

Beautifulsoup과 Selenium의 사용법에 대한 간략한 소개
Beautifulsoup 및 Selenium의 간단한 사용
요청 라이브러리 검토
저는 요청을 오랫동안 사용하지 않았습니다. 나중에 간단한 크롤러를 작성할 것이므로 조금만 작성하겠습니다. 검토. requests了,因为一会儿要写个简单的爬虫,所以还是随便写一点复习下。
import requests r = requests.get('https://api.github.com/user', auth=('haiyu19931121@163.com', 'Shy18137803170'))print(r.status_code) # 状态码200print(r.json()) # 返回json格式print(r.text) # 返回文本print(r.headers) # 头信息print(r.encoding) # 编码方式,一般utf-8# 当写入文件比较大时,避免内存耗尽,可以一次写指定的字节数或者一行。# 一次读一行,chunk_size=512为默认值for chunk in r.iter_lines():print(chunk)# 一次读取一块,大小为512for chunk in r.iter_content(chunk_size=512):print(chunk)
注意iter_lines和iter_content返回的都是字节数据,若要写入文件,不管是文本还是图片,都需要以wb的方式打开。
Beautifulsoup的使用
进入正题,早就听说这个著名的库,以前写爬虫用正则表达式虽然不麻烦,但有时候会匹配不准确。使用Beautifulsoup可以准确从HTML标签中提取数据。虽然是慢了点,但是简单好使呀。
from bs4 import BeautifulSoup html_doc = """<html><head><title>The Dormouse's story</title></head><body><p class="title"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;and they lived at the bottom of a well.</p><p class="story">...</p>"""# 就注意一点,第二个参数指定解析器,必须填上,不然会有警告。推荐使用lxmlsoup = BeautifulSoup(html_doc, 'lxml')
紧接着上面的代码,看下面一些简单的操作。使用点属性的行为,会得到第一个查找到的符合条件的数据。是find方法的简写。
soup.a soup.find('p')
上面的两句是等价的。
# soup.body是一个Tag对象。是body标签中所有html代码print(soup.body)
<body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> </body>
# 获取body里所有文本,不含标签print(soup.body.text)# 等同于下面的写法soup.body.get_text()# 还可以这样写,strings是所有文本的生成器for string in soup.body.strings:print(string, end='')
The Dormouse's story Once upon a time there were three little sisters; and their names were Elsie, Lacie and Tillie; and they lived at the bottom of a well. ...
# 获得该标签里的文本。print(soup.title.string)
The Dormouse's story
# Tag对象的get方法可以根据属性的名称获得属性的值,此句表示得到第一个p标签里class属性的值print(soup.p.get('class'))# 和下面的写法等同print(soup.p['class'])
['title']
# 查看a标签的所有属性,以字典形式给出print(soup.a.attrs)
{'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}# 标签的名称soup.title.name
title
find_all
使用最多的当属find_all / find方法了吧,前者查找所有符合条件的数据,返回一个列表。后者则是这个列表中的第一个数据。find_all有一个limit参数,限制列表的长度(即查找符合条件的数据的个数)。当limit=1其实就成了find方法 。
find_all同样有简写方法。
soup.find_all('a', id='link1') soup('a', id='link1')
上面两种写法是等价的,第二种写法便是简写。
find_all(self, name=None, attrs={}, recursive=True, text=None,
limit=None, **kwargs)name
name就是想要搜索的标签,比如下面就是找到所有的p标签。不仅能填入字符串,还能传入正则表达式、列表、函数、True。
传入True的话,就没有限制,什么都查找了。
recursive
调用tag的 find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点,如果只想搜索tag的直接子节点,可以使用参数 recursive=False 。
# title不是html的直接子节点,但是会检索其下所有子孙节点soup.html.find_all("title")# [The Dormouse's story ]# 参数设置为False,只会找直接子节点soup.html.find_all("title", recursive=False)# []# title就是head的直接子节点,所以这个参数此时无影响a = soup.head.find_all("title", recursive=False)# [The Dormouse's story ]keyword和attrs
使用keyword,加上一个或者多个限定条件,缩小查找范围。
# 查看所有id为link1的p标签soup.find_all('a', id='link1')
如果按类查找,由于class关键字Python已经使用。可以用class_,或者不指定关键字,又或者使用attrs填入字典。
soup.find_all('p', class_='story')
soup.find_all('p', 'story')
soup.find_all('p', attrs={"class": "story"})上面三种方法等价。class_可以接受字符串、正则表达式、函数、True。
text
搜索文本值,好像使用string参数也是一样的结果。
a = soup.find_all(text='Elsie')# 或者,4.4以上版本请使用texta = soup.find_all(string='Elsie')
text参数也可以接受字符串、正则表达式、True、列表。
CSS选择器
还能使用CSS选择器呢。使用select方法就好了,select始终返回一个列表。
列举几个常用的操作。
# 所有div标签soup.select('div')# 所有id为username的元素soup.select('.username')# 所有class为story的元素soup.select('#story')# 所有div元素之内的span元素,中间可以有其他元素soup.select('div span')# 所有div元素之内的span元素,中间没有其他元素soup.select('div > span')# 所有具有一个id属性的input标签,id的值无所谓soup.select('input[id]')# 所有具有一个id属性且值为user的input标签soup.select('input[id="user"]')# 搜索多个,class为link1或者link2的元素都符合soup.select("#link1, #link2")一个爬虫小例子
上面介绍了requests和beautifulsoup4的基本用法,使用这些已经可以写一些简单的爬虫了。来试试吧。
此例子来自《Python编程快速上手——让繁琐的工作自动化》[美] AI Sweigart
这个爬虫会批量下载XKCD漫画网的图片,可以指定下载的页面数。
import osimport requestsfrom bs4 import BeautifulSoup# exist_ok=True,若文件夹已经存在也不会报错os.makedirs('xkcd')
url = 'https://xkcd.com/'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/57.0.2987.98 Safari/537.36'}def save_img(img_url, limit=1):
r = requests.get(img_url, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')try:
img = 'https:' + soup.find('div', id='comic').img.get('src')except AttributeError:print('Image Not Found')else:print('Downloading', img)
response = requests.get(img, headers=headers)with open(os.path.join('xkcd', os.path.basename(img)), 'wb') as f:for chunk in response.iter_content(chunk_size=1024*1024):
f.write(chunk)# 每次下载一张图片,就减1limit -= 1# 找到上一张图片的网址if limit > 0:try:
prev = 'https://xkcd.com' + soup.find('a', rel='prev').get('href')except AttributeError:print('Link Not Exist')else:
save_img(prev, limit)if __name__ == '__main__':
save_img(url, limit=20)print('Done!')Downloading Downloading Downloading Downloading Downloading Downloading Downloading Downloading Downloading ... Done!
多线程下载
单线程的速度有点慢,比如可以使用多线程,由于我们在获取prev的时候,知道了每个网页的网址是很有规律的。它像这样。只是最后的数字不一样,所以我们可以很方便地使用range
import osimport threadingimport requestsfrom bs4 import BeautifulSoup
os.makedirs('xkcd')
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/57.0.2987.98 Safari/537.36'}def download_imgs(start, end):for url_num in range(start, end):
img_url = 'https://xkcd.com/' + str(url_num)
r = requests.get(img_url, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')try:
img = 'https:' + soup.find('div', id='comic').img.get('src')except AttributeError:print('Image Not Found')else:print('Downloading', img)
response = requests.get(img, headers=headers)with open(os.path.join('xkcd', os.path.basename(img)), 'wb') as f:for chunk in response.iter_content(chunk_size=1024 * 1024):
f.write(chunk)if __name__ == '__main__':# 下载从1到30,每个线程下载10个threads = []for i in range(1, 30, 10):
thread_obj = threading.Thread(target=download_imgs, args=(i, i + 10))
threads.append(thread_obj)
thread_obj.start()# 阻塞,等待线程执行结束都会等待for thread in threads:
thread.join()# 所有线程下载完毕,才打印print('Done!')iter_lines 및 iter_content는 텍스트이든 이미지이든 파일을 작성하려면 다음을 수행해야 합니다. < 코드>wb 모드에서 열기로 시작하세요. 🎜🎜Using Beautifulsoup🎜🎜 본론으로 들어가겠습니다. 예전부터 이 유명한 라이브러리에 대해 들어본 적이 있습니다. 예전에는 크롤러를 작성할 때 정규식을 사용하는 것이 번거롭지 않았지만 때로는 일치가 정확하지 않을 수도 있었습니다. . Beautifulsoup를 사용하여 HTML 태그에서 데이터를 정확하게 추출하세요. 조금 느리기는 하지만 간단하고 사용하기 쉽습니다. 🎜🎜from selenium import webdriverfrom selenium.webdriver.common.keys import Keysimport time browser = webdriver.Chrome()# Chrome打开百度首页browser.get('https://www.baidu.com/')# 找到输入区域input_area = browser.find_element_by_id('kw')# 区域内填写内容input_area.send_keys('The Zen of Python')# 找到"百度一下"search = browser.find_element_by_id('su')# 点击search.click()# 或者按下回车# input_area.send_keys('The Zen of Python', Keys.ENTER)time.sleep(3) browser.get('https://www.zhihu.com/') time.sleep(2)# 返回到百度搜索browser.back() time.sleep(2)# 退出浏览器browser.quit()
find 메소드의 약어입니다. 🎜🎜browser.back() # 返回按钮browser.forward() # 前进按钮browser.refresh() # 刷新按钮browser.close() # 关闭当前窗口browser.quit() # 退出浏览器
browser = webdriver.Chrome() browser.get('https://passport.csdn.net/account/login') browser.find_element_by_id('username').send_keys('haiyu19931121@163.com') browser.find_element_by_id('password').send_keys('**********') browser.find_element_by_class_name('logging').click()
find_all
🎜가장 많이 사용되는 방법은 의심할 여지 없이find_all입니다. /찾기</code > method 글쎄, 전자는 조건에 맞는 데이터를 모두 찾아서 리스트를 돌려주는 방식이다. 후자가 이 목록의 첫 번째 데이터입니다. <strong><code>find_all에는 목록의 길이(즉, 발견된 조건을 충족하는 데이터의 수)를 제한하는 limit 매개변수가 있습니다. limit=1이면 실제로 find 메서드가 됩니다. 🎜🎜find_all에는 단축 메서드도 있습니다. 🎜🎜rrreee🎜🎜위의 두 가지 쓰기 방법은 동일하며, 두 번째 쓰기 방법은 약어입니다. 🎜rrreeename
🎜name은 검색하려는 태그입니다. 예를 들어 다음은 모든 p 태그를 찾는 것입니다. 문자열을 채울 수 있을 뿐만 아니라 정규식, 목록, 함수 및 True를 전달할 수도 있습니다. 🎜🎜rrreee🎜🎜True를 전달하면 제한이 없으며 모든 항목이 검색됩니다. 🎜재귀
🎜태그의find_all() 메서드를 호출하면 BeautifulSoup은 현재 태그의 모든 하위 노드를 검색합니다. 태그에는 recursive=False 매개변수를 사용할 수 있습니다. 🎜🎜rrreee🎜키워드 및 속성
🎜키워드를 사용하고 하나 이상의 한정어를 추가하여 검색 범위를 좁히세요. 🎜🎜rrreee🎜🎜클래스로 검색하면 Python에서는 class 키워드 때문에 이미 사용하고 있습니다.class_를 사용하거나 키워드를 지정하지 않거나 attrs를 사용하여 사전을 채울 수 있습니다. 🎜🎜rrreee🎜🎜위의 세 가지 방법은 동일합니다. class_는 문자열, 정규식, 함수 및 True를 허용할 수 있습니다. 🎜text
🎜text 값을 검색해 보니 문자열 매개변수를 사용해도 같은 결과가 나오는 것 같습니다. 🎜🎜rrreee🎜🎜text 매개변수는 문자열, 정규 표현식, True 및 목록도 허용할 수 있습니다. 🎜CSS 선택기
🎜CSS 선택기를 사용할 수도 있습니다. select 메소드를 사용하면 select는 항상 목록을 반환합니다. 🎜🎜몇 가지 일반적인 작업을 나열해 보세요. 🎜🎜rrreee🎜🎜작은 크롤러 예🎜🎜요청 및 beautifulsoup4의 기본 사용법은 위에 소개되어 있습니다. 이를 사용하면 이미 몇 가지 간단한 크롤러를 작성할 수 있습니다. 와서 시도해 보세요. 🎜🎜이 예는 "Python 프로그래밍으로 빠르게 시작하기 - 번거로운 작업 자동화"에서 가져온 것입니다. [미국] AI Sweigart🎜🎜이 크롤러는 XKCD Comics Network에서 그림을 일괄 다운로드하며 숫자를 지정할 수 있습니다. 다운로드할 페이지 수. 🎜🎜rrreee🎜rrreee🎜멀티 스레드 다운로드🎜🎜싱글 스레드의 속도는 약간 느립니다. 예를 들어 멀티 스레드를 사용할 수 있습니다.
prev를 받으면 URL을 알 수 있기 때문입니다. 각 웹페이지의 내용은 매우 규칙적입니다. 이렇습니다. 마지막 숫자만 다르므로 range를 사용하여 쉽게 탐색할 수 있습니다. 🎜🎜rreee🎜来看下结果吧。
初步了解selenium
selenium用来作自动化测试。使用前需要下载驱动,我只下载了Firefox和Chrome的。网上随便一搜就能下载到了。接下来将下载下来的文件其复制到将安装目录下,比如Firefox,将对应的驱动程序放到C:\Program Files (x86)\Mozilla Firefox,并将这个路径添加到环境变量中,同理Chrome的驱动程序放到C:\Program Files (x86)\Google\Chrome\Application并将该路径添加到环境变量。最后重启IDE开始使用吧。
模拟百度搜索
下面这个例子会打开Chrome浏览器,访问百度首页,模拟输入The Zen of Python,随后点击百度一下,当然也可以用回车代替。Keys下是一些不能用字符串表示的键,比如方向键、Tab、Enter、Esc、F1~F12、Backspace等。然后等待3秒,页面跳转到知乎首页,接着返回到百度,最后退出(关闭)浏览器。
from selenium import webdriverfrom selenium.webdriver.common.keys import Keysimport time browser = webdriver.Chrome()# Chrome打开百度首页browser.get('https://www.baidu.com/')# 找到输入区域input_area = browser.find_element_by_id('kw')# 区域内填写内容input_area.send_keys('The Zen of Python')# 找到"百度一下"search = browser.find_element_by_id('su')# 点击search.click()# 或者按下回车# input_area.send_keys('The Zen of Python', Keys.ENTER)time.sleep(3) browser.get('https://www.zhihu.com/') time.sleep(2)# 返回到百度搜索browser.back() time.sleep(2)# 退出浏览器browser.quit()
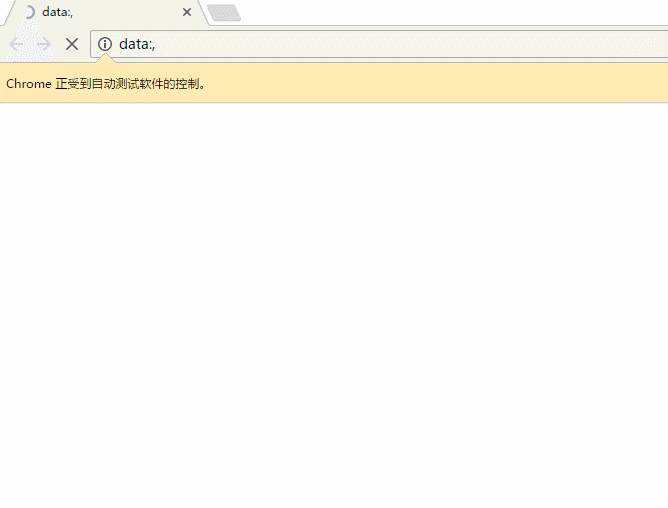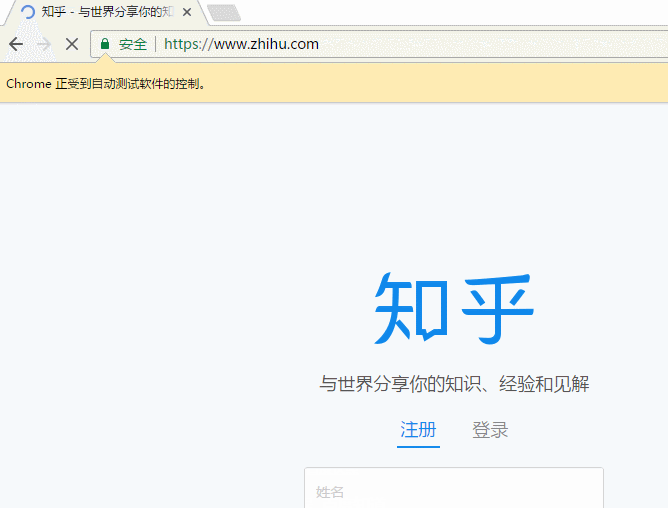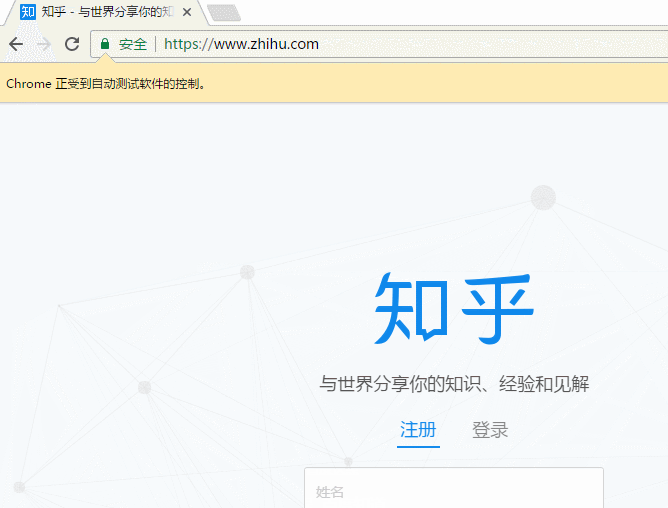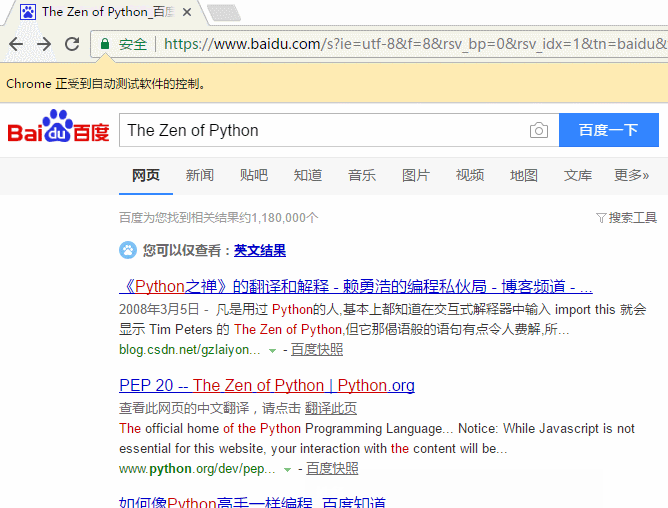
send_keys模拟输入内容。可以使用element的clear()方法清空输入。一些其他模拟点击浏览器按钮的方法如下
browser.back() # 返回按钮browser.forward() # 前进按钮browser.refresh() # 刷新按钮browser.close() # 关闭当前窗口browser.quit() # 退出浏览器
查找方法
以下列举常用的查找Element的方法。
| 方法名 | 返回的WebElement |
|---|---|
| find_element_by_id(id) | 匹配id属性值的元素 |
| find_element_by_name(name) | 匹配name属性值的元素 |
| find_element_by_class_name(name) | 匹配CSS的class值的元素 |
| find_element_by_tag_name(tag) | 匹配标签名的元素,如div |
| find_element_by_css_selector(selector) | 匹配CSS选择器 |
| find_element_by_xpath(xpath) | 匹配xpath |
| find_element_by_link_text(text) | 完全匹配提供的text的a标签 |
| find_element_by_partial_link_text(text) | 提供的text可以是a标签中文本中的一部分 |
登录CSDN
以下代码可以模拟输入账号密码,点击登录。整个过程还是很快的。
browser = webdriver.Chrome() browser.get('https://passport.csdn.net/account/login') browser.find_element_by_id('username').send_keys('haiyu19931121@163.com') browser.find_element_by_id('password').send_keys('**********') browser.find_element_by_class_name('logging').click()
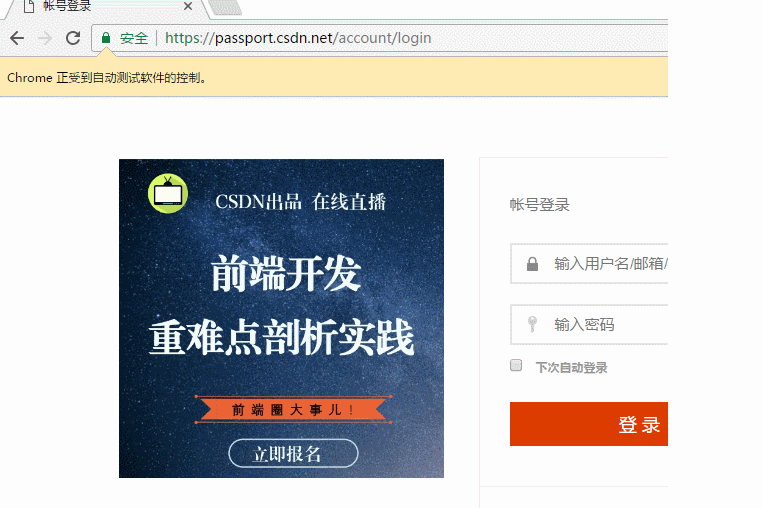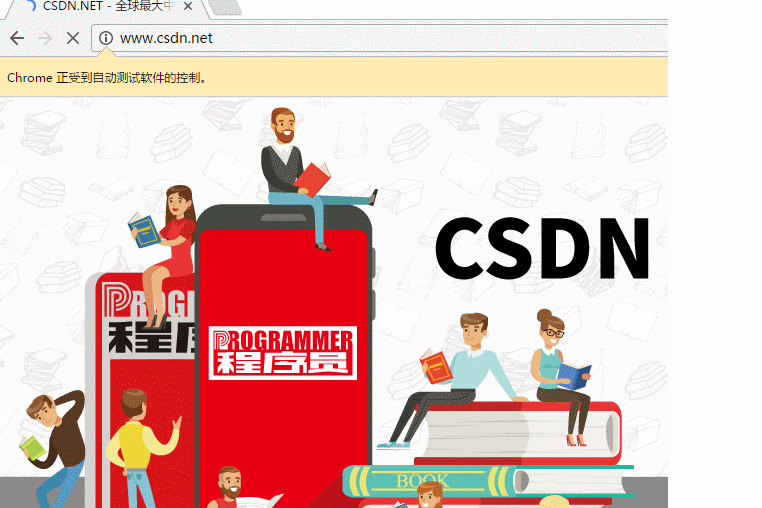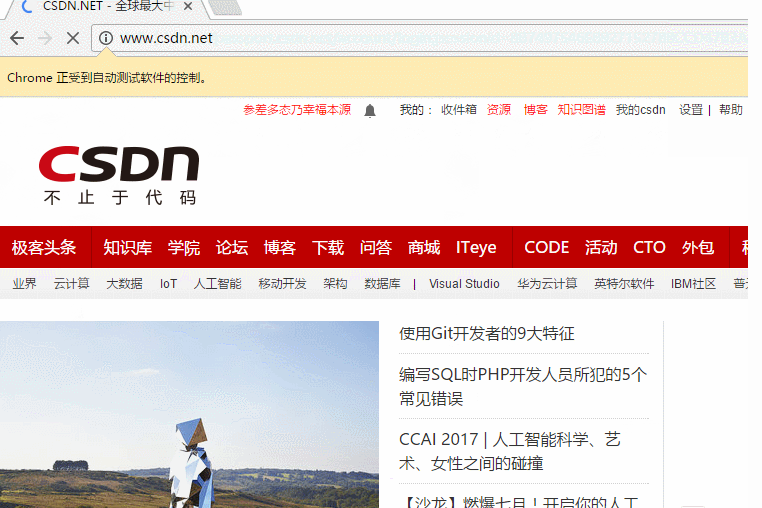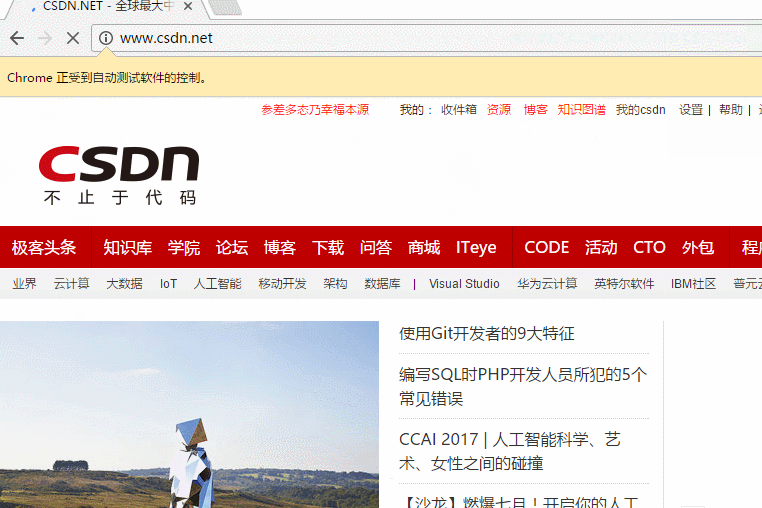
以上差不多都是API的罗列,其中有自己的理解,也有照搬官方文档的。
by @sunhaiyu
2017.7.13
위 내용은 Beautifulsoup과 Selenium의 사용법에 대한 간략한 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7554
7554
 15
1382
52
83
11
59
19
28
96
15
1382
52
83
11
59
19
28
96

 마그넷 링크 사용 방법
Feb 18, 2024 am 10:02 AM
마그넷 링크 사용 방법
Feb 18, 2024 am 10:02 AM
마그넷 링크는 리소스를 다운로드하기 위한 링크 방식으로, 기존 다운로드 방식보다 더 편리하고 효율적입니다. 마그넷 링크를 사용하면 중간 서버에 의존하지 않고 P2P 방식으로 리소스를 다운로드할 수 있습니다. 이번 글에서는 마그넷 링크의 사용법과 주의할 점을 소개하겠습니다. 1. 마그넷 링크란 무엇인가요? 마그넷 링크는 P2P(Peer-to-Peer) 프로토콜을 기반으로 한 다운로드 방식입니다. 마그넷 링크를 통해 사용자는 리소스 게시자에 직접 연결하여 리소스 공유 및 다운로드를 완료할 수 있습니다. 전통적인 다운로드 방법과 비교하여 자기
 mdf 및 mds 파일을 사용하는 방법
Feb 19, 2024 pm 05:36 PM
mdf 및 mds 파일을 사용하는 방법
Feb 19, 2024 pm 05:36 PM
mdf 파일, mds 파일 사용법 컴퓨터 기술의 지속적인 발전으로 우리는 다양한 방법으로 데이터를 저장하고 공유할 수 있게 되었습니다. 디지털 미디어 분야에서는 특별한 파일 형식을 자주 접하게 됩니다. 이 기사에서는 일반적인 파일 형식인 mdf 및 mds 파일에 대해 설명하고 사용 방법을 소개합니다. 먼저 mdf 파일과 mds 파일의 의미를 이해해야 합니다. mdf는 CD/DVD 이미지 파일의 확장자이고, mds 파일은 mdf 파일의 메타데이터 파일입니다.
 크리스탈디스크마크란 어떤 소프트웨어인가요? -크리스탈디스크마크는 어떻게 사용하나요?
Mar 18, 2024 pm 02:58 PM
크리스탈디스크마크란 어떤 소프트웨어인가요? -크리스탈디스크마크는 어떻게 사용하나요?
Mar 18, 2024 pm 02:58 PM
CrystalDiskMark는 순차 및 무작위 읽기/쓰기 속도를 빠르게 측정하는 하드 드라이브용 소형 HDD 벤치마크 도구입니다. 다음으로 편집자님에게 CrystalDiskMark 소개와 crystaldiskmark 사용법을 소개하겠습니다~ 1. CrystalDiskMark 소개 CrystalDiskMark는 기계식 하드 드라이브와 솔리드 스테이트 드라이브(SSD)의 읽기 및 쓰기 속도와 성능을 평가하는 데 널리 사용되는 디스크 성능 테스트 도구입니다. ). 무작위 I/O 성능. 무료 Windows 응용 프로그램이며 사용자 친화적인 인터페이스와 다양한 테스트 모드를 제공하여 하드 드라이브 성능의 다양한 측면을 평가하고 하드웨어 검토에 널리 사용됩니다.
 foobar2000을 어떻게 다운로드하나요? - foobar2000 사용법
Mar 18, 2024 am 10:58 AM
foobar2000을 어떻게 다운로드하나요? - foobar2000 사용법
Mar 18, 2024 am 10:58 AM
foobar2000은 언제든지 음악 리소스를 들을 수 있는 소프트웨어입니다. 모든 종류의 음악을 무손실 음질로 제공합니다. 음악 플레이어의 향상된 버전을 사용하면 더욱 포괄적이고 편안한 음악 경험을 얻을 수 있습니다. 컴퓨터에서 고급 오디오를 재생합니다. 이 장치는 보다 편리하고 효율적인 음악 재생 경험을 제공합니다. 인터페이스 디자인은 단순하고 명확하며 사용하기 쉽습니다. 또한 다양한 스킨과 테마를 지원하고, 자신의 선호도에 따라 설정을 개인화하며, 다양한 오디오 형식의 재생을 지원하는 전용 음악 플레이어를 생성합니다. 또한 볼륨을 조정하는 오디오 게인 기능도 지원합니다. 과도한 볼륨으로 인한 청력 손상을 방지하려면 자신의 청력 상태에 따라 조정하십시오. 다음엔 내가 도와줄게
 NetEase 메일박스 마스터를 사용하는 방법
Mar 27, 2024 pm 05:32 PM
NetEase 메일박스 마스터를 사용하는 방법
Mar 27, 2024 pm 05:32 PM
NetEase Mailbox는 중국 네티즌들이 널리 사용하는 이메일 주소로, 안정적이고 효율적인 서비스로 항상 사용자들의 신뢰를 얻어 왔습니다. NetEase Mailbox Master는 휴대폰 사용자를 위해 특별히 제작된 이메일 소프트웨어로 이메일 보내기 및 받기 프로세스를 크게 단순화하고 이메일 처리를 더욱 편리하게 만듭니다. 따라서 NetEase Mailbox Master를 사용하는 방법과 그 기능이 무엇인지 아래에서 이 사이트의 편집자가 자세한 소개를 제공하여 도움을 드릴 것입니다! 먼저, 모바일 앱스토어에서 NetEase Mailbox Master 앱을 검색하여 다운로드하실 수 있습니다. App Store 또는 Baidu Mobile Assistant에서 "NetEase Mailbox Master"를 검색한 후 안내에 따라 설치하세요. 다운로드 및 설치가 완료되면 NetEase 이메일 계정을 열고 로그인합니다. 로그인 인터페이스는 아래와 같습니다.
 Baidu Netdisk 앱 사용 방법
Mar 27, 2024 pm 06:46 PM
Baidu Netdisk 앱 사용 방법
Mar 27, 2024 pm 06:46 PM
오늘날 클라우드 스토리지는 우리의 일상 생활과 업무에 없어서는 안 될 부분이 되었습니다. 중국 최고의 클라우드 스토리지 서비스 중 하나인 Baidu Netdisk는 강력한 스토리지 기능, 효율적인 전송 속도 및 편리한 운영 경험으로 많은 사용자의 호감을 얻었습니다. 중요한 파일을 백업하고, 정보를 공유하고, 온라인으로 비디오를 시청하고, 음악을 듣고 싶은 경우 Baidu Cloud Disk는 귀하의 요구를 충족할 수 있습니다. 그러나 많은 사용자가 Baidu Netdisk 앱의 구체적인 사용 방법을 이해하지 못할 수 있으므로 이 튜토리얼에서는 Baidu Netdisk 앱 사용 방법을 자세히 소개합니다. Baidu 클라우드 네트워크 디스크 사용 방법: 1. 설치 먼저 Baidu Cloud 소프트웨어를 다운로드하고 설치할 때 사용자 정의 설치 옵션을 선택하십시오.
 BTCC 튜토리얼: BTCC 교환에서 MetaMask 지갑을 바인딩하고 사용하는 방법은 무엇입니까?
Apr 26, 2024 am 09:40 AM
BTCC 튜토리얼: BTCC 교환에서 MetaMask 지갑을 바인딩하고 사용하는 방법은 무엇입니까?
Apr 26, 2024 am 09:40 AM
MetaMask(중국어로 Little Fox Wallet이라고도 함)는 무료이며 호평을 받는 암호화 지갑 소프트웨어입니다. 현재 BTCC는 MetaMask 지갑에 대한 바인딩을 지원합니다. 바인딩 후 MetaMask 지갑을 사용하여 빠르게 로그인하고 가치를 저장하고 코인을 구매할 수 있으며 첫 바인딩에는 20 USDT 평가판 보너스도 받을 수 있습니다. BTCCMetaMask 지갑 튜토리얼에서는 MetaMask 등록 및 사용 방법, BTCC에서 Little Fox 지갑을 바인딩하고 사용하는 방법을 자세히 소개합니다. MetaMask 지갑이란 무엇입니까? 3천만 명 이상의 사용자를 보유한 MetaMask Little Fox Wallet은 오늘날 가장 인기 있는 암호화폐 지갑 중 하나입니다. 무료로 사용할 수 있으며 확장으로 네트워크에 설치할 수 있습니다.
 pip 미러 소스에 대한 간단한 가이드: 사용 방법을 쉽게 익힐 수 있습니다.
Jan 16, 2024 am 10:18 AM
pip 미러 소스에 대한 간단한 가이드: 사용 방법을 쉽게 익힐 수 있습니다.
Jan 16, 2024 am 10:18 AM
쉽게 시작하기: pip 미러 소스 사용 방법 전 세계적으로 Python이 인기를 끌면서 pip는 Python 패키지 관리를 위한 표준 도구가 되었습니다. 그러나 pip를 사용하여 패키지를 설치할 때 많은 개발자가 직면하는 일반적인 문제는 속도 저하입니다. 이는 기본적으로 pip가 Python 공식 소스나 기타 외부 소스에서 패키지를 다운로드하는데, 이러한 소스가 해외 서버에 있을 수 있어 다운로드 속도가 느려질 수 있기 때문입니다. 다운로드 속도를 향상시키기 위해 pip 미러 소스를 사용할 수 있습니다. pip 미러 소스란 무엇입니까? 쉽게 말하면 그냥
