
아래 편집기는 [Java IO 스트림] 바이트 스트림과 문자 스트림의 예를 제공합니다. 편집자님이 꽤 좋다고 생각하셔서 지금 공유하고 모두에게 참고용으로 드리고자 합니다. 에디터를 따라가며 함께 살펴볼까요
바이트 스트림과 문자 스트림
파일에 대한 읽기 및 쓰기 작업이 있어야 합니다. 읽기 및 쓰기는 입력 스트림과 출력 스트림에 해당하며 스트림은 바이트와 문자로 구분됩니다. . 흐름.
1. 파일 작업에는 읽기 작업과 쓰기 작업, 즉 입력과 출력이 있습니다.
2. 흐름 방향에는 입력과 출력이 있습니다.
3. 스트림 콘텐츠에는 바이트와 문자가 있습니다.
이 문서에서는 IO 스트림에서 바이트 스트림과 문자 스트림의 입력 및 출력 작업을 설명합니다.
1. 바이트 스트림
1) 입력 및 출력 스트림
우선 바이트 스트림은 읽고 쓰는 것, 즉 입력과 출력이 필요하므로 두 가지 추상이 있습니다. 부모 클래스 InputStream, OutputStream.
InputStream은 애플리케이션이 데이터, 즉 입력 스트림을 읽는 방식을 추상화합니다.
OutputStream은 애플리케이션이 데이터, 즉 출력 스트림을 쓰는 방식을 추상화합니다.
2) 읽기 및 쓰기 끝
바이트 스트림에서 읽기 및 쓰기가 끝나고 파일의 끝에 도달하면 EOF = End 또는 -1을 끝까지 읽습니다.
3) 입력 스트림의 기본 방법
우선 입력 스트림이 무엇인지 이해해야 합니다. 예를 들어 키보드를 통해 텍스트 파일에 콘텐츠를 입력할 때 키보드는 출력 스트림이 아닌 입력 스트림으로 작동합니다. 키보드의 기능은 시스템에 콘텐츠를 입력하는 것이고 시스템은 이를 파일에 기록하는 것입니다. 다음은 입력 스트림의 기본 메소드 read()입니다.
int b = in.read(); //读取一个字节无符号填充到int低八位。-1是EOF。 in.read(byte[] buf); //读取数据填充到字节数组buf中。返回的是读到的字节个数。 in.read(byte[] buf,int start, int size)//读取数据到字节数组buf从buf的start位置开始存放size长度分数据
여기서 in은 InputStream 추상 클래스의 인스턴스입니다. 이 메소드는 RandomAccessFile 클래스의 read() 메소드와 유사합니다. 둘 다 읽은 바이트로 전달되기 때문입니다.
4) 출력 스트림의 기본 방법
출력 스트림은 쓰기 작업입니다. 기본 작업 방법은 write()입니다. 이 방법은 더 나은 이해를 위해 입력 read() 방법과 하나씩 대응될 수 있습니다.
out.write(int b)//写出一个byte到流,b的低8位 out.write(byte[] buf)//将buf字节数组都写到流 out.write(byte[] buf, int start,int size) //字节数组buf从start位置开始写size长度的字节到流
InputStream 및 OutputStream의 기본 작업 방법을 이해한 후 두 가지 "자식" FileInputStream 및 FileOutputStream을 살펴보겠습니다.
이 두 하위 클래스는 특히 파일에서 데이터를 읽고 쓰는 작업을 구현합니다. 이 두 클래스는 일정 프로그래밍에서 더 일반적으로 사용됩니다.
2. FileInputStream 및 FileOutputStream 클래스 사용
----FileInputStream 클래스 사용
1. 파일을 읽는 방법
/**
* 读取指定文件内容,按照16进制输出到控制台
* 并且每输出10个byte换行
* @throws FileNotFoundException
*/
public static void printHex(String fileName) throws IOException{
//把文件作为字节流进行读操作
FileInputStream in=new FileInputStream(fileName);
int b;
int count=0;//计数读到的个数
while((b=in.read())!=-1){
if(b<=0xf){
//单位数前面补0
System.out.println("0");
}
System.out.print(Integer.toHexString(b& 0xff)+" ");
if(++count%10==0){
System.out.println();
}
}
in.close();//一定要关闭流
}실행 결과(모든 파일로 테스트):

참고:
FileInputStream() 생성자는 파일 이름(문자열) 또는 File 개체를 전달할 수 있습니다. 위의 경우는 파일 이름을 사용하여 구성됩니다.
(b=in.read())!=-1 -1을 읽어 파일 끝에 도달했는지 확인합니다.
in.close() IO 스트림 객체를 사용한 후에는 스트림을 닫아야 합니다. 좋은 습관을 기르는 것이 중요합니다.
2. 파일을 읽으려면 read(byte[] buf, int start, int size) 방법을 사용하세요.
위 방법은 1바이트만 읽을 수 있으며 더 큰 파일에는 너무 비효율적입니다. 파일을 한 번에 읽으려면 이 방법을 사용하세요.
public static void printHexByBytes(String fileName) throws IOException{
FileInputStream in=new FileInputStream(fileName);
byte[] buf=new byte[20*1024];//开辟一个20k大小的字节数组
/*
* 从in中批量读取字节,放入到buf这个字节数组中
* 从第0个位置开始放,最多放buf.length个
* 返回的是读到的字节个数
*/
//一次性读完的情况
int count=in.read(buf, 0, buf.length);
int j=1;
for(int i=0;i<count;i++){
if((buf[i]&0xff)<=0xf){
//单位数前面补0
System.out.print("0");
}
System.out.print(Integer.toHexString(buf[i]&0xff)+ " ");
if(j++%10==0){
System.out.println();
}
}
in.close();
}
}read(byte[] buf,int start, int size)는 읽은 바이트 수, 즉 buf 바이트 배열의 유효 길이를 반환하므로 buf 배열을 출력할 때 사용되는 길이는 count가 아닙니다. buf.length, 파일 크기와 배열 크기 사이의 관계를 모르기 때문에 위의 방법은 파일 크기가 배열 크기를 초과하지 않는 경우 파일 내용을 한 번에 배열로 읽어들이는 데 적합합니다. 파일 크기가 배열 크기를 초과하면 어떻게 모든 파일을 읽을 수 있습니까? ?
-1을 읽는다는 것은 파일 끝까지 읽는다는 것을 알고 있으므로 루프를 종료하기 위해 -1을 읽을 때까지 while 루프를 사용하여 반복적으로 읽습니다.
public static void printHexByBytes(String fileName) throws IOException{
FileInputStream in=new FileInputStream(fileName);
byte[] buf=new byte[20*1024];//开辟一个20k大小的字节数组
/*
* 从in中批量读取字节,放入到buf这个字节数组中
* 从第0个位置开始放,最多放buf.length个
* 返回的是读到的字节个数
*/
int j=1;
//一个字节数组读不完的情况,用while循环重复利用此数组直到读到文件末=-1
int b=0;
while((b=in.read(buf, 0, buf.length))!=-1){
for(int i=0;i<b;i++){
if((buf[i]&0xff)<=0xf){
//单位数前面补0
System.out.print("0");
}
System.out.print(Integer.toHexString(buf[i]&0xff)+ " ");
if(j++%10==0){
System.out.println();
}
}
}
in.close();
}
}좋아요. , 결과를 테스트하기 위해 배열보다 큰 파일을 사용합니다(너무 길므로 끝 부분을 스크린샷으로 표시).
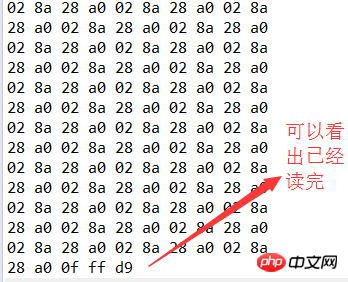
둘 사이의 차이점을 비교할 수 있습니다. 두 번째 파일은 최적화 후 일상적인 사용에 더 적합합니다. 파일 크기에 관계없이 직접 읽을 수 있습니다.
----FileOutputStream 클래스의 사용
FileOutputStream 클래스의 사용은 FileInputStream 클래스와 유사합니다. 파일.방법. FileInputStream과 유사한 내부 세부 사항 중 일부는 언급하지 않겠습니다.
1.시공방법
FileOutputStream类构造时根据不同的情况可以使用不同的方法构造,如:
//如果该文件不存在,则直接创建,如果存在,删除后创建
FileOutputStream out = new FileOutputStream("demo/new1.txt");//以路径名称构造//如果该文件不存在,则直接创建,如果存在,在文件后追加内容
FileOutputStream out = new FileOutputStream("demo/new1.txt",true);
更多内容可以查询API。2.使用write()方法写入文件
write()方法和read()相似,只能操作一个字节,即只能写入一个字节。例如:
out.wirte(‘A');//写出了‘A'的低八位 int a=10;//wirte只能写八位,那么写一个int需要写4次,每次八位 out.write(a>>>24); out.write(a>>>16); out.write(a>>>8); out.wirte(a);
每次只写一个字节,显然是不效率的,OutputStream当然跟InputStream一样可以直接对byte数组操作。
3.使用write(byte[] buf,int start, int size)方法写入文件
意义:把byte[]数组从start位置到size位置结束长度的字节写入到文件中。
语法格式和read相同,不多说明
三、FileInputStream和FileOutputStream结合案例
了解了InputStream和OutputStream的使用方法,这次结合两者来写一个复制文件的方法。
public static void copyFile(File srcFile,File destFile)throws IOException{
if(!srcFile.exists()){
throw new IllegalArgumentException("文件:"+srcFile+"不存在");
}
if(!srcFile.isFile()){
throw new IllegalArgumentException(srcFile+"不是一个文件");
}
FileInputStream in =new FileInputStream(srcFile);
FileOutputStream out =new FileOutputStream(destFile);
byte[] buf=new byte[8*1024];
int b;
while((b=in.read(buf, 0, buf.length))!=-1){
out.write(buf, 0, b);
out.flush();//最好加上
}
in.close();
out.close();
}测试文件案例:
try {
IOUtil.copyFile(new File("C:\\Users\\acer\\workspace\\encode\\new4\\test1"), new File("C:\\Users\\acer\\workspace\\encode\\new4\\test2"));
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}运行结果:



复制成功!
四、DataInputStream和DataOutputStream的使用
DataInputStream、DataOutputStream 是对“流”功能的扩展,可以更加方便地读取int,long。字符等类型的数据。
对于DataOutputStream而言,它多了一些方法,如
writeInt()/wirteDouble()/writeUTF()
这些方法其本质都是通过write()方法来完成的,这些方法都是经过包装,方便我们的使用而来的。
1.构造方法
以DataOutputStream为例,构造方法内的对象是OutputStream类型的对象,我们可以通过构造FileOutputStream对象来使用。
String file="demo/data.txt"; DataOutputStream dos= new DataOutputStream(new FileOutputStream(file));
2.write方法使用
dos.writeInt(10);
dos.writeInt(-10);
dos.writeLong(10l);
dos.writeDouble(10.0);
//采用utf-8编码写出
dos.writeUTF("中国");
//采用utf-16be(java编码格式)写出
dos.writeChars("中国");3.read方法使用
以上述的写方法对立,看下面例子用来读出刚刚写的文件
String file="demo/data.txt"; IOUtil.printHex(file); DataInputStream dis=new DataInputStream(new FileInputStream(file)); int i=dis.readInt(); System.out.println(i); i=dis.readInt(); System.out.println(i); long l=dis.readLong(); System.out.println(l); double d=dis.readDouble(); System.out.println(d); String s= dis.readUTF(); System.out.println(s); dis.close();
运行结果:
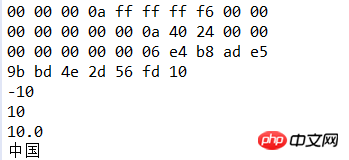
总结:DataInputStream和DataOutputStream其实是对FileInputStream和FileOutputStream进行了包装,通过嵌套方便我们使用FileInputStream和FileOutputStream的读写操作,它们还有很多其他方法,大家可以查询API。
注意:进行读操作的时候如果类型不匹配会出错!
五、字节流的缓冲流BufferredInputStresam&BufferredOutputStresam
这两个流类为IO提供了带缓冲区的操作,一般打开文件进行写入或读取操作时,都会加上缓冲,这种流模式提高了IO的性能。
从应用程序中把输入放入文件,相当于将一缸水倒入另一个缸中:
FileOutputStream---->write()方法相当于一滴一滴地把水“转移”过去
DataOutputStream---->write()XXX方法会方便一些,相当于一瓢一瓢地把水“转移”过去
BufferedOutputStream---->write方法更方便,相当于一瓢一瓢水先放入一个桶中(缓冲区),再从桶中倒入到一个缸中。提高了性能,推荐使用!
上述提到过用FileInputStream和FileOutputStream结合写的一个拷贝文件的案例,这次通过字节的缓冲流对上述案例进行修改,观察两者的区别和优劣。
主函数测试:
try {
long start=System.currentTimeMillis();
//IOUtil.copyFile(new File("C:\\Users\\acer\\Desktop\\学习路径.docx"), new File("C:\\Users\\acer\\Desktop\\复制文本.docx"));
long end=System.currentTimeMillis();
System.out.println(end-start);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}(1)单字节进行文件的拷贝,利用带缓冲的字节流
/*
* 单字节进行文件的拷贝,利用带缓冲的字节流
*/
public static void copyFileByBuffer(File srcFile,File destFile)throws IOException{
if(!srcFile.exists()){
throw new IllegalArgumentException("文件:"+srcFile+"不存在");
}
if(!srcFile.isFile()){
throw new IllegalArgumentException(srcFile+"不是一个文件");
}
BufferedInputStream bis=new BufferedInputStream(new FileInputStream(srcFile));
BufferedOutputStream bos=new BufferedOutputStream(new FileOutputStream(destFile));
int c;
while((c=bis.read())!=-1){
bos.write(c);
bos.flush();//刷新缓冲区
}
bis.close();
bos.close();
}运行结果(效率):
(2)单字节不带缓冲进行文件拷贝
/*
* 单字节不带缓冲进行文件拷贝
*/
public static void copyFileByByte(File srcFile,File destFile)throws IOException{
if(!srcFile.exists()){
throw new IllegalArgumentException("文件:"+srcFile+"不存在");
}
if(!srcFile.isFile()){
throw new IllegalArgumentException(srcFile+"不是一个文件");
}
FileInputStream in=new FileInputStream(srcFile);
FileOutputStream out=new FileOutputStream(destFile);
int c;
while((c=in.read())!=-1){
out.write(c);
out.flush();//不带缓冲,可加可不加
}
in.close();
out.close();
}运行结果(效率):
(3)批量字节进行文件的拷贝,不带缓冲的字节流(就是上面第三点最初的案例的代码)
/*
* 字节批量拷贝文件,不带缓冲
*/
public static void copyFile(File srcFile,File destFile)throws IOException{
if(!srcFile.exists()){
throw new IllegalArgumentException("文件:"+srcFile+"不存在");
}
if(!srcFile.isFile()){
throw new IllegalArgumentException(srcFile+"不是一个文件");
}
FileInputStream in =new FileInputStream(srcFile);
FileOutputStream out =new FileOutputStream(destFile);
byte[] buf=new byte[8*1024];
int b;
while((b=in.read(buf, 0, buf.length))!=-1){
out.write(buf, 0, b);
out.flush();//最好加上
}
in.close();
out.close();
}运行结果(效率):
(4)批量字节进行文件的拷贝,带缓冲的字节流(效率最高,推荐使用!!)
/*
* 多字节进行文件的拷贝,利用带缓冲的字节流
*/
public static void copyFileByBuffers(File srcFile,File destFile)throws IOException{
if(!srcFile.exists()){
throw new IllegalArgumentException("文件:"+srcFile+"不存在");
}
if(!srcFile.isFile()){
throw new IllegalArgumentException(srcFile+"不是一个文件");
}
BufferedInputStream bis=new BufferedInputStream(new FileInputStream(srcFile));
BufferedOutputStream bos=new BufferedOutputStream(new FileOutputStream(destFile));
byte[] buf=new byte[20*1024];
int c;
while((c=bis.read(buf, 0, buf.length))!=-1){
bos.write(buf, 0, c);
bos.flush();//刷新缓冲区
}
bis.close();
bos.close();
}运行结果(效率):
注意:
批量读取或写入字节,带字节缓冲流的效率最高,推荐使用此方法。
当使用字节缓冲流时,写入操作完毕后必须刷新缓冲区,flush()。
不使用字节缓冲流时,flush()可以不加,但是最好加上去。
六、字符流
首先我们需要了解以下概念。
1)需要了解编码问题---->转移至《计算机中的编码问题》
2)认识文本和文本文件
java的文本(char)是16位无符号整数,是字符的unicode编码(双字节编码)
文件是byte byte byte...的数据序列
文本文件是文本(char)序列按照某种编码方案(utf-8,utf-16be,gbk)序列化byte的存储
3)字符流(Reader Writer)
字符的处理,一次处理一个字符;
字符的底层依然是基本的字节序列;
4)字符流的基本实现
InputStreamReader:完成byte流解析成char流,按照编码解析。
OutputStreamWriter:提供char流到byte流,按照编码处理。
-------------------------Reader和Writer的基本使用-------------------------------
String file1="C:\\Users\\acer\\workspace\\encode\\new4\\test1";
String file2="C:\\Users\\acer\\workspace\\encode\\new4\\test2";
InputStreamReader isr=new InputStreamReader(new FileInputStream(file1));
OutputStreamWriter osw=new OutputStreamWriter(new FileOutputStream(file2));
// int c;
// while((c=isr.read())!=-1){
// System.out.print((char)c);
// }
char[] buffer=new char[8*1024];
int c;
//批量读取,放入buffer这个字符数组,从第0个位置到数组长度
//返回的是读到的字符个数
while((c=isr.read(buffer,0,buffer.length))!=-1){
String s=new String(buffer,0,c);//将char类型数组转化为String字符串
System.out.println(s);
osw.write(buffer,0,c);
osw.flush();
//osw.write(s);
//osw.flush();
}
isr.close();
osw.close();注意:
字符流操作的是文本文件,不能操作其他类型的文件!!
默认按照GBK编码来解析(项目默认编码),操作文本文件的时候,要写文件本身的编码格式(在构造函数时在后面加上编码格式)!!
字符流和字节流的区别主要是操作的对象不同,还有字符流是以字符为单位来读取和写入文件的,而字节流是以字节或者字节数组来进行操作的!!
在使用字符流的时候要额外注意文件的编码格式,一不小心就会造成乱码!
七、字符流的文件读写流FileWriter和FileReader
跟字节流的FileInputStream和FileOutputStream类相类似,字符流也有相应的文件读写流FileWriter和FileReader类,这两个类主要是对文本文件进行读写操作。
FileReader/FileWriter:可以直接写文件名的路径。
与InputStreamReader相比坏处:无法指定读取和写出的编码,容易出现乱码。
FileReader fr = new FileReader("C:\\Users\\acer\\workspace\\encode\\new4\\test1"); //输入流
FileWriter fw = new FileWriter(C:\\Users\\acer\\workspace\\encode\\new4\\test2");//输出流char[] buffer=new char[8*1024];
int c;
while((c=fr.read(buffer, 0, buffer.length))!=-1){
fw.write(buffer, 0, c);
fw.flush();
}
fr.close();
fw.close();注意:FileReader和FileWriter不能增加编码参数,所以当项目和读取文件编码不同时,就会产生乱码。 这种情况下,只能回归InputStreamReader和OutputStreamWriter。
八、字符流的过滤器BufferedReader&BufferedWriter
字符流的过滤器有BufferedReader和BufferedWriter/PrintWriter
除了基本的读写功能外,它们还有一些特殊的功能。
BufferedReader----->readLine 一次读一行,并不识别换行
BufferedWriter----->write 一次写一行,需要换行
PrintWriter经常和BufferedReader一起使用,换行写入比BufferedWriter更方便
定义方式:
BufferedReader br =new BufferedReader(new InputStreamReader(new FileInputStream(目录的地址))) BufferedWriter br =new BufferedWriter(new InputStreamWriter(new FileOutputStream(目录的地址))) PrintWriter pw=new PrintWriter(目录/Writer/OutputStream/File);
使用方法:
//对文件进行读写操作
String file1="C:\\Users\\acer\\workspace\\encode\\new4\\test1";
String file2="C:\\Users\\acer\\workspace\\encode\\new4\\test2";
BufferedReader br = new BufferedReader(new InputStreamReader(
new FileInputStream(file1)));
BufferedWriter bw=new BufferedWriter(new OutputStreamWriter(
new FileOutputStream(file2)));
String line;
while((line=br.readLine())!=null){
System.out.println(line);//一次读一行,并不能识别换行
bw.write(line);
//单独写出换行操作
bw.newLine();
bw.flush();
}
br.close();
bw.close();
}在这里我们可以使用PrintWriter来代替BufferedWriter做写操作,PrintWriter相比BufferedWriter有很多优势:
构造函数方便简洁,使用灵活
构造时可以选择是否自动flush
利用println()方法可以实现自动换行,搭配BufferedReader使用更方便
使用方法:
String file1="C:\\Users\\acer\\workspace\\encode\\new4\\test1";
String file2="C:\\Users\\acer\\workspace\\encode\\new4\\test2";
BufferedReader br = new BufferedReader(new InputStreamReader(
new FileInputStream(file1)));
PrintWriter pw=new PrintWriter(file2);
//PrintWriter pw=new PrintWriter(outputStream, autoFlush);//可以指定是否自动flush
String line;
while((line=br.readLine())!=null){
System.out.println(line);//一次读一行,并不能识别换行
pw.println(line);//自动换行
pw.flush();//指定自动flush后不需要写
}
br.close();
pw.close();
}注意:
可以使用BufferedReader的readLine()方法一次读入一行,为字符串形式,用null判断是否读到结尾。
使用BufferedWriter的write()方法写入文件,每次写入后需要调用flush()方法清空缓冲区;PrintWriter在构造时可以指定自动flush,不需要再调用flush方法。
在写入时需要注意写入的数据中会丢失换行,可以在每次写入后调用BufferedReader的newLine()方法或改用PrintWriter的println()方法补充换行。
通常将PrintWriter配合BufferedWriter使用。(PrintWriter的构造方法,及使用方式更为简单)。
위 내용은 Java IO 스트림 바이트 스트림 및 문자 스트림 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



