

Pandas 데이터 처리 예시 표시: 글로벌 상장 기업 데이터 수집
현재 Forbes의 2016년 글로벌 2000대 상장 기업 목록에 데이터가 있지만 원본 데이터는 표준화되지 않았으며 추가 사용 전에 처리가 필요합니다.
이 글에서는 실제 사례를 통해 데이터 구성에 팬더를 사용하는 방법을 소개합니다.
평소와 같이 먼저 내 운영 환경에 대해 이야기하겠습니다.
windows 7, 64-bit
python 3.5
pandas 버전 0.19.2
원본을 받은 후 데이터, 우리가 먼저 데이터를 살펴보고 어떤 데이터 결과가 필요한지 생각해 봅시다.
원시 데이터는 다음과 같습니다.
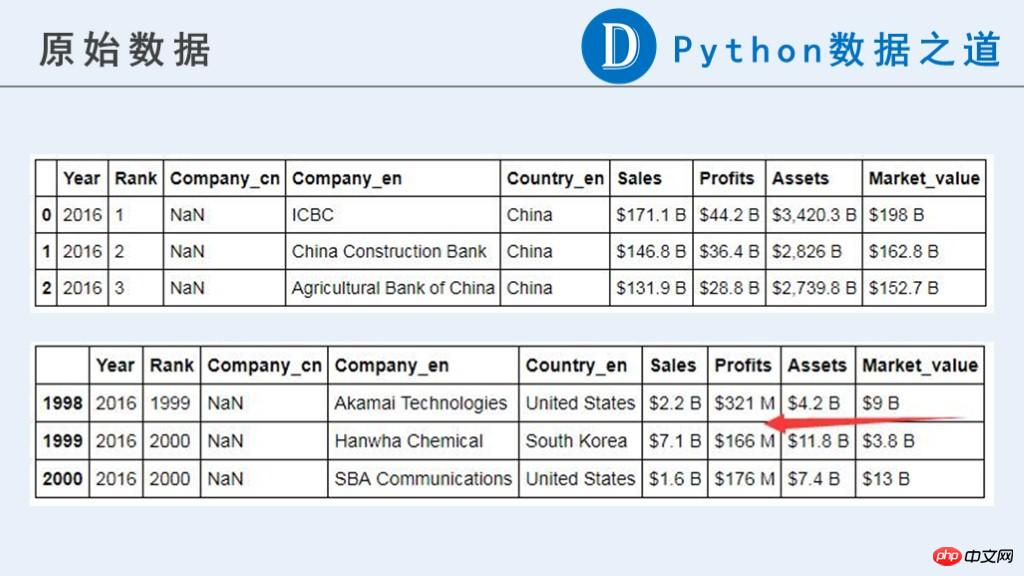
이 문서에서는 향후 사용을 위해 다음과 같은 예비 결과가 필요합니다.
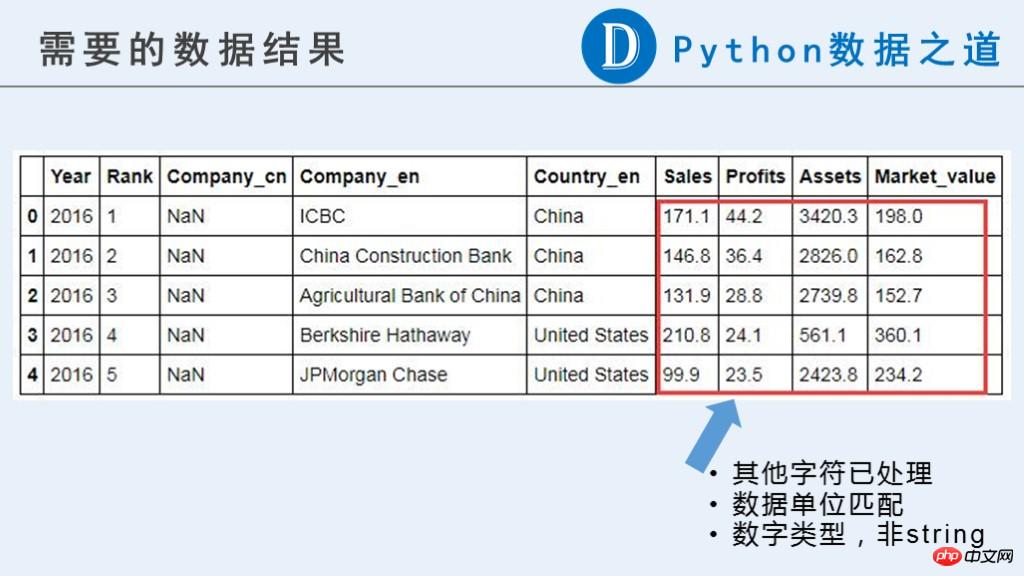
원래 데이터에서 기업과 관련된 데이터("매출", "이익", "자산", "시장_가치")는 현재 계산에 사용할 수 있는 숫자 유형이 아닌 것을 볼 수 있습니다.
원본 콘텐츠에는 통화 기호 "$", "-", 순수 문자로 구성된 문자열, 기타 비정상으로 간주되는 정보가 포함되어 있습니다. 게다가 이러한 데이터의 단위는 일관성이 없습니다. "B"(Billion, 10억)와 "M"(Million, 100만)으로 표시됩니다. 후속 계산 전에 단위 통일이 필요합니다.
1 처리 방법 Method-1
가장 먼저 떠오르는 처리 아이디어는 데이터 정보를 수십억('B')과 수백만('M')으로 분할하여 별도로 처리한 후 최종적으로 하나로 합치는 것입니다. 과정은 다음과 같습니다.
데이터 로드 및 열 이름 추가
import pandas as pd
df_2016 = pd.read_csv('data_2016.csv', encoding='gbk',header=None)# 更新列名df_2016.columns = ['Year', 'Rank', 'Company_cn','Company_en', 'Country_en', 'Sales', 'Profits', 'Assets', 'Market_value']
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head(3)데이터를 수십억('B') 단위로 가져오기
# 数据单位为 B的数据(Billion,十亿)df_2016_b = df_2016[df_2016['Sales'].str.endswith('B')]
print(df_2016_b.shape)
df_2016_b데이터를 수백만('M') 단위로 가져오기
# 数据单位为 M的数据(Million,百万)df_2016_m = df_2016[df_2016['Sales'].str.endswith('M')]
print(df_2016_m.shape)
df_2016_m이 방법은 비교적 이해하기 쉽지만 조작이 더 번거롭고, 특히 처리할 데이터 열이 많은 경우 시간이 많이 걸립니다.
여기서는 추가 처리에 대해 설명하지 않겠습니다. 물론 이 방법을 시도해 볼 수도 있습니다.
다음은 조금 더 간단한 방법입니다.
2 처리 방법 방법-2
2.1 데이터 로드
첫 번째 단계는 방법-1과 동일하게 데이터를 로드하는 것입니다.
다음은 'Sales' 열을 처리하는 방법입니다
2.2 관련 이상 문자 대체
먼저 달러 통화 기호 '$', 순수 알파벳 문자열 'undefine', '' 등 해당 이상 문자를 대체합니다. 비'. 여기서는 데이터 단위를 수십억 단위로 균일하게 구성하여 'B'를 직접 교체할 수 있도록 합니다. 그리고 'M'에는 더 많은 처리 단계가 필요합니다.
2.3 'M' 관련 데이터 처리
수백만 개의 "M" 단위가 포함된 데이터, 즉 "M"으로 끝나는 데이터를 처리하는 방법은 다음과 같습니다.
(1) 검색 조건 마스크를 설정합니다. ( 2) 문자열 "M"을 null 값으로 바꿉니다.
(3)用pd.to_numeric()转换为数字
(4)除以1000,转换为十亿美元,与其他行的数据一致
上面两个步骤相关的代码如下:
# 替换美元符号df_2016['Sales'] = df_2016['Sales'].str.replace('$','')# # 查看异常值,均为字母(“undefined”)# df_2016[df_2016['Sales'].str.isalpha()]# 替换异常值“undefined”为空白# df_2016['Sales'] = df_2016['Sales'].str.replace('undefined','')df_2016['Sales'] = df_2016['Sales'].str.replace('^[A-Za-z]+$','')# 替换符号十亿美元“B”为空白,数字本身代表的就是十亿美元为单位df_2016['Sales'] = df_2016['Sales'].str.replace('B','')# 处理含有百万“M”为单位的数据,即以“M”结尾的数据# 思路:# (1)设定查找条件mask;# (2)替换字符串“M”为空值# (3)用pd.to_numeric()转换为数字# (4)除以1000,转换为十亿美元,与其他行的数据一致mask = df_2016['Sales'].str.endswith('M')
df_2016.loc[mask, 'Sales'] = pd.to_numeric(df_2016.loc[mask, 'Sales'].str.replace('M', ''))/1000df_2016['Sales'] = pd.to_numeric(df_2016['Sales'])
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head(3)用同样类似的方法处理其他列
可以看到,这个方法比第一种方法还是要方便很多。当然,这个方法针对DataFrame的每列数据都要进行相关的操作,如果列数多了,也还是比较繁琐的。
有没有更方便一点的方法呢。 答案是有的。
插播一条硬广:技术文章转发太多。文章来自微信公众号“Python数据之道”(ID:PyDataRoad)。
3 处理方法 Method-3
在Method-2的基础上,将处理方法写成更通用的数据处理函数,根据数据的结构,拓展更多的适用性,则可以比较方便的处理相关数据。
3.1 加载数据
第一步还是加载数据,跟Method-1是一样的。
3.2 编写数据处理的自定义函数
参考Method-2的处理过程,编写数据处理的自定义函数’pro_col’,并在Method-2的基础上拓展其他替换功能,使之适用于这四列数据(“Sales”,“Profits”,“Assets”,“Market_value”)。
函数编写的代码如下:
def pro_col(df, col): # 替换相关字符串,如有更多的替换情形,可以自行添加df[col] = df[col].str.replace('$','')
df[col] = df[col].str.replace('^[A-Za-z]+$','')
df[col] = df[col].str.replace('B','')# 注意这里是'-$',即以'-'结尾,而不是'-',因为有负数df[col] = df[col].str.replace('-$','')
df[col] = df[col].str.replace(',','')# 处理含有百万“M”为单位的数据,即以“M”结尾的数据# 思路:# (1)设定查找条件mask;# (2)替换字符串“M”为空值# (3)用pd.to_numeric()转换为数字# (4)除以1000,转换为十亿美元,与其他行的数据一致mask = df[col].str.endswith('M')
df.loc[mask, col] = pd.to_numeric(df.loc[mask, col].str.replace('M',''))/1000# 将字符型的数字转换为数字类型df[col] = pd.to_numeric(df[col])return df3.3 将自定义函数进行应用
针对DataFrame的每列,应用该自定义函数,进行数据处理,得到需要的结果。
pro_col(df_2016, 'Sales')
pro_col(df_2016, 'Profits')
pro_col(df_2016, 'Assets')
pro_col(df_2016, 'Market_value')
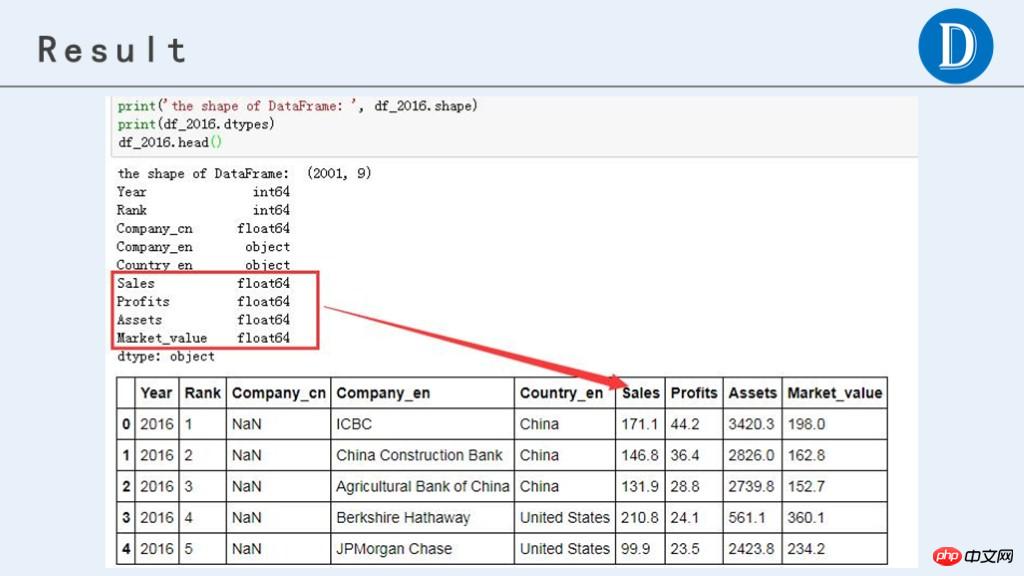
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head()当然,如果DataFrame的列数特别多,可以用for循环,这样代码更简洁。代码如下:
cols = ['Sales', 'Profits', 'Assets', 'Market_value']for col in cols:
pro_col(df_2016, col)
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head()最终处理后,获得的数据结果如下:
위 내용은 Pandas 데이터 처리 예시 표시: 글로벌 상장 기업 데이터 수집의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7322
7322
 9
1625
14
1350
46
1262
25
1209
29
9
1625
14
1350
46
1262
25
1209
29

 일반적인 Pandas 설치 문제 해결: 설치 오류에 대한 해석 및 해결 방법
Feb 19, 2024 am 09:19 AM
일반적인 Pandas 설치 문제 해결: 설치 오류에 대한 해석 및 해결 방법
Feb 19, 2024 am 09:19 AM
Pandas 설치 튜토리얼: 일반적인 설치 오류 및 해결 방법 분석, 구체적인 코드 예제가 필요합니다. 소개: Pandas는 데이터 정리, 데이터 처리 및 데이터 시각화에 널리 사용되는 강력한 데이터 분석 도구이므로 현장에서 높은 평가를 받고 있습니다. 데이터 과학의 . 그러나 환경 구성 및 종속성 문제로 인해 Pandas를 설치할 때 몇 가지 어려움과 오류가 발생할 수 있습니다. 이 기사에서는 Pandas 설치 튜토리얼을 제공하고 몇 가지 일반적인 설치 오류와 해결 방법을 분석합니다. 1. 팬더 설치
 Pandas를 사용하여 txt 파일을 올바르게 읽는 방법
Jan 19, 2024 am 08:39 AM
Pandas를 사용하여 txt 파일을 올바르게 읽는 방법
Jan 19, 2024 am 08:39 AM
Pandas를 사용하여 txt 파일을 올바르게 읽으려면 특정 코드 예제가 필요합니다. Pandas는 널리 사용되는 Python 데이터 분석 라이브러리로 CSV 파일, Excel 파일, SQL 데이터베이스 등을 포함하여 다양한 데이터 유형을 처리하는 데 사용할 수 있습니다. 동시에 txt 파일과 같은 텍스트 파일을 읽는 데에도 사용할 수 있습니다. 그러나 txt 파일을 읽을 때 인코딩 문제, 구분 기호 문제 등과 같은 몇 가지 문제가 발생할 수 있습니다. 이 기사에서는 팬더를 사용하여 txt를 올바르게 읽는 방법을 소개합니다.
 Pandas를 사용하여 txt 파일을 읽는 실용적인 팁
Jan 19, 2024 am 09:49 AM
Pandas를 사용하여 txt 파일을 읽는 실용적인 팁
Jan 19, 2024 am 09:49 AM
Pandas를 사용하여 txt 파일을 읽는 실용적인 팁, 데이터 분석 및 데이터 처리에서 txt 파일은 일반적인 데이터 형식입니다. Pandas를 사용하여 txt 파일을 읽으면 빠르고 편리한 데이터 처리가 가능합니다. 이 기사에서는 특정 코드 예제와 함께 pandas를 사용하여 txt 파일을 더 잘 읽는 데 도움이 되는 몇 가지 실용적인 기술을 소개합니다. 구분 기호가 있는 txt 파일 읽기 팬더를 사용하여 구분 기호가 있는 txt 파일을 읽을 때 read_c를 사용할 수 있습니다.
 Pandas의 효율적인 데이터 중복 제거 방법 공개: 중복 데이터를 빠르게 제거하는 팁
Jan 24, 2024 am 08:12 AM
Pandas의 효율적인 데이터 중복 제거 방법 공개: 중복 데이터를 빠르게 제거하는 팁
Jan 24, 2024 am 08:12 AM
Pandas 중복 제거 방법의 비밀: 데이터를 중복 제거하는 빠르고 효율적인 방법으로, 데이터 분석 및 처리 과정에서 데이터 중복이 자주 발생합니다. 중복된 데이터는 분석 결과를 오도할 수 있으므로 중복 제거는 매우 중요한 단계입니다. 강력한 데이터 처리 라이브러리인 Pandas는 데이터 중복 제거를 달성하기 위한 다양한 방법을 제공합니다. 이 기사에서는 일반적으로 사용되는 중복 제거 방법을 소개하고 특정 코드 예제를 첨부합니다. 단일 컬럼 기반 중복 제거의 가장 일반적인 경우는 특정 컬럼의 값이 중복되는지 여부에 따른 것입니다.
 Golang은 데이터 처리 효율성을 어떻게 향상시키나요?
May 08, 2024 pm 06:03 PM
Golang은 데이터 처리 효율성을 어떻게 향상시키나요?
May 08, 2024 pm 06:03 PM
Golang은 동시성, 효율적인 메모리 관리, 기본 데이터 구조 및 풍부한 타사 라이브러리를 통해 데이터 처리 효율성을 향상시킵니다. 구체적인 장점은 다음과 같습니다. 병렬 처리: 코루틴은 동시에 여러 작업 실행을 지원합니다. 효율적인 메모리 관리: 가비지 수집 메커니즘이 자동으로 메모리를 관리합니다. 효율적인 데이터 구조: 슬라이스, 맵, 채널과 같은 데이터 구조는 데이터에 빠르게 액세스하고 처리합니다. 타사 라이브러리: fasthttp 및 x/text와 같은 다양한 데이터 처리 라이브러리를 포함합니다.
 PythonPandas 설치 가이드: 이해하기 쉽고 작동하기 쉽습니다.
Jan 24, 2024 am 09:39 AM
PythonPandas 설치 가이드: 이해하기 쉽고 작동하기 쉽습니다.
Jan 24, 2024 am 09:39 AM
간단하고 이해하기 쉬운 PythonPandas 설치 가이드 PythonPandas는 유연하고 사용하기 쉬운 데이터 구조와 데이터 분석 도구를 제공하는 강력한 데이터 조작 및 분석 라이브러리이며 Python 데이터 분석을 위한 중요한 도구 중 하나입니다. 이 기사에서는 Pandas를 빠르게 설치하는 데 도움이 되는 간단하고 이해하기 쉬운 PythonPandas 설치 가이드를 제공하고, 쉽게 시작할 수 있도록 특정 코드 예제를 첨부합니다. Python 설치 Pandas를 설치하기 전에 먼저 다음을 수행해야 합니다.
 Redis를 사용하여 Laravel 애플리케이션의 데이터 처리 효율성 향상
Mar 06, 2024 pm 03:45 PM
Redis를 사용하여 Laravel 애플리케이션의 데이터 처리 효율성 향상
Mar 06, 2024 pm 03:45 PM
Redis를 사용하여 Laravel 애플리케이션의 데이터 처리 효율성을 향상하세요. 인터넷 애플리케이션의 지속적인 개발로 인해 데이터 처리 효율성은 개발자의 초점 중 하나가 되었습니다. Laravel 프레임워크를 기반으로 애플리케이션을 개발할 때 Redis를 사용하여 데이터 처리 효율성을 향상하고 데이터에 대한 빠른 액세스 및 캐싱을 달성할 수 있습니다. 이 글에서는 Laravel 애플리케이션에서 데이터 처리를 위해 Redis를 사용하는 방법을 소개하고 구체적인 코드 예제를 제공합니다. 1. Redis 소개 Redis는 고성능 메모리 데이터입니다.
 Laravel과 CodeIgniter의 데이터 처리 기능은 어떻게 비교됩니까?
Jun 01, 2024 pm 01:34 PM
Laravel과 CodeIgniter의 데이터 처리 기능은 어떻게 비교됩니까?
Jun 01, 2024 pm 01:34 PM
Laravel과 CodeIgniter의 데이터 처리 기능을 비교해 보세요. ORM: Laravel은 클래스-객체 관계형 매핑을 제공하는 EloquentORM을 사용하는 반면, CodeIgniter는 데이터베이스 모델을 PHP 클래스의 하위 클래스로 표현하기 위해 ActiveRecord를 사용합니다. 쿼리 빌더: Laravel에는 유연한 체인 쿼리 API가 있는 반면, CodeIgniter의 쿼리 빌더는 더 간단하고 배열 기반입니다. 데이터 검증: Laravel은 사용자 정의 검증 규칙을 지원하는 Validator 클래스를 제공하는 반면, CodeIgniter는 내장된 검증 기능이 적고 사용자 정의 규칙을 수동으로 코딩해야 합니다. 실제 사례: 사용자 등록 예시에서는 Lar를 보여줍니다.
