

이 Linux 튜토리얼에서는 Heka 구성에 대해 설명합니다.
Heka, ElasticSearch 및 Kibana를 기반으로 하는 분산 백엔드 로그 아키텍처
현재 주류 백엔드 로그는 표준 elk 모드(Elasticsearch, Logstash)를 사용합니다. , Kinaba)는 각각 로그 저장, 수집 및 로그 시각화를 담당합니다.
그러나 우리의 로그 파일은 다양하고 서로 다른 서버에 분산되어 있기 때문에 향후 2차 개발 및 사용자 정의를 용이하게 하기 위해 다양한 로그가 사용됩니다. 그래서 Mozilla는 golang 오픈소스를 사용하여 구현하고 Logstash를 모방한 Heka를 채택했습니다.
현재 주류 백엔드 로그는 각각 로그 저장, 수집 및 로그 시각화를 담당하는 표준 elk 모드(Elasticsearch, Logstash, Kinaba)를 채택합니다.
그러나 우리의 로그 파일은 다양하고 서로 다른 서버에 분산되어 있기 때문에 향후 2차 개발 및 사용자 정의를 용이하게 하기 위해 다양한 로그가 사용됩니다. 그래서 Mozilla는 golang 오픈소스를 사용하여 구현하고 Logstash를 모방한 Heka를 채택했습니다.
Heka, ElasticSearch, Kibana를 사용한 후의 전체 아키텍처는 아래 그림과 같습니다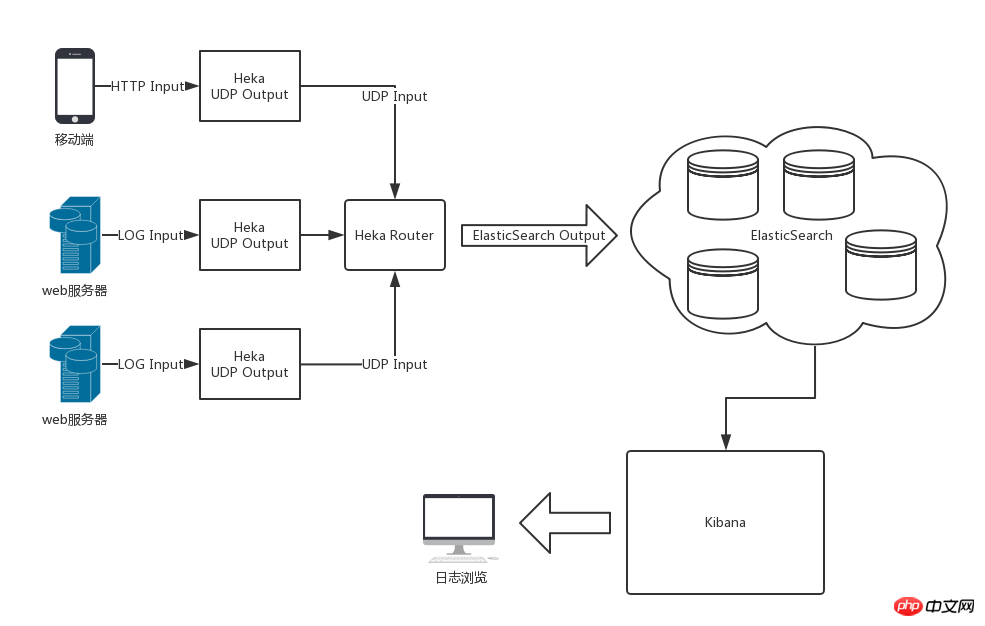
Heka의 로그 처리 흐름은 입력, 세분화, 디코딩, 필터링, 인코딩 및 출력입니다. . 단일 Heka 서비스 내의 데이터 흐름은 Heka에서 정의한 메시지 데이터 모델을 통해 각 모듈 내에서 흐릅니다.
heka에는
입력 플러그인과 같이 가장 일반적으로 사용되는 모듈 플러그인이 내장되어 있습니다. Logstreamer 입력은 로그 파일을 입력 소스로 사용할 수 있으며,
디코딩 플러그인 Nginx Access Log Decoder는 디코딩할 수 있습니다. nginx 액세스는 표준 키에 기록됩니다. 값 쌍 데이터는 처리를 위해 후속 모듈 플러그인으로 전달됩니다.
입력 및 출력의 유연한 구성 덕분에 Heka가 여러 곳에서 수집한 로그 데이터를 처리하여 로그 센터의 Heka로 출력하여 통합 인코딩한 후 ElasticSearch에 전달하여 저장할 수 있습니다.
위 내용은 Heka 구성에 대한 자세한 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



