시간이 촉박한 관계로 전자상거래 플랫폼의 아키텍처 실무를 다양한 각도에서 요약한 글입니다. 초안이 완성되었으며 보완 및 개선될 예정입니다.
재인쇄할 경우 출처를 명시해 주세요.
저자: Yang Butao
분산 아키텍처, 빅데이터, 검색, 오픈 소스 기술에 중점을 둡니다.
QQ:306591368
TechnologyBlog:
클라이언트 페이지 캐시(http 헤더에 가 포함됨) 만료/ 제어 캐시, 마지막 수정됨(304, 서버가 본문을 반환하지 않음, 클라이언트는 캐시를 계속 사용하여 트래픽을 줄일 수 있음 ), ETag)
역방향 프록시 캐시
애플리케이션 측 캐시 (memcache)
인메모리 데이터베이스
버퍼, 캐시 메커니즘(데이터베이스, 미들웨어 등)
해시 인덱스는 배열의 주소 지정과 연결 목록의 삽입 특성을 통합하는 데 적합하며 데이터에 대한 빠른 액세스를 달성할 수 있습니다.
B-트리 인덱스는 쿼리 중심 시나리오에 적합하며 다중IO를 방지하고 쿼리 효율성을 향상시킵니다.
역색인은 단어-문서 매핑 관계의 최상의 구현과 가장 효과적인 색인 구조를 구현하며 검색 분야에서 널리 사용됩니다.
비트맵은 매우 간단하고 빠른 데이터 구조로 (시간과 공간을 교환할 필요 없이) 저장 공간과 속도를 동시에 최적화할 수 있으며, 대용량 데이터가 포함된 컴퓨팅 시나리오에 적합합니다.2. 지역성의 특성은 지역성의 원리를 이용하여 대용량 데이터 계산의 문제를 분할하고 극복합니다.
MR 모델은 비공유 아키텍처이며 데이터 세트는 다양한 노드에 배포됩니다. 처리 중에 각 노드는 처리를 위해 로컬에 저장된 데이터를 읽고
2) 다중 프로세스, 다중 스레드 병렬 실행
(MPP)병렬 컴퓨팅(Parallel Computing)은 여러 컴퓨팅을 사용하는 것을 의미합니다. 동시에 해결하기 위한 자원 문제를 계산하는 과정은 컴퓨터 시스템의 계산 속도와 처리 능력을 향상시키는 효과적인 수단입니다. 기본 아이디어는 여러 프로세서 /프로세스 /스레드를 사용하여 동일한 문제를 공동으로 해결하는 것입니다. 즉, 해결해야 할 문제가 여러 부분으로 분해되고 각 부분이 독립 프로세서에 의해 병렬로 계산됩니다. 과 MR의 차이점은 데이터 분해가 아닌 문제 분해를 기반으로 한다는 점입니다. 플랫폼 동시성이 증가함에 따라 클러스터링 및 로드 밸런싱을 사용합니다. 로드 밸런싱 장치는 일반적으로 로드 밸런싱을 제공하는 동시에 오류 감지 기능도 제공합니다. 가용성을 향상하려면 노드 오류로 인한 가용성 문제를 방지하기 위한 재해 복구 백업이 필요합니다. 및 오프라인 백업의 경우 다양한 무효성 요구 사항에 따라 다양한 백업 전략을 선택할 수 있습니다. 읽기 및 쓰기 분리는 데이터베이스에 대한 것입니다. 시스템 동시성이 증가함에 따라 데이터 액세스 가용성을 향상시키는 중요한 수단은 쓰기 데이터와 읽기 데이터를 분리하는 것입니다. . 물론 읽기와 쓰기가 분리되어 있지만 일관성을 위해 데이터의 일관성에 주의를 기울여야 하지만, 분산 시스템에서는 CAP 정량화에 더 많은 주의를 기울여야 합니다. 플랫폼의 다양한 모듈 간의 관계는 가능한 한 비동기적으로 관련 메시지 구성 요소를 통해 상호 작용할 수 있어야 하며 주요 프로세스를 명확하게 구분할 수 있어야 합니다. 예를 들어, 보조 프로세스를 사용하면 기본 프로세스와 보조 프로세스가 비동기식으로 작동할 수 있으므로 전체 시스템의 가용성이 높아집니다. 물론 비동기 처리에서는 데이터가 수신되거나 처리되었는지 확인하기 위해 확인 메커니즘 (확인, ack)이 필요한 경우가 많습니다. 요청이 처리되었음에도 다른 이유(예: 불안정한 네트워크)로 인해 확인 메시지가 반환되지 않는 경우가 있습니다. 이 경우 요청을 다시 보내야 합니다. 설계에서는 재전송 요소로 인한 멱등성을 고려해야 합니다. 모니터링은 또한 전체 플랫폼의 가용성을 향상시키는 중요한 수단입니다. 모듈은 런타임 시 화이트박스를 달성하기 위해 여러 차원을 모니터링합니다. 런타임. Split에는 비즈니스 분할과 데이터베이스 분할이 포함됩니다. 시스템 리소스는 항상 제한되어 있습니다. 동시에 많은 수의 작업을 수행하는 경우 이 차단 방법은 다른 프로세스가 실행될 때까지 리소스를 효율적으로 해제할 수 없습니다. 높지 않습니다. 시스템 처리량을 향상하려면 비즈니스를 논리적으로 분할하고 비동기식 및 비차단 방식을 사용해야 합니다. 데이터의 양과 동시성이 증가함에 따라 읽기와 쓰기의 분리는 시스템 동시성 성능 요구 사항을 충족할 수 없습니다. 데이터를 데이터베이스와 테이블로 나누는 것을 포함하여 데이터를 분할해야 합니다. 데이터베이스와 테이블을 나누는 이 방법에는 데이터에 대한 라우팅 논리 지원을 추가해야 합니다. 시스템의 확장성을 위해서는 모듈이 Stateless인 것이 가장 좋으며, 노드를 추가하면 전체 처리량을 향상시킬 수 있습니다. 시스템 용량이 제한되어 있고, 아키텍처를 설계할 때 시스템이 견딜 수 있는 동시성 양도 제한되어 있습니다. 예상치 못한 공격이나 순간적인 동시성의 영향으로 인해 시스템이 충돌하는 것을 방지하려면 제어를 고려해야 합니다. 흐름 제어 조치를 추가하도록 설계할 때 요청 대기를 고려할 수 있습니다. 요청이 예상 범위를 초과하면 경보를 발행하거나 삭제할 수 있습니다. 공유 리소스에 액세스하려면 충돌을 방지하기 위해 동시성 제어가 필요합니다. 동시에 일부 트랜잭션은 트랜잭션 일관성을 보장하기 위해 트랜잭션이어야 합니다. 따라서 트랜잭션에서 시스템을 설계할 때 원자적 작업과 동시성 제어를 고려해야 합니다. 동시성 제어를 보장하기 위해 일반적으로 사용되는 고성능 수단에는 낙관적 잠금, Latch, mutex, Copy-On-Write, CAS 등이 포함됩니다. MVCC는 일반적으로 다음을 수행하는 데 중요한 수단입니다. 데이터베이스에 사용되는 일관성을 보장하는 것은 디자인에 자주 사용됩니다. 플랫폼에는 다양한 유형의 비즈니스 로직이 있으며 일부는 계산적으로 복잡하고 일부는 IO를 소비하며 동시에, 동일한 유형에 대해 서로 다른 비즈니스 로직은 서로 다른 양의 리소스를 소비하므로 서로 다른 로직에 대해 서로 다른 전략이 필요합니다. IO 유형의 경우 이벤트 기반 비동기 Non-Blocking 방식을 채택할 수 있으며, 단일 스레드 방식을 사용하면 스레드 전환으로 인한 오버헤드를 줄일 수 있고, 멀티 스레드의 경우 스핀 방식을 사용할 수 있습니다. 컴퓨팅을 위해 스레드 전환 (예: Oracle 래치 디자인 )을 줄이고 작업을 위해 멀티스레딩을 최대한 활용합니다. 동일한 유형의 호출 방법을 사용하면 기업마다 적절한 리소스를 할당하고 컴퓨팅 노드 또는 스레드 수를 다르게 설정하며 비즈니스를 전환하고 우선 순위가 높은 비즈니스에 우선 순위를 부여합니다. 시스템의 일부 비즈니스 모듈에서 오류가 발생할 때 동시성에서 정상적인 요청 처리에 미치는 영향을 줄이기 위해 때로는 별도의 채널을 고려해야 합니다. 이러한 비정상적인 요청에 대해 이러한 비정상적인 비즈니스 모듈을 처리하거나 일시적으로 자동으로 비활성화합니다. 일부 요청의 실패는 우발적인 일시적 실패(예: 네트워크 불안정)일 수 있으므로 요청 재시도를 고려해야 합니다. 리소스 사용 시 요청이 정상 경로이든 비정상 경로이든 마지막에 해제해야 원활한 진행이 가능합니다. 다른 요청에 사용하기 위해 적시에 자원을 재활용합니다. 통신 아키텍처를 설계할 때 시간 초과 제어를 고려해야 하는 경우가 많습니다. 전체 아키텍처는 CDN 및 수직 로드 밸런싱을 포함하는 계층화 및 분산 아키텍처입니다. 역방향 프록시, 웹 애플리케이션, 비즈니스 계층, 기본 서비스 계층, 데이터 저장 계층. 수평 방향에는 전체 플랫폼의 구성 관리, 배포 및 모니터링이 포함됩니다. CDN시스템은 네트워크 트래픽 및 각 노드의 연결, 로드 상태, 사용자까지의 거리, 서비스 노드의 응답 시간. 그 목적은 사용자가 근처에서 필요한 콘텐츠를 얻을 수 있도록 하고, 인터넷 네트워크 정체를 해결하고, 사용자가 웹사이트에 액세스하는 응답 속도를 향상시키는 것입니다. 대규모 전자상거래 플랫폼의 경우 일반적으로 네트워크 가속화를 위해 CDN을 구축해야 합니다. Taobao 및 JD.com과 같은 대규모 플랫폼은 자체 구축된 CDN을 사용합니다. 타사 CDN을 사용하여 Lan Xun, Wangsu, Kuaiwang 등과 같은 제조업체와 협력할 수 있습니다. 물론 CDN 공급업체를 선택할 때는 사업 기간, 확장 가능한 대역폭 리소스, 유연한 트래픽 및 대역폭 선택, 안정적인 노드, 비용 효율성 등을 고려해야 합니다. 대형 플랫폼에는 많은 비즈니스 도메인이 포함되어 있으며 다양한 비즈니스 도메인에는 다양한 클러스터가 있습니다. DNS를 사용하여 도메인 이름 확인을 배포하거나 폴링할 수 있습니다. DNS 방법은 간단합니다. 구현하지만 cache의 존재로 인해 유연성이 부족합니다. 일반적으로 상용 하드웨어 F5, NetScaler 또는 오픈 소스 소프트 로드 lvs를 기반으로 하며 4 계층에서 배포됩니다. 사용(예: lvs+keepalived), 활성 및 백업 모드를 채택합니다. 4 레이어가 비즈니스 클러스터에 배포된 후 레이어에서 nginx 또는 HAProxy와 같은 web 서버를 통과합니다. 7 마 로드 밸런싱 또는 역방향 에이전트는 클러스터의 애플리케이션 노드에 배포됩니다. 어떤 로드를 선택할지 선택하려면 다양한 요소(높은 동시성 및 고성능을 충족하는지, 세션 유지 문제를 해결하는 방법, 로드 밸런싱 알고리즘은 무엇인지, 지원 여부)를 종합적으로 고려해야 합니다. 압축, 캐시의 메모리 소비) 다음은 일반적으로 사용되는 몇 가지 로드 밸런싱 소프트웨어를 기반으로 한 소개입니다. LVS는 4 레이어에서 작동하며 Linux에서 구현된 고성능, 높은 동시성, 확장 가능하고 안정적인 로드 밸런서로, 다양한 전달 방법(NAT, DR, IP)을 지원합니다. 터널링), DR 모드는 WAN을 통한 로드 밸런싱을 지원합니다. 이중 시스템 핫 대기 (Keepalived 또는 Heartbeat)을 지원합니다. 네트워크 환경에 대한 의존도가 상대적으로 높습니다. Nginx는 7 레이어, 이벤트 중심, 비동기 및 비차단 아키텍처에서 작동하며 다중 프로세스 높은 동시성 로드 밸런서 / 역방향 프록시 소프트웨어를 지원합니다. 도메인 이름, 디렉터리 구조 및 일반 규칙을 기반으로 http에 대한 전환을 수행할 수 있습니다. 웹 페이지 처리 시 서버에서 반환하는 상태 코드, 시간 초과 등 내부 서버 오류를 포트를 통해 감지하고 다른 노드에 오류를 반환하는 요청을 다시 제출합니다. 그러나 단점은 url을 지원하지 않는다는 것입니다. 탐지를 위해. session Sticky의 경우 ip hash 알고리즘을 기반으로 구현할 수 있으며, 쿠키 기반 확장 nginx-sticky-module을 통해 session Sticky를 지원합니다. HAProxy은 로드 밸런싱을 위해 4 레이어와 7 레이어를 지원하고 session 세션 지속성을 지원합니다. cookie 지원 백엔드 url; 감지 방법; RR, 가중치 등을 포함하여 로드 밸런싱 알고리즘이 상대적으로 풍부합니다. 이미지의 경우 별도의 도메인 이름, 독립적 또는 분산 이미지 서버가 필요하거나 mogileFS와 같은 이미지 서버 위에 varnish를 추가할 수 있습니다. 이미지 캐싱용. 애플리케이션 계층은 프런트엔드 쇼핑, 사용자 독립적 서비스, 백엔드 시스템 등과 같은 독립적인 시스템을 나타내는 jboss 또는 tomcat컨테이너에서 실행됩니다. 프로토콜 인터페이스, HTTP, JSON 은 servlet3.0, 비동기 servlet, 을 사용하여 전체 시스템의 처리량을 향상시킬 수 있습니다 http요청 N ginx를 거쳐, 로드 밸런싱 알고리즘을 통해 App의 특정 노드에 할당됩니다. 이 레이어의 용량을 확장하는 것은 비교적 간단합니다. 소량의 사용자 부분 정보를 저장하기 위해 cookie를 사용하는 것 외에도(쿠키는 일반적으로 4K 크기를 초과할 수 없습니다), App액세스 레이어의 경우 사용자 관련 세션데이터가 저장되었지만 일부 역방향 프록시 또는 로드 밸런싱은 세션 고정을 지원하지 않거나 상대적으로 높은 액세스 가용성 요구 사항(앱 액세스 노드가 다운되고 세션이 손실)이 필요합니다. 세션의 중앙 집중식 저장을 고려하여 App 액세스 계층을 무상태로 만드는 동시에 시스템 사용자 수가 증가하면 더 많은 애플리케이션 노드를 추가하여 수평 확장을 달성할 수 있습니다. Session중앙 저장소는 다음 요구 사항을 충족해야 합니다. a, 효율적인 통신 프로토콜 b, session 분산 캐시, 노드 확장 지원, 데이터 중복 백업 및 데이터 마이그레이션 c, session만료 관리 는 특정 분야의 기업이 제공하는 서비스를 나타냅니다. 전자 상거래의 경우 필드에는 사용자, 상품, 주문, 빨간 봉투, 결제 서비스 등이 포함됩니다. 각 필드는 다양한 서비스를 제공합니다. 좋은 모듈 분할과 인터페이스 디자인은 매우 중요합니다. 일반적으로 높은 응집력과 인터페이스 융합의 원칙이 참조됩니다. 이를 통해 전체 시스템의 가용성이 향상될 수 있습니다. 물론, 애플리케이션의 크기에 따라 모듈을 함께 배포할 수도 있습니다. 대규모 애플리케이션의 경우 일반적으로 독립적으로 배포됩니다. 높은 동시성: 비즈니스 계층 외부 프로토콜은 의 RPC에 노출되며 netty, mina과 같은 보다 성숙한 NIO통신 프레임워크를 사용할 수 있습니다. 가용성: 모듈 서비스의 가용성을 높이기 위해 모듈은 중복성을 위해 여러 노드에 배포되고 자동으로 로드 전달 및 장애 조치를 수행합니다. 초기에는 VIP+heartbeat 5. 기본 서비스 미들웨어 1) 통신 구성 요소 통신 구성 요소는 비즈니스 시스템의 내부 서비스 간 호출에 사용되며 대규모 동시성 전자 상거래 플랫폼에서 높은 동시성 및 요구 사항을 충족해야 합니다. 높은 처리량. 전체 통신 구성 요소는 클라이언트와 서버라는 두 부분으로 구성됩니다. 클라이언트와 서버는 긴 연결을 유지하므로 각 요청에 대한 연결 설정 비용을 줄일 수 있습니다. 클라이언트는 연결이 초기화된 후 서버에 동시에 연결하여 rpc을 수행할 수 있습니다. 연결 풀의 긴 연결에는 하트비트 유지 관리 및 요청 시간 초과 설정이 필요합니다. 긴 연결의 유지 관리 프로세스는 요청을 보내는 프로세스와 응답을 받는 프로세스의 두 단계로 나눌 수 있습니다. 요청을 보내는 과정에서 IOException이 발생하면 연결이 유효하지 않은 것으로 표시됩니다. 응답을 받으면 서버는 SocketTimeoutException을 반환합니다. 시간 제한이 설정된 경우 예외를 직접 반환하고 현재 연결에서 시간 초과된 요청을 지웁니다. 그렇지 않으면 하트비트 패킷을 계속 보냅니다 ( pingInterval ping ( IOException) ping에 성공하면 현재 연결이 안정적이고 계속해서 읽을 수 있다는 의미입니다. 잘못된 연결은 연결 풀에서 지워집니다. 각 연결은 응답을 수신하기 위해 별도의 스레드에서 실행되며 클라이언트는 이를 동기적으로 (대기, 알림) 또는 비동기적으로 수행할 수 있습니다. 만들어 rpc 호출, 직렬화는 보다 효율적인 hession 직렬화 방법을 채택합니다. 서버는 이벤트 기반 NIO의 MINA 프레임워크를 사용하여 높은 동시성 및 높은 처리량 요청을 지원합니다. 대부분의 데이터베이스 샤딩 솔루션에서 데이터베이스의 처리량을 향상시키기 위해 첫 번째 단계는 서로 다른 테이블을 서로 다른 데이터베이스로 수직으로 분할하는 것입니다. 그런 다음 데이터베이스의 테이블이 특정 크기를 초과하면 테이블을 수평으로 분할해야 합니다. 여기서는 사용자 테이블을 예로 들어 보겠습니다. 사용자의 를 기반으로 액세스해야 하는 데이터를 찾습니다. 데이터 분할 알고리즘, 사용자의 , 일관성 Hash을 기반으로 hash 작업을 수행합니다. 사용자와 간의 매핑 관계 를 저장하는 라우팅 테이블을 유지 관리합니다. 리더와 복제본으로 구분됩니다. 쓰기와 읽기를 각각 담당합니다 이런 식으로 각 biz sharding 연결 풀을 유지해야 합니다. 이로 인해 전체 연결이 발생한다는 단점이 있습니다. 문제 해결책 샤딩 샤드 연결만 유지합니다. 사진보기(router Mongo DB id와 shard 간의 관계를 유지하려면 가용성을 보장하기 위해 replicatset 클러스터를 구축하세요. biz의 과 데이터베이스의 sharding은 일대일로 대응되며, 하나의 데이터베이스 에 액세스합니다. biz비즈니스 등록 노드가 도착합니다 Zookeeper /bizs/shard/down. router 노드 상태에서 /bizs/ zookeeper를 모니터링하고 router에 온라인으로 biz 캐시합니다. client가 router에 biz를 요청하면 router는 먼저 mongodb에서 사용자의 해당 샤드를 얻습니다. router는 캐시된 콘텐츠를 기반으로 RR 알고리즘을 통해 biz 노드를 얻습니다. router의 가용성 및 동시성 처리량 문제를 해결하기 위해 중복 router, client듣기 동물원 사육사의/ 라우터 노드 및 캐시 온라인 라우터노드 목록. HA를 구현하는 전통적인 방법은 일반적으로 Heartbeat와 결합된 가상 IP드리프트를 사용하는 것입니다. , keepalived 및 기타 구현HA , Keepalived은 vrrp를 사용하여 데이터 패킷을 전달하고, 4 레이어 로드 밸런싱을 제공하고, vrrp 패킷을 감지하여 전환하는 등의 작업을 수행합니다. 중복 핫 백업 더보기 LVS와 어울리네요. linux Heartbeat는 네트워크 또는 호스트 기반의 고가용성 서비스입니다. HAProxy 또는 Nginx는 7 레이어를 기반으로 데이터 패킷을 전달할 수 있으므로 Heatbeat가 HAProxy, Nginx에 더 적합합니다. , 높은 비즈니스 가용성을 포함합니다. 배포를 위해 zookeeper을 사용할 수 있습니다. 클러스터 목록 유지 관리 및 무효화를 달성하기 위한 조정 알림, 클라이언트 hash 알고리즘 또는 roudrobin을 선택하여 로드 밸런싱을 달성할 수 있습니다. master-master 모드 및 master-slave 모드의 경우 zookeeper 분산 잠금 메커니즘을 통해 지원될 수 있습니다. 플랫폼의 다양한 시스템 간의 비동기 상호작용을 위해 MQ 컴포넌트를 통해 수행됩니다. 메시지 서비스 구성 요소를 설계할 때는 메시지 일관성, 지속성, 가용성 및 전체 모니터링 시스템을 고려해야 합니다. 업계에는 두 가지 주요 오픈 소스 메시지 미들웨어가 있습니다. RabbitMQ 및 kafka, amqp 프로토콜을 팔로우하고 본질적으로 높은 콘크리 론에 의해 개발되었습니다. 주로 액티브 스트리밍 데이터,대량 데이터 처리에 사용됩니다. 메시지 생성 및 소비 프로세스를 포함하여 메시지 일관성 요구 사항이 상대적으로 높은 상황에서는 응답 확인 메커니즘이 필요합니다. 및 기타 원칙 누락은 메시지 중복으로 이어질 수 있으며, 이는 비즈니스 수준의 멱등성을 기반으로 판단 및 필터링될 수 있습니다. RabbitMQ는 이 접근 방식을 채택합니다. 소비자가 broker에서 메시지를 가져올 때 LSN 번호를 가져오고 broker의 특정 LSN 지점에서 일괄적으로 메시지를 가져오는 메커니즘도 있으므로 응답 메커니즘이 필요하지 않습니다. kafka 메시지 신뢰성 요구 사항과 포괄적인 성능 측정을 기반으로 broker의 메시지 저장은 메모리에 있거나 저장소에 지속될 수 있습니다. 가용성 및 높은 처리량 요구 사항을 위해 클러스터 및 활성-대기 모드를 모두 실제 시나리오에 적용할 수 있습니다. RabbitMQ 솔루션에는 일반 클러스터와 고가용성 미러 대기열 메서드가 포함되어 있습니다. kafka는 를 사용하여 클러스터의 broker 및 consumer를 관리합니다. 의 조정 메커니즘을 통해 topic을 등록할 수 있으며, producer는 해당 broker를 저장합니다. 주제 정보는 무작위로 또는 폴링 방식으로 broker에 전송될 수 있으며 Producer는 의미론에 따라 샤드를 지정할 수 있고 메시지는 broker의 특정 샤드에 전송될 수 있습니다. ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 일반적으로 RabbitMQ는 상대적으로 높은 신뢰성이 요구되는 실시간 메시징에 사용됩니다. kafka는 주로 활성 스트리밍 데이터를 처리하고 대량 데이터를 처리하는 데 사용됩니다. 5) 캐시 및 버퍼CacheSystem일부 높은 동시성 및 고성능 시나리오에서 cache를 사용하면 백엔드 시스템의 부하를 줄이고 부담을 줄일 수 있습니다. 대부분의 읽기 작업은 일반적으로 데이터베이스 저장 전에 캐시 캐시를 추가하는 등 시스템 처리량을 크게 향상시킬 수 있습니다. 그러나 캐시 아키텍처의 도입으로 인해 필연적으로 몇 가지 문제, 캐시적중률 문제, 캐시실패로 인한 지터, 캐시 및 스토리지 일관성이 발생합니다. Cache의 데이터는 스토리지에 비해 결국 제한적입니다. 이상적인 상황은 일부 일반적인 알고리즘 LRU 등을 사용하여 제거할 수 있는 스토리지 시스템의 핫 데이터입니다. 데이터; 시스템 규모가 증가함에 따라 단일 노드 cache는 요구 사항을 충족할 수 없으므로 일반적으로 단일 노드 장애로 인한 지터를 해결하려면 분산형 cache를 구축해야 합니다. 일관성을 사용합니다 hash 이 솔루션은 단일 노드의 오류로 인해 발생하는 지터 범위를 크게 줄이고 가용성 요구 사항이 상대적으로 높은 시나리오의 경우 각 노드를 백업해야 합니다. 데이터는 cache와 저장소에 모두 동일한 백업이 있으므로 일관성 문제가 있을 것입니다. 일관성이 비교적 강한 경우 데이터베이스 cache를 동시에 업데이트하세요. 일관성 요구 사항이 낮은 경우 캐시 만료 시간 정책을 설정할 수 있습니다. Memcached libevent의 이벤트 처리 메커니즘을 기반으로 합니다. Cache router 시스템 클라이언트에서 사용됩니다. 데이터 액세스가 실패하면 router 시스템에 액세스됩니다. 물론, 현재 , mongodb와 같은 더 많은 인메모리 데이터베이스가 cache에 사용됩니다. redis는 memcacheAPI보다 더 풍부한 데이터 작업을 제공합니다. 레디스 및 mongodb 모두 데이터를 유지하지만 memcache에는 이 기능이 없으므로 memcache가 관계형 데이터베이스에 데이터를 캐싱하는 데 더 적합합니다. System 고속 쓰기 작업 시나리오에 사용되면 플랫폼의 일부 데이터를 써야 합니다. 데이터베이스에 저장하고 데이터를 데이터베이스와 테이블로 구분하지만 데이터의 신뢰성은 그리 높지 않습니다. 데이터베이스에 대한 쓰기 부담을 줄이기 위해 일괄 쓰기 작업을 채택할 수 있습니다. 메모리 영역을 엽니다. 데이터가 80%와 같은 영역의 특정 임계값에 도달하면 메모리에서 하위 라이브러리 정렬 작업을 수행한 다음(메모리 속도는 여전히 상대적으로 빠릅니다) 하위 라이브러리를 플러시합니다. 배치. 6) 검색 주요 오픈소스 기업급 검색 엔진으로는 a. 대용량 데이터 처리, 읽기-쓰기 분리 지원 및 가용성 향상을 위해 검색 엔진이 분산 색인을 지원합니까? . 퍼포먼스 Solr은 lucene 기반의 고성능 전체 텍스트 검색 서버입니다. lucene보다 풍부한 쿼리 언어를 제공하고, 구성 및 확장이 가능하며, XML/JSON 형식으로 외부 인터페이스를 제공합니다. http 프로토콜. Solr4 버전부터 분산 인덱싱을 지원하고 각 샤딩을 통해 자동으로 샤딩데이터 샤딩을 수행하는 SolrCloud 메소드가 제공됩니다. 마스터-슬레이브 (leader, replica) 모드는 검색 성능을 향상시킵니다. zookeeper를 사용하여 leader 선택 등을 포함하여 클러스터를 관리하여 클러스터의 가용성을 보장합니다. 인덱싱된 Reader는 인덱스 snapshot을 기반으로 하므로 인덱스에 있어야 합니다. 커밋 이후에 새 커밋을 다시 엽니다. 스냅샷을 통해서만 새로 추가된 콘텐츠를 검색할 수 있으며 인덱싱 commit은 성능 집약적이므로 실시간 인덱스 검색의 효율성이 상대적으로 낮습니다. Solr4의 이전 솔루션은 전체 파일 인덱싱과 메모리 증분 인덱스 병합을 결합하는 것이었습니다. 아래 그림을 참조하세요. 는 NRT Softcommit에 대한 솔루션을 제공합니다. softcommit은 인덱스 작업을 제출하지 않고도 인덱스에 대한 최신 변경 사항을 검색할 수 있지만 인덱스에 대한 변경 사항은 동기화 커밋이 아닙니다. 사고가 발생하여 프로그램이 비정상적으로 종료되면 커밋되지 않은 데이터가 손실되므로 정기적으로 커밋 작업을 수행해야 합니다. 플랫폼의 데이터 인덱싱 및 저장 작업은 비동기식이므로 가용성과 처리량을 크게 향상시킬 수 있으며 특정 속성 필드에서는 인덱스 작업만 수행되며 데이터 식별은 Stored , 인덱스 크기를 줄입니다. 데이터는 분산 저장소 Hbase에 저장됩니다. hbase는 보조 인덱스 검색을 잘 지원하지 않지만 Solr 검색 기능과 결합하여 다차원을 수행할 수 있습니다. 검색 통계. 인덱스 데이터와 데이터 저장소의 일관성, 즉 HBase에 저장된 데이터가 인덱싱되었는지 확인하는 방법에 따라 confirm 확인 메커니즘을 사용할 수 있습니다. 인덱싱 전 설정 인덱싱할 데이터 큐 데이터가 저장되고 인덱싱된 후 인덱싱할 데이터 큐에서 데이터가 삭제됩니다. 7) 로그 수집 로그 시스템에는 agent(데이터 소스를 캡슐화하고 데이터 소스의 데이터를 collector로 전송), collector(여러 agent에서 데이터를 수신하여 요약)라는 세 가지 기본 구성 요소가 있어야 합니다. store), store(중앙 저장소 시스템은 확장 가능하고 안정적이어야 하며 현재 매우 인기 있는 HDFS을 지원해야 함). 업계에서 가장 일반적으로 사용되는 오픈 소스 로그 수집 시스템은 cloudera의 Flume 및 facebook의 Scrib입니다. e, 그 중 Flume현재 버전 FlumeNG은 Flume의 아키텍처를 크게 변경했습니다. 로그 수집 시스템을 설계하거나 기술적으로 선택할 때 일반적으로 다음과 같은 특성을 갖추어야 합니다. a. 분석 시스템은 이들 간의 관계가 분리 b, 분산 및 확장 가능하며 확장성이 높습니다. 데이터 양이 증가하면 노드를 추가하여 수평으로 확장할 수 있습니다 로그 수집 시스템은 확장 가능하며 전혀 사용할 수 없습니다. 확장 가능하고 데이터 처리에는 상태가 필요하지 않으며 확장성은 비교적 달성하기 쉽습니다. c, 거의 실시간 적시성이 요구되는 일부 시나리오에서는 데이터 분석을 위해 적시에 로그를 수집해야 합니다. 일반 로그 파일은 정기적으로 또는 정량적으로롤링되므로 실시간 탐지가 가능합니다. 로그 파일을 생성하려면 적시에 로그 파일에 대해 유사한 tail 작업을 수행하고 일괄 전송을 지원하여 전송 효율성을 높이십시오. 일괄 전송 타이밍은 메시지 수 및 시간 간격 요구 사항을 충족해야 합니다. d, Fault Tolerance Scribe 내결함성 고려 사항은 백엔드 스토리지 시스템 crash, scribe이 스토리지 시스템이 정상으로 돌아올 때 데이터를 로컬 디스크에 기록한다는 것입니다. , scribe스토리지 시스템에 로그를 다시 로드합니다. FlumeNG은 싱크 프로세서를 통해 로드 밸런싱 및 장애 조치를 달성합니다. 여러 개의 싱크가 싱크 그룹을 형성할 수 있습니다. 싱크 프로세서는 지정된 싱크 그룹에서 싱크을 활성화하는 역할을 담당합니다. 싱크 프로세서는 그룹의 모든 싱크를 통해 로드 밸런싱을 달성할 수 있으며, 하나의 싱크이 실패하면 다른 프로세서로 전송할 수도 있습니다. e, 거래 지원 Scribe은 거래 지원을 고려하지 않습니다. Flume은 응답 확인 메커니즘을 통해 거래 지원을 실현합니다. 아래 그림을 참조하세요. 보통 메시지 추출 및 전송은 일괄적으로 이루어지며, 메시지 확인은 일괄 데이터 확인이며, 이는 데이터 전송 효율성을 크게 향상시킬 수 있습니다. f、복구성 FlumeNG의 channel은 다양한 신뢰성 요구 사항에 따라 메모리 및 파일 지속성 메커니즘을 기반으로 할 수 있습니다. 메모리 기반 데이터 전송은 매출이 높지만 노드가 다운되면 데이터가 손실되어 파일을 복구할 수 없습니다. 지속성 가동 중지 시간을 복구할 수 있습니다. g, 데이터의 정기적이고 정량적인 보관 데이터는 로그 수집 시스템에 의해 수집된 후 후속 처리 및 분석을 용이하게 하기 위해 일반적으로 Hadoop과 같은 분산 파일 시스템에 저장됩니다. 데이터, 타이밍(TimeTrigger)또는 양적(SizeTrigger의 rolling분산 시스템 파일. 거래 시스템에서는 일반적으로 필요합니다. 이기종 데이터 소스를 동기화하려면 일반적으로 관계형 데이터베이스에 데이터 파일, 분산 데이터베이스에 데이터 파일, 분산 데이터베이스에 관계형 데이터베이스 등이 있습니다. 이기종 소스 간의 데이터 동기화는 일반적으로 성능 및 비즈니스 요구 사항을 기반으로 합니다. 쿼리 요구 사항; 분산 데이터베이스는 점점 더 많은 양의 데이터를 저장하지만 관계형 데이터베이스는 대규모 데이터 스토리지 및 쿼리 요청을 충족할 수 없습니다. 데이터 동기화 설계에서는 처리량, 내결함성, 신뢰성 및 일관성 문제를 종합적으로 고려해야 합니다. 동기화는 실시간 증분 데이터 동기화와 오프라인 전체 데이터로 구분됩니다. 2차원, 실시간 증분은 일반적으로 Tail 파일로 파일 변경 사항을 실시간으로 추적하고 배치 또는 다중 스레드로 데이터베이스에 내보내며 , 이 방법의 아키텍처는 로그 수집 프레임워크와 유사합니다. 이 방법에는 두 가지 측면을 포함하는 확인 메커니즘이 필요합니다. 한 가지 측면은 Channel이 일괄적으로 데이터 레코드를 수신했음을 agent에 확인하고 LSN 번호를 agent에 보내어 agent가 실패하고 복구될 때 이것을 사용할 수 있습니다 LSN 시작을 클릭하세요 tail 물론 소량의 중복 레코드를 허용하는 문제에 대해서는 (은 channel이 agent을 확인하고 agent이 다운되어 수신되지 않는 경우 발생합니다. 확인 메시지), 비즈니스 시나리오 심사에 들어가야 합니다. 또 다른 측면은 sync에서 채널로 데이터베이스에 일괄 쓰기가 완료되었는지 확인하여 channel 메시지에서 확인된 이 부분을 삭제할 수 있습니다. 신뢰성 요구 사항에 따라 channel은 파일 지속성을 사용할 수 있습니다. 아래 사진을 보세요 전체 오프라인 버전은 공간 간의 시간 교환, 분할 및 정복, 데이터 동기화 시간을 최대한 단축하고 동기화 효율성을 향상시키는 원리를 따릅니다. MySQL과 같은 소스 데이터를 분할하고, 소스 데이터를 여러 스레드로 동시에 읽고, HBase와 같은 분산 데이터베이스에 일괄적으로 동시에 쓰는 작업이 필요합니다. 채널을 읽기와 쓰기 사이의 버퍼로 사용하세요. 더 나은 디커플링을 달성하기 위해 channel은 파일 저장 또는 메모리를 기반으로 할 수 있습니다. 아래 그림을 참고하세요. 관계형 데이터베이스의 경우 일정 시간 동안만 오프라인으로 데이터를 동기화하는 것이 일반적인 요구 사항이므로 예를 들어 이른 아침에 그날의 주문 데이터를 HBase에 동기화)하므로 분할이 필요합니다. 행 수에 따른 데이터( ), 멀티 스레드는 전체 테이블을 스캔합니다 (제 시간에 인덱스를 구축하고 테이블을 반환해야 합니다 ). IO는 매우 높고 효율성은 매우 낮습니다. 여기에 해결 방법이 있습니다. 시간 필드에 따라 데이터베이스용 파티션을 생성하고 시간에 따라 동기화 )하고 파티션에 따라 각각 내보내는 것입니다. 시간. 9) 데이터 분석에서 거의 실시간에 가까운 인메모리 컴퓨팅을 위한 기존 관계형 데이터베이스 기반 병렬 처리 클러스터부터 현재까지 등을 포함하여 대규모 전자상거래 웹사이트에서 널리 사용됩니다. 병렬 처리 클러스터에는 상용 EMC Greenplum이 있습니다. 의 아키텍처는 대용량 데이터 저장을 위해 postgresql 기반의 분산 데이터베이스인 MPP(Massively Parallel Process)를 채택합니다. 메모리 컴퓨팅 측면에서는 SAP의 이 있고, 오픈 소스인 nosql메모리 데이터베이스 mongodb도 mapreduce를 지원합니다. 데이터 분석을 위해. 대량 데이터의 오프라인 분석은 현재 인터넷 기업에서 널리 사용되고 있습니다. Hadoop, Hadoop Hadoop은 MapReduce의 분산 처리 프레임워크를 통해 대규모 데이터를 처리하는 데 사용되며 확장성도 매우 좋습니다. MapReduce 데이터 분석을 위한 MapRduce 모델 프로그래밍을 기반으로 개발 효율성이 높지 않습니다. hadoop 위에 위치한 Hive의 등장으로 sql 작성과 유사한 방식으로 데이터 분석을 수행할 수 있습니다. sql은 구문 분석을 거쳐 실행 계획을 생성한 후 최종적으로 MapReduce 작업이 생성되어 실행되므로 개발 효율성이 크게 향상되고 ad-hoc(쿼리 발생 시 계산)에서 분석이 가능해집니다. 방법. 모델 기반의 분산 데이터 분석은 모두 오프라인 분석이며 실행은 모두 무차별 대입 스캔이므로 메커니즘을 사용할 수 없습니다. ; 오픈 소스 Cloudera Impala는 MPP 병렬 프로그래밍 모델을 기반으로 하며, 기본 레이어는 Hadoop에 저장된 고성능 실시간 분석 플랫폼으로, 데이터 지연을 크게 줄일 수 있습니다. 분석. 현재 에서 사용하는 버전은 Hadoop1.0입니다. 반면에 원본 MapReduce 프레임워크에는 JobTracker에 단일 지점 문제가 있습니다. , JobTracker 리소스 관리를 수행하면 데이터 양이 증가하고 Job 작업 수가 증가함에 따라 확장성, 메모리 소비, 스레드 모델, Hadoop2.0 원사에 명백한 병목 현상이 발생합니다. 전체 프레임워크를 재구성하고 리소스 관리와 작업 스케줄링을 분리하여 아키텍처 설계에서 이 문제를 해결했습니다. Yarn의 아키텍처 참조 10) 실시간 컴퓨팅 동시에 자체 구현도 필요합니다. -시스템에 대한 과도한 압력으로 인한 예기치 않은 시스템 마비를 방지하기 위해 모듈 흐름을 제어하는 등 시스템 보호 메커니즘. 트래픽이 너무 많으면 일부 비즈니스에서는 위험 제어가 필요할 수 있습니다. 예를 들어, 복권에 참여하는 일부 기업에서는 시스템의 실시간 판매량을 기준으로 숫자를 제한하고 숫자를 할당해야 합니다. 원래 계산은 단일 노드를 기반으로 했습니다. 시스템 정보가 폭발적으로 생성되고 계산 복잡성이 증가함에 따라 단일 노드 계산은 더 이상 다중 노드 분산 계산 요구 사항을 충족할 수 없습니다. 분산형 실시간 컴퓨팅 플랫폼이 등장했습니다. 여기서 언급된 실시간 컴퓨팅은 실제로 스트림 컴퓨팅입니다. 개념의 전신은 실제로 복잡한 이벤트 처리입니다. Esper, 업계 분산 스트림 컴퓨팅 제품인 Yahoo S4, Twitter storm, storm오픈 소스 제품이 가장 널리 사용됩니다. 실시간 컴퓨팅 플랫폼의 경우 아키텍처 설계 측면에서 다음 요소를 고려해야 합니다. 1. 확장성 비즈니스 규모가 증가하고 계산량이 증가함에 따라 노드 처리량을 늘려서 처리할 수 있습니다. 2. 고성능, 낮은 대기 시간 컴퓨팅 플랫폼으로 유입되는 데이터부터 출력 결과 계산까지 메시지를 빠르게 처리하고 실시간 계산이 이루어지도록 하려면 효율적인 성능과 낮은 대기 시간이 필요합니다. 3. 신뢰성 각 데이터 메시지가 완전히 한 번 처리되는지 확인하세요. 4. 내결함성 시스템은 애플리케이션에 투명하게 노드 가동 중지 시간 및 오류를 자동으로 관리할 수 있습니다. Twitter의 Storm은 위의 측면에서 더 좋습니다. Storm의 아키텍처를 간략하게 소개하겠습니다. 전체 클러스터는 zookeeper를 통해 관리됩니다. 클라이언트가 nimbus에 토폴로지를 제출합니다. Nimbus이 토폴로지에 대한 로컬 디렉토리를 설정하고, topology 구성에 따라 task를 계산하고, task를 할당하고, 할당노드 저장소 task 및 supervisor를 설정합니다. 사육사 노드에 있는 woker의 기계 통신 . 모니터링할 taskbeats노드를 zooke eper에 생성하세요. 작업 하트비트 시작 토폴로지. Supervisor zookeeper로 이동하여 할당된 tasks를 받고 여러 woker를 시작하여 진행하세요. , 하나의 task 스레드 ; task 간의 연결 은 topology 정보 초기화를 기반으로 설정됩니다. 이후에는 zeroMQ를 통해 관리됩니다. 전체 토폴로지가 실행됩니다. 튜플 는 스트림의 기본 처리 단위이며 메시지인 Tuple이 들어 있습니다. task Tuple의 송수신 과정은 다음과 같습니다. 보내기 Tuple, Worker는 기능 현재 task를 튜플 이동하려면 다른 task로 보내세요. taskid 및 tuple 매개변수를 사용하여 tuple 데이터를 직렬화하고 transfer queue에 넣습니다. 0.8 버전 이전에는 이 queue가 LinkedBlockingQueue이었고, 0.8 이후에는 DisruptorQueue이었습니다. 버전 0.8 이후에는 각 woker가 인바운드 전송 대기열 및 아웃본드 대기열에 바인딩됩니다. 바운드 큐는 메시지를 수신하는 데 사용됩니다. , outbond queue는 메시지를 보내는 데 사용됩니다. ㅋㅋㅋ 다른 worker 중간에 보내기 . 은 Tuple 모든 woker는 zeroMQ의 tcp 포트를 수신하여 메시지를 받습니다. DisruptorQueue 중간 이후, after from queue 에서 message(taskid,tuple)을 얻어 목적 taskid, tuple 값에 따라 실행을 위해 task로 라우팅합니다. 각 tuple은 으로 emit되거나 Reglular 모드에서 Stream Group(stream id-->comComponent id-- >outbond)에 의해 regular stream으로 전송될 수 있습니다. Tasks) 함수는 현재 tuple이 보낼 Tuple의 대상을 완성합니다. ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 위 분석에서도 알 수 있듯이, Storm 확장성, 내결함성 및 고성능 측면에서 아키텍처 설계 측면을 지원하는 동시에 안정성 측면에서 Storm의 ack 구성 요소는 XOR xor 알고리즘을 사용합니다. 매 순간 메시지가 완전히 처리되도록 합니다. 11) 실시간 푸시 시스템 모니터링 역학의 실시간 곡선 그리기, 휴대폰 메시지 푸시, 등 실시간 푸시에 대한 다양한 응용 시나리오가 있습니다. 웹실시간 채팅 등 실시간 푸시를 구현하는 데는 Comet 방법, websocket 방법 등을 포함하여 다양한 기술이 있습니다. Comet 두 가지 유형을 포함하는 긴 서버 연결을 기반으로 하는 "서버 푸시" 기술: Long Polling: 서버가 요청을 받은 후 정지되고, 업데이트가 있으면 연결이 반환되고 연결이 끊긴 다음 클라이언트가 새로운 연결을 시작합니다. 연결 Streammethod: 서버 데이터가 전송될 때마다 연결이 닫히지 않습니다. 연결은 통신 오류가 발생하거나 연결이 다시 설정될 때만 닫힙니다. 지나치게 긴 연결을 삭제하도록 설정하는 경우가 많으므로 클라이언트는 시간 초과 기간을 설정할 수 있으며 시간 초과 후에는 연결을 다시 설정하고 원래 연결을 닫으라는 알림을 클라이언트에 보냅니다. Websocket: 긴 연결, 전이중 통신 은 HTML5의 새로운 프로토콜입니다. 브라우저와 서버 간의 양방향 통신을 구현합니다. webSocket API 에서 브라우저와 서버는 브라우저와 클라이언트 사이에 빠른 양방향 채널을 형성하기 위해 핸드셰이크 작업만 필요하므로 데이터를 양방향으로 빠르게 전송할 수 있습니다. Socket.io는 클라이언트 측 js 및 서버 측 nodejs을 포함하는 NodeJS websocket 라이브러리로, 실시간 web 애플리케이션을 빠르게 구축하는 데 사용됩니다. 추가 예정 데이터베이스 저장소는 크게 관계형(트랜잭션) 데이터베이스를 포함하여 다음과 같은 범주로 나뉩니다. 오라클 , mysql이 표시되고, redis 및 memcached db로 표시되는 keyvalue 데이터베이스가 있고, mongodb와 같은 문서 데이터베이스가 있고, HBase, cassandra와 같은 열형 분산 데이터베이스가 있으며, dynamo로 표시됩니다. , 기타 그래프 데이터베이스, 객체 데이터베이스, xml 데이터베이스 등이 있습니다. 각 유형의 데이터베이스 애플리케이션의 비즈니스 분야가 다릅니다. 다음은 메모리, 관계형 및 분산형의 세 가지 차원에서 관련 제품의 성능, 가용성 및 기타 측면을 분석합니다. 인 메모리 데이터베이스는 높은 동시성 및 고성능을 목표로 하며 트랜잭션 측면에서 그다지 엄격하지 않습니다. 그리고 오픈 소스 osnosqldatabasemongodb, RedisSOMPENT의 경우 mongodbcommunication 방법 multi-shreading 방법, 메인 스레드는 새로운 연결을 모니터링하고 연결 후, 데이터 작업(IO 전환)을 수행하기 위해 새 스레드를 시작합니다. 데이터 구조 Database-->collection-->record 는 데이터 저장소의 네임스페이스, 동일 네임스페이스 내의 데이터는 여러 개의 로 나누어지고, Extent는 이중 연결 리스트를 통해 연결됩니다. 각 Extent에는 각 행의 특정 데이터가 저장되며, 이 데이터도 양방향 링크를 통해 연결됩니다. 각 행의 데이터 저장 공간에는 데이터가 차지하는 공간뿐만 아니라 데이터업데이트가 커진 후에도 위치가 이동되지 않도록 하는 추가 공간의 일부가 포함될 수 있습니다. 인덱스는 BTree 구조로 구현됩니다. jorunalinglog를 활성화하면 모든 작업 기록을 저장하는 파일도 있습니다. 영구 저장 MMap 메소드는 write, read 작업을 호출하지 않고 메모리 주소 공간을 직접 작동하여 파일을 작동할 수 있습니다. 비교하면 높다. mongodb는 mmap을 호출하여 디스크의 데이터를 메모리에 매핑하므로 안정성을 보장하기 위해 항상 데이터를 하드 디스크에 플러시하는 메커니즘이 있어야 합니다. syncdelay 매개변수. 저널(복구에 사용)은 Mongodb의 redo 로그이고, Oplog는 복제 binlog를 담당합니다. 저널이 켜져 있으면 전원이 꺼지더라도 100ms의 데이터만 손실되며 이는 대부분의 애플리케이션에서 허용되는 수준입니다. 1.9.2+부터 mongodb에서는 데이터 보안을 보장하기 위해 기본적으로 journal 기능을 켭니다. 또한 journal의 새로 고침 시간은 2-300ms 범위 내에서 변경할 수 있습니다. --journalCommitInterval 명령을 사용하세요. Oplog 및 데이터가 디스크에 새로 고쳐지는 시간은 60s입니다. 복제의 경우 oplog가 디스크를 새로 고칠 때까지 기다릴 필요가 없으며 메모리의 Secondary 노드에 직접 복사할 수 있습니다. . ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 거래 지원Mongodb페어만 지원 단일 행 레코드의 원자적 연산 HA 클러스터 이 더 일반적으로 사용됩니다. 복제 세트는 선택 알고리즘을 사용하여 리더 선거를 자동으로 수행하는 동시에 가용성을 보장하면서 강력할 수 있습니다. 일관성 요구 사항 . 물론 대용량 데이터의 경우 mongodb는 데이터 샤딩 아키텍처 도 제공합니다. Ø Redis풍부한 데이터 구조, 고속 응답 속도, 메모리 연산 통신 방식모든 연산이 메모리에 있기 때문에 논리 연산이 매우 빨라 CPU를 줄입니다. 스위칭 오버헤드이므로 단일 스레드 모드입니다(논리 처리 스레드와 메인 스레드가 하나임). 리액터 모드, 자신만의 멀티플렉싱 NIO 메커니즘 구현(epoll, select, kqueue 등) 단일 스레드 처리 -작업 데이터 구조 해시+버킷 구조, 연결 리스트의 길이가 너무 길면 마이그레이션 조치가 취해집니다. (원본을 hash 테이블의 두 배로 확장하고 거기에 데이터를 마이그레이션, expand+rehash) ㅋㅋㅋ save 명령은 메인 스레드를 차단합니다. bgsave하위 프로세스를 시작하여 snapshot rdb
종료하면 save 작업이 라고 데이터가 변경되면 몇초 정도 bgsavesync, master slaveb의 명령을 받아들입니다. (aof redolog와 유사) , 먼저 작성하세요. Log buffer , 그런 다음 flush flush 전략은 단일 또는 일괄적으로 구성될 수 있음) 파일에 대한 flush만 실제로 클라이언트에 반환됩니다. aof 파일과 rdb 파일은 정기적으로 병합되어야합니다 (스냅 샷 프로세스 중에 변경된 데이터는 먼저 Buf와 Child에 기록됩니다. 프로세스 완료 스냅샷 <memorysnapshot>을 찍은 후 aofbuf의 변경된 부분과 전체 이미지 데이터를 병합합니다. 높은 동시 액세스 모드에서 RDB 모드는 성능 오버헤드 측면에서 aof가 RDB보다 낫습니다. 하지만 복구됩니다. 메모리에 다시 로드하는 데 걸리는 시간은 데이터 양에 비례합니다. 클러스터HA 일반적인 솔루션은 실패한 마스터 redis를 슬레이브 redis로 신속하게 전환할 수 있도록 HA 소프트웨어를 사용하는 마스터-슬레이브 백업 전환입니다. 마스터-슬레이브 데이터 동기화는 복제 메커니즘을 채택하며 이 시나리오에서는 읽기와 쓰기를 분리할 수 있습니다. 현재 복제 측면에서 문제는 네트워크가 불안정할 때 Slave 및 Master 연결이 끊어져(플래시 중단 포함) Master를 전송해야 한다는 것입니다. memory rdb 파일(스냅샷 파일)의 모든 데이터가 재생성된 후 Slave로 전송됩니다. Slave는 Master가 전달한 rdb 파일을 받은 후 자체 메모리를 지우고 rdb 파일을 메모리에 다시 로드합니다. 이 방법은 상대적으로 비효율적입니다. 향후 버전인 Redis2.8에서는 작성자가 복사 기능의 일부를 구현했습니다. 관계형 데이터베이스도 트랜잭션 성능을 충족해야 합니다. mysqldatabase 예를 들어 설명해보세요. 아키텍처 설계 원칙, 성능 고려 사항 및 가용성 요구 사항을 충족하는 방법을 알아보세요. Ø mysql(innodb) 의 아키텍처 원리 mysql은 아키텍처 측면에서 server 레이어와 스토리지 엔진 레이어로 구분됩니다. Server서버 계층의 아키텍처는 연결/스레드 처리, 쿼리 처리(파서, 최적화 프로그램) 및 기타 시스템 작업을 포함하여 다양한 스토리지 엔진에서 동일합니다. 다양한 유형의 스토리지 엔진 계층이 있습니다. mysql은 스토리지 엔진의 플러그인 구조를 제공하고 여러 스토리지 엔진을 지원합니다. 가장 널리 사용되는 계층은 innodb이고 myisamin은 주로 OLTP입니다. 응용 프로그램은 트랜잭션 처리를 지원하고 myisam은 트랜잭션, 테이블 잠금을 지원하지 않으며 OLAP에서 빠르게 작동합니다. 다음은 주로 innodb
스레드 처리 측면에서 Mysql은 master 스레드, 잠금 모니터링 스레드, 오류 모니터링 스레드 및 여러 IO 스레드로 구성된 멀티 스레드 아키텍처입니다. 그리고 연결을 제공하기 위해 스레드가 열립니다. io 스레드는 임의의 IO를 저장하기 위한 삽입 버퍼, 트랜잭션 제어를 위한 oracle과 유사한 redo log, 다중 write, 다중 read 하드 디스크 및 메모리 교환 IO 스레드로 나뉩니다. . innodb 버퍼 풀 및 로그 버퍼를 포함한 메모리 할당 측면에서. 그 중 innodb 버퍼 풀에는 삽입 버퍼, 데이터페이지, 인덱스 페이지, 데이터 사전, 적응형 해시가 포함됩니다. 로그 버퍼는 성능 향상을 위해 트랜잭션 로그를 캐시하는 데 사용됩니다. 데이터 구조 측면에서 innodb에는 테이블 공간, 세그먼트, 영역, 페이지 / 블록 및 행이 포함됩니다. 인덱스 구조는 보조 인덱스와 기본 키 인덱스를 포함하는 B+tree 구조입니다. 보조 인덱스의 리프 노드는 기본 키 PK이며, 기본 키에 따라 인덱스된 리프 노드는 저장된 데이터 블록. 이 B+트리 저장소 구조는 무작위 쿼리 작업 IO 요구 사항을 더 잘 충족할 수 있습니다. 이는 데이터 페이지와 보조 인덱스 페이지로 구분되며, 쓰기 중 성능을 향상시키기 위해 를 채택합니다. insert buffer는 순차적 쓰기를 수행한 다음 백그라운드 스레드가 특정 빈도로 여러 삽입을 보조 인덱스 페이지에 병합합니다. 데이터베이스(메모리 및 하드 디스크 데이터 파일)의 일관성을 보장하고 인스턴스 복구 시간을 단축하기 위해 관계형 데이터베이스에는 이전 더티 페이지를 변환하는 데 사용되는 체크포인트 기능도 있습니다. 비율 (old 에 따라 메모리 버퍼가 디스크에 기록되므로 장애 복구 시 redolog 파일의 LSN이전 로그를 덮어쓰고 재활용할 수 있습니다. 로그에서 LSN을 클릭하세요. 복원하세요. ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 트랜잭션 기능 지원 측면에서 관계형 데이터베이스는 ACID4가지 기능을 충족해야 합니다. 다양한 트랜잭션 동시성 및 데이터 가시성 요구 사항을 기반으로 다양한 트랜잭션 격리 수준을 정의해야 하며 리소스 경합을 위한 잠금 메커니즘과 분리될 수 없습니다. 교착 상태를 방지하기 위해 mysql은 Server 계층 및 스토리지 엔진 계층에서 동시성 제어를 수행하며 주로 읽기-쓰기 잠금에 반영됩니다. 잠금 수준에 따라 다양한 잠금 수준이 있습니다(테이블 잠금, 행 잠금, 페이지 잠금 Lock, MVCC); 동시성 성능 향상을 고려하여 다중 버전 동시성 제어 MVCC를 사용하여 트랜잭션 격리를 지원하며, 트랜잭션 롤백 시 undo를 기반으로 구현됩니다. 부분도 사용하게 됩니다. mysql redolog를 사용하여 데이터 쓰기 및 오류 복구 성능을 보장합니다. 데이터 수정 시 메모리만 수정한 다음 수정 동작을 트랜잭션 로그(Sequential IO)에 기록하면 됩니다. 매번 데이터를 수정해야 함 데이터 수정 자체가 하드 디스크(randomIO)에 유지되어 성능이 크게 향상됩니다. ㅋㅋㅋㅋㅋㅋㅋㅋㅋ 신뢰성 측면에서 innodb 스토리지 엔진은 두 번 쓰기 메커니즘double을 제공합니다. writer 페이지 저장 시 flush 오류를 방지하고 디스크 half-writern 문제를 해결하는 데 사용됩니다. Ø 높은 동시성 및 고성능 mysql을 위해 성능 튜닝은 다차원에서 수행될 수 있습니다. a, 하드웨어 수준, 로그와 데이터 저장소가 분리되어야 하고, 로그는 순차적으로 작성되어야 하며, 을 수행해야 하며, buffer-IO를 사용해야 합니다. , 파일 시스템 cache로 인한 오버헤드를 피하려면 direct IO를 사용하세요. 저장 용량, disk 작업(raid카드 캐시, 읽기캐시 끄기, 디스크 끄기, 미리 읽기 끄기, 전용 사용 writebackbuffer 단, 충전 및 방전 문제를 고려해야 합니다.) 물론 데이터 크기가 크지 않으면 데이터 저장을 위해 고속 장비인 , SSD를 사용할 수 있습니다. 데이터 쓰기의 경우 더티 페이지 새로 고침 빈도를 제어하고, 데이터 읽기의 경우 캐시 적중 속도를 제어합니다. 따라서 시스템 요구 사항을 예측하세요. IOPS, 필요한 하드 디스크 수를 평가합니다(fusion io 최대 IOPS 10w 이상, 일반 하드 디스크 150). Cpu단일 인스턴스의 경우 NUMA가 꺼지고, mysql은 멀티코어를 잘 지원하지 않으며, CPU는 여러 인스턴스에 바인딩될 수 있습니다. b, 운영 체제 수준, 커널 및 socket 최적화, 네트워크 최적화본드, 파일 시스템, IO스케줄링 in nodb 주로 OLTP에서 사용됩니다. 애플리케이션은 일반적으로 IO 집약적 애플리케이션으로 IO 기능 향상을 기반으로 cache 메커니즘을 최대한 활용합니다. 고려해야 할 사항은 다음과 같습니다: 시스템의 사용 가능한 메모리를 보장하기 위해 일반적으로 3으로 설정되는 innodb 버퍼 풀을 최대한 확장합니다. /4 파일 시스템을 사용하고, 트랜잭션 로그를 기록할 때는 파일 시스템의 cache만 사용하세요. swap을 사용하여 mysql을 피하세요. 파일 시스템을 단단히 해제합니다. thecache) ii Scheduling 최적화, 불필요한 차단을 줄이고 무작위 의 대기 시간 감소 + d. 애플리케이션 수준(예: 인덱스 고려 사항, 적절한 중복성을 통한 schema 최적화, sql 쿼리로 인한 CPU 문제 및 메모리 문제 최적화, 잠금 범위 축소, 테이블 백 축소) 스캔 및 포함 인덱스) Ø 고가용성 측면에서 는 master-master master-slave 모드를 지원합니다. master-master 모드에서는 한 가지 작업만 수행합니다. 마스터로서 읽기 및 쓰기를 담당하고, 다른 하나는 재해를 제공하는 대기 역할을 합니다. 백업을 위해 maser-slave는 마스터로서 쓰기 작업을 제공하는 노드이고 다른 여러 노드는 읽기 작업을 수행합니다. , 읽기 및 쓰기 분리를 지원합니다. 노드 1차 및 2차 장애 감지 및 전환을 위해 HA 소프트웨어를 사용할 수 있습니다. 물론 더 많은 관점에서 zookeeper를 클러스터 조정 서비스로 사용할 수도 있습니다. 세밀한 사용자 정의. 분산 시스템의 경우 데이터베이스 마스터/백업 전환의 일관성이 항상 문제가 됩니다. a, oracle의 rack과 같은 클러스터 방법, 단점은 다음과 같습니다. 더 복잡하다고 b, 공유 SAN 저장 방법에서는 관련 데이터 파일과 로그 파일이 공유 저장소에 배치됩니다. 장점은 활성 및 대기 전환 중에 데이터가 일관성을 유지하고 손실되지 않는다는 것입니다. 대기 머신이 일정 시간 동안 당겨지면 단기적으로 사용할 수 없는 상태가 됩니다 c. 메인 및 백업 데이터 동기화 방법은 일반적인 방법은 로그 동기화로, 핫 백업과 양호한 백업을 보장할 수 있습니다. 실시간 성능을 제공하지만 전환 중에 일부 데이터가 동기화되지 않아 데이터 일관성 문제가 발생할 수 있습니다. 메인 데이터베이스를 운영하는 동안 작업 로그를 기록할 수 있으며, 동기화되지 않은 데이터를 보충하기 위해 작업 로그를 check 수행합니다. 또 다른 방법은 대기 데이터베이스를 사용하는 것입니다. 데이터가 손실되지 않도록 메인 라이브러리의 regolog 저장소로 전환하세요. mysql에서는 데이터베이스 마스터-슬레이브 복제의 효율성이 그다지 높지 않습니다. 주된 이유는 트랜잭션이 순서를 엄격하게 유지하기 때문입니다. 인덱스 mysql에는 복제 측면에서 로그 라는 두 가지 프로세스가 포함되어 있습니다. 및 relog log 모두 단일 스레드 직렬 작업이므로 데이터 복사 최적화 측면에서 IO의 영향이 최소화됩니다. 그러나 Mysql5.6 버전부터는 서로 다른 라이브러리에서의 병렬 복제가 지원될 수 있습니다. Ø 다양한 비즈니스 요구 사항에 따른 액세스 방법플랫폼 비즈니스에서는 두 가지 일반적인 비즈니스 사용자 및 주문과 같이 비즈니스마다 액세스 요구 사항이 다릅니다. 일반적으로 사용자는 총량은 제어 가능하지만 주문은 지속적으로 증가하고 있습니다. 사용자 테이블의 경우 먼저 하위 데이터베이스로 나누고 각 sharding은 하나의 마스터와 다중 읽기를 수행합니다. 마찬가지로 주문의 경우 사용자에 대한 수요가 더 많습니다. 주문 라이브러리도 사용자별로 나누어야 하며 하나의 마스터에서 여러 읽기를 지원합니다. 하드웨어 저장 측면에서는 트랜잭션 로그가 순차적으로 기록되기 때문에 플래시 메모리의 장점은 하드 디스크보다 크게 높지 않으므로 데이터 파일에는 배터리 보호 쓰기 캐시 raid카드 저장 장치가 채택됩니다. 사용자용이든 주문용이든 무작위 읽기 및 쓰기 작업이 많이 있을 것입니다. 물론 메모리를 늘리는 것도 하나의 측면입니다. 또한 PCIe 카드와 같은 고속 장치 플래시 메모리를 사용할 수 있습니다. 퓨전-io. 플래시 메모리 사용은 마스터-슬레이브 복제와 같은 단일 스레드 워크로드에도 적합합니다. 슬레이브 노드에 fusion-IO 카드를 구성하여 복제 대기 시간을 줄일 수 있습니다. 주문업무의 경우 물량이 지속적으로 증가하고, PCIe 카드 저장 용량이 상대적으로 제한되어 있으며, 주문업무의 핫데이터는 최근 기간에 불과합니다(예를 들어 , 최근 개월) 두 가지 솔루션이 있습니다. 하나는 플래시 메모리와 하드 디스크 스토리지 기반의 오픈 소스 하이브리드 스토리지 방식을 사용하여 핫스팟 데이터를 플래시 메모리에 저장하는 flashcache 방식입니다. 또 다른 방법은 정기적으로 분산 데이터베이스 HBase로 내보내는 것입니다. 사용자가 주문 목록을 쿼리하면 mysql에서 최신 데이터를 가져옵니다. 물론 가 필요합니다. . HBase의 잘 설계된 rowkey는 쿼리 요구 사항에 맞게 설계되었습니다. 데이터에 대한 높은 동시 액세스를 위해 기존 관계형 데이터베이스는 읽기-쓰기 분리 솔루션을 제공하지만 이로 인해 데이터 일관성 문제가 발생하고 점점 더 많은 양의 데이터에 대한 데이터 분할 솔루션을 제공합니다. 데이터베이스는 구현이 더 복잡하고 향후 지속적인 마이그레이션과 유지 관리가 필요한 하위 데이터베이스와 하위 테이블을 사용합니다. 기존 데이터는 마스터-대기, 마스터-슬레이브 및 다중 마스터 솔루션을 사용합니다. 확장성이 상대적으로 낮습니다. 노드를 추가하고 가동 중지 시간이 발생하면 데이터 마이그레이션이 필요합니다. 위에서 제기된 문제에 대해 분산 데이터베이스 HBase는 동시성 대용량 데이터 액세스 요구 사항에 적합한 완전한 솔루션 세트를 갖추고 있습니다. Ø HBase 열 기반 효율적인 저장 공간 감소 IO 고성능 LSM 트리 고속 쓰기 시나리오에 적합 강하고 일관된 데이터 액세스 MVCC HBase의 일관된 데이터 액세스는 MVCC를 통해 구현됩니다. HBase 데이터를 쓰는 과정에서 HLog 쓰기, memstore 쓰기, MVCC 업데이트 등 여러 단계를 거쳐야 진정한 memstore 쓰기 성공, 격리가 이루어집니다. 예를 들어, 데이터를 읽으면 다른 스레드에서 제출하지 않은 데이터를 얻을 수 없습니다. 신뢰성이 높은 HBase의 데이터 저장소는 중복 메커니즘을 제공하는 HDFS를 기반으로 합니다. Region 노드 가동 중지 시간은 파일로 플러시 zookeeper 를 통해 대상 ZOKEERPER 를 찾아서 지역을 찾아서 regrion을 찾습니다. Region Server는 자체적으로 Master에 게시하여 확장하고, Master는 이를 균등하게 배포합니다. 단일 장애 지점이 있습니다. Region Server가 다운된 후 server가 관리하는 region에 짧은 시간 내에 액세스할 수 없게 됩니다. failover가 적용되기를 기다리고 있습니다. Master를 통해 각 Region Server의 상태와 Region 배포를 유지합니다. 여러 Master, Masterdowntime에는 zookeeper의 paxos투표 메커니즘이 있어 다음 Master을 선택합니다. Master가 완전히 다운되더라도 Region의 읽기 및 쓰기에는 영향을 미치지 않습니다. Master는 자동 운영 및 유지보수 역할만 합니다. HDFS은 분산 스토리지 엔진으로, 1개의 백업, 3개의 백업, 높은 신뢰성, 0데이터 손실이 가능합니다. HDFS의 namenode는 SPOF입니다. 단일 지역에 너무 자주 액세스하고 단일 시스템에 과도한 압력을 가하는 것을 방지하기 위해 분할 메커니즘 HBase은 LSM-TREE 아키텍처를 사용하여 작성되었습니다. 데이터에는 점점 더 많은 append, HFile, HBase가 HFile 파일 처리 compact를 제공하여 만료된 데이터를 지우고 쿼리 성능을 향상시킵니다. Schema free HBase 관계형 데이터베이스처럼 엄격한 schema가 없으며 schema를 추가하고 삭제할 수 있습니다. 의 자유로운 필드. HBase 분산 데이터베이스는 현재 rowkey의 인덱스만 지원하므로 rowkey의 디자인은 쿼리 성능에 매우 중요합니다. 통합 구성 라이브러리 배포 플랫폼 대규모 분산 시스템에는 다음과 같은 다양한 장치가 포함됩니다. 네트워크 스위치로 , 일반 PC 머신, 다양한 유형의 네트워크 카드, 하드 디스크, 메모리 등은 물론 애플리케이션 비즈니스 수준 모니터링의 수가 매우 많으면 오류 가능성도 높아지며 일부 모니터링 요구 사항이 있습니다. 상대적으로 시기적절함. 일부는 두 번째 수준에 도달함. 비정상 데이터는 다수의 데이터 스트림에서 필터링되어야 하며 때로는 경보가 필요한지 여부를 결정하기 위해 데이터에 대해 복잡한 상황 관련 계산이 수행됨. 따라서 모니터링 플랫폼의 성능, 처리량 및 가용성이 더 중요합니다. 모든 수준에서 시스템을 모니터링하려면 통합 모니터링 플랫폼을 계획해야 합니다. 플랫폼의 데이터 분류 애플리케이션 비즈니스 수준: 애플리케이션 이벤트, 비즈니스 로그, 감사 로그, 요청 로그, 예외, 요청 비즈니스metrics, 성능 지표 시스템 수준: CPU , 메모리, 네트워크, IO 적시성 요구 사항 임계값, 알람: 실시간 계산: 거의 실시간 분 계산 시간 및 날짜별 오프라인 분석 실시간 쿼리 아키텍처 노드의 Agent 에이전트는 로그, 애플리케이션 이벤트를 수신하고 프로브를 통해 데이터를 수집할 수 있습니다. agent 데이터 수집의 한 가지 원칙은 비즈니스 애플리케이션에서 비동기적으로 격리되는 것입니다. 프로세스는 거래 프로세스에 영향을 미치지 않습니다. 데이터는 collector 클러스터를 통해 균일하게 수집되며 처리를 위해 다양한 데이터 유형에 따라 다양한 컴퓨팅 클러스터에 배포됩니다. 예를 들어 시간별 통계와 같은 일부 데이터는 hadoop 클러스터에 저장됩니다. 순환하는 추적 데이터를 쿼리할 수 있어야 하는 경우 인덱싱을 위해 solr 클러스터에 넣을 수 있습니다. 실시간으로 계산한 다음 경고해야 하는 일부 데이터는 처리를 위해 storm 클러스터에 넣어야 합니다. 컴퓨팅 클러스터에서 데이터를 처리한 후 결과는 Mysql 또는 HBase에 저장됩니다. 모니터링 web 애플리케이션은 실시간 모니터링 결과를 브라우저에 푸시할 수 있으며, 결과 표시 및 검색을 위한 API도 제공할 수 있습니다. 3. 다차원 가용성
1) 로드 밸런싱, 재해 복구, 백업
2) 읽기 및 쓰기 분리
3) 종속성
4) 모니터링
4. Scaling
1) Split
2) Stateless
5. 리소스 활용 최적화
1) 제한된 시스템 용량
2) 원자적 작업 및 동시성 제어
3) 다양한 로직을 기반으로 다양한 전략이 채택됩니다
4) 내결함성 격리
5) 리소스 해제
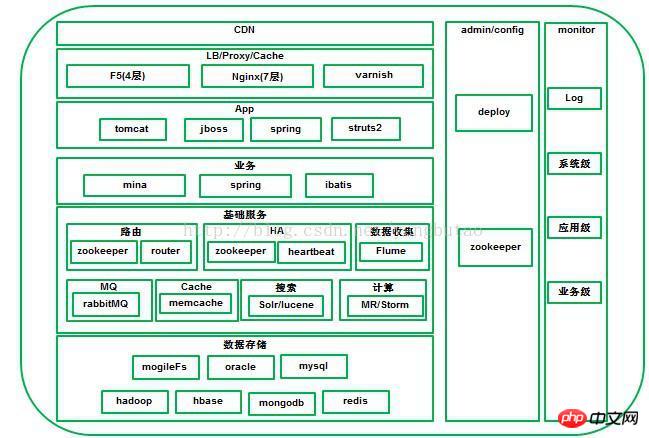
3. 아키텍처 분석
1. CDN
2. 로드 밸런싱, 역방향 프록시
3. 앱 액세스
4 . 비즈니스 서비스
)
을 보냅니다. ping
fails
2) RoutingRouter

3) HA
4) MessageMessage
검색은 전자상거래 플랫폼에서 매우 중요한 기능으로 주로 검색어 카테고리 탐색, 자동 프롬프트 및 검색 정렬 기능을 포함합니다.

전체 거래 과정에서 수많은 로그가 생성되며, 이러한 로그는 중앙 집중화를 위해 분산 저장 시스템에 수집 및 저장되어야 합니다. 쿼리 및 분석 및 처리.

8) 데이터 동기화

 소스 데이터의 분할을 위해 파일인 경우 파일 이름에 따라 블록 크기를 설정할 수 있습니다.
소스 데이터의 분할을 위해 파일인 경우 파일 이름에 따라 블록 크기를 설정할 수 있습니다. 의 대용량 데이터 분석, 데이터 분석은
트래픽 통계, 추천 엔진, 추세 분석, 사용자 행동 분석, 데이터 마이닝 분류기, 분산 인덱스 등 인터넷 분야에서는 실시간 컴퓨팅이 널리 사용됩니다. 모니터링 및 분석, 흐름 제어, 위험 제어 및 기타 분야. 전자상거래 플랫폼 시스템이나 애플리케이션은 매일 생성되는 대량의 로그와 이상 정보를 실시간 필터링 및 분석하여 조기 경보가 필요한지 여부를 판단해야 합니다.

12) 추천 엔진
6. 데이터 저장소
1) 인 메모리 데이터베이스
 collection으로 구분됩니다.
collection으로 구분됩니다. 2) 관계형 데이터베이스

3) 분산 데이터베이스
일반적인 쿼리에는 행의 모든 필드가 필요하지 않고 대부분 몇 개의 필드만 필요합니다.
행 중심 저장 시스템을 사용하면 각 쿼리가 모든 데이터를 을 빼낸 후 필수 필드를 선택합니다
컬럼 중심의 저장 시스템으로 컬럼을 별도로 쿼리할 수 있어 IO가 대폭 절감됩니다IO
압축 효율성 향상
동일 컬럼에 있는 데이터의 유사도가 높아 압축 효율성이 높아집니다.
Hbase 많은 기능이 열 저장에 의해 결정됩니다

7. 관리 및 배포 구성
8. 모니터링 및 통계

위 내용은 높은 동시성 및 고가용성 아키텍처 구축의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



