

php UTF-8、Unicode和BOM问题_php技巧

UTF-8 是一种在web应用中经常使用的一种 Unicode 字符的编码方式,使用 UTF-8 的好处在于它是一种变长的编码方式,对于 ANSII 码编码长度为1个字节,这样的话在传输大量 ASCII 字符集的网页时,可以大量节约网络带宽。
UTF-8签名(UTF-8 signature)也叫做BOM(Byte Order Mark),是UTF编码方案里用于标识编码的标准标记。BOM,是UTF编码方案里用于标识编码的标准标记,在UTF-16里本来是FF FE,变成UTF-8就成了EF BB BF。这个标记是可选的,因为UTF8字节没有顺序,所以它可以被用来检测一个字节流是否是UTF-8编码的。微软做这种检测,但有些软件不做这种检测,而把它当作正常字符处理。微软在自己的UTF-8格式的文本文件之前加上了EF BB BF三个字节, windows上面的notepad等程序就是根据这三个字节来确定一个文本文件是ASCII的还是UTF-8的, 然而这个只是微软暗自作的标记, 其它平台上并没有对UTF-8文本文件做个这样的标记。也就是说一个UTF-8文件可能有BOM,也可能没有BOM。
只有一个BOM,是不会有问题的。如果多个文件设置了签名,在二进制流中就会包含多个UTF-8签名,也就是导致XML转换失败的"root element must be well-formed"原因。
二、查看和转换
既然一个UTF-8文件可能有BOM,也可能没有,那该如何区分呢?
只要用带十六进制编辑方式的软件,例如,用UltraEdit-32打开文件,切换到十六进制编辑模式,察看文件头部是否有EF BB BF。有,则为带BOM方式。
Windows自带的notepad记事本,保存为UTF-8时,默认就带BOM。
转换的方法有很多,常见的UltraEdit-32或NotePad++都可以,以UltraEdit-32为例。打开文件后,选择“另存为”,在“格式”一栏中有如下选择:
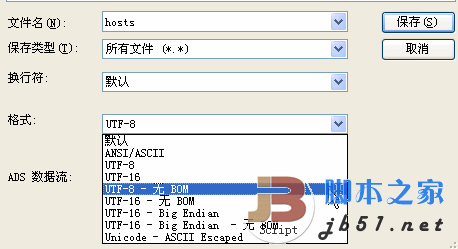
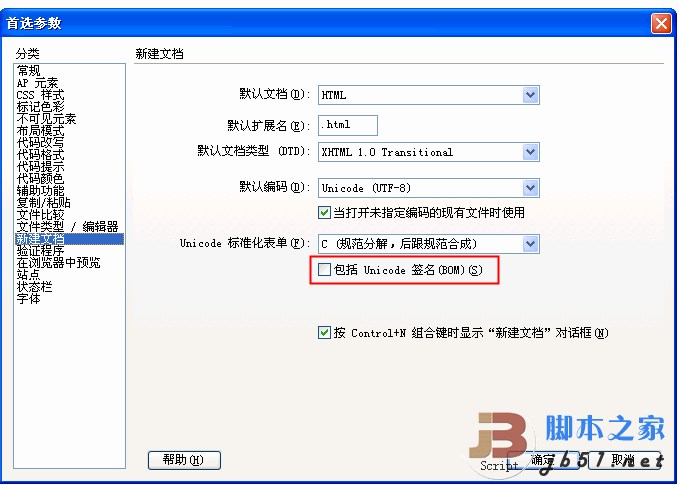
另外,DreamWeaver CS3也有类似的选项,在“首选项”中,如果选择 Unicode (UTF-8) 作为默认编码,则可以选择“包括 Unicode 签名 (BOM)”选项,以在文档中包括字节顺序标记 (BOM)。否则,不带BOM:
三、其他知识
从http://blog.csdn.net/thimin/archive/2007/08/03/1724393.aspx 一文了解到:
所谓的unicode保存的文件实际上是utf-16,只不过恰好跟unicode的码相同而已,但在概念上unicode与utf是两回事,unicode是内存编码表示方案,而utf是如何保存和传输unicode的方案。utf-16还分高位在前 (LE)和高位在后(BE)两种。官方的utf编码还有utf-32,也分LE和BE。非unicode官方的utf编码还有utf-7,主要用于邮件传输。utf-8的单字节部分是和iso-8859-1兼容的,这主要是一些旧的系统和库函数不能正确处理utf-16而被迫出来的,而且对英语字符来说,也节省保存的文件空间(以非英语字符浪费空间为代价)。在iso-8859-1的时候,utf8和iso-8859-1都是用一个字节表示的,当表示其它字符的时候,utf-8会使用两个或三个字节。
一段关于BOM的更详细说明,来自这里:
在UCS 编码中有一个叫做"ZERO WIDTH NO-BREAK SPACE"的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输字符"ZERO WIDTH NO-BREAK SPACE"。这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-Endian的。因此字符"ZERO WIDTH NO-BREAK SPACE"又被称作BOM。
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符"ZERO WIDTH NO-BREAK SPACE"的UTF-8编码是EF BB BF。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
Windows就是使用BOM来标记文本文件的编码方式的。
PHP也不支持BOM。
PHP在设计时就没有考虑BOM的问题,也就是说他不会忽略UTF-8编码的文件开头BOM的那三个字符。由于必须在※ 补充一句:特别是当使用php导入模板的时候,更容易因为这三个字符,导致浏览异常。

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7621
7621
 15
1389
52
89
11
70
19
31
136
15
1389
52
89
11
70
19
31
136

 PHP에 대한 심층적인 이해: JSON 유니코드를 중국어로 변환하는 구현 방법
Mar 05, 2024 pm 02:48 PM
PHP에 대한 심층적인 이해: JSON 유니코드를 중국어로 변환하는 구현 방법
Mar 05, 2024 pm 02:48 PM
PHP에 대한 심층적인 이해: JSONUnicode를 중국어로 변환하는 구현 방법 개발 중에 JSON 데이터를 처리해야 하는 상황이 자주 발생하며, JSON의 유니코드 인코딩은 일부 시나리오, 특히 변환해야 할 때 몇 가지 문제를 일으킬 수 있습니다. 유니코드 인코딩을 한자로 변환하는 경우입니다. PHP에는 이러한 변환 프로세스를 달성하는 데 도움이 되는 몇 가지 방법이 아래에 소개되고 구체적인 코드 예제가 제공됩니다. 먼저 JSON의 Un을 먼저 이해해 봅시다.
 유니코드를 중국어로 변환하는 방법
Dec 14, 2023 am 10:57 AM
유니코드를 중국어로 변환하는 방법
Dec 14, 2023 am 10:57 AM
유니코드는 다양한 언어와 기호를 표현하는 데 사용되는 문자 인코딩 표준입니다. 유니코드 인코딩을 중국어 문자로 변환하려면 Python의 내장 함수 chr() 및 ord()를 사용할 수 있습니다.
 Eclipse에서 한자 깨짐 문제를 해결하는 방법을 시도해 보세요.
Jan 03, 2024 pm 05:28 PM
Eclipse에서 한자 깨짐 문제를 해결하는 방법을 시도해 보세요.
Jan 03, 2024 pm 05:28 PM
Eclipse에서 중국어 문자가 깨져서 고민이신가요? 이러한 솔루션을 시도하려면 구체적인 코드 예제가 필요합니다. 1. 배경 소개 컴퓨터 기술이 지속적으로 발전함에 따라 소프트웨어 개발에서 중국어의 역할이 점점 더 중요해지고 있습니다. 그러나 많은 개발자는 중국어 개발에 Eclipse를 사용할 때 잘못된 코드 문제에 직면하여 작업 효율성에 영향을 미칩니다. 그런 다음 이 기사에서는 몇 가지 일반적인 잘못된 코드 문제를 소개하고 독자가 Eclipse에서 중국어 잘못된 코드 문제를 해결하는 데 도움이 되는 해당 솔루션과 코드 예제를 제공합니다. 2. 일반적인 잘못된 코드 문제 및 솔루션 파일
 PHP 튜토리얼: JSON 유니코드를 한자로 변환하는 방법
Mar 05, 2024 pm 06:36 PM
PHP 튜토리얼: JSON 유니코드를 한자로 변환하는 방법
Mar 05, 2024 pm 06:36 PM
JSON(JavaScriptObjectNotation)은 웹 애플리케이션 간의 데이터 교환에 일반적으로 사용되는 경량 데이터 교환 형식입니다. JSON 데이터를 처리할 때 유니코드로 인코딩된 중국어 문자(예: "u4e2du6587")를 자주 접하고 이를 읽을 수 있는 중국어 문자로 변환해야 합니다. PHP에서는 몇 가지 간단한 방법을 통해 이러한 변환을 수행할 수 있습니다. 다음으로 JSONUnico 변환 방법을 자세히 소개하겠습니다.
 dom 및 bom 객체는 무엇입니까?
Nov 13, 2023 am 10:52 AM
dom 및 bom 객체는 무엇입니까?
Nov 13, 2023 am 10:52 AM
"문서", "요소", "노드", "이벤트" 및 "창"을 포함한 5개의 DOM 개체가 있습니다. 2. "창", "네비게이터", "위치" 및 "역사" 및 "화면" 및 기타 5개; BOM 객체의 유형.
 봄과 돔의 차이점은 무엇인가요?
Nov 13, 2023 pm 03:23 PM
봄과 돔의 차이점은 무엇인가요?
Nov 13, 2023 pm 03:23 PM
BOM과 DOM은 역할과 기능, JavaScript와의 관계, 상호의존성, 다양한 브라우저의 호환성, 보안 고려사항 측면에서 다릅니다. 세부 소개: 1. 역할 및 기능 BOM의 주요 기능은 브라우저 창에 대한 직접 액세스 및 제어를 제공하는 반면, DOM의 주요 기능은 웹 문서를 개체 트리로 변환하는 것입니다. 개발자는 이 개체 트리를 사용하여 웹 페이지의 요소와 콘텐츠를 얻고 수정합니다. 2. JavaScript와의 관계
 Java가 MySQL 데이터베이스에 연결할 때 일관되지 않은 유니코드 문자 집합 인코딩 문제를 해결합니다.
Jun 10, 2023 am 11:39 AM
Java가 MySQL 데이터베이스에 연결할 때 일관되지 않은 유니코드 문자 집합 인코딩 문제를 해결합니다.
Jun 10, 2023 am 11:39 AM
빅데이터, 클라우드 컴퓨팅 등 기술의 발전으로 데이터베이스는 기업 정보화의 중요한 초석 중 하나가 되었습니다. Java로 개발된 애플리케이션에서는 MySQL 데이터베이스에 연결하는 것이 표준이 되었습니다. 그러나 이 과정에서 유니코드 문자 세트 인코딩이 일치하지 않는다는 까다로운 문제에 자주 직면합니다. 이는 개발 효율성에 영향을 미칠 뿐만 아니라 애플리케이션의 성능과 안정성에도 영향을 미칩니다. 이 기사에서는 이 문제를 해결하고 Java가 MySQL 데이터베이스에 보다 원활하게 연결되도록 하는 방법을 소개합니다. 1. 유니코드
 유니코드와 ASCII의 차이점은 무엇입니까
Sep 06, 2023 am 11:56 AM
유니코드와 ASCII의 차이점은 무엇입니까
Sep 06, 2023 am 11:56 AM
유니코드와 ASCII의 차이점에는 인코딩 범위, 저장 공간 및 호환성이 다릅니다. 자세한 소개: 1. 인코딩 범위는 다릅니다. ASCII의 인코딩 범위는 주로 영문자를 나타내는 데 사용됩니다. 유니코드의 인코딩 범위는 훨씬 더 넓으며 거의 모든 언어 문자를 나타낼 수 있습니다. 공백은 다릅니다. ASCII는 일반적으로 문자를 저장하는 데 1바이트를 사용하는 반면, 유니코드는 문자를 저장하는 데 2바이트 이상을 사용할 수 있습니다.
