

Python: Pandas로 효율적인 작업을 수행하는 방법
이 글에서는 어떤 방법으로 운영 효율성을 높일 수 있는지 알아보기 위해 Pandas의 운영 효율성에 대한 비교 테스트를 진행합니다.
테스트 환경은 다음과 같습니다:
windows 7, 64-bit
python 3.5
pandas 0.19.2
-
numpy 1.11.3
-
jupyter 노트북
설명이 필요합니다. 예, 시스템, 컴퓨터 구성, 소프트웨어 환경이 다르면 작동 결과가 다를 수 있습니다. 동일한 컴퓨터라도 실행될 때마다 결과가 정확히 동일하지는 않습니다.
1 테스트 내용
테스트 내용은 a*a+b*b 세 가지 방법을 사용하여 간단한 연산 과정을 계산하는 것입니다.
세 가지 방법은 다음과 같습니다.
python의 for 루프
Pandas의 Series
Numpy의 ndarray
먼저 데이터의 크기, 즉 데이터의 행 수인 DataFrame을 구성합니다. DataFrame은 10, 100, 1000, ..., 10,000,000(천만)까지입니다.
그런 다음 jupyter 노트북에서 다음 코드를 사용하여 각각 테스트하여 다양한 메서드의 실행 시간을 확인하고 비교합니다.
import pandas as pdimport numpy as np# 100分别用 10,100,...,10,000,000来替换运行list_a = list(range(100))# 200分别用 20,200,...,20,000,000来替换运行list_b = list(range(100,200))
print(len(list_a))
print(len(list_b))
df = pd.DataFrame({'a':list_a, 'b':list_b})
print('数据维度为:{}'.format(df.shape))
print(len(df))
print(df.head())100 100 数据维度为:(100, 2) 100 a b 0 0 100 1 1 101 2 2 102 3 3 103 4 4 104
a*a + b*b 연산을 수행합니다.
방법 1: for 루프
%%timeit# 当DataFrame的行数大于等于1000000时,请用 %%time 命令for i in range(len(df)): df['a'][i]*df['a'][i]+df['b'][i]*df['b'][i]
100 loops, best of 3: 12.8 ms per loop
방법 2: Series
type(df['a'])
pandas.core.series.Series
%%timeit df['a']*df['a']+df['b']*df['b']
The slowest run took 5.41 times longer than the fastest. This could mean that an intermediate result is being cached. 1000 loops, best of 3: 669 µs per loop
방법 3: ndarray
type(df['a'].values)
numpy.ndarray
%%timeit df['a'].values*df['a'].values+df['b'].values*df['b'].values
10000 loops, best of 3: 34.2 µs per loop
2 테스트 결과
실행 결과는 다음과 같습니다.
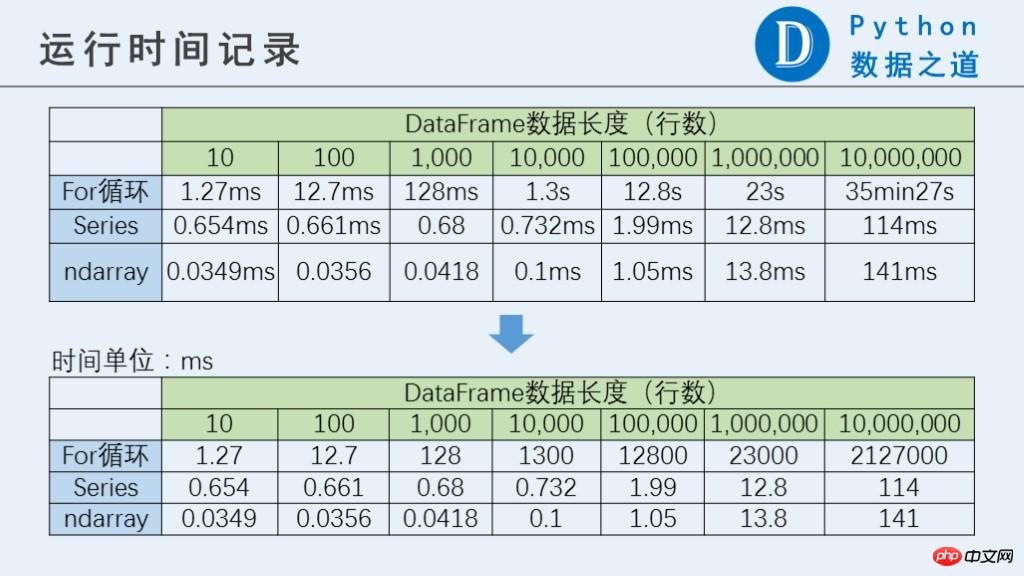
실행 결과에서 볼 수 있듯이 for 루프는 분명히 Series 및 ndarray보다 훨씬 느리고 더 큽니다. 데이터의 양이 많을수록 그 차이는 더욱 분명해집니다. 데이터 양이 1천만 행에 도달하면 for 루프의 성능은 10,000배 이상 저하됩니다. 시리즈와 ndarray의 차이는 그리 크지 않습니다.
PS: 1천만 개의 행이 있는 경우 for 루프를 실행하는 데 매우 오랜 시간이 걸립니다. 테스트하려면 주의가 필요합니다. %%time 명령을 사용하세요(한 번만 테스트하세요).
다음 차트는 Series와 ndarray의 성능을 비교합니다.
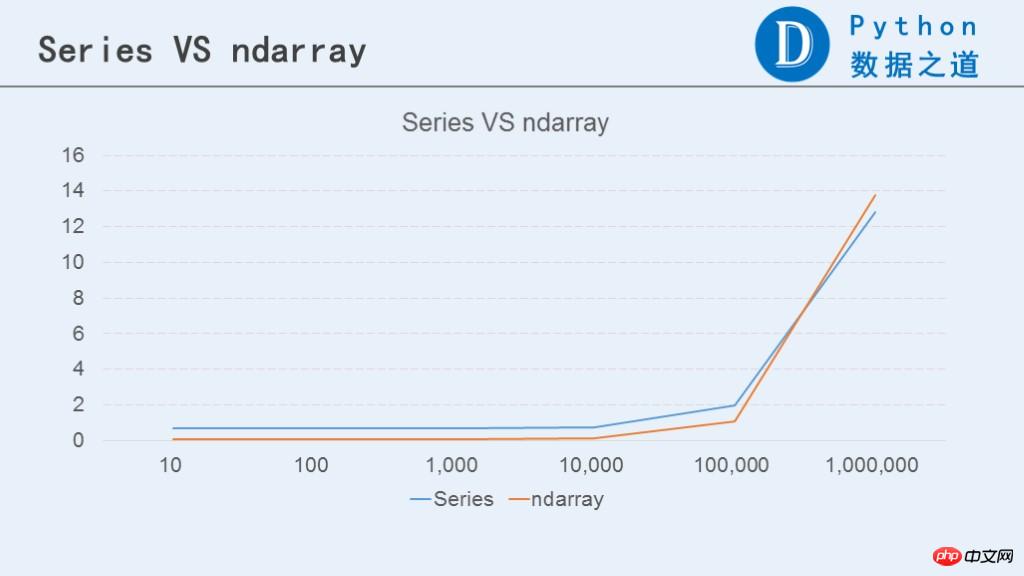
위 그림에서 볼 수 있듯이 데이터가 100,000행 미만일 때는 ndarray가 Series보다 성능이 좋습니다. 데이터 행 수가 100만 행보다 큰 경우 Series는 ndarray보다 성능이 약간 더 좋습니다. 물론 둘 사이의 차이는 특별히 뚜렷하지 않습니다.
그래서 일반적인 상황에서는 가능하면 for 루프를 사용하는 것이 좋습니다. 숫자가 특별히 크지 않은 경우 ndarray(예: df['col'].values)를 사용하여 계산하는 것이 좋습니다. 운영 효율이 상대적으로 낮다고 합니다.
위 내용은 Python: Pandas로 효율적인 작업을 수행하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7317
7317
 9
1625
14
1349
46
1261
25
1209
29
9
1625
14
1349
46
1261
25
1209
29

 DeepSeek Xiaomi를 다운로드하는 방법
Feb 19, 2025 pm 05:27 PM
DeepSeek Xiaomi를 다운로드하는 방법
Feb 19, 2025 pm 05:27 PM
DeepSeek Xiaomi를 다운로드하는 방법? Xiaomi App Store에서 "Deepseek"을 검색하십시오. 요구 사항 (검색 파일, 데이터 분석)을 식별하고 DeepSeek 기능이 포함 된 해당 도구 (예 : 파일 관리자, 데이터 분석 소프트웨어)를 찾으십시오.
 당신은 그에게 Deepseek에게 어떻게 물어 봐요
Feb 19, 2025 pm 04:42 PM
당신은 그에게 Deepseek에게 어떻게 물어 봐요
Feb 19, 2025 pm 04:42 PM
DeepSeek을 효과적으로 사용하는 열쇠는 질문을 명확하게 요청하는 것입니다. 질문을 직접 그리고 구체적으로 표현하십시오. 구체적인 세부 사항 및 배경 정보를 제공합니다. 복잡한 문의의 경우 여러 각도 및 반박 의견이 포함됩니다. 코드의 성능 병목 현상과 같은 특정 측면에 중점을 둡니다. 당신이 얻는 답변에 대한 비판적 사고를 유지하고 당신의 전문 지식을 바탕으로 판단하십시오.
 DeepSeek을 검색하는 방법
Feb 19, 2025 pm 05:18 PM
DeepSeek을 검색하는 방법
Feb 19, 2025 pm 05:18 PM
강력한 시맨틱 분석 알고리즘과 함께 제공되는 검색 기능을 사용하면 검색 의도를 정확하게 이해하고 관련 정보를 제공 할 수 있습니다. 그러나 인기가없는 최신 정보 또는 고려해야 할 문제가있는 검색의 경우 키워드를 조정하거나보다 구체적인 설명을 사용하고 다른 실시간 정보 소스와 결합하며 DeepSeek이 필요한 도구라는 것을 이해해야합니다. 적극적이고 명확하며 세련된 검색 전략.
 DeepSeek을 프로그래밍하는 방법
Feb 19, 2025 pm 05:36 PM
DeepSeek을 프로그래밍하는 방법
Feb 19, 2025 pm 05:36 PM
DeepSeek은 프로그래밍 언어가 아니라 깊은 검색 개념입니다. DeepSeek을 구현하려면 기존 언어를 기반으로 선택해야합니다. 다양한 응용 프로그램 시나리오의 경우 적절한 언어 및 알고리즘을 선택하고 기계 학습 기술을 결합해야합니다. 코드 품질, 유지 관리 및 테스트가 중요합니다. 귀하의 요구에 따라 올바른 프로그래밍 언어, 알고리즘 및 도구를 선택하고 고품질 코드를 작성하면 성공적으로 구현할 수 있습니다.
 DeepSeek을 사용하여 계정을 해결하는 방법
Feb 19, 2025 pm 04:36 PM
DeepSeek을 사용하여 계정을 해결하는 방법
Feb 19, 2025 pm 04:36 PM
질문 : DeepSeek은 회계에 이용 가능합니까? 답변 : 아니요, 재무 데이터를 분석하는 데 사용할 수있는 데이터 마이닝 및 분석 도구이지만 회계 소프트웨어의 회계 기록 및 보고서 생성 기능이 없습니다. DeepSeek을 사용하여 재무 데이터를 분석하려면 데이터 구조, 알고리즘 및 DeepSeek API에 대한 지식으로 데이터를 처리하기 위해 코드를 작성해야합니다. 잠재적 문제 (예 : 프로그래밍 지식, 학습 곡선, 데이터 품질).
 DeepSeekapi에 액세스하는 방법 -Deepseekapi Access Call Tutorial
Mar 12, 2025 pm 12:24 PM
DeepSeekapi에 액세스하는 방법 -Deepseekapi Access Call Tutorial
Mar 12, 2025 pm 12:24 PM
DeepSeekapi Access and Call에 대한 자세한 설명 : 빠른 시작 안내서이 기사는 DeepSeekapi에 액세스하고 전화하는 방법에 대해 자세히 안내하여 강력한 AI 모델을 쉽게 사용할 수 있도록 도와줍니다. 1 단계 : API 키를 가져와 DeepSeek 공식 웹 사이트에 액세스하고 오른쪽 상단의 "오픈 플랫폼"을 클릭하십시오. 특정 수의 무료 토큰을 얻게됩니다 (API 사용량을 측정하는 데 사용됨). 왼쪽의 메뉴에서 "Apikeys"를 클릭 한 다음 "Apikey 만들기"를 클릭하십시오. Apikey (예 : "테스트")의 이름을 지정하고 생성 된 키를 즉시 복사하십시오. 한 번만 표시 되므로이 키를 올바르게 저장하십시오.
 Pi Coin의 주요 업데이트 : Pi Bank가오고 있습니다!
Mar 03, 2025 pm 06:18 PM
Pi Coin의 주요 업데이트 : Pi Bank가오고 있습니다!
Mar 03, 2025 pm 06:18 PM
Pinetwork는 혁신적인 모바일 뱅킹 플랫폼 인 Pibank를 출시하려고합니다! Pinetwork는 오늘 Pibank라고 불리는 Elmahrosa (Face) Pimisrbank에 대한 주요 업데이트를 발표했습니다. Pibank는 Pinetwork Cryptocurrency 기능을 완벽하게 통합하여 화폐 통화 및 암호 화폐의 원자 교환을 실현합니다 (US Dollar, Indones rupiah, indensian rupiah and with rupiah and and indensian rupiah and rupiah and and Indones rupiah and rupiahh and rupiah and rupiah and rupiah and rupiah and rupiah and rupiah and rupiah cherrenciance) ). Pibank의 매력은 무엇입니까? 알아 보자! Pibank의 주요 기능 : 은행 계좌 및 암호 화폐 자산의 원 스톱 관리. 실시간 거래를 지원하고 생물학을 채택하십시오
 현재 AI 슬라이싱 도구는 무엇입니까?
Nov 29, 2024 am 10:40 AM
현재 AI 슬라이싱 도구는 무엇입니까?
Nov 29, 2024 am 10:40 AM
다음은 인기 있는 AI 슬라이싱 도구입니다. TensorFlow DataSetPyTorch DataLoaderDaskCuPyscikit-imageOpenCVKeras ImageDataGenerator
