦lucene_searcher搜索出的结果集不能直接被Python处理,因而在搜索操作返回结果之前应将结果由Pylucene转为普通的Python数据结构。使用For循环依次处理每个结果,将结果文档按相关度得分高低依次将它们的地址域“url”的值放入Python列表result_urls,将标题域“title”的值放入列表result_titles。最后将包含地址、标题的列表和结果总数组合成一个Python“字典”,将最后处理的结果作为整个搜索操作的返回值。
用户在浏览器搜索框输入搜索词并点击搜索,浏览器发起一个GET请求,Flask的路由route设置了由result函数响应该请求。result函数先实例化一个搜索类query的对象infoso,将搜索词传递给该对象,infoso完成搜索将结果返回给函数result。函数result将搜索出来的页面和结果总数等传递给模板result.html,模板result.html用于呈现结果
如下是Python使用flask模块处理搜索请求的代码:
app = Flask(__name__)#创建Flask实例
@app.route('/')#设置搜索默认主页
def index():
html="<h1>title这是标题</h1>"
return render_template('index.html')
@app.route("/result",methods=['GET', 'POST'])#注册路由,并指定HTTP方法为GET、POST
def result(): #resul函数
if request.method=="GET":#响应GET请求
key_word=request.args.get('word')#获取搜索语句
if len(key_word)!=0:
infoso = query("./glxy") #创建查询类query的实例
re = infoso.search(key_word)#进行搜索,返回结果集
so_result=[]
n=0
for item in re["url"]:
temp_result={"url":item,"title":re["title"][n]}#将结果集传递给模板
so_result.append(temp_result)
n=n+1
return render_template('result.html', key_word=key_word, result_sum=re["Hits"],result=so_result)
else:
key_word=""
return render_template('result.html')
if __name__ == '__main__':
app.debug = True
app.run()#运行web服务위 내용은 검색 엔진(Pylucene)의 Python 구현 예제 튜토리얼의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



