

PHP의 opcode 최적화에 대한 심층적인 이해(그림 및 텍스트)

1. 개요
PHP(이 글에서 언급된 PHP 버전은 모두 7.1.3)는 동적 스크립팅 언어입니다. zend 가상 머신에서의 실행 프로세스는 스크립트 프로그램 문자열을 읽고 이를 통해 변환하는 것입니다. 어휘 분석기는 단어 기호이고, 구문 분석기는 구문 구조를 발견하고 추상 구문 트리를 생성하고, 정적 컴파일러는 opcode를 생성하고, 마지막으로 인터프리터는 각 opcode를 실행하기 위해 기계 명령어를 시뮬레이션합니다.
위에서 언급한 전체 프로세스에서 생성된 opcode는 데드 코드 삭제, 조건부 상수 전파, 함수 인라인 등 다양한 최적화를 적용하여 opcode를 간소화하여 코드의 실행 성능을 향상시킬 수 있습니다.
PHP 확장 opcache는 공유 메모리를 기반으로 생성된 opcode에 대한 캐싱 최적화를 지원합니다. 이를 바탕으로 opcode의 정적 컴파일 최적화가 추가됩니다. 여기에 설명된 최적화는 일반적으로 최적화 프로그램(Optimizer)에 의해 관리됩니다. 컴파일 원칙에서 각 최적화는 일반적으로 최적화 단계(Opt pass)에 의해 설명됩니다.
일반적으로 최적화 패스에는 두 가지 유형이 있습니다.
하나는 변환 패스에 대한 보조 정보를 제공하기 위해 데이터 흐름 및 제어 흐름 분석 정보를 제공하는 분석 패스입니다. 생성된 코드를 변경하는 작업에는 명령어 추가 및 삭제, 명령어 변경 및 교체, 명령어 순서 조정 등이 포함됩니다. 일반적으로 생성된 코드의 변경 사항은 각 패스 전후에 덤프될 수 있습니다.
이 글은 opcache 확장에서 제공하는 옵티마이저와 결합된 컴파일 원리를 기반으로 하며, PHP 컴파일 op_array의 기본 단위와 PHP 실행 opcode의 최소 단위를 출발점으로 삼습니다. 이 기사에서는 Zend 가상 머신에 컴파일 최적화 기술을 적용하는 방법을 소개하고, 각 최적화 패스가 Opcode를 단계별로 최적화하여 코드 실행 성능을 향상시키는 방법을 정리합니다. 마지막으로 PHP 언어 가상 머신의 실행을 기반으로 몇 가지 전망을 제시합니다.
2. 여러 개념 설명
1) 정적 컴파일/해석 실행/적시 컴파일
정적 컴파일(정적 컴파일), 사전 컴파일(ahead-of-time 컴파일)이라고도 함, AOT라고 합니다. 즉, 소스코드를 타겟 코드로 컴파일하고 실행하면 해당 타겟 코드를 지원하는 플랫폼에서 실행된다.
동적 컴파일(동적 컴파일)은 정적 컴파일과 관련하여 "런타임 시 컴파일"을 의미합니다. 일반적으로 컴파일과 실행을 위해 인터프리터를 사용하는데, 이는 소스 언어를 하나씩 해석하고 실행하는 것을 의미합니다.
JIT 컴파일(Just-In-Time 컴파일), 즉 좁은 의미의 Just-In-Time 컴파일은 특정 코드 조각이 처음 실행될 때 컴파일된 후 실행되는 것을 의미합니다. 컴파일 없이 직접 실행되는 것은 동적 컴파일의 특별한 경우입니다.
위의 세 가지 유형의 다양한 컴파일 실행 프로세스를 대략적으로 설명하면 다음과 같습니다.
2) 데이터 흐름/제어 흐름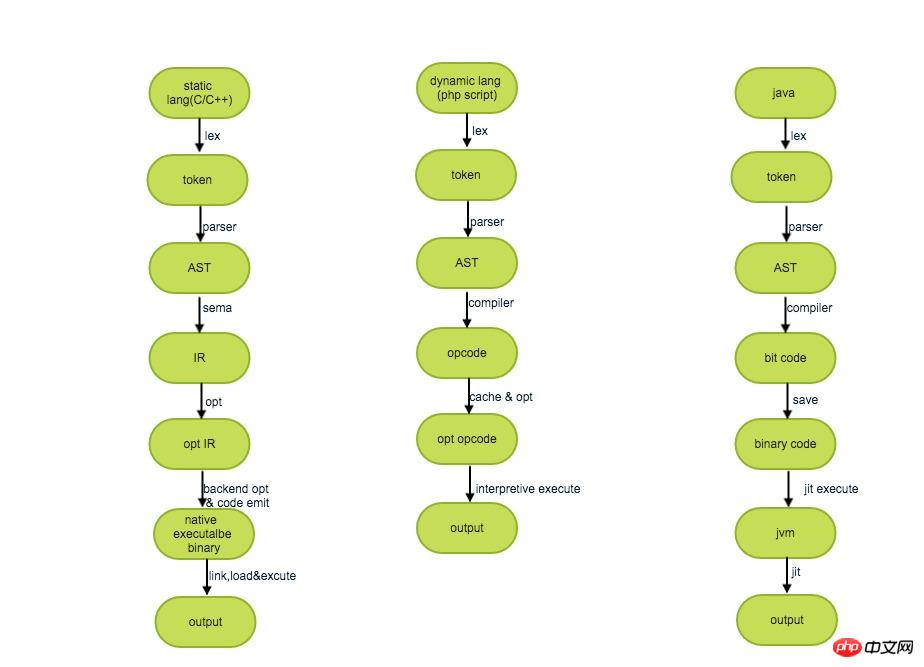 컴파일 최적화를 위해서는 프로그램에서 충분한 정보를 얻어야 하며, 이는 모든 컴파일 최적화의 기초입니다.
컴파일 최적화를 위해서는 프로그램에서 충분한 정보를 얻어야 하며, 이는 모든 컴파일 최적화의 기초입니다.
컴파일러 프런트 엔드에서 생성된 결과는 구문 트리 또는 일종의 하위 수준 중간 코드일 수 있습니다. 그러나 결과의 형태가 무엇이든 간에 프로그램이 수행하는 작업이나 수행 방법에 대해 많은 정보를 제공하지는 않습니다. 컴파일러는 각 프로시저 내에서 제어 흐름 계층을 발견하는 작업을 제어 흐름 분석에 맡기고, 데이터 흐름 분석에 데이터 처리와 관련된 전역 정보를 결정하는 작업을 맡깁니다.
제어 흐름은 프로그램 제어 구조 정보를 얻기 위한 형식적 분석 방법이며 데이터 흐름 분석 및 종속성 분석의 기초입니다. 제어의 기본 모델은 제어 흐름 그래프(CFG)입니다. 단일 프로세스의 제어 흐름을 분석하는 방법에는 두 가지가 있습니다. 필요한 노드를 사용하여 루프를 찾는 방법과 간격 분석입니다.
데이터 흐름은 프로그램 코드에서 프로그램의 의미 정보를 수집하고, 대수적 방법을 통해 컴파일 타임에 변수의 정의와 사용을 결정합니다. 데이터의 기본 모델은 데이터 흐름 그래프(DFG)입니다. 공통 데이터 흐름 분석은 컨트롤 트리 기반 데이터 흐름 분석이며, 알고리즘은 간격 분석과 구조 분석으로 구분됩니다.
3) op_array
는 C 언어의 스택 프레임 개념과 비슷합니다. 스택 프레임은 실행 중인 프로그램의 기본 단위(한 프레임), 일반적으로 함수 호출의 기본 단위입니다. 여기서는 함수나 메소드, 전체 PHP 스크립트 파일, PHP 코드를 나타내기 위해 eval에 전달된 문자열이 op_array로 컴파일됩니다.
구현에 있어서 op_array는 프로그램 실행의 기본 단위에 대한 모든 정보를 담고 있는 구조체입니다. 물론 opcode 배열은 구조체의 가장 중요한 필드이지만, 그 외에도 변수 유형, 주석 정보, 예외 캡처 정보 및 점프 정보를 기다립니다.
4) opcode
interpreter 실행(ZendVM) 프로세스는 기본 단위인 op_array에서 최적화된 최소 opcode를 실행하고, 순서대로 실행을 순회한 후, 현재 opcode를 실행하고, 마지막 RETRUN까지 다음 opcode를 미리 가져오는 과정이며, 이는 특별한 opcode가 반환되고 종료됩니다.
여기서 opcode는 정적 컴파일러의 중간 표현(LLVM IR과 유사)과 어느 정도 유사합니다. 이는 일반적으로 연산자, 두 개의 피연산자 및 연산 결과를 포함하는 3개의 주소 코드 형식을 취합니다. . 두 피연산자 모두 유형 정보를 포함합니다. 여기에는 다섯 가지 유형의 정보가 있습니다. 즉,
컴파일된 변수(줄여서 CV)는 PHP 스크립트에 정의된 변수입니다.
ZendVM에서 사용하는 임시 변수인 내부 재사용 가능 변수(VAR)를 다른 opcode와 공유할 수 있습니다.
ZendVM에서 사용하는 임시 변수인 내부 재사용 불가능 변수(TMP_VAR)는 다른 opcode와 공유할 수 없습니다.
상수(CONST), 읽기 전용 상수, 값을 변경할 수 없습니다.
쓸모없는 변수(사용되지 않음). Opcode는 세 개의 주소 코드를 사용하므로 모든 Opcode에 피연산자 필드가 있는 것은 아닙니다. 기본적으로 이 변수는 필드를 완성하는 데 사용됩니다.
연산자와 함께 유형 정보를 사용하면 실행자는 특정 컴파일된 C 함수 라이브러리 템플릿을 일치 및 선택하고 실행을 위한 기계 명령어를 시뮬레이션 및 생성할 수 있습니다.
opcode는 ZendVM의 zend_op 구조로 표현됩니다. 주요 구조는 다음과 같습니다. 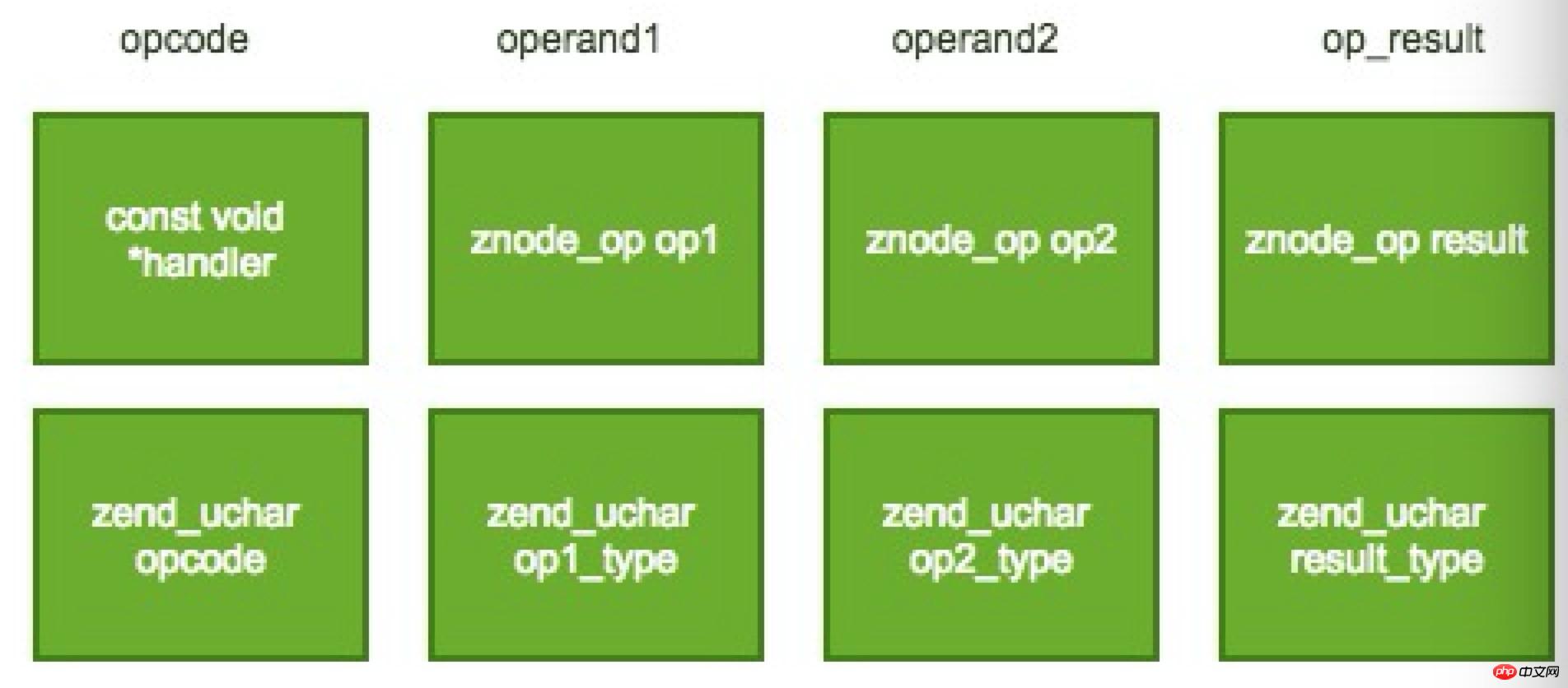
3.opcache 최적화 최적화
PHP 스크립트는 어휘 분석 및 구문 분석을 통해 추상 구문 트리 구조를 생성합니다. 정적으로 컴파일되고 생성된 opcode. 다양한 가상 머신에 명령을 실행하기 위한 공통 플랫폼으로서 다양한 가상 머신의 특정 구현에 의존합니다(그러나 PHP의 경우 대부분 ZendVM을 참조합니다).
가상 머신이 opcode를 실행하기 전에 opcode가 최적화되면 실행 효율성이 더 높은 코드를 얻을 수 있습니다. pass의 기능은 opcde에 작용하고 opcode를 처리하고 opcode를 분석하고 최적화를 찾는 것입니다. 실행 효율성이 높은 보다 효율적인 코드를 생성하기 위해 opcode를 수정합니다.
1) ZendVM 최적화 소개
Zend 가상 머신(ZendVM)에서 opcache의 정적 코드 최적화는 zend opcode 최적화입니다.
최적화 효과를 관찰하고 디버깅을 용이하게 하기 위해 최적화 및 디버깅 옵션도 제공합니다.
optimizationlevel (opcache.optimizationlevel=0xFFFFFFFF) 최적화 수준은 기본적으로 켜져 있습니다. 종료를 제어하려면 명령줄 매개 변수를 입력하세요
optdebuglevel (opcache.optdebuglevel=-1) 디버깅 수준은 기본적으로 켜져 있지 않지만 이전에 opcode 변환 프로세스를 제공합니다. 각 최적화 후
실행 후에 정적 최적화에 필요한 스크립트 컨텍스트 정보는 다음과 같이 zend_script 구조에 캡슐화됩니다.
typedef struct _zend_script {
zend_string *filename; //文件名
zend_op_array main_op_array; //栈帧
HashTable function_table; //函数单位符号表信息
HashTable class_table; //类单位符号表信息
} zend_script;위의 세 가지 콘텐츠 정보는 분석 및 최적화를 위한 입력 매개 변수로 최적화 프로그램에 전달됩니다. 물론 일반적인 PHP 확장과 유사하게 opcode 캐시 모듈(zend_accel)과 함께 opcache 확장을 구성합니다. 캐시 가속기에 세 가지 내부 API가 포함되어 있습니다.
zendoptimizerstartup 시작 최적화
zendoptimize스크립트 최적화는 최적화의 기본 논리를 구현합니다
zendoptimizer종료 최적화 리소스 정리 프로세서에 의해 생성
opcode 캐싱에 관해서도 opcode의 매우 중요한 최적화입니다. 기본 응용 원칙은 대략 다음과 같습니다.
PHP는 동적 스크립팅 언어이지만 GCC/LLVM과 같은 전체 컴파일러 도구 체인을 직접 호출하지 않으며 Javac와 같은 순수 프런트 엔드 컴파일러를 호출하지도 않습니다. 그러나 PHP 스크립트 실행을 요청할 때마다 어휘집, 구문, opcode 컴파일 및 VM 실행의 전체 수명 주기를 거칩니다.
실행을 제외한 처음 세 단계는 기본적으로 프런트엔드 컴파일러의 전체 프로세스입니다. 하지만 이 컴파일 프로세스는 빠르지 않습니다. 동일한 스크립트를 반복적으로 실행하는 경우 처음 세 단계의 컴파일 시간으로 인해 작업 효율성이 심각하게 제한되지만 각 컴파일에서 생성된 opcode는 변경되지 않습니다. 따라서 opcode는 처음 컴파일할 때 특정 위치에 캐시될 수 있습니다. opcache 확장은 이를 공유 메모리에 캐시합니다(Java는 이를 파일에 저장합니다). opcode는 다음 번에 공유 메모리에서 직접 가져옵니다. 스크립트가 실행되므로 컴파일 시간이 절약됩니다.
opcache 확장의 opcode 캐싱 프로세스는 대략 다음과 같습니다. 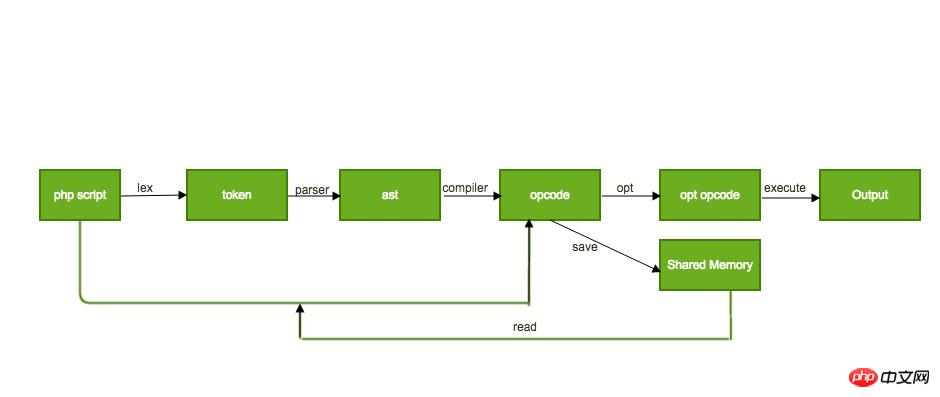 이 문서는 주로 정적 최적화 패스에 중점을 두기 때문에 여기서는 캐시 최적화의 구체적인 구현에 대해 논의하지 않습니다.
이 문서는 주로 정적 최적화 패스에 중점을 두기 때문에 여기서는 캐시 최적화의 구체적인 구현에 대해 논의하지 않습니다.
2) ZendVM 최적화 원리
"Whale Book"("고급 컴파일러 설계 및 구현")에 따르면 최적화 컴파일러에 대한 보다 합리적인 최적화 통과 순서는 다음과 같습니다. 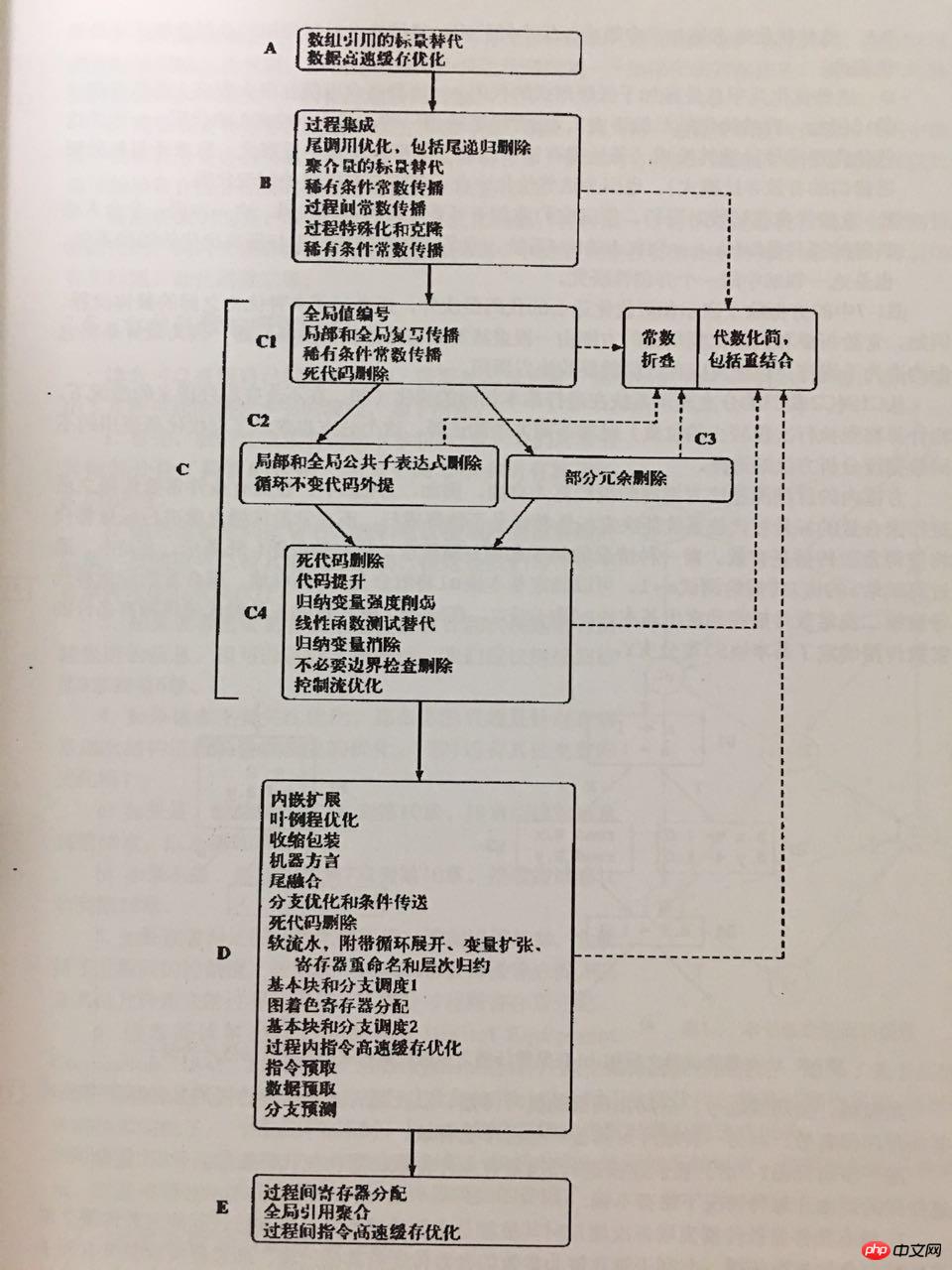
위 그림과 관련된 최적화가 시작됩니다. 단순부터 상수 및 데드 코드부터 루프 및 분기 점프까지, 함수 호출부터 프로시저 간 최적화까지, 프리패치 및 캐싱부터 소프트 파이프라이닝 및 레지스터 할당까지 데이터 흐름 및 제어 흐름 분석도 포함됩니다.
물론 현재 opcode 최적화 프로그램은 위의 모든 최적화 패스를 구현하지 않으며 레지스터 할당과 같은 기계 관련 하위 수준 중간 표현 최적화를 구현할 필요가 없습니다.
위의 스크립트 매개변수 정보를 받은 후 opcache 최적화 프로그램은 최소 컴파일 단위를 찾습니다. 이를 기반으로 최적화 패스 매크로와 해당 최적화 수준 매크로에 따라 특정 패스의 등록 제어가 실현될 수 있습니다.
등록된 최적화에는 상수 최적화, 중복 nop 삭제, 함수 호출 최적화 변환 패스, 데이터 흐름 분석, 제어 흐름 분석, 호출 관계 분석 등의 분석 패스 등 각 최적화가 일정한 순서로 시리즈로 구성되어 있습니다.
zendoptimize스크립트와 실제 최적화 등록 zend_optimize 과정은 다음과 같습니다.
zend_optimize_script(zend_script *script,
zend_long optimization_level, zend_long debug_level)
|zend_optimize_op_array(&script->main_op_array, &ctx);
遍历二元操作符的常量操作数,由运行时转化为编译时(反向pass2)
实际优化pass,zend_optimize
遍历二元操作符的常量操作数,由编译时转化为运行时(pass2)
|遍历op_array内函数zend_optimize_op_array(op_array, &ctx);
|遍历类内非用户函数zend_optimize_op_array(op_array, &ctx);
(用户函数设static_variables)
|若使用DFA pass & 调用图pass & 构建调用图成功
遍历二元操作符的常量操作数,由运行时转化为编译时(反向pass2)
设置函数返回值信息,供SSA数据流分析使用
遍历调用图的op_array,做DFA分析zend_dfa_analyze_op_array
遍历调用图的op_array,做DFA优化zend_dfa_optimize_op_array
若开调试,遍历dump调用图的每一个op_array(优化变换后)
若开栈矫正优化,矫正栈大小adjust_fcall_stack_size_graph
再次遍历调用图内的的所有op_array,
针对DFA pass变换后新产生的常量场景,常量优化pass2再跑一遍
调用图op_array资源清理
|若开栈矫正优化
矫正栈大小main_op_array
遍历矫正栈大小op_array
|清理资源该部分主要调用了SSA/DFA/CFG这几类用于opcode分析pass,涉及的pass有BB块、CFG、DFA(CFG、DOMINATORS、LIVENESS、PHI-NODE、SSA)。
用于opcode转换的pass则集中在函数zend_optimize内,如下:
zend_optimize |op_array类型为ZEND_EVAL_CODE,不做优化 |开debug, 可dump优化前内容 |优化pass1, 常量替换、编译时常量操作变换、简单操作转换 |优化pass2 常量操作转换、条件跳转指令优化 |优化pass3 跳转指令优化、自增转换 |优化pass4 函数调用优化(主要为函数调用优化) |优化pass5 控制流图(CFG)优化 |构建流图 |计算数据依赖 |划分BB块(basic block,简称BB,数据流分析基本单位) |BB块内基于数据流分析优化 |BB块间跳转优化 |不可到达BB块删除 |BB块合并 |BB块外变量检查 |重新构建优化后的op_array(基于CFG) |析构CFG |优化pass6/7 数据流分析优化 |数据流分析(基于静态单赋值SSA) |构建SSA |构建CFG 需要找到对应BB块序号、管理BB块数组、计算BB块后继BB、标记可到达BB块、计算BB块前驱BB |计算Dominator树 |标识循环是否可简化(主要依赖于循环回边) |基于phi节点构建完SSA def集、phi节点位置、SSA构造重命名 |计算use-def链 |寻找不当依赖、后继、类型及值范围值推断 |数据流优化 基于SSA信息,一系列BB块内opcode优化 |析构SSA |优化pass9 临时变量优化 |优化pass10 冗余nop指令删除 |优化pass11 压缩常量表优化
还有其他一些优化遍如下:
优化pass12 矫正栈大小 优化pass15 收集常量信息 优化pass16 函数调用优化,主要是函数内联优化
除此之外,pass 8/13/14可能为预留pass id。由此可看出当前提供给用户选项控制的opcode转换pass有13个。但是这并不计入其依赖的数据流/控制流的分析pass。
3)函数内联pass的实现
通常在函数调用过程中,由于需要进行不同栈帧间切换,因此会有开辟栈空间、保存返回地址、跳转、返回到调用函数、返回值、回收栈空间等一系列函数调用开销。因此对于函数体适当大小情况下,把整个函数体嵌入到调用者(Caller)内部,从而不实际调用被调用者(Callee)是一个提升性能的利器。
由于函数调用与目标机的应用二进制接口(ABI)强相关,静态编译器如GCC/LLVM的函数内联优化基本是在指令生成之前完成。
ZendVM的内联则发生在opcode生成后的FCALL指令的替换优化,pass id为16,其原理大致如下:
| 遍历op_array中的opcode,找到DO_XCALL四个opcode之一
| opcode ZEND_INIT_FCALL
| opcode ZEND_INIT_FCALL_BY_NAMEZ
| 新建opcode,操作码置为ZEND_INIT_FCALL,计算栈大小,
更新缓存槽位,析构常量池字面量,替换当前opline的opcode
| opcode ZEND_INIT_NS_FCALL_BY_NAME
| 新建opcode,操作码置为ZEND_INIT_FCALL,计算栈大小,
更新缓存槽位,析构常量池字面量,替换当前opline的opcode
| 尝试函数内联
| 优化条件过滤 (每个优化pass通常有较多限制条件,某些场景下
由于缺乏足够信息不能优化或出于代价考虑而排除)
| 方法调用ZEND_INIT_METHOD_CALL,直接返回不内联
| 引用传参,直接返回不内联
| 缺省参数为命名常量,直接返回不内联
| 被调用函数有返回值,添加一条ZEND_QM_ASSIGN赋值opcode
| 被调用函数无返回值,插入一条ZEND_NOP空opcode
| 删除调用被内联函数的call opcode(即当前online的前一条opcode)如下示例代码,当调用fname()时,使用字符串变量名fname来动态调用函数foo,而没有使用直接调用的方式。此时可通过VLD扩展查看其生成的opcode,或打开opcache调试选项(opcache.optdebuglevel=0xFFFFFFFF)亦可查看。
function foo() { }
$fname = 'foo';开启debug后dump可看出,发生函数调用优化前opcode序列(仅截取片段)为:
ASSIGN CV0($fname) string("foo")
INIT_FCALL_BY_NAME 0 CV0($fname)
DO_FCALL_BY_NAMEINIT_FCALL_BY_NAME这条opcode执行逻辑较为复杂,当开启激进内联优化后,可将上述指令序列直接合并成一条DO_FCALL string("foo")指令,省去间接调用的开销。这样也恰好与直接调用生成的opcode一致。
4)如何为opcache opt添加一个优化pass
根据以上描述,可见向当前优化器加入一个pass并不会太难,大体步骤如下:
先向zend_optimize优化器注册一个pass宏(例如添加pass17),并决定其优化级别。
在优化管理器某个优化pass前后调用加入的pass(例如添加一个尾递归优化pass),建议在DFA/SSA分析pass之后添加,因为此时获得的优化信息更多。
实现新加入的pass,进行定制代码转换(例如zendoptimizefunc_calls实现一个尾递归优化)。针对当前已有pass,主要添加转换pass,这里一般也可利用SSA/DFA的信息。不同于静态编译优化一般是在贴近于机器相关的低层中间表示优化,这里主要是在opcode层的opcode/operand相应的一些转换。
实现pass前,与函数内联类似,通常首先收集优化所需信息,然后排除掉不适用该优化的一些场景(如非真正的尾不递归调用、参数问题无法做优化等)。实现优化后,可dump优化前后生成opcode结构的变化是否优化正确、是否符合预期(如尾递归优化最终的效果是变换函数调用为forloop的形式)。
4.一点思考
以下是对基于动态的PHP脚本程序执行的一些看法,仅供参考。
由于LLVM从前端到后端,从静态编译到jit整个工具链框架的支持,使得许多语言虚拟机都尝试整合。当前PHP7时代的ZendVM官方还没采用,原因之一虚拟机opcode承载着相当复杂的分析工作。相比于静态编译器的机器码每一条指令通常只干一件事情(通常是CPU指令时钟周期),opcode的操作数(operand)由于类型不固定,需要在运行期间做大量的类型检查、转换才能进行运算,这极度影响了执行效率。即使运行时采用jit,以byte code为单位编译,编译出的字节码也会与现有解释器一条一条opcode处理类似,类型需要处理、也不能把zval值直接存在寄存器。
以函数调用为例,比较现有的opcode执行与静态编译成机器码执行的区别,如下图:
类型推断
在不改变现有opcode设计的前提下,加强类型推断能力,进而为opcode的执行提供更多的类型信息,是提高执行性能的可选方法之一。
多层opcode
既然opcode承担如此复杂的分析工作,能否将其分解成多层的opcode归一化中间表示( intermediate representation, IR)。各优化可选择应用哪一层中间表示,传统编译器的中间表示依据所携带信息量、从抽象的高级语言到贴近机器码,分成高级中间表示(HIR) 、中级中间表示(MIR)、低级中间表示(LIR)。
패스 관리
opcode의 최적화된 패스 관리에 관해서는 이전 글에서 언급한 것처럼 개선의 여지가 있을 것입니다. 현재의 분석은 데이터 흐름/제어 흐름 분석에 의존하고 있지만, 실행 순서, 실행 횟수, 등록 관리, 복잡한 통과 분석의 정보 덤프 등 프로세스 간 분석 및 최적화가 여전히 부족합니다. llvm과 같은 성숙한 프레임워크에 비해 여전히 부족합니다.
JIT
ZendVM은 LLVM의 도움으로 런타임용 기계어 코드로 컴파일할 수 있는 다수의 zval 값, 유형 변환 및 기타 작업을 구현하지만 컴파일 시간이 극도로 빠르게 확장됩니다. 물론 libjit도 사용할 수 있습니다.
위 내용은 PHP의 opcode 최적화에 대한 심층적인 이해(그림 및 텍스트)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7523
7523
 15
1378
52
81
11
54
19
21
74
15
1378
52
81
11
54
19
21
74

 Ubuntu 및 Debian용 PHP 8.4 설치 및 업그레이드 가이드
Dec 24, 2024 pm 04:42 PM
Ubuntu 및 Debian용 PHP 8.4 설치 및 업그레이드 가이드
Dec 24, 2024 pm 04:42 PM
PHP 8.4는 상당한 양의 기능 중단 및 제거를 통해 몇 가지 새로운 기능, 보안 개선 및 성능 개선을 제공합니다. 이 가이드에서는 Ubuntu, Debian 또는 해당 파생 제품에서 PHP 8.4를 설치하거나 PHP 8.4로 업그레이드하는 방법을 설명합니다.
 PHP 개발을 위해 Visual Studio Code(VS Code)를 설정하는 방법
Dec 20, 2024 am 11:31 AM
PHP 개발을 위해 Visual Studio Code(VS Code)를 설정하는 방법
Dec 20, 2024 am 11:31 AM
VS Code라고도 알려진 Visual Studio Code는 모든 주요 운영 체제에서 사용할 수 있는 무료 소스 코드 편집기 또는 통합 개발 환경(IDE)입니다. 다양한 프로그래밍 언어에 대한 대규모 확장 모음을 통해 VS Code는
 이전에 몰랐던 후회되는 PHP 함수 7가지
Nov 13, 2024 am 09:42 AM
이전에 몰랐던 후회되는 PHP 함수 7가지
Nov 13, 2024 am 09:42 AM
숙련된 PHP 개발자라면 이미 그런 일을 해왔다는 느낌을 받을 것입니다. 귀하는 상당한 수의 애플리케이션을 개발하고, 수백만 줄의 코드를 디버깅하고, 여러 스크립트를 수정하여 작업을 수행했습니다.
 PHP에서 HTML/XML을 어떻게 구문 분석하고 처리합니까?
Feb 07, 2025 am 11:57 AM
PHP에서 HTML/XML을 어떻게 구문 분석하고 처리합니까?
Feb 07, 2025 am 11:57 AM
이 튜토리얼은 PHP를 사용하여 XML 문서를 효율적으로 처리하는 방법을 보여줍니다. XML (Extensible Markup Language)은 인간의 가독성과 기계 구문 분석을 위해 설계된 다목적 텍스트 기반 마크 업 언어입니다. 일반적으로 데이터 저장 AN에 사용됩니다
 JWT (JSON Web Tokens) 및 PHP API의 사용 사례를 설명하십시오.
Apr 05, 2025 am 12:04 AM
JWT (JSON Web Tokens) 및 PHP API의 사용 사례를 설명하십시오.
Apr 05, 2025 am 12:04 AM
JWT는 주로 신분증 인증 및 정보 교환을 위해 당사자간에 정보를 안전하게 전송하는 데 사용되는 JSON을 기반으로 한 개방형 표준입니다. 1. JWT는 헤더, 페이로드 및 서명의 세 부분으로 구성됩니다. 2. JWT의 작업 원칙에는 세 가지 단계가 포함됩니다. JWT 생성, JWT 확인 및 Parsing Payload. 3. PHP에서 인증에 JWT를 사용하면 JWT를 생성하고 확인할 수 있으며 사용자 역할 및 권한 정보가 고급 사용에 포함될 수 있습니다. 4. 일반적인 오류에는 서명 검증 실패, 토큰 만료 및 대형 페이로드가 포함됩니다. 디버깅 기술에는 디버깅 도구 및 로깅 사용이 포함됩니다. 5. 성능 최적화 및 모범 사례에는 적절한 시그니처 알고리즘 사용, 타당성 기간 설정 합리적,
 문자열로 모음을 계산하는 PHP 프로그램
Feb 07, 2025 pm 12:12 PM
문자열로 모음을 계산하는 PHP 프로그램
Feb 07, 2025 pm 12:12 PM
문자열은 문자, 숫자 및 기호를 포함하여 일련의 문자입니다. 이 튜토리얼은 다른 방법을 사용하여 PHP의 주어진 문자열의 모음 수를 계산하는 방법을 배웁니다. 영어의 모음은 A, E, I, O, U이며 대문자 또는 소문자 일 수 있습니다. 모음이란 무엇입니까? 모음은 특정 발음을 나타내는 알파벳 문자입니다. 대문자와 소문자를 포함하여 영어에는 5 개의 모음이 있습니다. a, e, i, o, u 예 1 입력 : String = "Tutorialspoint" 출력 : 6 설명하다 문자열의 "Tutorialspoint"의 모음은 u, o, i, a, o, i입니다. 총 6 개의 위안이 있습니다
 PHP에서 늦은 정적 결합을 설명하십시오 (정적 : :).
Apr 03, 2025 am 12:04 AM
PHP에서 늦은 정적 결합을 설명하십시오 (정적 : :).
Apr 03, 2025 am 12:04 AM
정적 바인딩 (정적 : :)는 PHP에서 늦은 정적 바인딩 (LSB)을 구현하여 클래스를 정의하는 대신 정적 컨텍스트에서 호출 클래스를 참조 할 수 있습니다. 1) 구문 분석 프로세스는 런타임에 수행됩니다. 2) 상속 관계에서 통화 클래스를 찾아보십시오. 3) 성능 오버 헤드를 가져올 수 있습니다.
 php magic 방법 (__construct, __destruct, __call, __get, __set 등)이란 무엇이며 사용 사례를 제공합니까?
Apr 03, 2025 am 12:03 AM
php magic 방법 (__construct, __destruct, __call, __get, __set 등)이란 무엇이며 사용 사례를 제공합니까?
Apr 03, 2025 am 12:03 AM
PHP의 마법 방법은 무엇입니까? PHP의 마법 방법은 다음과 같습니다. 1. \ _ \ _ Construct, 객체를 초기화하는 데 사용됩니다. 2. \ _ \ _ 파괴, 자원을 정리하는 데 사용됩니다. 3. \ _ \ _ 호출, 존재하지 않는 메소드 호출을 처리하십시오. 4. \ _ \ _ get, 동적 속성 액세스를 구현하십시오. 5. \ _ \ _ Set, 동적 속성 설정을 구현하십시오. 이러한 방법은 특정 상황에서 자동으로 호출되어 코드 유연성과 효율성을 향상시킵니다.
