

Excel을 이용한 Python 연산에 대한 자세한 설명

전제 조건:
Python이 Excel을 작동하기 위해 사용해야 하는 모듈에는 xlrd, xlwt 및 xlutils가 있습니다. Excel에서 읽기, 쓰기 및 업데이트 작업을 수행합니다. Excel을 실행할 때 먼저 이 모듈을 가져와야 합니다. 데모는 다음과 같습니다.
excel - 작업 지식 포인트 읽기:
book = xlrd.open_workbook( sheet = sheet1 = book.sheet_by_name( rows = cols = row_value = sheet.row_values(2 col_values = sheet.col_values(1 cell_value = sheet.cell(8, 1 cell_str = sheet.cell(8, 1).value
excel - Excel 작은 경우 읽기:
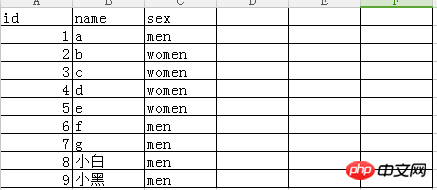
1 import xlrd 2 ''' 3 读取excel的数据,读取数据的列固定,循环读取每行数据,读取后的数据格式如下: 4 [ 5 {'name':xxx,'sex':xxx,'id':1}, 6 {'name':xxx,'sex':xxx,'id':1}, 7 ....... 8 ] 9 '''10 def readExcel():11 try:12 #若输入的excel不存在,则打开excel报错13 book = xlrd.open_workbook('students.xlsx')14 except Exception as e:15 print('error msg:', e)16 else:17 sheet = book.sheet_by_index(0)18 #获取excel的总行数19 rows = sheet.nrows20 stu_list = []21 #循环读取每行数据,第0行是表头信息,所以从第1行读取数据22 for row in range(1, rows):23 stu = {}24 #获取第row行的第0列所有数据25 id = sheet.cell(row, 0).value26 name = sheet.cell(row, 1).value27 sex = sheet.cell(row, 2).value28 #将id、name、sex添加到字典,若元素不存在则新增,否则是更新操作29 stu['id'] = id30 stu['name'] = name31 stu['sex'] = sex32 stu_list.append(stu)33 print(stu_list)34 35 if __name__ == '__main__':36 readExcel()excel 데이터 형식은 다음과 같습니다. :
excel - 쓰기 작업 지식 포인트:
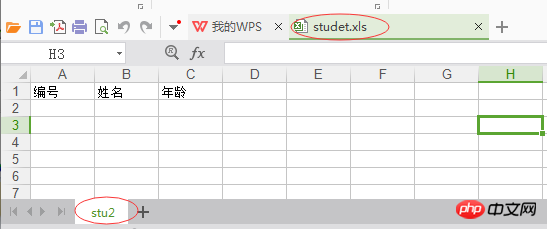
1 import xlwt 2 ''' 3 写 excel的操作步骤如下: 4 1. 打开excel,打开不存在的excel,若打开已存在的excel,进行写操作,写入的数据会覆盖以前的数据 5 2. 获取sheet对象并指定sheet的名称 6 3. 对excel进行操作: 7 写入excel、保存excel 8 ''' 9 #打开excel创建book对象10 book = xlwt.Workbook()11 #创建sheet指定sheet名称12 sheet = book.add_sheet('stu2')13 #写入excel数据,第n行第n列写入某个值,写入的数据类型为str14 sheet.write(0, 0, '编号')15 sheet.write(0, 1, '姓名')16 sheet.write(0, 2, '年龄')17 #保存excel,保存的后缀必须是xls18 book.save('studet.xls')엑셀이 새로운 엑셀을 작성한 후 데이터 형식은 다음과 같습니다.
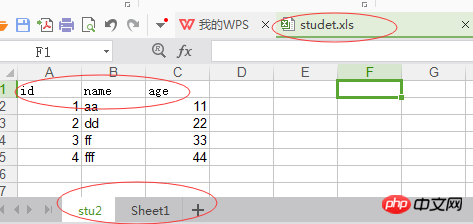
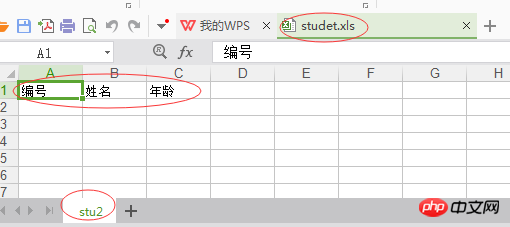
excel은 기존 엑셀을 운영하고, 쓰기 작업 이후의 엑셀 형식은 다음과 같습니다.
 --- ->
--- ->
excel - 작은 엑셀 케이스 작성 :
1 import xlwt 2 ''' 3 将list数据: 4 [{'name': '小白', 'id': 1.0, 'sex': '男'}, 5 {'name': '小花', 'id': 2.0, 'sex': '女'}, 6 {'name': '小黑', 'id': 3.0, 'sex': '男'}, 7 {'name': '小茹', 'id': 4.0, 'sex': '女'}, 8 {'name': '小小', 'id': 5.0, 'sex': '男'}] 9 写入excel,title信息为:编号、姓名、性别10 '''11 def writeExcel():12 book = xlwt.Workbook()13 sheet = book.add_sheet('stu')14 titles = ['编号', '姓名', '性别']15 #循环读取titles的长度,col的值为:0,1,2,并将title值写入excel16 for title_col in range(len(titles)):17 #title 写入excel的第0行的第col列,写入titles[col]值18 sheet.write(0, title_col, titles[title_col])19 students_list = [{'name': '小白', 'id': 1.0, 'sex': '男'},{'name': '小花', 'id': 2.0, 'sex': '女'},{'name': '小黑', 'id': 3.0, 'sex': '男'},{'name': '小茹', 'id': 4.0, 'sex': '女'},{'name': '小小', 'id': 5.0, 'sex': '男'}]20 for stu_row in range(len(students_list)):21 #循环读取student_list的长度,从0开始,写入excel时从第1行开始写入数据22 #写入excel的数据是从list里进行取值,获取list的每个元素,返回字典,然后通过字典的key获取value23 sheet.write(stu_row+1, 0, students_list[stu_row]['id'])24 sheet.write(stu_row+1, 1, students_list[stu_row]['name'])25 sheet.write(stu_row+1, 2, students_list[stu_row]['sex'])26 book.save('student.xls')27 if __name__ == '__main__':28 writeExcel()excel 데이터 형식은 다음과 같습니다.
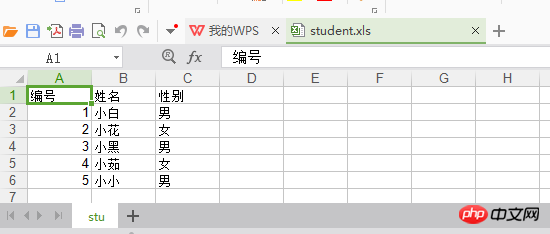
excel - 업데이트 운영 지식 포인트 :
1 import xlrd 2 from xlutils.copy import copy 3 ''' 4 更新excel操作: 5 1. 打开excel,更新的excel必须存在 6 2. 复制一个新的excel,使用xlutils模块中的copy方法 7 3. 更新excel内的数据 8 4. 保存更新后的excel数据,以前的excel数据不会更改 9 '''10 from xlutils.copy import copy11 #打开excel12 book = xlrd.open_workbook('student.xlsx')13 #复制一个新的excel14 new_book = copy(book)15 #查看某个对象下的所有方法16 #print(dir(new_book))17 #获取新excel的sheet对象18 sheet = new_book.get_sheet(0)19 #新增一列数据20 sheet.write(0, 3, '更新')21 #更新第4行第1列的值,将其修改为'郭静',修改的数据类型为str22 sheet.write(4, 1, '郭静')23 #保存更改后的excel,以前的excel数据不更改24 new_book.save('student.xls')위 내용은 간단한 엑셀 연산입니다~~
위 내용은 Excel을 이용한 Python 연산에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7677
7677
 15
1393
52
1207
24
91
11
73
19
15
1393
52
1207
24
91
11
73
19

 PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP는 주로 절차 적 프로그래밍이지만 객체 지향 프로그래밍 (OOP)도 지원합니다. Python은 OOP, 기능 및 절차 프로그래밍을 포함한 다양한 패러다임을 지원합니다. PHP는 웹 개발에 적합하며 Python은 데이터 분석 및 기계 학습과 같은 다양한 응용 프로그램에 적합합니다.
 PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP는 웹 개발 및 빠른 프로토 타이핑에 적합하며 Python은 데이터 과학 및 기계 학습에 적합합니다. 1.PHP는 간단한 구문과 함께 동적 웹 개발에 사용되며 빠른 개발에 적합합니다. 2. Python은 간결한 구문을 가지고 있으며 여러 분야에 적합하며 강력한 라이브러리 생태계가 있습니다.
 Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
VS 코드는 파이썬을 작성하는 데 사용될 수 있으며 파이썬 애플리케이션을 개발하기에 이상적인 도구가되는 많은 기능을 제공합니다. 사용자는 다음을 수행 할 수 있습니다. Python 확장 기능을 설치하여 코드 완료, 구문 강조 및 디버깅과 같은 기능을 얻습니다. 디버거를 사용하여 코드를 단계별로 추적하고 오류를 찾아 수정하십시오. 버전 제어를 위해 git을 통합합니다. 코드 서식 도구를 사용하여 코드 일관성을 유지하십시오. 라인 도구를 사용하여 잠재적 인 문제를 미리 발견하십시오.
 Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python은 부드러운 학습 곡선과 간결한 구문으로 초보자에게 더 적합합니다. JavaScript는 가파른 학습 곡선과 유연한 구문으로 프론트 엔드 개발에 적합합니다. 1. Python Syntax는 직관적이며 데이터 과학 및 백엔드 개발에 적합합니다. 2. JavaScript는 유연하며 프론트 엔드 및 서버 측 프로그래밍에서 널리 사용됩니다.
 Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
VS 코드는 Windows 8에서 실행될 수 있지만 경험은 크지 않을 수 있습니다. 먼저 시스템이 최신 패치로 업데이트되었는지 확인한 다음 시스템 아키텍처와 일치하는 VS 코드 설치 패키지를 다운로드하여 프롬프트대로 설치하십시오. 설치 후 일부 확장은 Windows 8과 호환되지 않을 수 있으며 대체 확장을 찾거나 가상 시스템에서 새로운 Windows 시스템을 사용해야합니다. 필요한 연장을 설치하여 제대로 작동하는지 확인하십시오. Windows 8에서는 VS 코드가 가능하지만 더 나은 개발 경험과 보안을 위해 새로운 Windows 시스템으로 업그레이드하는 것이 좋습니다.
 VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VS 코드 확장은 악의적 인 코드 숨기기, 취약성 악용 및 합법적 인 확장으로 자위하는 등 악성 위험을 초래합니다. 악의적 인 확장을 식별하는 방법에는 게시자 확인, 주석 읽기, 코드 확인 및주의해서 설치가 포함됩니다. 보안 조치에는 보안 인식, 좋은 습관, 정기적 인 업데이트 및 바이러스 백신 소프트웨어도 포함됩니다.
 PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP는 1994 년에 시작되었으며 Rasmuslerdorf에 의해 개발되었습니다. 원래 웹 사이트 방문자를 추적하는 데 사용되었으며 점차 서버 측 스크립팅 언어로 진화했으며 웹 개발에 널리 사용되었습니다. Python은 1980 년대 후반 Guidovan Rossum에 의해 개발되었으며 1991 년에 처음 출시되었습니다. 코드 가독성과 단순성을 강조하며 과학 컴퓨팅, 데이터 분석 및 기타 분야에 적합합니다.
 터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
vs 코드에서는 다음 단계를 통해 터미널에서 프로그램을 실행할 수 있습니다. 코드를 준비하고 통합 터미널을 열어 코드 디렉토리가 터미널 작업 디렉토리와 일치하는지 확인하십시오. 프로그래밍 언어 (예 : Python의 Python Your_file_name.py)에 따라 실행 명령을 선택하여 성공적으로 실행되는지 여부를 확인하고 오류를 해결하십시오. 디버거를 사용하여 디버깅 효율을 향상시킵니다.
