

오늘날 데이터베이스 작업은 전체 애플리케이션, 특히 웹 애플리케이션의 성능 병목 현상을 점점 더 많이 발생시키고 있습니다. 데이터베이스의 성능과 관련하여 이는 DBA가 걱정해야 할 사항일 뿐만 아니라 우리 프로그래머가 주의해야 할 사항이기도 합니다
오늘날 데이터베이스 작업은 점점 더 전체 애플리케이션의 성능 병목 현상이 되고 있습니다. 웹에서는 매우 중요합니다. 애플리케이션은 특히 분명합니다. 데이터베이스의 성능에 관해서는 이는 DBA만이 고민해야 할 부분이 아니라, 우리 프로그래머들이 주목해야 할 부분입니다. 데이터베이스 테이블 구조를 설계하고 데이터베이스를 운영할 때(특히 테이블 조회 시 SQL 문) 우리 모두는 데이터 작업의 성능에 주의를 기울여야 합니다. 여기서는 SQL 문의 최적화에 대해 너무 많이 이야기하지 않고 가장 많은 웹 애플리케이션이 있는 데이터베이스인 MySQL에만 중점을 둘 것입니다. Mysql의
성능 최적화는 하루아침에 달성할 수 없습니다. 단계별로 수행하고 모든 측면에서 최적화해야 최종 성능이 크게 향상됩니다. ㆍ 4가지 유형: 일반 인덱스, 기본 키 인덱스, 고유 인덱스, 전체 텍스트 인덱스]
•테이블 분할 기술(가로 분할, 수직 분할)
•읽고 쓰기[쓰기: 업데이트/삭제/추가] 분리 •저장 프로시저 [모듈식 프로그래밍, 속도 증가 가능]
•mysql 구성 최적화 [최대 동시성 my.ini 수 구성, 캐시 크기 조정]
•Mysql 서버 하드웨어 업그레이드
• Timed 불필요한 데이터 삭제 및 정기적인 조각 모음 수행(MyISAM)
또한 적절한 저장 프로시저를 사용하면 성능도 향상될 수 있습니다.
이 순서는 이 네 가지 작업이 성능에 미치는 영향도 보여줍니다.
데이터베이스 테이블 디자인
관계형 데이터베이스
인 한 모두 1NF를 충족함)
두 번째 정규형: 2NF는 고유성입니다. 레코드 제약 조건에는 레코드에 고유 식별자, 즉 엔터티의 고유성이 있어야 합니다.
세 번째 정규형: 3NF는 필드 중복에 대한 제약으로, 필드에 중복이 없어야 합니다. 중복된 데이터베이스 디자인은 이를 수행할 수 없습니다.
그러나 중복성이 없는 데이터베이스는 최고의 데이터베이스가 아닐 수도 있습니다. 때로는 운영 효율성을 높이기 위해 패러다임 표준을 낮추고 중복된 데이터를 적절하게 보관해야 할 수도 있습니다. 구체적인 접근 방식은 개념적 데이터 모델을 설계할 때 세 번째 패러다임을 준수하고, 물리적 데이터 모델을 설계할 때 패러다임 표준을 낮추는 작업을 고려하는 것입니다. 정규형을 낮추는 것은 필드를 추가하고 중복성을 허용하는 것을 의미합니다.
☞ 데이터베이스 분류
관계형 데이터베이스: mysql/oracle/db2/informix/sysbase/sql server
비관계형 데이터베이스: (기능: 객체 지향또는 컬렉션)
NoSql 데이터베이스: MongoDB (특성적으로 문서 중심)
중간 중복성 또는 이유가 있는 중복성이 무엇인지 예를 들어보세요!
위는 부적절한 중복성이며, 그 이유는 다음과 같습니다.
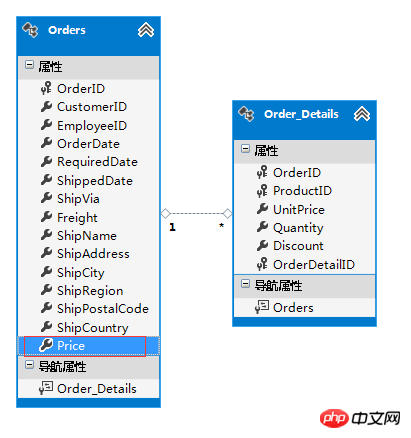
주문 세부 정보 테이블에서 이 주문의 가격을 계산할 수 있으므로 주문 테이블의 가격은 중복 필드이지만 이러한 중복은 합리적이며 쿼리 성능도 향상시킬 수 있습니다.
위의 두 가지 예에서 결론을 내릴 수 있습니다.
1---n 중복은 1측에서 발생해야 합니다.
SQL 문 최적화
일반 SQL 최적화 단계
1. 다양한 SQL의 실행 빈도를 이해하려면 show status 명령을 사용하세요.
2. 실행 효율성이 낮은 SQL 문을 찾아냅니다. - (선택 강조)
3. 설명을 통해 비효율적인 SQL을 분석합니다.
4. 문제를 식별하고 그에 맞는 최적화 조치를 취합니다.
-- select语句分类 Select Dml数据操作语言(insert update delete) dtl 数据事物语言(commit rollback savepoint) Ddl数据定义语言(create alter drop..) Dcl(数据控制语言) grant revoke -- Show status 常用命令 --查询本次会话 Show session status like 'com_%'; //show session status like 'Com_select' --查询全局 Show global status like 'com_%'; -- 给某个用户授权 grant all privileges on *.* to 'abc'@'%'; --为什么这样授权 'abc'表示用户名 '@' 表示host, 查看一下mysql->user表就知道了 --回收权限 revoke all on *.* from 'abc'@'%'; --刷新权限[也可以不写] flush privileges;
SQL 문을 최적화합니다. -show 매개변수
MySQL 클라이언트 연결에 성공한 후 show [session|global] status 명령을 사용하여 서버 상태 정보를 제공할 수 있습니다. 세션은 현재 연결의 통계 결과를 나타내고, 전역은 데이터베이스가 마지막으로 시작된 이후의 통계 결과를 나타냅니다. 기본값은 세션 수준입니다.
다음 예:
show status like 'Com_%';
여기서 Com_XXX는 XXX 문이 실행된 횟수를 나타냅니다.
주요 사항: Com_select, Com_insert, Com_update, Com_delete 이러한 매개변수를 통해 현재 데이터베이스 응용 프로그램이 주로 삽입 및 업데이트 또는 쿼리 작업을 기반으로 하는지와 다양한 유형의 SQL에 대한 대략적인 실행 비율을 쉽게 이해할 수 있습니다. . 얼마입니까?
사용자가 데이터베이스의 기본 상황을 이해하는 데 도움이 되도록 일반적으로 사용되는 여러 매개변수도 있습니다.
Connections: MySQL 서버에 연결을 시도한 횟수
Uptime: 서버가 작동하는 시간(초)
Slow_queries: 느린 쿼리 수(기본값은 느린 쿼리 시간 10초)
show status like 'Connections' show status like 'Uptime' show status like 'Slow_queries'
mysql 시간의 느린 쿼리를 쿼리하는 방법
Show variables like 'long_query_time';
mysql 느린 쿼리 시간 수정
set long_query_time=2
SQL 문 최적화-느린 쿼리 찾기
문제는 대규모 프로젝트에서 느린 실행 문을 빠르게 찾는 방법입니다. (느린 쿼리 찾기)
먼저 mysql 데이터베이스의 일부 실행 상태를 쿼리하는 방법을 이해합니다(예: mysql의 현재 실행 시간/총 실행 횟수를 알고 싶은 경우
선택/업데이트/삭제../현재 연결)
테스트를 용이하게 하기 위해 대규모 테이블(400만개)을 구축합니다.-> 저장 프로시저 사용Build
기본적으로 mysql은 느린 쿼리가 되도록 하세요.
mysql의 느린 쿼리를 수정하세요.
show variables like 'long_query_time' ; //可以显示当前慢查询时间 set long_query_time=1 ;//可以修改慢查询时间
큰 테이블 구축->큰 테이블의 레코드에 대한 요구 사항이 있습니다. 레코드는 서로 다를 경우에만 유용합니다. 그렇지 않으면 테스트 효과가 매우 달라집니다. 실제 생성:
CREATE TABLE dept( /*部门表*/ deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/ dname VARCHAR(20) NOT NULL DEFAULT "", /*名称*/ loc VARCHAR(13) NOT NULL DEFAULT "" /*地点*/ ) ENGINE=MyISAM DEFAULT CHARSET=utf8 ; CREATE TABLE emp (empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/ ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/ job VARCHAR(9) NOT NULL DEFAULT "",/*工作*/ mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*上级编号*/ hiredate DATE NOT NULL,/*入职时间*/ sal DECIMAL(7,2) NOT NULL,/*薪水*/ comm DECIMAL(7,2) NOT NULL,/*红利*/ deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部门编号*/ )ENGINE=MyISAM DEFAULT CHARSET=utf8 ; CREATE TABLE salgrade ( grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, losal DECIMAL(17,2) NOT NULL, hisal DECIMAL(17,2) NOT NULL )ENGINE=MyISAM DEFAULT CHARSET=utf8;
Test data
INSERT INTO salgrade VALUES (1,700,1200); INSERT INTO salgrade VALUES (2,1201,1400); INSERT INTO salgrade VALUES (3,1401,2000); INSERT INTO salgrade VALUES (4,2001,3000); INSERT INTO salgrade VALUES (5,3001,9999);
저장 프로시저를 정상적으로 실행하려면 명령 실행 종료 문자 수정 구분 기호 $$
임의를 반환하는 함수를 생성해야 합니다. 지정된 길이의 문자열
create function rand_string(n INT) returns varchar(255) #该函数会返回一个字符串 begin #chars_str定义一个变量 chars_str,类型是 varchar(100),默认值'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; declare return_str varchar(255) default ''; declare i int default 0; while i < n do set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1)); set i = i + 1; end while; return return_str; end
저장 프로시저 생성
create procedure insert_emp(in start int(10),in max_num int(10)) begin declare i int default 0; #set autocommit =0 把autocommit设置成0 set autocommit = 0; repeat set i = i + 1; insert into emp values ((start+i) ,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand()); until i = max_num end repeat; commit; end #调用刚刚写好的函数, 1800000条记录,从100001号开始 call insert_emp(100001,4000000);
이때, 문 실행 시간이 1초를 초과하면 카운트됩니다.
느린 쿼리 SQL을 우리 로그 중 하나에 기록하면
기본적으로 낮은 버전의 mysql에서는 느린 쿼리를 기록하지 않습니다. mysql
binmysqld.exe - -safe-mode - -slow-query-log [mysql5.5를 지정할 수 있습니다. in my.ini]
binmysqld.exe –log-slow-queries=d:/abc.log [하위 버전 mysql5.0은 my.ini에 지정 가능]
느린 쿼리 로그는 다음 위치에 저장됩니다. 데이터 디렉터리 [mysql5.0 버전에서는 mysql 설치 디렉터리 /data/에 위치함], mysql5.5.19 아래에서는 이를 확인해야 합니다
my .ini의 datadir="C:/Documents and Settings/All Users/Application Data/MySQL/MySQL Server 5.5/Data/"를 결정합니다.
mysql5.6에서 기본값은 기록 느린 쿼리를 시작하는 것입니다. ini가 있는 디렉터리는 C:ProgramDataMySQLMySQL Server 5.6, 구성 항목이 있습니다
slow-query-log=1
mysql5.5
binmysqld.exe - -safe -mode - -slow-query-log
my.ini 파일에서도 구성할 수 있습니다.
[mysqld] # The TCP/IP Port the MySQL Server will listen on port=3306 slow-query-log
느린 쿼리 로그를 통해 실행 효율성이 낮은 SQL 문을 찾습니다. 느린 쿼리 로그에는 실행 시간이 long_query_time 설정을 초과하는 모든 SQL 문이 기록됩니다.
show variables like 'long_query_time'; set long_query_time=2;
dept 테이블에 데이터 추가
desc dept; ALTER table dept add id int PRIMARY key auto_increment; CREATE PRIMARY KEY on dept(id); create INDEX idx_dptno_dptname on dept(deptno,dname); INSERT into dept(deptno,dname,loc) values(1,'研发部','康和盛大厦5楼501'); INSERT into dept(deptno,dname,loc) values(2,'产品部','康和盛大厦5楼502'); INSERT into dept(deptno,dname,loc) values(3,'财务部','康和盛大厦5楼503');UPDATE emp set deptno=1 where empno=100002;
****테스트 문*** [emp 테이블의 레코드는 3600000일 수 있으며 효과는 분명히 느립니다.]
select * from emp where empno=(select empno from emp where ename='研发部')
e.empno로 주문을 가져오면, 속도는 더 빨라질 것입니다. 느림, 때로는 1분 이상
테스트 명령문
select * from emp e,dept d where e.empno=100002 and e.deptno=d.deptno;
느린 쿼리 로그 보기: 기본값은 데이터 디렉터리 데이터의 호스트 이름-slow.log입니다. 낮은 버전의 mysql은 mysql을 열 때 - -log-slow-queries[=file_name]을 사용하여 구성해야 합니다.
SQL 문 최적화-분석 설명 문제
Explain select * from emp where ename=“wsrcla”
는 다음 정보를 생성합니다.
select_type : 쿼리 유형을 나타냅니다.
table: 결과 집합을 출력하는 테이블
type: 테이블의 연결 유형을 나타냅니다.
possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引
key_len:索引字段的长度
rows:扫描出的行数(估算的行数)
Extra:执行情况的描述和说明

explain select * from emp where ename='JKLOIP'
如果要测试Extra的filesort可以对上面的语句修改
explain select * from emp order by ename\G
EXPLAIN详解
id
SELECT识别符。这是SELECT的查询序列号
id 示例
SELECT * FROM emp WHERE empno = 1 and ename = (SELECT ename FROM emp WHERE empno = 100001) \G;
select_type
PRIMARY :子查询中最外层查询
SUBQUERY : 子查询内层第一个SELECT,结果不依赖于外部查询
DEPENDENT SUBQUERY:子查询内层第一个SELECT,依赖于外部查询
UNION :UNION语句中第二个SELECT开始后面所有SELECT,
SIMPLE
UNION RESULT UNION 中合并结果
Table
显示这一步所访问数据库中表名称
Type
对表访问方式
ALL:
SELECT * FROM emp \G
完整的表扫描 通常不好
SELECT * FROM (SELECT * FROM emp WHERE empno = 1) a ;
system:表仅有一行(=系统表)。这是const联接类型的一个特
const:表最多有一个匹配行
Possible_keys
该查询可以利用的索引,如果没有任何索引显示 null
Key
Mysql 从 Possible_keys 所选择使用索引
Rows
估算出结果集行数
Extra
查询细节信息
No tables :Query语句中使用FROM DUAL 或不含任何FROM子句
Using filesort :当Query中包含 ORDER BY 操作,而且无法利用索引完成排序,
Impossible WHERE noticed after reading const tables: MYSQL Query Optimizer
通过收集统计信息不可能存在结果
Using temporary:某些操作必须使用临时表,常见 GROUP BY ; ORDER BY
Using where:不用读取表中所有信息,仅通过索引就可以获取所需数据;
위 내용은 Mysql 데이터베이스 성능 최적화에 대해 알고 계시나요?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



