
이 글은 주로 Java LRU 알고리즘을 소개합니다. LRU 알고리즘의 개념을 간략하게 소개하고 LRU 알고리즘의 구체적인 사용법을 예제 형식으로 분석합니다. 도움이 필요한 친구들이 참고할 수 있습니다.
이 글의 예제는 Java LRU 알고리즘의 소개 및 사용. 참조를 위해 모든 사람과 공유하세요. 세부 사항은 다음과 같습니다.
1. 소개
사용자가 네트워크로 연결된 소프트웨어를 사용할 때 동일한 데이터가 여러 번 사용되면 항상 네트워크에서 데이터를 얻습니다. 그 당시에는 사용자가 인터넷을 사용할 때마다 요청을 하기 위해 인터넷에 접속할 수 없으며 이는 시간과 네트워크의 낭비입니다
이 때 사용자가 요청한 데이터가 저장될 수 있으며, 하지만 모든 데이터가 저장되지는 않으므로 메모리 낭비가 발생합니다. LRU 알고리즘의 아이디어를 적용할 수 있다.
2. LRU 소개
LRU는 오랫동안 사용하지 않은 데이터를 삭제할 수 있는 Least Recent Used 알고리즘입니다.
LRU는 어떤 사람들의 감정에도 잘 반영됩니다. 여러 친구들과 연락할 때 자주 연락하는 사람들과의 관계는 매우 좋습니다. 오랫동안 연락하지 않고 아마도 다시 연락하지 않을 것이라면 이것을 잃게 될 것입니다. 친구.
3 다음 코드는 LRU 알고리즘을 보여줍니다.
가장 간단한 방법은 LinkHashMap을 사용하는 것입니다. 설정된 캐시 범위 내에서 여분의 오래된 데이터를 제거하는 방법이 있기 때문입니다
public class LRUByHashMap<K, V> {
/*
* 通过LinkHashMap简单实现LRU算法
*/
/**
* 缓存大小
*/
private int cacheSize;
/**
* 当前缓存数目
*/
private int currentSize;
private LinkedHashMap<K, V> maps;
public LRUByHashMap(int cacheSize1) {
this.cacheSize = cacheSize1;
maps = new LinkedHashMap<K, V>() {
/**
*
*/
private static final long serialVersionUID = 1;
// 这里移除旧的缓存数据
@Override
protected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) {
// 当超过缓存数量的时候就将旧的数据移除
return getCurrentSize() > LRUByHashMap.this.cacheSize;
}
};
}
public synchronized int getCurrentSize() {
return maps.size();
}
public synchronized void put(K k, V v) {
if (k == null) {
throw new Error("存入的键值不能为空");
}
maps.put(k, v);
}
public synchronized void remove(K k) {
if (k == null) {
throw new Error("移除的键值不能为空");
}
maps.remove(k);
}
public synchronized void clear() {
maps = null;
}
// 获取集合
public synchronized Collection<V> getCollection() {
if (maps != null) {
return maps.values();
} else {
return null;
}
}
public static void main(String[] args) {
// 测试
LRUByHashMap<Integer, String> maps = new LRUByHashMap<Integer, String>(
3);
maps.put(1, "1");
maps.put(2, "2");
maps.put(3, "3");
maps.put(4, "4");
maps.put(5, "5");
maps.put(6, "6");
Collection<String> col = maps.getCollection();
System.out.println("存入缓存中的数据是--->>" + col.toString());
}
}이후 효과 실행 중:
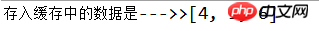
코드에는 6개의 항목이 명확하게 입력되어 있지만 결국 3개만 표시되었습니다. 그 사이의 3개는 오래되어 직접 클릭되었습니다.
두 번째 유형은 이중 연결 목록 + 해시 테이블을 사용하는 방법입니다
이중 연결 리스트의 역할은 위치를 기록하는 것이고, HashTable은 데이터를 저장하는 컨테이너로 사용됩니다.
HashMap 대신 HashTable을 사용하는 이유는 무엇입니까?
1. HashTable의 키와 값은 null일 수 없습니다.
2. 위의 LinkHashMap으로 구현된 LRU는 스레드가 이를 동기적으로 처리할 수 있도록 하여 다중 스레드가 통합 데이터를 처리할 때 문제를 방지하는 데 유용합니다. HashTable 자체 동기화 메커니즘을 가지고 있어 멀티 스레드가 HashTable을 올바르게 처리할 수 있습니다.
모든 캐시는 위치 이중 목록으로 연결됩니다. 위치가 연결되면 연결 목록의 포인팅을 조정하여 위치가 연결 목록의 선두 위치로 조정됩니다. 연결리스트의 선두. 이러한 방식으로 여러 캐시 작업 후에 가장 최근에 적중된 항목은 연결 목록의 선두 쪽으로 이동하고, 적중되지 않은 항목은 연결 목록의 뒤쪽으로 이동합니다. 가장 최근에 사용된 캐시입니다. 콘텐츠를 교체해야 하는 경우 연결 목록의 마지막 위치가 가장 적중률이 낮은 위치가 됩니다. 연결 목록의 마지막 부분만 제거하면 됩니다
public class LRUCache {
private int cacheSize;
private Hashtable<Object, Entry> nodes;//缓存容器
private int currentSize;
private Entry first;//链表头
private Entry last;//链表尾
public LRUCache(int i) {
currentSize = 0;
cacheSize = i;
nodes = new Hashtable<Object, Entry>(i);//缓存容器
}
/**
* 获取缓存中对象,并把它放在最前面
*/
public Entry get(Object key) {
Entry node = nodes.get(key);
if (node != null) {
moveToHead(node);
return node;
} else {
return null;
}
}
/**
* 添加 entry到hashtable, 并把entry
*/
public void put(Object key, Object value) {
//先查看hashtable是否存在该entry, 如果存在,则只更新其value
Entry node = nodes.get(key);
if (node == null) {
//缓存容器是否已经超过大小.
if (currentSize >= cacheSize) {
nodes.remove(last.key);
removeLast();
} else {
currentSize++;
}
node = new Entry();
}
node.value = value;
//将最新使用的节点放到链表头,表示最新使用的.
node.key = key
moveToHead(node);
nodes.put(key, node);
}
/**
* 将entry删除, 注意:删除操作只有在cache满了才会被执行
*/
public void remove(Object key) {
Entry node = nodes.get(key);
//在链表中删除
if (node != null) {
if (node.prev != null) {
node.prev.next = node.next;
}
if (node.next != null) {
node.next.prev = node.prev;
}
if (last == node)
last = node.prev;
if (first == node)
first = node.next;
}
//在hashtable中删除
nodes.remove(key);
}
/**
* 删除链表尾部节点,即使用最后 使用的entry
*/
private void removeLast() {
//链表尾不为空,则将链表尾指向null. 删除连表尾(删除最少使用的缓存对象)
if (last != null) {
if (last.prev != null)
last.prev.next = null;
else
first = null;
last = last.prev;
}
}
/**
* 移动到链表头,表示这个节点是最新使用过的
*/
private void moveToHead(Entry node) {
if (node == first)
return;
if (node.prev != null)
node.prev.next = node.next;
if (node.next != null)
node.next.prev = node.prev;
if (last == node)
last = node.prev;
if (first != null) {
node.next = first;
first.prev = node;
}
first = node;
node.prev = null;
if (last == null)
last = first;
}
/*
* 清空缓存
*/
public void clear() {
first = null;
last = null;
currentSize = 0;
}
}
class Entry {
Entry prev;//前一节点
Entry next;//后一节点
Object value;//值
Object key;//键
}위 내용은 Java에서 LRU 알고리즘을 사용하는 방법에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



